第12链 分裂的万维网
万维网远非由节点和链接组成的一个匀质的海洋,它分裂成四块大陆,其中每块大陆上又有许多的村庄和城市,它们以重叠社区的形式出现。目前,我们还远不了解万维网的这种精细结构。但有许多的动力,如商业利益、科学上的好奇等,它们不断激励着我们去更好地了解万维网。
万维网的结构影响一切
小时候我常读科幻作品,它们使我相信在世纪之交,类似人类的机器人将能够处理所有普通任务。然而,进入新的千禧年时,这样谦卑的机器人服务并没有出现。或者,机器人服务已经悄悄地出现了。但它们没有C-3PO[1]那样闪亮耀眼的外表,也不能够发出像R2-D2[2]的愉悦哨声。它们明智地避开了与我们争抢这个拥挤的欧几里得空间——在这个空间里,真实的物质财产是非常短缺的。21世纪的机器人是非物质的,无形的。它们存在于虚拟的世界里,这使得它们能够轻易地从一块大陆跨越到另一块大陆。盯着电脑屏幕是无法发现这些机器人的。但是,如果你花些时间去仔细检查记录你页面访问情况的电脑日志,你就能发现它们的踪迹。你将会看到,它们不知疲倦地执行着人们设计的最不讨喜且最无聊的一种工作:阅读并索引上百万的网页。
设计这些机器人的初衷在于获得速度与效率——它们像万维网上的跑车,迅速地扫描着一个个链接,嗅着它们经过的路径上的一切事物。这些万维网络上的战士们使得郑浩雄编写的用于绘制万维网的小甲虫黯然失色,但我依旧很喜欢它,就像一个人对第一辆买得起的汽车的喜欢。尽管它基本上每隔一天就死机,还经常大意地去抓取拒绝机器人抓取的网页,并因此造成麻烦。
我们很快意识到,绘制整个万维网的地图超过了我们小小的搜索引擎的能力范围,是一个不可能实现的梦。但经过不断的潜行,尽管时常中断,它采回来的近300000个网页,足以让我们发现一个无尺度网络。我们在这个时候就关闭它可能为时过早,如果让它继续带回更多的网络样本,我们可能会发现复杂网络的其他特征,而这些特征在小的样本中并不明显。相比实验所得结果,搜索引擎能够看到万维网更多的部分。
链接洞察
研究这些巨大的样本的学者们有一些令人着迷的发现。他们发现万维网是碎片化分成多块大陆和社区的,这限制且决定了我们在网络世界中的行为。但自相矛盾的是,他们也告诉我们这里有未曾被发现的区域,万维网中有大片的区域从未有机器人访问过。最重要的是,我们认识到,万维网的结构对任何东西都有影响——从网上冲浪到民主政治。
颠覆人们对万维网上可达信息的认识
几年前,我们以为自己知道关于万维网的一切,经常会听到诸如“如果你不能用Alta Vista找到它,那它很可能不在这里”,或“HotBot是首个能够索引和搜索整个万维网的搜索机器人”的评论。我们相信搜索引擎能够覆盖和传递万维网。然而这一切在1998年4月突然改变了。一家大搜索引擎公司的发言人表示:“我们倾向于索引高质量的站点,而不是索引一大堆的站点。”还有一些公司更进一步声明:“有许多网页不值得索引。”发生了什么事情?这个突然的模式转移是1998年4月3日发表在《科学》杂志上的一篇研究论文激起的。它仅有的3页彻底颠覆了我们对万维网上可达信息的认识。
史蒂夫·劳伦斯和李·贾伦斯(Lee Giles)从来没想过去破坏搜索引擎的可信性。他们在新泽西州普林斯顿的NEC研究机构工作,他们对机器学习感兴趣——计算机科学下面的一个新兴热门子领域。他们构建了一个元搜索引擎,即一个名叫Inquirus的机器人,它能够查询所有的主搜索引擎上拥有某一给定查询串的文档。在研究过程中他们意识到,他们的机器人能做更多的事情,它可以帮助他们估计万维网的规模。
Inquirus询问数个搜索引擎并列出所有包含某个给定单词的文档,如“水晶”。如果每个搜索引擎都访问和索引了整个万维网,那它们肯定会返回相同的文档列表。但在实际中,不同搜索引擎返回的列表极少有完全相同的。尽管如此,列表内容总是有显著的重叠。
比如说,AltaVista发现的包括“水晶”的1000个文档中,有343个也出现在HotBot的列表中。用重叠的文档数除以AltaVista返回的文档总数就可以得到HotBot在万维网络中覆盖到的范围。由于HotBot号称索引了1.1亿个页面,所以在1997年12月时,NEC小组估计万维网有近110000000/0.343,即大约3.2亿个文档。这个数量放在今天来看并不大,但在1997年,这个值是当时对万维网规模最精确估计的两倍以上。
链接洞察
1998年以前,搜索引擎告诉我们的有关万维网大小的一切我们都信以为真。毕竟,它们应该知道这一点。劳伦斯和贾伦斯的研究具有里程碑意义,它将万维网变成科学查询的目标——一个能够而且必须采用系统性的、可重现的方法进行研究的东西。但他们有关搜索引擎映射万维网能力的发现却令我们无法为此欢呼。
最多不一定最好
NEC1997年的研究工作表明,HotBot搜集了数量最多的文档,是覆盖最全面的引擎。这对该公司而言是个大好消息。HotBot的市场总监戴维·普里查德(David Pritchard)自豪地说:“我们是最大的索引,我们看到这个报告毫不吃惊。”好吧,其实他们有些吃惊。坏消息是HotBot仅覆盖了整个互联网的34%。这也就是说,有66%的网页是它看不到的。当时最流行的搜索引擎AltaVista被排在第2位,因为它的机器人只能够索引到28%。还有一些搜索引擎,比如Lycos,只抓取到了少得可怜的2%,它们的反应是可以预测的。“坦白地说,我对这类报告并没有太多的信心。我们关注的不是数量,而是质量。”拉吉夫·马瑟(Rajive Mathur),Lycos公司的资深产品经理这样说道。
人们本以为,NEC的研究结果会促使这些搜索引擎增加它们的覆盖率,但实际上并没有。一年过去了,1999年2月,劳伦斯和贾伦斯再次测量并且发现,万维网的规模增长了一倍还多,膨胀到8亿文档,但搜索引擎却跟不上这个增长速度。实际上,它们的覆盖率更低了。这次Northern Light排在首位,但仅覆盖了16%的万维网。HotBot和AltaVista丢失了重要的领地:它们的覆盖率分别下降至11%和15%。Google仅索引了7.8%。加在一起,在1999年,搜索引擎覆盖了全部万维网的约40%。这意味着,与你的查询相关的10个页面中有6个从来不会被任何搜索引擎返回。简单来说,这些搜索引擎从来就没见过它们。
最终,NEC的研究引发了搜索引擎之间一场激烈的竞争。规模突然变得有意义了。AltaVista和FAST运行的新搜索引擎(网址是Alltheweb.com,公司的目标显而易见)之间展开了一场有关领地开发的竞争。2000年1月,Alltheweb.com打破了3亿个页面的目标。AltaVista紧跟其后。到了2000年6月,乳臭未干的Google成为一个重要的竞争者,它打破了5亿的目标。Inktomi不久后也达到了该目标,同时还有另一个新人,WebTop.com。2001年6月,Google又创造了一个新纪录,第一次达到了令人惊讶的覆盖10亿个文档的目标。
直到现在Google仍保持领先。致力于覆盖整个万维网的网站Alltheweb.com排在第二,索引了超过6亿的文档,随后的是AltaVista,5.5亿。搜索引擎做得越来越好。这是个非常好的新闻,只是存在一个问题:万维网增长得更快了。
绝大部分搜索引擎并不试图去索引整个万维网。原因很简单:覆盖最多文档的搜索引擎不一定是最好的。可以确信的是,如果你在寻找最难找到的信息,具有最大覆盖率的搜索引擎是你最好的选择。但如果你想搜索时下最流行的话题,一个更大的索引并不一定能提供更好的结果。大部分人已经被进行简单查询时,搜索引擎返回的成千上万的页面所淹没,他们当然不希望日后还要面对上百万个结果。因此,在一个确定的点上,提高算法性能以从搜索引擎现有的巨大数据库中找到最好的页面,比进一步网罗万维网更为有利。
链接洞察
无论是个人还是机器人浏览互联网,经济刺激(或缺乏此类刺激)都不是唯一的限制。万维网的拓扑限制了我们的能力,使我们无法看到其上所有事物。万维网是一个无尺度网络,由一些拥有大量链接的交换机和节点主宰。但是,我们将会看到,这个无尺度的拓扑与大量的小尺度结构并存,这些小尺度结构严重地限制了我们仅通过简单点击链接就能够探索到的范围。
万维网上的四块“大陆”
尽管万维网上有10亿个文档,但十九度分隔说明万维网是易导航的。它既大又小。不过,万维网背后的小世界网络有点让人产生误解。如果两个文档之间存在一条路径,那么这条路径往往很短。但在实际中,并非所有页面之间都是互通的。从任意页面出发,我们仅能浏览全部文档的24%。剩余的部分我们看不到,也无法通过浏览到达。
出现这一结果主要是因为万维网是有向网络,而这是由一些技术方面的原因决定的。换句话说,对于一个给定的URL,我们只能朝一个方向前进。如果有向网络中的两个节点间不存在有向路径,那你就不能通过其他节点使这两个节点相连。
例如,如果你想从节点A到达节点D,你可以从节点A出发,然后走到节点B,节点B能链接到节点C,而节点C又有指向节点D的链接。但你不能够倒回来走。在无向网络中,一条边上可以双向跳转,存在一条A→B→C→D的路径意味着从节点D到节点A的最短路径正是倒过来的那条,即D→C→B→A。但在有向网络中,逆向路径却不一定存在。更可能出现的情况是,你需要沿着一条不同的路径才能返回节点A:从节点D出发,你可能要访问许多中间节点才能回到节点A。
万维网中到处都是这类不相交的有向路径。它们本质上决定了万维网的导航性能。
有向网络并非一种全新的网络类型:不管网络是无尺度的还是随机的,链接都既可以是有向的,也可以是无向的。到目前为止,我们涉及的网络大部分都是无向的。实际上,大部分网络都是无向的,如社会网络、蛋白质作用网络等。但也有一些网络是有向的,如万维网、食物链网络等。这种有向性对网络的拓扑结构产生了影响。在万维网中,远景公司(AltaVista)的安德烈·布罗德(Andrei Broder)以及来自IBM和康柏的合作者们首次分析了这些影响。他们研究了一个2亿节点的样本,这一数量约为1999年全部互联网页面的1/5。他们的测量表明,有向性最重要的影响结果是万维网并非一个单一匀质的网络。实际上,万维网分裂成四块主要的大陆(见图12-1),若想实现导航,我们要在每块大陆上遵循不同的交通规则。
第一块大陆包括了全部万维网页面的1/4。该部分通常被称为中央核心(central core),囊括了所有的主流网站,如雅虎、美国有线电视新闻网等。它最突出的特点是极易导航,因为隶属于它的任意两个文档之间都存在一条路径。这并不是说任意两个节点间都有一条直接的链接,而是指任意两个节点之间都存在一条路径,允许你浏览至任意节点。
第二块和第三块大陆被称为IN大陆和OUT大陆,这两块大陆的规模与中央核心一样,但导航很困难。从IN大陆中的页面出发你能够到达中央核心,但从中央核心没有路径能让你返回IN陆地。与这种情况相反,从中央核心出发很容易就能到达属于OUT大陆的节点,但一旦离开了中央核心,就不存在让你返回去的链接。OUT大陆上主要是公司网站,它们能方便地从外部进入,然而一旦你进入了,就没有路径退出去。第四块大陆由卷须(tendrils)和分散的岛屿组成。这些岛屿是由仅存在内部链接的网页组成的孤立组,无法从中央核心到达,也没有到达中央核心的链接。有一些孤立组包含成千上万个网络文档。近四分之一的万维网文档都存在于这样的孤岛或卷须上。通常来说,一个页面在万维网上的位置与该页面的内容并无多少关系,主要取决于它的关系,即与其他文档之间的出、入链接情况。
这四块大陆严重地限制了万维网的可导航性。我们能够浏览到多远取决于我们从哪里出发。从一个属于中央核心的节点出发,我们能够到达所有属于这个主要大陆的页面。然而,无论我们点击多少次,始终有近一半的万维网无法看到,因为IN大陆和孤岛不能由中央核心到达。如果走到中央核心之外,到达了OUT大陆,我们不久就会走进一条死胡同。如果从一个卷须或孤岛出发,万维网将显得很微小,因为我们仅能够到达同一个岛屿上的其他文档。如果你的网页在一个孤岛上,搜索引擎永远都不能发现它,除非你把你的URL地址提交给它们。
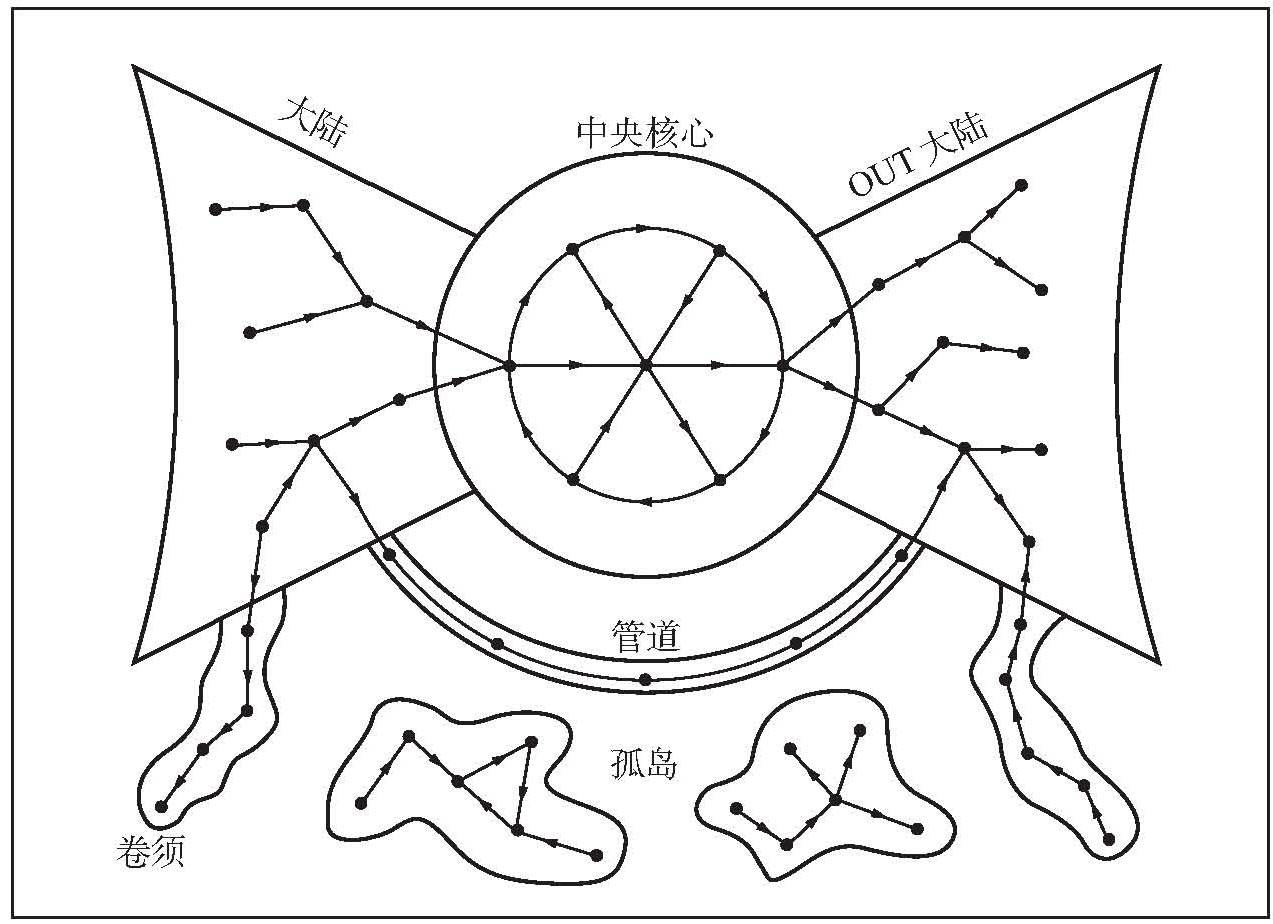
像万维网这样的有向网络会自然地分隔成几块易识别的大陆区域。在中央核心,任意两节点间均可达。对IN大陆中的节点,跟随它们的链接最终会让你回到中央核心,但从中央核心出发你无法回到IN大陆。正好相反的是,OUT大陆中的所有节点都能够从中央核心区域到达,但你一旦到达了,就无法回到中央核心。最后,有管道直接连接了IN大陆至OUT大陆,还有些节点形成了卷须,仅与IN大陆和OUT大陆相连,还有少量节点形成了孤岛,它们无法通过其他节点访问到。
图12-1 有向网络图中的大陆
因此,我们绘制整个万维网的能力并不仅受资源或经济动机的影响。链接的有向性创造了一个由四块主要大陆主导的极度碎片化的万维网。搜索引擎能很容易地绘制出近一半的内容,即互相通连的区域和OUT大陆,因为只要从人们经常访问的中央核心的任意节点出发,就能很容易地定位到属于它们的所有节点。然而,由孤岛和IN大陆组成的万维网的另一半,则无助地孤立着。无论机器人多么努力,都找不到其上的文档。这也正是大部分搜索引擎允许你提交自己网站的地址的原因。如果你这么做了,它们就能从该地址抓取网页,并潜在地发现链向它们从未到达过的万维网区域的链接。但如果你不愿提供这个信息,你的网页将继续在网络上隐姓埋名。
这个分散的结构会一直存在下去吗?还是随着万维网的演化和增长,四块大陆最终会融合成一个任意节点都相互连通的核心?答案很简单:只要链接仍是有向的,这样的同质化就永远不会发生。这些大陆的存在并不是万维网独有的特点,它们存在于所有的有向网络中。有助于我们获取科学知识的引文网络就是一个例子。一篇科学论文往往引用与工作相关的其他论文。某篇数学论文往往会引用数学领域研究类似问题的其他文章,极偶然的,也可能会引用一篇生物或物理论文,用于说明所获得结果的应用性。因此,所有的科学出版物都是科学论文引用网的一部分。这些链接都是有向的。实际上,根据本书后面的参考文献你能找到所有被引用的文章,但这些文章中没有一篇能使你找到这本书,因为它们没有引用这本书。引文网络是一个非常特殊的有向网络,它的IN大陆和OUT大陆反映了文章的历史顺序,而且中央区域即便存在也非常小。自然界中还存在一些有向网络。食物链网络中,物种之间由捕食关系链接在一起。这些网络的链接极少是双向的:比如狮子吃羚羊,但反之则不行。
链接洞察
最后的结果是,所有的有向网络都会分裂为相同的四块大陆。它们的存在并没有反映万维网的任何组织规律。不管网络是随机的还是无尺度的,只要链接是有向的,大陆就会存在。最近,葡萄牙波尔图大学的谢尔盖·多洛戈切夫(Sergey Dorogovstev),约瑟·门德斯(Jose Mendes)和A.N.萨姆金(A.N.Samukhin)证明了这一点。他们指出,这些大陆的规模和结构能够解析地预测出来。显然,这些大陆的相对规模会随着网络的实际属性而变化。然而,这些结果表明,无论万维网变得多么复杂和庞大,这些大陆都会继续存在。
万维网上的社区
2000年6月,芝加哥的一位法律教授卡斯·桑斯坦(Cass Sustein)随机调查了60个政治网站,发现其中仅有15%的站点链接到与它们观点对立的站点。反之,有多达60%的站点拥有指向观点相似的网页的链接。一项关注万维网上民主言论的研究得到了一个相似的结论:仅有约15%的网页提供了指向对立观点网页的链接。桑斯坦担心,通过限制到达对立观点,正在涌现的网络世界鼓励了隔离和社会分化。但实际上,万维网上的社会和政治孤立背后的机制是自我加强的,它们还会改变万维网的拓扑结构,隔离网络世界。因此,四块大陆并不是万维网上唯一的孤立结构。在一个更小的尺度上,这些大陆上存在许多活跃的村庄和城市。它们是因某个共同的想法、爱好或习惯而形成的基于共同兴趣的社区。爵士爱好者就形成了一个良好的网络社区,观鸟爱好者也一样,东欧的宗教基本教义派和美国的与他们思想类似的人们共享虚拟空间,欧洲的反全球化活动人士和他们在日本的同伴一起联合进行战略协调和活动。
社区是人类社会历史发展的重要组件。格兰诺维特提出的“朋友圈”指出了这一事实,这类朋友圈正是社区构建的基石。然而,社区成员没有意识到的是,这类社区越来越多地被记录在万维网拓扑结构中。数字化生活带来的一个副作用是我们的信仰和从属关系是公开可获得的。每一次链接到一个网页,我们都指出了它与我们求知欲的关联。因此,一个热心的观鸟爱好者能带我们去其他类似的网站,从而使我们能绘制出观鸟爱好者的社区。
识别出这样的基于网络的社区具有巨大的潜在应用价值:
找到跑车爱好者的社区,汽车公司就能最有效地推销他们的新车型,如通过在这个社区的数个枢纽节点上放置广告。
艾滋病活动人士能够利用社区知识来组织调动起那些关心疾病的人,把他们塑造成强有力的游说人士和活动团体。
民族节日的组织者可以利用网络上种族相关的社区信息来宣传最近的活动,以及发展基层组织。
但问题是,网上有超过10亿个页面,我们能在这么巨大的万维网上准确找到社区吗?
1964年,美国联邦最高法院大法官波特·斯图加特(Potter Stewart)说了一句非常著名的话:“我现在并不能给色情下一个定义,而且可能我以后都无法成功给出一个明确的定义。但我看到了它们时,就会知道那是色情的。”试图给“网上社区”找一个合适的定义时,我们也面临类似的问题。一旦看到了,我们都知道它们就是社区,但每个人对此都有略微不同的评价准则。其中一个原因就在于不同社区间不存在明显的界限划分。实际上,同一站点能同时属于不同的组。比如,一个物理学家的网页上可能混合有指向物理、音乐和爬山的链接,包括了职业兴趣及爱好。我们应该把这样一个页面划分到哪个社区呢?另外,社区规模的差别也很大。比如说,“密码学”方向的兴趣社区规模偏小并且相对容易识别,而由“英语文化”的爱好者组成的社区则很难识别,并且常分化成许多子社区,比如莎士比亚爱好者组成的子社区,或是库尔特·冯内古特(Kurt Vonnegut)的粉丝组成的子社区。
最近,NEC的盖瑞·弗雷克(Gary Flake)、史蒂夫·劳伦斯和李·贾尔斯建议,如果某些文档之间存在的链接多于指向它以外的其他文档的链接,则认为它们属于一个社区。这个定义很精确,人们能够根据这个定义设计算法以识别万维网结构上的各种社区。但结果表明,在实际中去寻找这些社区是非常困难的。这类搜索属于NP完全问题,这意味着,虽然原则上社区能够被准确定位,但不存在有效的算法来解决这个问题。因此,在万维网上寻找社区的困难程度类似于求解旅行商问题——该问题要求寻找能到达一组给定城市的最短路由策略,前提是每一个城市仅能访问一次。确保找到社区或是给出旅行商路由策略的唯一算法是穷举所有可能的组合。对于社区发现问题,执行这样的搜索所需的时间随着万维网规模的增加呈指数级增长。若计算机运算速度足够快,我们应该能在100个文档的样本中识别出社区。然而,想从10亿个网页中找到它们则根本不可能。
如果把内容和拓扑相结合,这个问题的挑战性会稍微降低些。举例而言,我们可以专门寻找那些包含一个或两个关键字的文档。来自斯坦福大学的拉达·阿达米克(Lada Adamic)最近调查了根据搜索短语“堕胎-选择优先”(即支持堕胎)和“堕胎-生命优先”(即反对堕胎)发现的社区。生命优先的查询结果是以41个文档组成的一个核心集,其中任意两个页面均可互达。相反,选择优先行动则分裂成许多分散的站点。
竞争的社区在结构上的这种差异会对它们宣传以及组织活动的能力产生重要的影响。正如阿达米克指出的,生命优先聚团中发起的反对堕胎法案的消息很容易到达其他生命优先网站,因为它们相互之间有许多链接。此外,由于选择优先网站有链向生命优先网站的链接,选择优点网站的访问者也能够接收到该消息。然而,要是想达到等价的宣传效果,需要在数个分散的选择优先网站上进行宣传。因此,生命优先社区在网上得以更好地展示,组织得也更为良好——因为此类网站更加关注彼此。
链接洞察
万维网远非由节点和链接组成的一个匀质的海洋,它分裂成四块大陆,其中每块大陆上又有许多的村庄和城市,它们以重叠社区的形式出现。我们每个人都愿意用一个虚拟的身份加入其中的一个或多个社区。确定无疑的是,我们还远不了解万维网的这种精细结构。但有许多的动力,如商业利益、科学上的好奇等,它们不断激励着我们去更好地了解万维网。随着我们更深入地挖掘,我确信我们将会遇到许多令人惊讶的东西,而它们将会让我们对这个复杂的、无定形的、时刻变化的网络世界有更加清晰的看法。
代码与架构
2000年11月20日,法国的吉恩-雅克·戈梅斯(Jean-Jacques Gomes)法官裁定雅虎应拒绝法国消费者访问其网站上拍卖纳粹纪念品的页面。该判决依据法国的一条禁止此类物品在法国销售的法律。法院的这一裁决在全球范围内至今仍存有争议。雅虎辩解称,互联网本质上与地理及国家界限无关,让在美国的公司去遵从世界各国的法律是对互联网基本哲学的严重破坏。其他人则对此不以为然,他们认为互联网没有任何特别的创新之处,应该和其他国际商业活动遵守相同的国际贸易协定。
除了法律上的分歧,更深层次的问题在于代码——万维网背后的软件。法国法院承认,考虑到万维网的性质,没有方法让法国与世界完全分离。但是他们被一些专家说服,那些专家表示雅虎可以通过增加过滤机制来禁止至少70%~80%法国人民尝试访问雅虎纳粹相关站点的行为。因此,法院裁决雅虎去修改代码。斯坦福法律教授劳伦斯·莱西格(Lawrence Lessig)在他的著作《代码和其他网络空间法律》(Code and Other Laws of Cyberspace)中准确地预见了这一举动。莱西格认为:“若允许网络空间自由发展,它将变为一个完美的控制工具。”网络空间看不见的手正在构建着一个与其诞生时彻底相反的架构。
莱西格用单词“架构”来表示运行在万维网背后的所有软件,并总结得出,影响网络空间行为的唯一办法就是调整代码。他建议要合两方面之力一起做这件事。政府在监管万维网上的行为时会感到很棘手。制定法律禁止访问色情文学或窃取密码是很容易的,但要在无边界的网络空间落实这些法律却几乎是不可能的。如果政府错过规范万维网的机会,商业领域将会接手。许多公司出于安全或市场营销等不同目的,会寻找更为安全的商业环境以对用户进行鉴别。它们将促使代码往可控的方向发展。由于技术始终朝着商人希望的方向发展,普通网民将完全失去他们的匿名性以及不受空间限制的存在。
一方面,雅虎的案例和其他案例都证实了莱西格的一些黯淡的预言都已成真。另一方面,在我看来,我们需要把代码和架构两者仔细区分开来才能真实地了解网络空间。代码或软件是网络空间的砖和泥浆;架构则是我们使用代码构建出的事物。人类历史上伟大的建筑师们,从米开朗基罗到弗兰克·劳埃德·赖特(Frank Lloyd Wright),都证明了一点,纵使原材料有限,建筑的可能性却是无限的。代码能够约束行为,并且确实能影响架构,但代码不是确定架构的唯一因素。
链接洞察
和建筑师设计的建筑一样,万维网架构是两个同等重要的因素共同作用的产物:代码和人类作用于代码的集体行为。第一个因素能够受到法院、政府和公司等的规范。而第二个因素却无法由任何个人或机构来管制,因为万维网不是中心设计模式——它是自组织的。它的演化是由数百万用户的个体行动造成的。因此,它的架构远丰富于自身组成部分的简单加总。万维网的众多真实的重要特性和涌现属性都来源于其大规模自组织拓扑结构。
万维网上的民主就是一个好例子。我们已经看到,无尺度拓扑结构意味着绝大多数文档很难被看到,因为少数流行度高的文档拥有几乎所有的链接。在万维网上,我们确实拥有言论自由。尽管如此,很可能出现的情况是,我们的声音太微弱了,根本无法被其他人听到。仅拥有少量导入链接的网页在随意浏览中不可能被找到。相反,我们会一遍又一遍地被导向枢纽节点。相信机器人能避免这种流行驱动引发的陷阱是一种非常美好的想法。它们应该能,但它们并不这样做。相反,一个文档被一个搜索引擎索引的可能性强依赖于它拥有的导入链接数量。仅拥有一条导入链接的文档只有不到10%的机会被搜索引擎索引。与此相反,机器人找到并索引拥有21至100条导入链接的页面的可能性则接近90%。
莱西格是对的:万维网的架构几乎控制了一切,从获得消费者到在浏览时被访问到的可能性。但是万维网的科学越来越证明了,这个架构代表了比代码更高的组织层次。你能否找到我的页面仅取决于一个因素:该页面在万维网上的位置。如果许多人发现我的页面有趣并且链接到我的页面,那么它就会慢慢地变成一个较小的枢纽节点,搜索引擎必然会注意到它。如果所有人都忽略我的网站,搜索引擎必然也将会忽略它,我的页面将会加入到不可见站点的行列中。毕竟,不可见的站点占大多数。因此,万维网的大规模拓扑结构——即它真实的架构,给万维网上我们的行为和可见性施加了更严重的限制,远超过政府或产业仅通过更改代码所能达到的程度。规则来了又走,但管控万维网的拓扑结构和基本的自然法则是不变的。只要我们继续让个体拥有自行设置链接的权力,我们就不能显著地改变万维网的大尺度拓扑结构,而且我们必须接受这样带来的结果。
记录互联网的历史
互联网的一大好处在于我们的网页和我们一起成熟。一旦我们修改了个人主页,我们将不再因几十年前持有的与现在相反的观点而受到别人的困扰。你还记得几年前分手的男朋友吗?你当然记得,但你可能希望别人都不记得。他的所有照片确实都已从你的页面移除,但那些至今仍使你脸红的中学宣言呢?或是在你转向共和党的两年前,自己在页面上添加的那些指向民主党网站的链接?这些都已无迹可寻。至少我们倾向于这么认为。这是因为大部分网民从来没有听说过布鲁斯特·卡利(Brewster Kahle)。事实上,卡利能够轻易获得你曾从网站上小心移除的,甚至都自己都已忘记的所有图片和文档。
卡利是万维网上的一名资深人士,他是广域信息服务器的发明者,同时还是主流搜索引擎之一Alexa互联网的创办者。他在1999年把Alexa网站卖给亚马逊,并在此后用这笔收入创建了互联网档案馆(Internet Archives),一个位于普雷西迪奥(Presidio)的非营利性组织。互联网档案馆坐落在旧金山市中心,由一个军事基地改造而成。他的目标很简单:避免万维网上的内容随时间消失。
2000年3月,我因为要在第一届互联网档案研讨会上做报告,所以访问了这个档案馆。卡利跟我提及亚历山大(Alexandria)的古图书馆——那个图书馆被认为保存了所有的古代书籍,但它们随着图书馆被烧毁一并消失殆尽。他还告诉我,许多珍贵的电影收藏胶片由于里面含银而被回收。没有文化遗产,人类就没有记忆,而没有了记忆,人类就不能从成功与失败中学习。对于万维网,我们依旧没有记录好它的历史。为避免重蹈覆廽,卡利创建的互联网档案馆仔细保存了Alexa自1996年来抓取到的所有文档。这个收集已增长到1000亿个网页,信息量约100TB。对比而言,美国国会图书馆收藏的所有的书和文档仅有20TB。
这个档案馆的收藏对于历史学家、社会科学家,以及万维网地志学者等都具有无与伦比的价值。如果你想撰写关于2000年总统竞选的文章,就应当从这个档案馆入手。他们有一个时间机器,你可以看到当年候选人的站点,选民指南,以及各党派的网站,精确得如同身处于那段竞选期。你是否想追踪2001年9月11日恐怖袭击时在线世界的反应?在事件后的1个月里,这个档案库搜集了2亿个相关文档。如果你是一个致力于理解万维网架构的万维网地志学者,这个档案馆是一个极好的出发点。它让你能追踪网页和链接在何时何地被添加和移除,后来节点如何一夜蹿红,以往的枢纽节点如何失去光彩。对比不同时间间隔得到的网络地图,你能够追踪虚拟社区的涌现和结晶。档案馆拥有能够重建节点和链接的混沌演化的数据,有助于揭露万维网当前架构的形成机制。
档案馆拥有来自不同学科的众多粉丝,但大部分能够从中获益的研究者要么不知道它的存在,要么缺乏编程技巧来访问和有效地利用它。因此它的全部潜能仍然未被研究者和公众利用起来。尽管如此,我希望互联网档案管只是一个开始,更希望它能够唤起我们对网上世界的历史使命感。档案管还远不能够抓取发生在万维网上的所有一切。它的主要收集来自于卡利和布鲁·吉利亚特(Bruce Gilliat)在1996年创立的搜索引擎Alexa。正如我们所知道的,搜索引擎仅覆盖了万维网的一小部分,而Alexa的覆盖面就更少了。因此,尽管互联网档案库的规模巨大,目前的这些收集也仅是万维网中很微小的一部分,绝大多数是流行的页面。Alexa采集到了网络中的枢纽节点,而其余那些数量巨大的只有很少链接的页面都被它的机器人忽略了,这类页面正在以百万级每天的速率被遗漏掉。
不断扩大的互联网黑洞
对于一个正在接近我们太阳系的外星人而言,地球就只是一个圆球。再靠近一些,这个外星人可能会注意到地球上的陆地。巴黎、纽约、伦敦和东京等发出的亮光还给出了智能生命存在的线索。再靠近一些,外星人就能辨别出小的社区,以及由高速公路和道路交织成的精细结构。然而,这个外星人需要靠得非常近,才能看到造就了太空可见的大尺度秩序的人类。
我们对万维网的探索也遵循着相同的路线。首先,我们发现了非匀质的大尺度拓扑,并且知道了这和绝大多数行星是球形一样不可避免。再细看,我们注意到有四块主要大陆,各自遵循着不同的规律。进一步关注更多的细节,我们开始看到社区,即由相同兴趣聚合在一起的一组网页。这些向未知领域的探索已极大地改变了我们对万维网的理解。我们了解到网上世界比任何人预计的都要大得多,并且它的增长速度也比我们所愿相信的更快。令人失望的是,我们还发现它极少被绘制下来,少到远低于我们能接受的程度。两年前,6/10的页面不能被任何搜索引擎访问到。如果这个趋势可信,如今搜索引擎能看到的万维网的范围就更小了。不过,好的一面是竞争迫使搜索引擎工作得越来越好。但我们绝不能只看到小枝小节,而忽视全局:不管搜索引擎之间竞争程度如何,万维网只会更大。
然而,我们也不能低估搜索引擎和它们的机器人提供给我们的大量服务。我们经常绝望地叹息,称万维网为“丛林”。事实上,没有了机器人,它将是一个黑洞。空间会在它的周围弯曲,任何事物一旦进入其中就再也逃逸不出来。机器人使得万维网在其复杂性持续增加的情况下仍不会塌陷。它们支撑了这个空间,维持着节点和链接在混沌之中的秩序。
我们的生活越来越受万维网主宰。然而,我们只投入很少的注意力和资源用于理解它。实际上,只需要相对较少的努力就能为信息获取带来新的革命。这一定会发生。但问题是,与此同时我们会失去什么?
在这样一个互联网主导程度日益增强的社会里,理解万维网对其自身具有巨大的价值。不过,对我而言,价值远大于此。这一探索中最令人兴奋的一个方面是揭示了一些规则在赛博空间[3]中依旧有效。这些规则同样适用于细胞和生态系统,这也证明了自然规则是不可避免的,以及自组织对我们周围世界的深刻塑造。由于具有数字化的优点,并且规模巨大,万维网提供了一个模型系统,其中所有细节都能够被揭露。对于以往的其他任何网络,我们都未能如此接近。对于想抓住与万维网类似的世界的属性的任何人来说,万维网仍然是灵感和想法的源泉。
[1] C-3PO是电影《星球大战》中的角色,是一个9岁的天才小孩用废弃零件制造的机器人。——编者注
[2] R2-D2也是电影《星球大战》中的角色,是一个机智、勇敢,而又有些鲁莽的机器人。——编者注
[3] 赛博空间是哲学和计算机领域中的一个抽象概念,指在计算机以及计算机网络里的虚拟现实。——编者注
