7.5.2 AsyncTask的执行
异步任务创建完毕后,便调用其execute方法开始执行。异步任务的执行流程如图7-5所示。
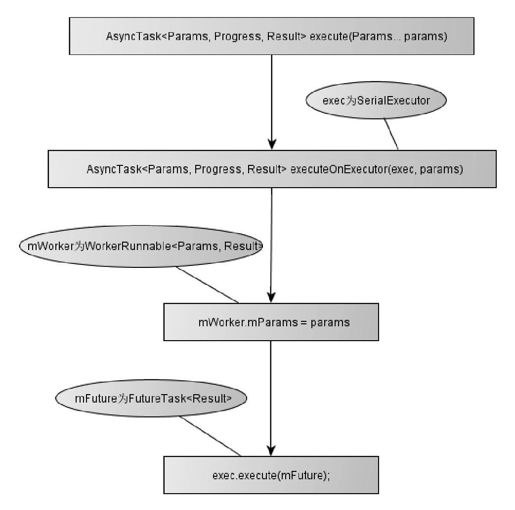
图 7-5 异步任务的执行流程
由图7-5可知,调用异步任务的execute方法,进而会调用executeOnExecutor方法,该方法的作用正如其方法名所表示的:放入执行器中执行。
executeOnExecutor方法接收两个参数,其中参数exec用于指定执行器,params是异步任务的参数。默认实现中,执行器由Serial Executor提供,参数parmms则存入mWorker中,最后连同mFuture一起传入SerialExecutor执行器的execute方法。
SerialExecutor的execute方法接收的是Runnable类型的线程参数,FutureTask实现了Runnable接口,因此可以作为该execute的参数。
1.SerialExecutor的execute方法
接下来分析SerialExecutor的execute方法,代码如下:
public abstract class AsyncTask<Params, Progress, Result>{
……
//Executor是一个接口,定义了execute方法
private static class SerialExecutor implements Executor{
//定义一个队列,存储Runnable类型的成员
final ArrayDeque<Runnable>mTasks=new ArrayDeque<Runnable>();
Runnable mActive;
//实现Executor接口定义的execute方法,接收Runnable类型的参数mFuture
public synchronized void execute(final Runnable r){
//再次将mFuture封装到Runnable中,并存入队列mTasks的队尾
mTasks.offer(new Runnable(){
public void run(){
try{
r.run();//在新线程的run方法中调用mFuture的run方法
}finally{
scheduleNext();
}
}
});
if(mActive==null){//当前处理任务为空时,调度下一个任务
scheduleNext();
}
}
protected synchronized void scheduleNext(){
//从mTasks的队首取出一个任务
if((mActive=mTasks.poll())!=null){
//将取出的任务放入线程池中执行
THREAD_POOL_EXECUTOR.execute(mActive);
}
}
}
……
调用SerialExecutor的execute方法,首先将传入的mFuture封装到Runnable中,然后存入ArrayDeque类型的mTasks任务队列中。接下来便调用scheduleNext方法从mTasks取出一个任务放入THREAD_POOL_EXECUTOR线程池中等待执行。
线程池是AsyncTask的公开静态成员变量,为所有异步任务共享,其初始化代码如下:
public abstract class AsyncTask<Params, Progress, Result>{
……
//线程池的核心大小,即线程池中核心线程数默认为5
private static final int CORE_POOL_SIZE=5;
//线程池的最大值为128
private static final int MAXIMUM_POOL_SIZE=128;
//当线程池中线程数量大于线程池核心大小的时候,指定空闲线程的存活时间
private static final int KEEP_ALIVE=1;
//线程池所需的线程创建工厂,用于创建线程池中的线程
private static final ThreadFactory sThreadFactory=new ThreadFactory(){
private final AtomicInteger mCount=new AtomicInteger(1);
public Thread newThread(Runnable r){
return new Thread(r,"AsyncTask#"+mCount.getAndIncrement());
}
};
//存放线程池中待执行任务的队列
private static final BlockingQueue<Runnable>sPoolWorkQueue=
new LinkedBlockingQueue<Runnable>(10);
//默认线程池,TimeUnit.SECONDS是KEEP_ALIVE的时间,单位为s(秒)
public static final Executor THREAD_POOL_EXECUTOR=
new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIMUM_POOL_SIZE,
KEEP_ALIVE, TimeUnit.SECONDS,
sPoolWorkQueue, sThreadFactory);
……
关于线程池的内容请参考《Java并发编程实战》一书,这里不赘述。
2.ThreadPoolExecutor线程池的execute方法
接下来分析ThreadPoolExecutor线程池的execute方法,代码如下:
public class ThreadPoolExecutor extends AbstractExecutorService{
/*调用ctlOf方法将整数RUNNING和0做或操作,操作结果存入一个整数ctl中。
*RUNNING表示线程池的运行状态(runState)为RUNNING状态,
0表示线程池中处于运行状态的线程数(workerCount)为0/
private final AtomicInteger ctl=new AtomicInteger(ctlOf(RUNNING,0));
//COUNT_BITS的值为29
private static final int COUNT_BITS=Integer.SIZE-3;
/*CAPACITY表示线程池中处于运行状态的线程最大数,
*其二进制形式为0001 1111 1111 1111 1111 1111 1111 1111,
*高3位全为0,低29位全为1,表示一个29位二进制数码能表示的最大值,
这个值即workerCount的最大值/
private static final int CAPACITY=(1<<COUNT_BITS)-1;
/*RUNNING的二进制形式为1110 0000 0000 0000 0000 0000 0000 0000,
即用一个32位整数的高3位111存储线程池的runState,下同/
private static final int RUNNING=-1<<COUNT_BITS;
//0左移29位后仍是0,因此SHUTDOWN的值为0,高3位为000
private static final int SHUTDOWN=0<<COUNT_BITS;
//STOP的二进制形式为0010 0000 0000 0000 0000 0000 0000 0000,高3位为001
private static final int STOP=1<<COUNT_BITS;
//TIDYING的值为0100 0000 0000 0000 0000 0000 0000 0000,高3位为010
private static final int TIDYING=2<<COUNT_BITS;
//TERMINATED的值为0110 0000 0000 0000 0000 0000 0000 0000,高3位为011
private static final int TERMINATED=3<<COUNT_BITS;
/*传入的参数c为ctl,用于获取ctl中存储的runState。
*~CAPACITY的二进制形式为1110 0000 0000 0000 0000 0000 0000 0000。
*c&~CAPACITY操作的结果是将c的低29位置为0,高3位值不变。
已知runState存储在高3位,因此runStateOf返回runState/
private static int runStateOf(int c){return c&~CAPACITY;}
/*传入的参数c为ctl,用于获取ctl中存储的workerCount。
*CAPACITY的二进制形式为0001 1111 1111 1111 1111 1111 1111 1111。
*c&CAPACITY操作的结果是将c的高3位置为0,低29位值不变。
已知workerCount存储在低29位,因此workerCountOf返回workerCount/
private static int workerCountOf(int c){return c&CAPACITY;}
/*ctlOf将两个整数rs和wc做或操作,放入一个整数中。
*rs表示runState, wc表示workerCount。已知runState以32位整数的高3位表
示,因此ctlOf的运算结果以高3位表示runState,以低29位表示workerCount/
private static int ctlOf(int rs, int wc){return rs|wc;}
public void execute(Runnable command){//command即封装后的mFuture
if(command==null)
throw new NullPointerException();
int c=ctl.get();//获取存储runState和workerCount的整数,存入c中
/*workerCountOf获取c中存储的workerCount, corePoolSize表示线程池的核
*心线程数,其值为5。如果线程池当前处于运行状态的线程数小于核心线程数,需要
调用addWorker创建新线程,传入的command将成为新线程的第一个执行任务/
if(workerCountOf(c)<corePoolSize){①
if(addWorker(command, true))
return;
c=ctl.get();
}
/*isRunning方法判断c是否小于SHUTDOWN,在线程池的runState中,只有
*RUNNING小于SHUTDOWN。workQueue在创建ThreadPoolExecutor时指定。这个
if分支的意思是:如果当前线程池处于运行状态,并且工作队列中可以插入任务/
if(isRunning(c)&&workQueue.offer(command)){②
int recheck=ctl.get();//防止有并发操作修改ctl,这里重新检查
/*recheck后,如果是线程池的runState发生改变,即不在
运行状态时,需要将上步中提交到工作队列的任务移除/
if(!isRunning(recheck)&&remove(command))
reject(command);//拒绝运行这个任务
/recheck后,如果是线程池的workerCount变为0,则创建新线程/
else if(workerCountOf(recheck)==0)
addWorker(null, false);
}
/*线程池runState不为RUNNING,或工作队列无法添加任务,这两种情况至少满足一种时,尝试
添加新线程,如果添加失败,说明线程池确实处于shut down状态了,此时拒绝执行任务/
else if(!addWorker(command, false))//③
reject(command);
}
ThreadPoolExecutor提供了线程池的默认实现,该线程池提供两个整型数runState和workerCount跟踪线程池的控制状态(ctl status)。其中runState表示线程池的运行状态,用于线程池生命周期的控制;workerCount表示线程池中允许start和没有stop的Worker数量,即线程池中当前工作线程的数量。
runState可以有以下五种状态:
RUNNING:运行状态,可以接受新任务,也可以处理工作队列中已有任务。
SHUTDOWN:关闭状态,不可以接收新任务,但可以处理工作队列中已有任务。
STOP:停止状态,不可以接收新任务,不可以处理工作队列中已有任务,并且要中断正在执行的任务。
TIDYING:整理状态,所有任务都已结束,workerCount为0,准备执行terminated()方法。
TERMINATED:终止状态,terminated()方法执行完毕。
runState以一个32位整型数的高3位表示,workerCount则通过CAPACITY限制为29位二进制数,因此可以调用ctlOf方法将runState和workerCount做“|”运算,这样将runState和workerCount分别存储到整数ctl的高3位和低29位。
线程池的execute方法所作的工作可以分成三部分,如上述代码中①②③所示。
1)在①中,如果线程池中工作线程的数量小于线程池定义的核心线程数量,需要调用addWorker(command, true)创建新的工作线程。
2)在②中,如果线程池处于运行状态,并且工作队列中可以插入新的任务,此时对ctl进行重新检查。如果检查结果是runState发生改变,则需要从工作队列中移除①中加入的任务;如果检查结果是workerCount发生变化,则需要调用addWorker(null, false)创建新的工作线程。
3)不满足②的情况下,即线程池runState不为RUNNING、工作队列无法添加任务这两种情况至少满足一种时,进入③中。此时需要调用addWorker(command, false),尝试创建工作线程,如果创建失败,说明线程池确实shut down了,此时拒绝执行任务。
上述三部分工作都是围绕addWorker展开的,只是传入的参数不同而已。接下来分析addWorker方法,代码如下:
private boolean addWorker(Runnable firstTask, boolean core){
retry://retry标签标记外层的for循环
for(;){
int c=ctl.get();//获取线程池的控制状态
int rs=runStateOf(c);//从控制状态中获取runState
/*根据逻辑运算规则,该判定条件可以转换为rs>=SHUTDOWN&&
*((rs!=SHUTDOWN||firstTask!=null||workQueue.isEmpty())
表示当线程池处于非RUNNING状态时,只要满足||运算的任一条件便直接返回/
if(rs>=SHUTDOWN&&
!(rs==SHUTDOWN&&
firstTask==null&&
!workQueue.isEmpty()))
return false;
for(;){//内层for循环
int wc=workerCountOf(c);//获取线程池的当前工作线程数
/*工作线程数已经达到CAPACITY的限制;
*如果参数core为true,需要判断工作线程数是否大于corePoolSize;
*如果参数core为false,需要判断工作线程数是否超过maximumPoolSize;
上述三种情况下,都需要直接返回/
if(wc>=CAPACITY||
wc>=(core?corePoolSize:maximumPoolSize))
return false;
//workCount加1,成功则跳出外层for循环,到①处的后续代码继续执行
if(compareAndIncrementWorkerCount(c))
break retry;
//如果workCount加1操作失败
c=ctl.get();//重新获取ctl
if(runStateOf(c)!=rs)//如果runState改变则继续外层for循环
continue retry;
//运行到此处说明workerCount改变,开始内层for循环的下一次循环
}
}
//①workCount成功加1后,就可以创建工作线程处理任务了
//将mFuture封装成Worker
Worker w=new Worker(firstTask);
Thread t=w.thread;
final ReentrantLock mainLock=this.mainLock;//访问工作线程池需要加锁
mainLock.lock();
try{
……
/workers的类型是HashSet<Worker>,将工作线程加入到工作线程池/
workers.add(w);
……
}finally{
mainLock.unlock();
}
t.start();//②启动t,注意这里不是启动w
……
return true;
}
addWorker的核心工作可以分成两部分,在上述代码中以①和②标出。其中①用于创建工作线程Worker,②用于启动工作线程。
Worker是ThreadPoolExecutor的内部类,代码如下:
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/Worker运行于thread中/
final Thread thread;
/初始任务/
Runnable firstTask;
/Per-thread task counter/
volatile long completedTasks;
Worker(Runnable firstTask){
//新创建的工作线程可以指定一个初始任务
this.firstTask=firstTask;
/*通过工厂方法创建一个线程,该线程工厂在创建ThreadPoolExecutor时
指定newThread方法将当前Worker对象封装成Thread返回/
this.thread=getThreadFactory().newThread(this);
}
public void run(){//工作线程的运行代码
runWorker(this);
}
……
}
Worker是Runnable的子类,在其内部定义了一个Thread类型的成员变量thread。构造Worker对象时,通过工厂方法创建一个新线程,将Worker封装成Thread存入成员变量thread中。这样便可以通过thread.start方法启动Worker,进而执行Worker的run方法。
在Worker的run方法中调用runWorker方法,其代码如下:
final void runWorker(Worker w){
Runnable task=w.firstTask;//获取工作线程的第一个任务
w.firstTask=null;
boolean completedAbruptly=true;
try{
//如果指定了第一个任务则首先执行第一个任务,否则从工作队列中提取任务
while(task!=null||(task=getTask())!=null){
w.lock();
clearInterruptsForTaskRun();
try{
beforeExecute(w.thread, task);//方法体为空,可以在子类中覆盖
Throwable thrown=null;
try{
//调用任务的run方法执行任务,该任务此时运行于Worker线程中
task.run();
}catch(RuntimeException x){
……
}finally{
afterExecute(task, thrown);//方法体为空
}
}finally{
task=null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly=false;
}finally{
processWorkerExit(w, completedAbruptly);
}
}
可见runWorker方法是在工作线程中执行任务的run方法。而任务封装了FutureTask类型的mFuture对象,执行任务的run方法会调用mFuture的run方法,这部分内容在分析SerialExecutor的execute方法时已经分析过。接下来分析FutureTask的run方法,代码如下:
public void run(){
sync.innerRun();
}
在FutureTask的run方法中会调用其成员变量sync的innerRun方法,代码如下:
public class FutureTask<V>implements RunnableFuture<V>{
/用于FutureTask的同步控制/
private final Sync sync;
//创建FutureTask时,传入一个Callable类型的参数,该参数是WorkerRunnable类型的mWorker
public FutureTask(Callable<V>callable){
if(callable==null)
throw new NullPointerException();
sync=new Sync(callable);
}
private final class Sync extends AbstractQueuedSynchronizer{
……
void innerRun(){
if(!compareAndSetState(READY, RUNNING))
return;
runner=Thread.currentThread();
if(getState()==RUNNING){//recheck after setting thread
V result;
try{
result=callable.call();//调用的是mWorker的call方法
}catch(Throwable ex){
setException(ex);
return;
}
set(result);
}else{
releaseShared(0);//cancel
}
}
可见,sync的innerRun最终调用了其成员变量callable的call方法,而callable在创建mFuture时保存的是mWorker对象,因此这里实际调用了mWorker的call方法。该方法代码如下:
mWorker=new WorkerRunnable<Params, Result>(){
public Result call()throws Exception{
mTaskInvoked.set(true);
Process.setThreadPriority(
Process.THREAD_PRIORITY_BACKGROUND);
return postResult(doInBackground(mParams));
}
};
mWorker的call方法会调用doInBackground方法,并将返回结果作为postResult方法的参数,这样便实现了在后台线程中执行doInBackground。
接下来分析postResult,代码如下:
public abstract class AsyncTask<Params, Progress, Result>{
……
private static final int MESSAGE_POST_RESULT=0x1;
//InternalHandler是Handler的子类
private static final InternalHandler sHandler=new InternalHandler();
……
private Result postResult(Result result){//Result是个泛型参数
@SuppressWarnings("unchecked")
/*通过sHandler获取what标记为MESSAGE_POST_RESULT的消息。
*obtainMessage方法的第一个参数存入消息的what成员变量中,第二个参数
存入消息的obj成员变量中,消息的target存储的是当前对象sHandler/
Message message=sHandler.obtainMessage(MESSAGE_POST_RESULT,
new AsyncTaskResult<Result>(this, result));
message.sendToTarget();//将消息发送到sHandler处理
return result;
}
由以上代码可知,doInBackground方法执行完毕后将执行结果传入postResult方法,在该方法中以AsyncTaskResult类型的对象封装处理结果,并将其放入消息的obj成员变量中,然后通过Handler机制处理消息。首先分析AsyncTaskResult,其代码如下:
private static class AsyncTaskResult<Data>{
final AsyncTask mTask;
final Data[]mData;
AsyncTaskResult(AsyncTask task, Data……data){
mTask=task;//本例中即AddCallTask
mData=data;//执行结束和执行过程的数据,本例只分析执行结束
}
}
AsyncTaskResult只是将异步任务及其执行数据做了一个绑定,AsyncTaskResult最终封装到消息的obj成员变量中,发送到消息处理器InternalHandler。
InternalHandler是AsyncTask的内部类,其代码如下:
public abstract class AsyncTask<Params, Progress, Result>{
……
private static final InternalHandler sHandler=new InternalHandler();
……
private static class InternalHandler extends Handler{
@SuppressWarnings({"unchecked","RawUseOfParameterizedType"})
@Override
public void handleMessage(Message msg){
//从消息的obj成员变量中取出发送时存入的AsyncTaskResult
AsyncTaskResult result=(AsyncTaskResult)msg.obj;
switch(msg.what){
case MESSAGE_POST_RESULT://对应于执行结束的消息
//result的mTask存储的是异步任务
result.mTask.finish(result.mData[0]);
break;
case MESSAGE_POST_PROGRESS://对应于执行过程的消息
result.mTask.onProgressUpdate(result.mData);
break;
}
}
}
可见InternalHandler最终将消息的处理转发给异步任务的finish和onProgressUpdate方法处理。由于异步任务必须在UI线程中创建,因此其成员变量sHandler,以及finish和onProgressUpdate方法便定义于UI线程,当线程池中的工作线程执行doInBackground方法后,将处理结果以消息的形式发送到sHandler,这样便可以利用sHandler更新UI控件。
接下来分析finish方法,代码如下:
public abstract class AsyncTask<Params, Progress, Result>{
……
private void finish(Result result){
if(isCancelled()){
onCancelled(result);//由异步任务的子类定义具体的Cancel操作
}else{
onPostExecute(result);//由异步任务的子类定义具体的后续处理操作
}
mStatus=Status.FINISHED;//更改异步任务的状态,不能重复执行
}
finish方法很简单,只是根据异步任务的执行情况,分别调用不同的处理方法,而这些处理方法都是运行于UI线程的,可以由子类定义其具体行为。
