08 阿里巴巴的大数据实践
按照我们通常的理解,一个人在注册某一网站的时候,性别登记只会是男性或女性,但不知你是否能想到,阿里巴巴竟然有18个性别标签。
在经过仔细调查后,我们发现了一些可以识别用户性别的方法。比如,某个登记用户早上的浏览行为更男性一些,晚上就会变得更女性(也许是妻子在用)。真实的性别只有0与1的关系,而现实却是0~1的关系,或者70%是男性,30%是女性。在每一个场景内,性别的变化都确有其原因,例如搜索、社交和广告等。静态的“真实”性别在A/B测试[1]中的表现不如动态的虚拟性别有效,这恰恰证明了数据是需要运营的,绝不可以闭门造车,这样的例子在阿里巴巴不胜枚举。
谈到数据化运营,在公司内部我们是这样的流程:例如,我们要为一个童装类目做营销推广以征集新客户,我们会先找到目标客户群,会把对这个类目感兴趣的消费者用标签找出来,然后通过发邮件或者短信等方式来吸引他们的关注,这其实就是数据化运营,也就是用数据去帮助企业解决问题。最简单的解决办法是找出所有曾经看过但没有购买的客户群,又或者利用关联类目去扩大目标客群。
而数据从“用”上升到“养”,即运营数据,我们就会尝试在整个淘宝用户中查找。以针对12岁年龄之下儿童的商品为例,此时我们的做法就是在用户中搜索有多少用户家中有12岁以下的孩子,但却未发生过从这个类目购买商品的行为。你会发现,以前只能运营有过购买行为的几百万用户,现在我们的运营范围竟然可以达到几千万可能有12岁以下孩子的用户。从几百万到几千万,这就是运营数据,它是一个需要从主动收集数据到运营数据,再到产生新数据的过程。
在我的理解中,从数据化运营到运营数据是不断运行的循环。在这样的循环中,会容纳许多新的、不同维度的数据,这些数据经过在整个循环中的适应过程,然后再运用到数据化运营中,并且改变原有的运营方式,这个过程就是我认为的大数据落地的方法。
数据化运营的前提是假定数据是稳定的,并且以此来改变企业的运营。但以前的数据都是结构化数据,比如说,早期大部分企业都用财务数据来帮助企业运营,因为财务数据经过多年的积淀,相对来说较为稳定。而自从非结构性数据或者半结构性数据产生以后,数据化运营的难度就变大了。比如,音频是一种典型的非结构化数据,你很难把音频变成结构化数据,有了这样的数据以后,用数据来指导企业运营,面临的技术难度远远大于以往。
我们做数据化运营,其前提是假定数据是稳定的;而运营数据,则是假定数据都是可以获取的,而且是不稳定的(见图8—1)。
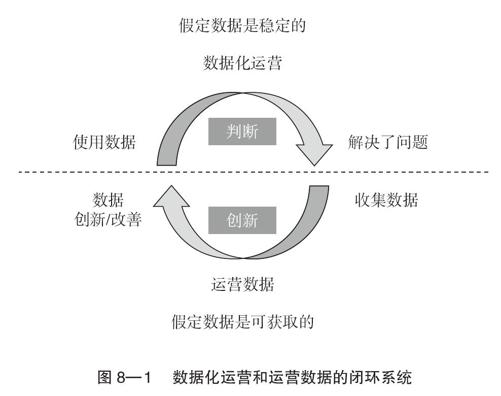
这又如何理解呢?所谓稳定,比如说关键词ROI,这项数据听起来很稳定,但反映的却是短线利益。数据化运营需要和商业咬合得非常紧密,所以数据也是混合在商业里,以假定稳定的方法去做业务上的对比和细分及趋势预估的。
这并不是说稳定是对的,而是因为企业对数据运营的分析是需要假设很多稳定因素的。
假定数据是稳定的
假定数据是稳定的,也意味着我们习惯于不去寻找一些新数据。
在这里,我们用点击率做例子。数据运营人员可能会觉得这项数据我们一直在使用,能有什么特别的呢?但在我眼里,点击率是变化的。我的问题是,当用户点击到详情页时,又有多少用户连第二屏都不会拉下去看?如果这项比例很高,那么就意味着点击率本身就有很多水分。
所以说,在数据化运营里,我们往往假定数据稳定不变,因为在我们的认知中,我只是数据的使用者,我假定数据是稳定的就可以了,这是普遍心理。那么,为什么我要去关注数据稳不稳定?而且,假定数据稳定,也意味着我们习惯于不去寻找一些新数据。
我的钥匙不见了,一般的做法是去那些我可能丢东西的地方找。同理,在运用数据的时候若出了问题,我们也会是一样的心理,不会去思考除惯性思维之外的其他可能性,而且这些地方无法解决问题时,我们就会不解。而这是数据化运营中很常见的一条死路。
于是,到了养数据,也就是运营数据的阶段时,我们的做法就必须改变了。此时,当我们要想静态的性别时,就要问自己:“会不会不好用?是否需要改善?”
从企业的角度来讲,数据化运营一般是自上而下的——管理者强调KPI指标,员工们按照目标进行分解。所以,数据化运营是计划性的,但凡计划性的一定都是稳定且结构化的。
运营数据却是自下而上的,经过了无数的错误和无数的实验,慢慢地向上追溯。就像阿里巴巴有18个性别这件事情,这18个性别不是管理层凭空想象出来的,而是将众人发现的性别经过交叉比对,分析到底在什么场景下更适合。可见,这样的结果是试出来的。
在我们的日常工作中,你很少会发现负责业务的管理者说:“我要收集这项数据,它很有用。”这样的场景一般不会出现。我有过这样的经历,是因为我是数据部门的管理者,我这么做的原因,是在跟其他公司的人讨论时产生了这样的想法,而我也会在我回到公司后提出“我们也试试这个数据”的意见。比如,前面提到的那个亚马逊根据IP地址观察用户附近10公里内有没有书店的例子,同样的运营数据的方法我就在淘宝尝试过。
我想说的是,如果没有了运营数据的这个部分,收集来的数据绝对就不是大数据。
假定数据是可获取的
“用数据拿数据”的方法可以将数据化运营和运营数据打通。
从假定数据可以获取的角度来思考问题,是数据化运营里很重要的一个方法,这与“如何利用数据来拿到更多数据”的问题并不一样。今天,我已经知道了你的一些数据了,但是并不多,此时我就要想办法用我知道的东西来拿到你更多的数据,这在数据化思考里叫作“有意识地用数据拿数据”(Data Get Data)。
现在,最常见的一种“数据拿数据”的方法就是“A/B Test” 。原理是,我本来知道你对某种东西很感兴趣,今天我给你做一个测试,本来是A页面,我给你一个B页面,然后看看你有什么样的反应(有点像功夫里的假动作)。其实,B页面拿到的数据肯定是基于A页面拿到的数据的。
比如说,你经常会走过一条路,而今天在你走过这条路时,我安排了一个美女从这里走过,然后测试一下你的路径有没有变化以及你有没有停下来。
正常来说,以前收集到的数据会告诉我你在路过的时候是不作停留的。而今天你停了下来,那我就得到了“美女的出现可以让你停下来”的数据。这时候,美女就是我抛出来的一个问题,即用问题来获得更多数据,这就是在用一部分数据拿更多的数据时采用得最常见的方法。
将数据化运营和运营数据打通,有可能会创造出一些意想不到的创新。
我们在大数据环境里运营数据时,有可能走不通的原因是,现在的数据已经庞大到需要管理才能到创新的数据化运营。这个循环能否成型,往往需要很长时间的努力。
互联网金融就是一个近些年比较新颖的例子,现在也有很多前沿公司在做类似的事情。这么做的原因是,公司发现用户的资金链是评估其经济状况的一个有用信息,而收集到的这些数据应用在信用评估上时,可以更动态地决定用户的信用额度,以减少借出方的风险。
比如,这个网站拥有关于整个公司流水的数据,大概知道用户的资金流水——原来还有30%的订单在处理,还有不少订单在路上,而有些则是押在了一些担保交易上,所以这个用户不是没钱,而是钱押在了供应链的各个环节上。万一用户不还钱,网站也有能力卡住用户的资金流,这使得网站有能力降低自己遭受坏账的风险。
其实,阿里巴巴在从数据化运营到运营数据的循环系统中,能做到现在的成绩,跟管理层更相信数据、更愿意付出以及更愿意投资有很大的关系。此循环系统的关键在于管理层如何应对数据价值的断层,这对整个循环能否走下去的影响非常大,而阿里巴巴应对这个循环的内功,我认为答案在于“混、通、晒”。
先不要一头雾水,“混、通、晒”简单来说,应该是我们数据分析师的“内三板斧”,我会在第9章中进行详细的介绍。
[1] A/B Test,A/B测试,是数据分析中的一种对比分析方法,可以将试验组和控制组的试验结果更加明确地展示出来。——编者注
