11.2.4 查看及分析即时编译结果
一般来说,虚拟机的即时编译过程对用户程序是完全透明的,虚拟机通过解释执行代码还是编译执行代码,对于用户来说并没有什么影响(执行结果没有影响,速度上会有很大差别),在大多数情况下用户也没有必要知道。但是虚拟机也提供了一些参数用来输出即时编译和某些优化手段(如方法内联)的执行状况,本节将介绍如何从外部观察虚拟机的即时编译行为。
本节中提到的运行参数有一部分需要Debug或FastDebug版虚拟机的支持,Product版的虚拟机无法使用这部分参数。如果读者使用的是根据本书第1章的内容自己编译的JDK,注意将SKIP_DEBUG_BUILD或SKIP_FASTDEBUG_BUILD参数设置为false,也可以在OpenJDK网站上直接下载FastDebug版的JDK(从JDK 6u25之后Oracle官网就不再提供FastDebug的JDK下载了)。注意,本节中所有的测试都基于代码清单11-2所示的Java代码。
代码清单11-2 测试代码
public static final int NUM=15000;
public static int doubleValue(int i){
//这个空循环用于后面演示JIT代码优化过程
for(int j=0;j<100000;j++);
return i*2;
}
public static long calcSum(){
long sum=0;
for(int i=1;i<=100;i++){
sum+=doubleValue(i);
}
return sum;
}
public static void main(String[]args){
for(int i=0;i<NUM;i++){
calcSum();
}
}
首先运行这段代码,并且确认这段代码是否触发了即时编译,要知道某个方法是否被编译过,可以使用参数-XX:+PrintCompilation要求虚拟机在即时编译时将被编译成本地代码的方法名称打印出来,如代码清单11-3所示(其中带有“%”的输出说明是由回边计数器触发的OSR编译)。
代码清单11-3 被即时编译的代码
VM option'+PrintCompilation'
310 1 java.lang.String:charAt(33 bytes)
329 2 org.fenixsoft.jit.Test:calcSum(26 bytes)
329 3 org.fenixsoft.jit.Test:doubleValue(4 bytes)
332 1%org.fenixsoft.jit.Test:main@5(20 bytes)
从代码清单11-3输出的确认信息中可以确认main()、calcSum()和doubleValue()方法已经被编译,我们还可以加上参数-XX:+PrintInlining要求虚拟机输出方法内联信息,如代码清单11-4所示。
代码清单11-4 内联信息
VM option'+PrintCompilation'
VM option'+PrintInlining'
273 1 java.lang.String:charAt(33 bytes)
291 2 org.fenixsoft.jit.Test:calcSum(26 bytes)
@9 org.fenixsoft.jit.Test:doubleValue inline(hot)
294 3 org.fenixsoft.jit.Test:doubleValue(4 bytes)
295 1%org.fenixsoft.jit.Test:main@5(20 bytes)
@5 org.fenixsoft.jit.Test:calcSum inline(hot)
@9 org.fenixsoft.jit.Test:doubleValue inline(hot)
从代码清单11-4的输出中可以看到方法doubleValue()被内联编译到calcSum()中,而calcSum()又被内联编译到方法main()中,所以虚拟机再次执行main()方法的时候(举例而已,main()方法并不会运行两次),calcSum()和doubleValue()方法都不会再被调用,它们的代码逻辑都被直接内联到main()方法中了。
除了查看哪些方法被编译之外,还可以进一步查看即时编译器生成的机器码内容,不过如果虚拟机输出一串0和1,对于我们的阅读来说是没有意义的,机器码必须反汇编成基本的汇编语言才可能被阅读。虚拟机提供了一组通用的反汇编接口[1],可以接入各种平台下的反汇编适配器来使用,如使用32位80x86平台则选用hsdis-i386适配器,其余平台的适配器还有hsdis-amd64、hsdis-sparc和hsdis-sparcv9等,可以下载或自己编译出反汇编适配器[2],然后将其放置在JRE/bin/client或/server目录下,只要与jvm.dll的路径相同即可被虚拟机调用。在为虚拟机安装了反汇编适配器之后,就可以使用-XX:+PrintAssembly参数要求虚拟机打印编译方法的汇编代码了,具体的操作可以参考本书4.2.7节。
如果没有HSDIS插件支持,也可以使用-XX:+PrintOptoAssembly(用于Server VM)或-XX:+PrintLIR(用于Client VM)来输出比较接近最终结果的中间代码表示,代码清单11-2被编译后部分反汇编(使用-XX:+PrintOptoAssembly)的输出结果如代码清单11-5所示。从阅读角度来说,使用-XX:+PrintOptoAssembly参数输出的伪汇编结果包含了更多的信息(主要是注释),利于阅读并理解虚拟机JIT编译器的优化结果。
代码清单11-5 本地机器码反汇编信息(部分)
……
000 B1:#N1<-BLOCK HEAD IS JUNK Freq:1
000 pushq rbp
subq rsp,#16#Create frame
nop#nop for patch_verified_entry
006 movl RAX,RDX#spill
008 sall RAX,#1
00a addq rsp,16#Destroy frame
popq rbp
testl rax,[rip+#offset_to_poll_page]#Safepoint:poll for GC
……
前面提到的使用-XX:+PrintAssembly参数输出反汇编信息需要Debug或者FastDebug版的虚拟机才能直接支持,如果使用Product版的虚拟机,则需要加入参数-XX:+UnlockDiagnosticVMOptions打开虚拟机诊断模式后才能使用。
如果除了本地代码的生成结果外,还想再进一步跟踪本地代码生成的具体过程,那还可以使用参数-XX:+PrintCFGToFile(使用Client Compiler)或-XX:PrintIdealGraphFile(使用Server Compiler)令虚拟机将编译过程中各个阶段的数据(例如,对C1编译器来说,包括字节码、HIR生成、LIR生成、寄存器分配过程、本地代码生成等数据)输出到文件中。然后使用Java HotSpot Client Compiler Visualizer[3](用于分析Client Compiler)或Ideal Graph Visualizer[4](用于分析Server Compiler)打开这些数据文件进行分析。以Server Compiler为例,笔者分析一下JIT编译器的代码生成过程。
Server Compiler的中间代码表示是一种名为Ideal的SSA形式程序依赖图(Program Dependence Graph),在运行Java程序的JVM参数中加入“-XX:PrintIdealGraphLevel=2-XX:PrintIdealGraphFile=ideal.xml”,编译后将产生一个名为ideal.xml的文件,它包含了Server Compiler编译代码的过程信息,可以使用Ideal Graph Visualizer对这些信息进行分析。
Ideal Graph Visualizer加载ideal.xml文件后,在Outline面板上将显示程序运行过程中编译过的方法列表,如图11-5所示。这里列出的方法是代码清单11-2中的测试代码,其中doubleValue()方法出现了两次,这是由于该方法的编译结果存在标准编译和OSR编译两个版本。在代码清单11-2中,笔者特别为doubleValue()方法增加了一个空循环,这个循环对方法的运算结果不会产生影响,但如果没有任何优化,执行空循环会占用CPU时间,到今天还有许多程序设计的入门教程把空循环当做程序延时的手段来介绍,在Java中这样的做法真的能起到延时的作用吗?
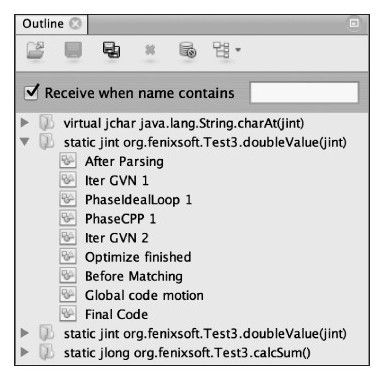
图 11-5 编译过的方法列表
展开方法根节点,可以看到下面罗列了方法优化过程的各个阶段(根据优化措施的不同,每个方法所经过的阶段也会有所差别)的Ideal图,我们先打开“After Parsing”这个阶段。上文提到,JIT编译器在编译一个Java方法时,首先要把字节码解析成某种中间表示形式,然后才可以继续做分析和优化,最终生成代码。“After Parsing”就是Server Compiler刚完成解析,还没有做任何优化时的Ideal图表示。在打开这个图后,读者会看到其中有很多有颜色的方块,如图11-6所示。每一个方块就代表了一个程序的基本块(Basic Block),基本块的特点是只有唯一的一个入口和唯一的一个出口,只要基本块中第一条指令执行了,那么基本块内所有执行都会按照顺序仅执行一次。
代码清单11-2的doubleValue()方法虽然只有简单的两行字,但是按基本块划分后,形成的图形结构要比想象中复杂得多,这一方面是要满足Java语言所定义的安全需要(如类型安全、空指针检查)和Java虚拟机的运作需要(如Safepoint轮询),另一方面是由于有些程序代码中一行语句就可能形成好几个基本块(例如循环)。对于例子中的doubleValue()方法,如果忽略语言安全检查的基本块,可以简单理解为按顺序执行了以下几件事情:
1)程序入口,建立栈帧。
2)设置j=0,进行Safepoint轮询,跳转到4)的条件检查。
3)执行j++。
4)条件检查,如果j<100000,跳转到3)。
5)设置i=i*2,进行Safepoint轮询,函数返回。
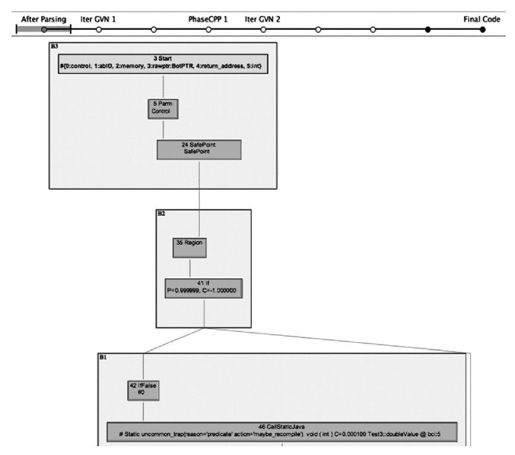
图 11-6 基本块图示(1)
以上几个步骤,反映到Ideal Graph Visualizer的图上,就是如图11-7所示的内容。这样我们要看空循环是否优化,或者何时优化,只要观察代表循环的基本块是否消除,或者何时消除就可以了。
要观察到这一点,可以在Outline面板上右键点击“Difference to current graph”,让软件自动分析指定阶段与当前打开的Ideal图之间的差异,如果基本块被消除了,将会以红色显示。对“After Parsing”和“PhaseIdealLoop 1”阶段的Ideal图进行差异分析,发现在“PhaseIdealLoop 1”阶段循环操作被消除了,如图11-8所示,这也就说明空循环实际上是不会被执行的。
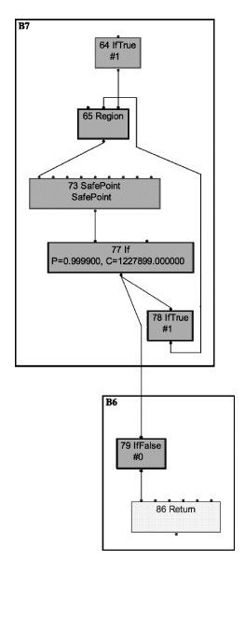
图 11-7 基本块图示(2)
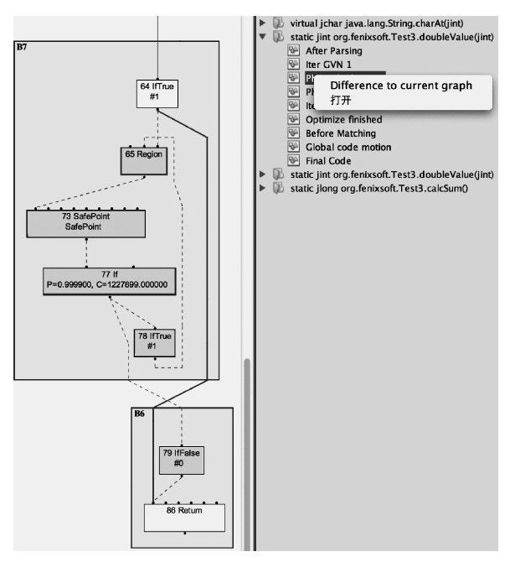
图 11-8 基本块图示(3)
从“After Parsing”阶段开始,一直到最后的“Final Code”阶段,可以看到doubleValue()方法的Ideal图从繁到简的变迁过程,这也是Java虚拟机在尽力优化代码的过程。到了最后的“Final Code”阶段,不仅空循环的开销消除了,许多语言安全和Safepoint轮询的操作也一起消除了,因为编译器判断即使不做这些安全保障,虚拟机也不会受到威胁。
最后提醒一下读者,要输出CFG或IdealGraph文件,需要一个Debug版或FastDebug版的虚拟机支持,Product版的虚拟机无法输出这些文件。
[1]相关信息:http://wikis.sun.com/display/HotSpotInternals/PrintAssembly。
[2]HSDIS的源码可以从以下地址获取:http://hg.openjdk.java.net/jdk7/hotspot/hotspot/file/tip/src/share/tools/hsdis/。另外,相关网站可以下载一个已经编译好了的适合32位80x86平台使用的反汇编适配器,如在ITeye的高级语言虚拟机圈子的共享区(http://hllvm.group.iteye.com/group/share)中可以下载。
