8.4.3 基于栈的解释器执行过程
初步的理论知识已经讲解过了,本节准备了一段Java代码,看看在虚拟机中实际是如何执行的。前面曾经举过一个计算“1+1”的例子,这样的算术题目显然太过简单了,笔者准备了四则运算的例子,请看代码清单8-16。
代码清单8-16 一段简单的算术代码
public int calc(){
int a=100;
int b=200;
int c=300;
return(a+b)*c;
}
从Java语言的角度来看,这段代码没有任何解释的必要,可以直接使用javap命令看看它的字节码指令,如代码清单8-17所示。
代码清单8-17 一段简单的算术代码的字节码表示
public int calc();
Code:
Stack=2,Locals=4,Args_size=1
0:bipush 100
2:istore_1
3:sipush 200
6:istore_2
7:sipush 300
10:istore_3
11:iload_1
12:iload_2
13:iadd
14:iload_3
15:imul
16:ireturn
}
javap提示这段代码需要深度为2的操作数栈和4个Slot的局部变量空间,笔者根据这些信息画了图8-5~图8-11共7张图,用它们来描述代码清单8-17执行过程中的代码、操作数栈和局部变量表的变化情况。
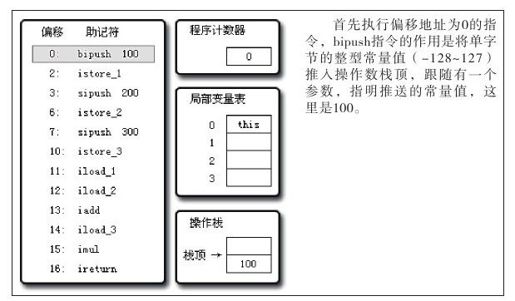
图 8-5 执行偏移地址为0的指令的情况
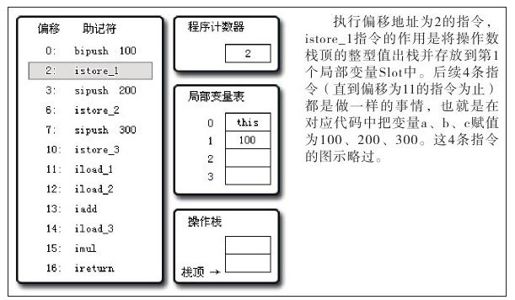
图 8-6 执行偏移地址为1的指令的情况

图 8-7 执行偏移地址为11的指令的情况
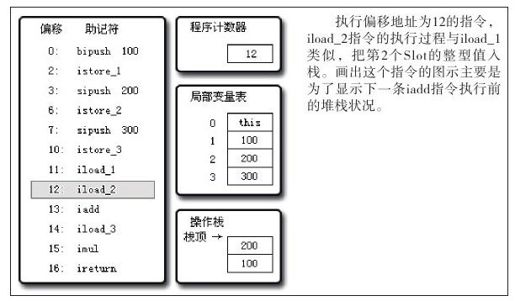
图 8-8 执行偏移地址为12的指令的情况
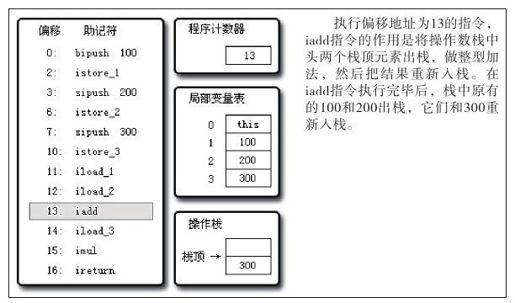
图 8-9 执行偏移地址为13的指令的情况
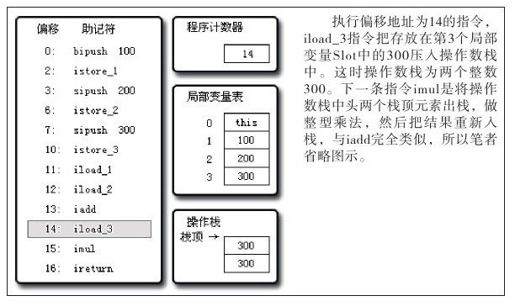
图 8-10 执行偏移地址为14的指令的情况
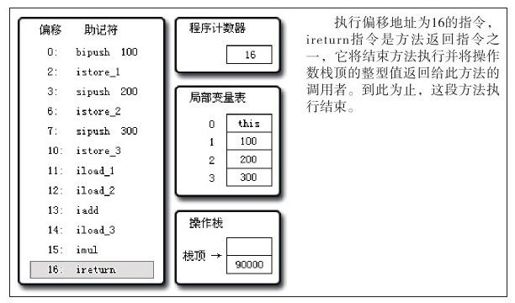
图 8-11 执行偏移地址为16的指令的情况
上面的执行过程仅仅是一种概念模型,虚拟机最终会对执行过程做一些优化来提高性能,实际的运作过程不一定完全符合概念模型的描述……更准确地说,实际情况会和上面描述的概念模型差距非常大,这种差距产生的原因是虚拟机中解析器和即时编译器都会对输入的字节码进行优化,例如,在HotSpot虚拟机中,有很多以“fast_”开头的非标准字节码指令用于合并、替换输入的字节码以提升解释执行性能,而即时编译器的优化手段更加花样繁多[1]。
不过,我们从这段程序的执行中也可以看出栈结构指令集的一般运行过程,整个运算过程的中间变量都以操作数栈的出栈、入栈为信息交换途径,符合我们在前面分析的特点。
[1]具体可以参考第11章中的相关内容。
