1.7 索引
查询是在表上进行的最频繁的访问。在查询数据时,很少有用户愿意查询表中的所有数据,除非要对整个表进行处理。一般情况下用户总是查询表中的一部分数据。在SELECT语句中,通常需要通过WHERE子句指定查询条件,以获得满足该条件的所有数据。如果能够在很小的范围内查询需要的数据,而不是在全表范围内查询,那么将减少很多不必要的磁盘I/O,查询的速度无疑会大大加快。提供这种快速查询的方法就是索引。
1.7.1 索引的基本概念
索引是一种建立在表上的数据库对象,它主要用于加快对表的查询操作。合理使用索引可以大大减少磁盘访问的次数,从而大大提高数据库的性能。
使用索引的主要目的是加快查询速度,另外,索引也可以作为唯一性约束。如果在表的一个列上建立了唯一性索引,那么系统将自动在这个列上建立唯一性约束,这样可以保证插入这个列的数据是唯一的。
索引究竟是怎样加快查询速度的呢?原来,索引是建立在表中的某个列或几个列上的,这样的列称为索引列。在创建索引时,数据库服务器将对索引列的数据进行排序,并将排序的结果存储在索引所占用的存储空间中。在查询数据时,数据库服务器首先在索引中查询,然后再到表中查询。因为索引中的数据事先进行了排序,所以只需要很少的查找次数就可以找到需要的数据。
例如,假设要执行下面的查询语句:
SQL>SELECT empno, ename, sal FROM emp WHERE empno=7902;
假设在表emp中有1000行数据,如果没有创建索引,那么系统将不得不在全表范围内查询,查询的次数为1000。但是如果使用了索引进行查询,那么只需要很少的几次查询就可以找到编号为7902的员工的数据。
图1.2为索引和表之间的关系示意。
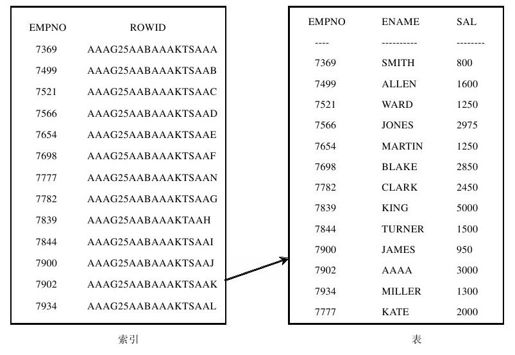
图 1.2 索引与表的关系
从上图可以看到,在索引中,不仅存储了索引列上的数据,而且还存储了一个ROWID的值。ROWID是表中的一个伪列,是数据库服务器自动添加的,表中的每一行数据都有一个ROWID值,它代表这一行的标识,即一行数据在存储空间的物理位置。在访问表中的数据时,都要根据这个伪列的值找到数据的实际存储位置,然后再进行访问。由于索引列上的数据已经进行了排序,在索引中很快就能找到这行数据,然后根据ROWID就能直接到表中找到这行数据了。
需要注意的是,表是独立于索引的,无论对在表上建立了多少索引,无论索引对表中的数据进行什么样的排序,表中的数据都不会有任何变化。
在查询一行数据时,首先在索引中查询该行的行标识,然后根据这个行标识找到表中的数据。因为索引中的数据是经过排序的,所以采用了折半查找法查找数据,以达到快速查找的目的。图1.3表示利用索引查找数据的过程。
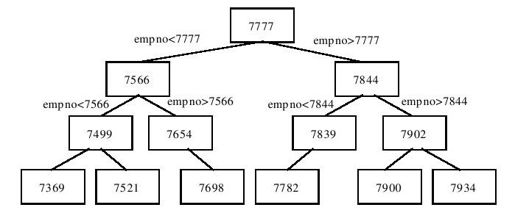
图 1.3 索引的工作原理
利用折半查找法在索引中查找数据的过程类似于遍历一棵二叉树,首先与根节点比较,如果与查找的数据相同,则一次访问就完成查询。如果要查找的数据小于根节点,则在根节点的左子树中查找,否则在右子树中查找,这样查找的范围将缩小一半。按照这种方法,每次将查找范围缩小一半,然后在剩下的节点中继续查找,直到找到所需的数据。如果利用上述索引在表emp中查找员工7777,访问一次磁盘就可以得到结果,要查找员工7902,第三次就可以得到结果。
按照索引列的值是否允许重复,索引可以分为唯一性索引和非唯一性索引,其中唯一性索引可以保证索引列的值是唯一的。按照索引列中列的数目,索引可以分为单列索引和复合索引。按照索引列的数据的组织方式,索引可以分为B树索引、位图索引、反向索引和基于函数的索引,这里仅介绍B树索引的用法。
合理地使用索引固然可以大大提高数据库的查询性能,但是不合理的索引反而会降低数据库的性能,尤其是在进行DML操作时。在创建索引时,表中的数据将被排序,如果对表进行了DML操作,表中的数据发生了变化,这时索引中的数据也将被重新排序,如果在表上建立了多个索引,那么每个索引中的数据都要被重新进行排序。这种排序的开销是很大的,尤其是表非常大时。
索引是关系型数据库系统用来提高性能的有效方法之一,索引的使用可以减少磁盘访问的次数,从而大大提高了系统的性能。但是在设计索引时必须全面考虑在表上所进行的操作,如果在表上进行的主要操作是查询操作,那么可以考虑在表上建立索引,如果在表上要进行频繁的DML操作,那么索引反而会引起更多的系统开销。一般来说,创建索引要遵循以下原则:
·如果每次查询仅选择表中的少量行,应该建立索引。
·如果在表上需要进行频繁的DML操作,不要建立索引。
·尽量不要在有很多重复值的列上建立索引。
·不要在太小的表上建立索引。在一个小表中查询数据时,速度可能已经足够快,如果建立索引,对查询速度不仅没有多大帮助,反而需要一定的系统开销。
