第11链 觉醒中的互联网
虽然互联网是人造系统,但从结构上来看,却更像是一个生态系统。多种观念、多种动机汇聚到一起,在互联网的结构上留下了各自的印记,创造出这个混杂的信息集合。互联网的复杂性恐怕只有人脑才能与之媲美。不过,人类大脑的容量几个世纪以来就稳定不变了,而互联网的大小却一直在以指数级增长,并且丝毫没有减慢的迹象。
保罗·巴兰与最优的抗击打系统
保罗·巴兰(Paul Baran)在宾夕法尼亚大学注册学习他的第一门计算机科学课程时,该课程已经开始一周了。他知道自己错过了第一节课,但并没有过于担忧,反正第一节课也不会讲太多内容。第二次上课的时候他去了,那堂课讲的是布尔代数,这是计算机逻辑背后的数学运算基础。他回忆道:“当时,老师走到黑板前,写下了‘1+1=0’。我环顾整个教室,等着有人来纠正他的这个低级运算错误。结果没有人那么做。于是,我觉得自己可能错过了什么内容。不过,我后来也没有去补课。”但十年后,他重温了该课程。那时他已经做起了毕业后的第四份工作。这次他遇到了另外一个问题:来得太早了。
那时,巴兰不到30岁,刚刚在兰德公司(RAND Corporation)工作了几个月。公司交给巴兰一个艰巨的任务,让他负责开发一个能够在遭受核攻击时继续使用的通信系统。在1959年,如果说苏联的核弹头会从天而降,这绝不只是科幻片,而是确实存在的一种战争威胁。巴兰的雇主是加利福尼亚的一个智囊团体,成立于1946年,主要是为军方的核武器建设提供知识技能服务,在预演战争场景和潜在灾难后果方面拥有大量的专业技术。该公司从事的工作,如预计和详述数百万人会死于核攻击,让公司的媒体形象不是很好,公司通常被冠以核战争狂的头衔。巴兰的任务是开发一个能经受核攻击的通信系统,这和兰德公司的宗旨是吻合的。巴兰对待这份工作非常认真,在十二卷的“兰德公司备忘录”中,他详细描述了当时通信基础设施的脆弱性,并提出了一个更好的方案——互联网。
巴兰看到了20世纪50年代指令系统的脆弱性,这类指令系统隐藏在现有通信网络的拓扑中。考虑到核攻击会破坏掉其爆炸范围内的所有设备,巴兰希望设计出一个系统,使核爆炸范围之外的用户仍然能够保持联系。在考察当时的通信系统时,巴兰看到了三种类型的网络(见图11-1)。巴兰放弃了星形拓扑,他认为:“中心式网络显然是脆弱的,摧毁单个枢纽节点就能破坏终端之间的通信。”巴兰将当时的系统视为“由一组星形网络以更大的星型方式形成的层级结构”,这是对无尺度网络的早期描述。他以惊人的洞察力发现,这种拓扑过于中心化,面对攻击时无法存活。在巴兰的脑子里,理想的架构是一种分布式的网状结构,类似于高速公路系统。这种网状结构中存在足够多的冗余,在某些节点失效后还有替代的路径,使其他节点之间保持联系。
长期以来,关于互联网有一个神话:互联网的设计能够经受苏联的核攻击。没错,巴兰的主要初衷就是要设计出一个能够经受苏联核攻击的系统。但是,他的观点和创见最终被军方完全忽视。如此一来,如今互联网的拓扑和巴兰的愿景几乎就没有什么关系了。不过,从军方到工业界都激烈反对其设计的原因,并不是因为巴兰提倡进行拓扑改变。反对主要针对他的一项提议:将信息分成大小相同,能够独立在网络上传输的数据包。当时的模拟通信系统无法做到这一点。
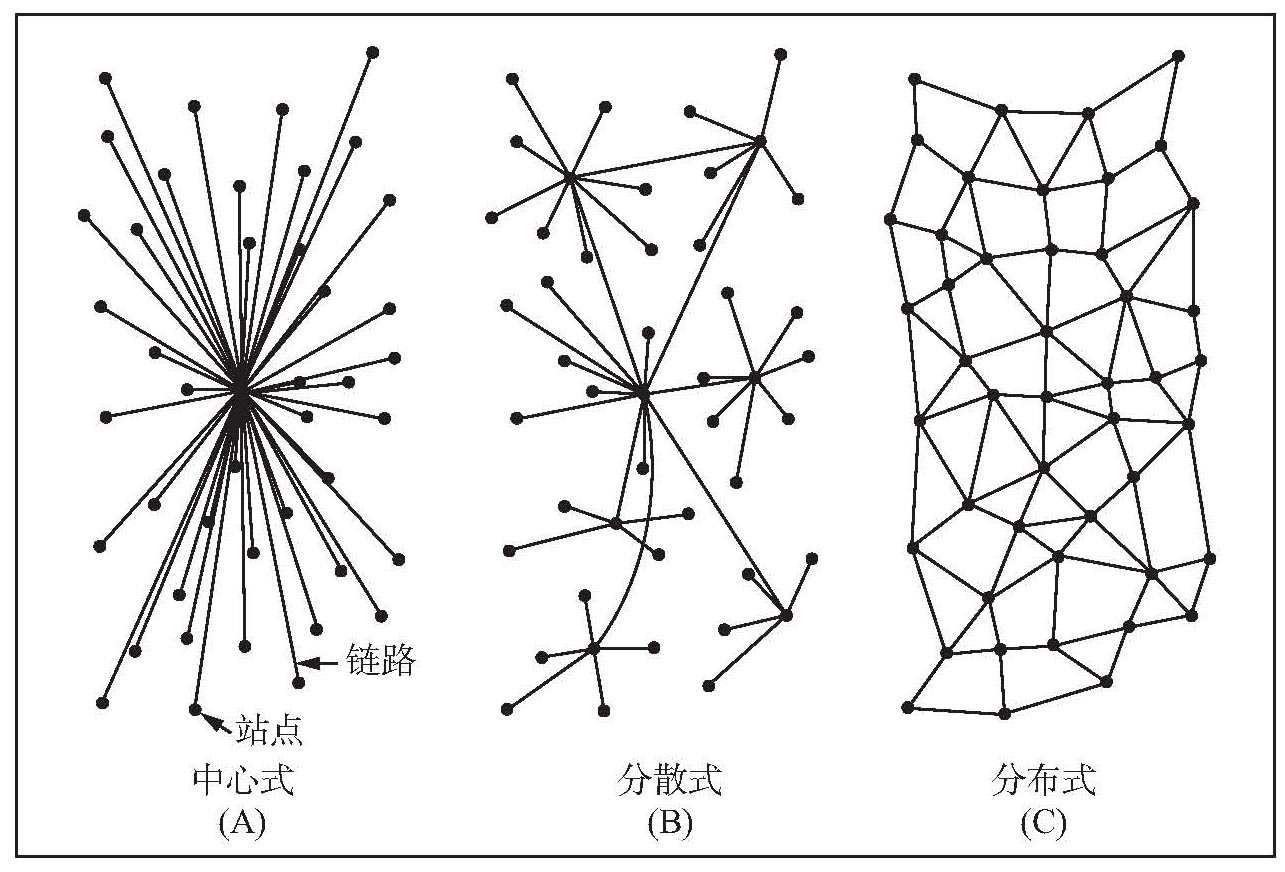
1964年,保罗·巴兰开始思考互联网的最优结构。他建议了三种可能的网络架构——中心式、分散式和分布式,并同时给出了警示:主宰当时通信系统的中心式结构和分散式结构,在面临攻击时是非常脆弱的。他提出,互联网应该设计成分布式网格状架构。
图11-1 保罗·巴兰的网络
因此,他提议将通信系统换成数字系统。对于当时的通信垄断企业美国电话电报公司来说,这种替换是难以接受的。美国电话电报公司的杰克·奥斯特曼(Jack Osterman)一听到巴兰的提议就驳斥道:“首先,这个系统不可能运行起来;其次,即使它能运行,我们也不会傻到去创建一个跟自己竞争的系统。”巴兰的观点,每一步都遭到军方和工业界的反对。直到数年之后,美国国防部高级研究计划署(简称ARPA),在不知道巴兰研究结果的情况下独立地提出了同样的构想,人们才重新认识到当初巴兰提出的建议的价值。不过,这时互联网的发展已经蒸蒸日上了。
链接洞察
理解互联网的拓扑,是开发能够提供快速可靠通信基础设施所需工具和服务的前提。虽然互联网也是人造系统,但却没有中心化的设计。从结构上来看,互联网更像是一个生态系统,而不像瑞士手表。因此,理解互联网不仅仅是工程或数学的问题。在塑造互联网的拓扑中,历史力量发挥了重要作用。多种观念、多种动机汇聚到一起,在互联网的结构上留下了各自的印记,创造出这个混杂的信息集合,留给历史学家和计算机科学家去解读。
将互不兼容的机器连起来——互联网的诞生
ARPA是艾森豪威尔总统为回应苏联发射人类第一颗人造卫星而创立的。最初,ARPA掌控着大多数高级军事研究和开发项目,尤其是反弹道导弹计划和卫星计划。但在美国国家航空航天局接管太空计划后,ARPA的实力大减。
为了竭力争取新的研究项目,ARPA对自身定位进行了调整,转而致力于军事相关的长期研究项目,与由不同的军方机构自己组织的短期开发项目相区别。互联网进入ARPA的视野大约是在1965年或1966年。当时,ARPA的计算项目部主任鲍勃·泰勒(Bob Taylor)突然意识到,联邦政府的资金存在巨大的浪费。
20世纪60年代,ARPA已经开始大量资助计算机研究。计算机研究确实需要大量的投资——当时个人电脑的时代还未到来,每台电脑的价钱动辄几十万,甚至数百万美元。ARPA遍布全国的研究机构拥有数台这样的巨兽。问题是,即使是放置在同一房间中的电脑,也无法相互通信,更不用说利用其他ARPA研究机构的计算能力了。鲍勃·泰勒当时想出了一个绝妙的主意:为了避免浪费,为什么不把这些互不兼容的机器连接起来呢?1966年2月,泰勒将这一想法汇报给ARPA的主任查理·赫尔茨菲尔德(Charlie Herzfeld),主任给他批了100万美元,让他启动这一新的计划。
英国国家物理研究所(Britain's National Physical Laboratory)位于离伦敦不远的特丁顿(Teddington)。该研究所的计算机科学部主任唐纳德·戴维斯(Donald Davies)也想到了计算机互联的主意。戴维斯努力想把自己的想法变成现实,在不知道巴兰早已做过先期研究的情况下,他重新发明了数据包和数据包交换等概念。1967年,在得克萨斯州加特林堡(Gatlinburg)召开的一次学术会议上,他的研究小组向ARPA支持的一个研究项目展示了这些概念。大家突然间都清楚地意识到,通过更高速的线路传输数据包,是创建真正高效通信网络所必不可少的技术。最终,巴兰在10年前提出的想法付诸实践了。从此就有了我们现在所熟知的互联网。
互联网这个词经常用来描述与在线世界有关的一切东西,包括计算机、路由器、光缆甚至万维网。但在本书中,我们仅用它来代表连接计算机的物理基础设施。互联网的出现多亏了ARPA的雄厚资金支持,它是由相互通信的路由器构成的网络,路由器之间的通信依靠保罗·巴兰设想的网络协议来实现。具有讽刺意味的是,当今互联网的每项设计原则几乎都和巴兰最初的设想一致,却不包括那个最根本的指导原则:削弱面对攻击时的脆弱性。只有在军事部门的控制和维持下,巴兰预想的高速公路网似的分布式网络才得以实现。不过,互联网随后便自发地成长起来了。
无法绘制的互联网地图
在计算机科学界,朗讯/贝尔公司(Lucent/Bell)分离出来的Lumeta公司的研究员比尔·切斯维克(Bill Cheswick)是防火墙和计算机安全方面的著名专家。但是公众对他日益熟悉,是因为他和Lumeta公司的哈尔·伯克(Hal Burch)一起绘制了彩色的互联网地图,并通过Peacockmaps.com网站销售。互联网的千禧年地图,描绘了2000年1月1日的互联网拓扑。该地图显示了由路由器和链接构成的密林,是一幅非常优美的网络图,其复杂性恐怕只有人脑才能与之媲美。不过,两者之间有着重大区别:人类大脑的容量几个世纪以来就稳定不变了,但互联网的大小一直在呈指数级增长,并且丝毫没有减慢的迹象。
切斯维克绝不是富有激情的孤独科学家,他任职于一家著名的公司。作为ARPA的继承者,DARPA目前耗资数百万美元资助美国的许多研究组织,进行和切斯维克类似的工作:绘制互联网地图。其中最著名的是互联网数据分析合作协会(the Cooperative Association for Internet Data Analysis;CAIDA),它是加利福尼亚大学圣迭戈分校下属的互联网成像合作组织,其主要目标就是监视互联网方方面面的特性,从流量到拓扑等。在大西洋对岸,英国伦敦大学学院(University College London)高级空间分析中心(the Center for Advanced Spatial Analysis)的研究员马丁·道奇(Martin Dodge)创办了Cybermaps.com网站,这个丰富多彩的网站搜集了大量的互联网可视化地图。
你是否想过给自己的手表、计算机奔腾芯片或每天驾驶去工作的汽车详细地画上一幅图呢?恐怕不会。如果你真的想知道汽车引擎罩下面到底是什么样子,你会与汽车制造商联系,索取汽车的设计蓝图。工程师在制造手表、芯片或汽车的时候,会绘制数百张设计图纸,不仅要将每个部件都详细绘制出来,而且还要将每个部件的位置和相互关系绘制出来。然而,虽然互联网现在已经成为推动美国经济发展的原动力,但我们到现在还没有绘制出互联网的详细地图。自从1995年年初美国国家科学基金会(简称NSF)放弃了对互联网的管理权之后,就没有任何官方机构控制或记录互联网的增长和设计了。
今天,互联网根据需求按照局部的分布式决策演化。从企业到教育机构的任何人,无需得到官方机构的许可,都可以向互联网添加节点和链接。互联网也不是单一的网络,而是多个独立而互联的网络共存运营,包括WNET、vBNS或Abilene。
如果你认为有人能够在必要的时候关闭整个互联网,那你就大错特错了。虽然我们能够说服某个机构关闭其管理的那部分网络,但是任何公司或个人所掌控的网络都只是互联网微不足道的一部分。互联网背后的网络已经变得极其分布式、非中心化和本地化,以至于像绘制互联网地图这样普通的任务都变得不可能完成了。
人类创造的互联网有了自己的生命
绘制互联网的全局图具有重要的现实意义。不知道互联网的拓扑,就不可能设计出更好的工具和服务。在设计目前的互联网协议时,互联网还只是一个小网络,设计时考虑的也只是20世纪70年代的技术和需求。随着网络的增长和新应用的出现,这些协议已经无法满足我们的期望了。事实上,当今互联网的大多数应用,对于当初设计互联网基础设施的人来说,都是无法想象的。例如,电子邮件的产生。
当时,富有冒险精神的黑客雷·汤姆林森(Rag Tomlinson)在马萨诸塞州坎布里奇市一家名为BBN的小咨询公司工作,他尝试修改文件传输协议以传输邮件消息。很长一段时间,他都对自己的突破守口如瓶。后来,在第一次向同事展示时,他警告对方:“不要告诉任何人!因为这不是我们分内的工作。”不过,电子邮件的秘密还是泄露出去,并成为早期互联网上的主要应用之一。
万维网的产生也是如此。互联网的基础设施并不是为万维网准备的,万维网是“成功灾难”的绝佳例子。在设计完全到位之前,新功能的设计就已经进入了现实世界并以空前的速度普及。如今,互联网几乎主要用于访问万维网和收发电子邮件。假如互联网最初的创造者能预见到这些,他们肯定会设计一套完全不同的基础设施,让人们的上网体验更加流畅。然而,我们现在受困于互联网最初的设计,只好克服很大的困难进行技术改造,以适应日新月异的多样性应用和互联网创造性使用带来的需求。
20世纪90年代中期之前,所有的研究都集中于设计新的协议和组件。然而,随后越来越多的研究人员开始问一个出人意料的问题:我们到底创造了什么?虽然完全是人类设计的,但互联网现在有了自己的生命。互联网具有复杂演化系统的所有特性,这使它更像细胞,而不是计算机芯片。许多独立开发的不同组件,共同实现这个复杂系统的功能,系统不仅仅是所有组件的总和。因此,互联网研究人员越来越像探险家,而不是设计师。他们就像是生物学家或生态学家,面对着一个实际上独立于他们而存在的非常复杂的系统。然而,互联网的神秘之处还不止这些。生物学家花了数十年时间才弄清楚蛋白质看起来像什么以及它们之间是如何交互的,但互联网各个组件的细节对于互联网的绘图师而言是一清二楚的。计算机科学家和生物学家都不知道:当我们把各个部分放到一起时,大规模结构是如何出现的?
互联网遵从幂律
加利福尼亚大学伯克利分校研究互联网的国际计算机科学研究中心的计算机科学家维恩·帕克森(Vern Paxon)和莎莉·弗洛伊德(Sally Floyd)在1997年发表了一篇非常有影响力并被大量引用的论文。他们在论文中指出,我们的网络拓扑方面的知识非常有限,这是限制我们更好地理解互联网整体的主要障碍。两年后,同为计算机科学家的希腊三兄弟发表了一项惊人的发现。他们分别是加利福尼亚大学河滨分校的米凯利斯·法鲁托斯(Michalis Faloutsos),多伦多大学的佩特罗斯·法鲁托斯(Petros Faloutsos)和卡内基·梅隆大学的克里斯托斯·法鲁托斯(Christos Faloutsos)。他们发现,互联网路由器的连通性遵循幂律分布。他们在题为《互联网拓扑的幂律关系》(On Power-Law Relationship of the Internet Topology)的研讨会论文中指出,由各种路由器通过物理线路连接起来的互联网,是一个无尺度网络。他们的发现传递了一个简单的信息,这个信息很快传遍了整个学术界:1999年之前用以建模互联网结构的所有工具都是错误的,因为这些工具都是基于随机网络的。
法鲁托斯兄弟并不知道,人们在万维网的拓扑中也发现了同样的幂律分布。将这些发现综合起来看,法鲁托斯兄弟的发现具有了新的意义:把互联网从随机网络世界中剥离出来,放到无尺度拓扑的缤纷世界里。这非常出乎人们的意料。互联网毕竟是由物理链路和路由器构成的,而它们都是硬件。这些价格昂贵且笨重的铜线和光缆遵循的规律,怎么会和人们建立社会联系或者在网页中添加URL一样呢?
互联网中的“权力制衡”
1969年10月,查理·克兰(Charley Kline)接到任务,首次通过普通电话线在计算机之间传递信息。他当时是莱昂纳多·科莱恩若克(Lenard Kleinrock)的加州大学洛杉矶分校实验室的一名程序员。他参与了一个项目,尝试连接到位于斯坦福大学的,当时唯一的互联网节点。建立连接后,克莱恩开始输入“login”。他输入字母“l”并收到了斯坦福那边确认收到该字母的反馈。他接着输入“o”,同样收到了正确的反馈。随后,他继续输入“g”。然而,这个新系统还应对不了如此多的信息,计算机死机了,连接也中断了。
连接很快就重新建立。当加州大学洛杉矶分校和斯坦福的计算机节点之间建立起稳定的连接后,许多其他节点加入了进来。
据《互联网:从神话到现实》(A Brief History of the Future)的作者约翰·诺顿(John Naughton)所说,加利福尼亚大学圣巴巴拉分校和犹他大学分别在1969年11月和12月建成了第3个和第4个节点。1970年年初,马萨诸塞州的一家咨询公司BBN拥有了第5个节点,同时建成了第一条跨越全国的回路——这是洛杉矶的计算机和波士顿BBN的计算机之间的第二条线路。截至1970年夏天,第6、第7、第8、第9个节点分别部署在麻省理工学院、兰德公司、系统开发公司(System Development Corporation)和哈佛大学。截至1971年年底,互联网上共有15个节点;到1972年年底,共有37个节点。
诺顿这样描述道:“互联网展开了羽翼——或者,假如你是个本性多疑的人,会说它张开了魔爪。”
你可能已经注意到,互联网遵循着生长网络所具有的经典模式。如今,互联网在诞生20余年后,依然在逐个节点地扩张着——这是无尺度拓扑出现的第一个必要条件。然而,第二个条件,即偏好连接,却显得更加微妙和难以琢磨。为什么人们会将计算机连接到任意路由器上,而不是只连接到最近的路由器上呢?毕竟,铺设更长的电缆需要更高的成本。
事实证明,电缆长度并不是决定互联网增长或停滞的限制性因素。当某个机构决定将它的计算机连接到互联网时,他们只考虑一个问题:通信成本。带宽是指链路每秒钟能传输的比特数,考虑到带宽,距离最近的节点往往不是最佳选择。多走几公里,有可能连接到更快的路由器。
路由器的带宽越大,越有可能拥有更多的链接。因此,在选择一个好位置进行连接时,网络工程师不免会倾向于选择连接度更大的接入点。这个简单的效应便是偏好连接的可能来源之一。我们虽然不确定这是否是唯一的原因,但是互联网中毋庸置疑地出现了偏好连接。在我的研究组工作的宋勋毓(Soon-Hyung Yook)和郑浩雄,在对比有几个月时间间隔的互联网地图时率先发现了这一现象。通过展示互联网如何逐个节点生长,他们找到了定量的证据:和只有少数链接的节点相比,链接数多的节点将来会得到更多的链接。
生长机制和偏好连接应该足以解释法罗托斯兄弟发现的无尺度拓扑了。然而,在互联网上,情况还要稍微复杂一些。距离虽然不是首要考虑的因素,但它确实会产生影响。毫无疑问,铺设2公里光缆要比铺设半公里光缆昂贵。我们还要考虑到,在互联网上,节点出现的位置也不是随机的。路由器只会添加在有需求的地方,而这种需求取决于想要使用互联网的人数。因此,人口密度和互联网节点的密度之间存在着很强的关联性。在北美的互联网地图上,路由器的分布形成一个分形集合,这是20世纪70年代伯努瓦·曼德尔布罗(Benoit Mandelbrot)发现的一种自相似的数学对象。因此,在建模互联网时,我们必须同时考虑生长机制、偏好连接、距离依赖和潜在分形结构的相互作用。
链接洞察
每个因素在极端情况下都会破坏无尺度拓扑。例如,在决定连接到哪里时,如果线路长度是首要考虑,最终形成的网络会具有指数度分布,和高速公路系统的拓扑非常相似。但令人吃惊的是,这些共存的机制巧妙地相互平衡,维系着互联网的无尺度特性。这种平衡正是互联网的阿喀琉斯之踵。
无法预料的危险和脆弱威胁互联世界
总部位于弗吉尼亚州麦克莱恩(McLean)的小网络服务提供商MAI网络服务公司(MAI Network Services)通过它拥有的一些高速互联网路由器,连接到斯普林特(Sprint)和UUNet的巨大网络中。1997年4月25日是一个星期五,这天早上MAI更新了路由器的路由表。路由器通过将数据包上的地址与路由表进行匹配,将接收到的数据包发送到目的地。这些路由表就是互联网上的路线图。由于网络拓扑在持续变化,路由表也会周期性地更新。早上8:30,MAI向自己的路由器广播了更新后的路由信息。由于一个不正确的配置,更新超出了MAI所拥有的路由器范围,重写了斯普林特和UUNet大量路由器的路由表。这意味着,这些路由器会将所有的数据流量发送到MAI的几个路由器上。
这就像水从垮掉的大坝中涌出,大水所经之处横扫一切。MAI惊恐地看着所有的互联网流量都重新定向到了MAI。由于根本不具备处理这种信息洪流的能力,MAI变成了信息黑洞,以惊人的速率吞噬着数据包。45分钟后,MAI公司被迫停止服务以避免灾难。与此同时,互联网服务提供商无助地看着它们的数据流量流向因MAI错误重置而产生的黑洞。在人工修改了所有的路由表之后,斯普林特公司才恢复正常。受该问题影响的很多其他大大小小的互联网服务提供商也是通过人工修改路由表的方式恢复正常的。
由于问题得到了迅速解决,而互联网当时的规模还不大,整个世界对这个事件的关注度并不高。然而,这一事件向我们生动地展示了错误在网络上传输的速度:错误配置的路由表在发布数分钟后,就已经传播到了几个大型网络上,触发了级联失效的一个经典案例。
在设计互联网原型时,保罗·巴兰脑海里有着非常明确的假想敌。他预计苏联的核弹头会集中打击情报和军事总部,从而造成信息和通信能力的完全丧失。无论是他还是互联网的缔造者们,都没有预料到有朝一日全世界任何国家的人都可以访问互联网这一基础设施。许多年来,美国一直拒绝和敌对国共享这项技术。对这一点,我有亲身体会。广遭诟病的CO-COM名单将匈牙利官方地排除在互联网之外,这种局面一直持续到柏林墙倒塌才得以改变。然而,互联网的传染性太强,人为设置的障碍根本阻碍不了它的传播。早在禁令解除之前,许多东欧大学里的老师就开始使用电子邮件和西方同行进行联络,这多亏了本地系统管理员的智慧。如今,地球上几乎所有的国家都连接到了互联网。这种公开访问政策同时也给互联网带来了无法预料的危险和脆弱,日益威胁到我们这个互联的世界。
美国电话电报公司拥有美国最繁忙的其中一个节点,是一个高度戒备的秘密机构,位于伊利诺伊州的绍姆堡(Schaumburg),在芝加哥郊区。这个节点和一些同样严加保护的关键节点,给人们造成一种错误的印象,即互联网不会因外来的攻击而瘫痪。然而,随着对网络架构和协议之间相互作用的日益理解,我们的面前出现了一幅完全不同的图景。少数几个训练有素的骇客,在半小时之内,就能从世界任何地方破坏该网络。有很多方式可以做到这一点,或者侵入运行关键路由器的计算机,或者对最繁忙的节点发起拒绝服务攻击。
2001年夏天,红色代码(Code Red)蠕虫像病毒一样广为传播,感染了数十万台计算机。这个例子很好地说明了,利用技术可以达到很大程度的破坏。刚开始,红色代码看上去似乎是一种无害的病毒,因为它根本不危害宿主。但是在休眠多日之后,它会突然将所有被感染的电脑变为僵尸,同时向白宫网站发送大量的数据包。红色代码证明了自动激活病毒可以具有何等的破坏力。更为复杂的病毒变种则可能造成史无前例的破坏。破坏少数主要节点不足以让整个网络变成碎片,但是,将流量重定向到较小的节点造成的路由器级联失效,会造成网络的瘫痪。
大多数掌握攻击技术的黑客,都不愿意让互联网整体出局。一次成功的攻击就会让他们失去钟爱的“玩具”,让他们自己也无法上网了。因此,针对整个互联网采取的大规模攻击绝不会来自真正的黑客。但是,互联网很容易成为邪恶国家和恐怖分子的目标,而理解互联网的拓扑将有助于我们保护它。
寄生计算,让所有的计算机都为你工作
2001年8月30日,就在我们的最新研究成果发表在《自然》杂志上的这一天,美国国家公共广播电台(National Public Radio)播出了一个5分钟的节目,介绍了我们的最新研究。虽然我们的研究成果受到大众媒体的宣传已经不是第一次了,然而,第二天早上看到我们项目网站的访问量计数器时,我们仍感到难以置信。一夜之间,我们网站的访问量就突破了10000。我开始意识到,这次的情况不同寻常。我的电子邮箱也塞满了邮件,大多数邮件的语气都是正面的。不过,也有一些比较吓人。
“离我电脑远点!”防御程序开发公司的高级管理人员这样写道。另一个人说道:“我不愿意看到又一个东欧的计算机科学家被美国联邦政府投入大牢。”他提醒我注意,最近有一个俄罗斯黑客被美国当局抓获了。“(我)要求你向我们保证,我们的网络中没有任何电脑曾经或正在被你所指的软件当做攻击目标。”挪威一家公司的首席执行官这么说道。“我提醒阁下,任何人未经授权使用以下IP地址都是非法的,并可能导致相应的法律行动和索求赔偿。”
一篇原本是写给研究人员看的,而且是发表在最高等级的科学期刊上的学术论文,为什么会带来如此激烈和迅速的反应呢?
2000年年初,圣母大学政府及国际研究系的系主任詹姆斯·麦克亚当斯(James McAdams)想到一个好主意。他召集了来自经济、物理、法律、化学工程、计算机科学和亚洲语言学等不同院系的七名教授,在一个非正式的场合探讨互联网对人类生活各个方面的影响,话题涉及民主、教学等方面。我们这些人每个月聚在一起吃一次午饭或早饭,大家轮流定题目、布置阅读材料,内容从电子法律到万维网上的社会运动等。在一次聚会上,计算机科学家杰伊·布罗克曼提到整个万维网可以视为一台大计算机。他的说法让我一时间迷惑不解。没错,互联网的确是由计算机构成的,计算机之间可以交换网页和电子邮件。但是,这种有限的、由用户驱动的通信还不能使万维网变成一台独立的电脑。
要想改变这一点,我们能做些什么呢?我们是否能让一台计算机驱动其他计算机的行动呢?作为开始,我们是否能让网络上的所有计算机都为我而计算呢?这个问题很有意思,我非常愿意参与探讨。最后,我们组成了一个研究小组来解决这一问题。除了我和布罗克曼之外,文森特·弗里(Vincent Freeh)和郑浩雄也加入了进来。弗里是互联网协议专家,而郑浩雄是我的长期合作者。在对计算机如何通信进行了多次讨论和调研之后,我们提出了一个简单但颇有争议的观点:寄生计算。
通过互联网发送信息是一个复杂的过程,需要多层复杂协议进行管理。例如,在点击了网页上的URL地址后,你的请求会被分成很小的数据包,传送给存储该网页的电脑。到达那台电脑后,数据包被重构和解释,并让远程电脑发送你所请求的网页给你。因此,像单击URL地址这样简单动作的背后,其实包含了一连串复杂的计算。寄生计算就是基于这一原理,宿主计算机利用计算机之间的通信让其他计算机参与计算。为了实现这一目标,我们把复杂的计算问题伪装成合法的互联网请求。计算机接收到数据包后会执行例行检查,确认数据包在传输过程中没有遭到破坏。在进行这些运算的同时,这些计算机也解决了我们感兴趣的问题,因为这些问题编码在数据包内。
寄生计算的实现表明,我们能够让千里之外的计算机为我们进行计算。互联网这一根本上的脆弱性,带来了一连串的计算、伦理和法律问题。要是有人改进了我们的寄生计算方法,使其变得足够高效,并开始大规模使用这种计算,后果会怎样呢?谁拥有这种通过互联网让所有人使用的计算资源呢?这是否意味着互联网电脑的诞生?沿着这条路走下去,会不会形成新的智能生命呢?
寄生计算发展到极端,就意味着未来的电脑可以按需交换信息和服务。目前,芯片内部的通信速度大大高于互联网上信息的传送速度。随着宽带的发展,它们之间的差距会缩小。很快,想办法利用其他电脑的剩余计算资源来解决单个电脑或研究小组无法解决的复杂问题就显得顺理成章了。加州大学伯克里分校的SETI@home(在家中进行外星智能探索)项目组正在进行小规模的网络计算实验。该项目利用上百万台个人电脑的剩余时间和资源来搜索外星人。
SETI项目要求人们自愿参加。大多数人都太懒了,不愿意持之以恒地进行下去。但如果网络协议允许这种服务和信息交换成为常态,那么大量的闲置资源就能得以利用。沿着这条路走下去,互联网就有可能脱离人类的监管,因为它变得能够管理大多数的信息和资源,来解决待定的问题。这也会对互联网的拓扑结构产生无法预料的影响,使得自组织结构有可能发挥更大的作用。可以想象,未来某个时候,大家通过浏览器得到某个问题的答案时,无论是你还是你的计算机,都不知道答案是从哪里来的。其实这也很容易理解:你知道字母A存储在大脑的哪个位置吗?
互联网何时会拥有自我意识
人类的皮肤是一项工程杰作。它能够感知温度变化和空气流动;它可以识别物体的大小和材质。想要具备这些能力,需要大量有机组织在一起的化学传感器通过神经系统交换信息。尼尔·格罗斯(Neil Gross)在《商务周刊》(Business Week)中撰文指出,地球表面也在形成一层具有类似灵敏度的皮肤。数以百万计的测量设备,包括摄像头、话筒、自动调温器、温度计量器、光线和流量传感器、环境污染检测仪等,在各个地方冒出来,并将信息传送到越来越快、越来越复杂的计算机中。专家预言,到2010年,地球上平均每个人将拥有约10000个遥感装置。这个数字本身并不是特别大——我们毕竟已经使用传感器很久了,从超市的监控摄像头,到人行道上控制十字路口交通信号灯的汽车监测器等。真正的变革是,各种传感器第一次把信息传送给单个集成系统进行处理。联网手机很快将超过30亿部,联网计算机则会接近160亿台,这其中包括嵌入电烤箱、服装设计中的计算机。地球表面的微型传感器会监视一切,从环境到公路甚至人的身体。更重要的是,它们都是连在一起的。我们的星球正在演变成一个由数十亿台联网的处理器和传感器构成的巨型计算机。许多人关心的问题是,这台计算机何时会具有自我意识?一台思维速度大大超过人脑的思维机器,何时会自发地从数十亿个互相连接的模块中产生?
我们无法预言互联网何时会具有自我意识,但是它显然已经具有了自己的生命。它遵循着自然界创建自身网络时同样的规则,以空前的速度成长和演化。事实上,互联网和生物体有许多相似之处。正如细胞中发生的数百万次化学反应一样,每天有数十亿字节的信息沿着互联网上的链接传输。让我们感到惊讶的是,有些信息很难被找到。这把我们带到了另一个网络:万维网。
