10.4 簇的管理
簇是一种数据库对象,它由一组共享相同数据块的表组成。簇中的表根据簇键组合在一起,簇键相同的行存储在相同的数据块或相邻的数据块中。簇键是一个列或多个列的组合,簇中的每个表都必须具有与簇键相同的列。
在常规的情况下,每个表对应一个单独的表段,表中的数据存储在表段中。当多个表以簇的形式组织在一起后,单独的表段将不存在,表中的数据都将存储在一个簇段中。
把表组织为簇的主要目的,是在进行多表联合查询时,减少磁盘操作次数,提高查询速度。例如,假设要经常执行下面的查询:
SQL>SELECT empno, ename, sal, dname
FROM emp, dept
WHERE emp.deptno=dept.deptno;
由于是在两个表之间进行连接查询,所以至少需要两次磁盘读操作。如果把这两个表以簇的形式组织在一起,磁盘操作的次数可以减少到一次。由于表emp和dept都有deptno列,所以这个列在簇中就作为簇键。两个表中簇键相同的行将存储在同一个数据块或相邻的多个数据块中。图10.5表示簇与普通表的区别。
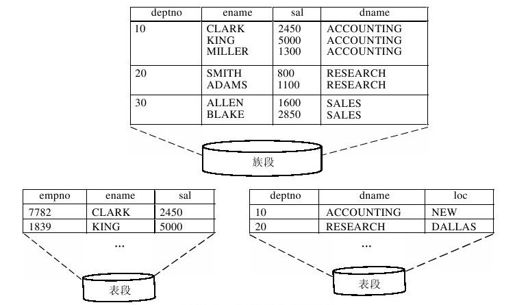
图 10.5 簇与普通表的区别
10.4.1 簇的创建
要把表以簇的形式组织在一起,首先需要创建一个簇,然后在簇中创建表。用户需要具有CREATE CLUSTER系统权限和表空间中的配额。如果希望在其他用户的模式中创建簇,需要具有CREATE ANY CLUSTER系统权限。在创建簇时应注意以下原则:
·簇中的表主要用来查询,而不应该频繁地执行DML操作。
·簇中的表应该是经常用来进行连接查询的表。
·簇中的表必须包含一个或多个共同的列,并把这样的列作为簇键。
·由于簇中的数据存储在簇段中,所以可以为簇指定存储参数。
·可以为每个簇键列的值和相关行指定平均大小。
创建簇的命令是CREATE CLUSTER。例如,下面的语句将创建簇emp_dpt:
SQL>CREATE CLUSTER emp_dept(deptno number(3))
TABLESPACE USERS
SIZE 1024
PCTFREE 20;
在上面的语句中,deptno是簇中的簇键。当在簇中创建表时,每个表都必须包含与簇键相同的列,最好将两个表的主键和外键作为簇键。SIZE子句的作用是为每个簇键列的值和相关行指定平均大小,单位为字节。簇键值相同的行存储在同一个数据块中,或者相邻的多个数据块中。簇键值不同的行也可存储在同一个数据块中。如果SIZE指定的大小不合适,那么可能发生数据块的迁移,或者浪费数据块空间,所以在创建簇之前,应该充分估计簇键列的值和相关行的大小。
在创建簇以后,就可以在簇中创建表了。由于表中的数据存储在簇段中,所以不能为表指定存储参数。在创建表时必须通过CLUSTER指定表所在的簇及簇键。下面的语句用于在簇emp_dept中创建表dept和emp。
SQL>CREATE TABLE dept(
deptno number(3)primary key,
dname varchar(10),
loc varchar(20)
)CLUSTER emp_dept(deptno);
SQL>CREATE TABLE emp(
empno number(4)primary key,
ename varchar(10),
deptno number(3)references dept(deptno)
)CLUSTER emp_dept(deptno);
在往簇中的表里插入数据之前,必须在簇上创建索引。创建簇索引的用户必须是簇的属主,或者具有CREATE ANY CLUSTER系统权限。除了要指定所在的簇以外,簇索引的创建方法与普通索引类似,索引和簇可以位于同一个表空间,也可以位于不同的表空间中。下面的语句将用于在簇emp_dept上创建索引:
SQL>CREATE INDEX emp_dept_idx
ON CLUSTER emp_dept
TABLESPACE ts1;
