10.3.4 分组与合计数据
我们经常需要知道多少行分成一个特定的集合,或一些列的平均值。例如,每个订单的平均金额。MySQL有一组合计函数可实现这类查询。
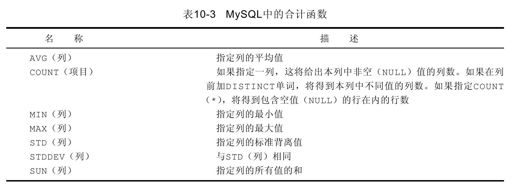
这些合计函数可以作为一个整体应用于一个表,或者表中的一组数据。最常用的函数如表10-3所示。
我们来看看一些例子,以前面提到的一个例子为开始。可以如下计算一个订单总金额的平均值:
select avg(amount)
from orders;
输出如下所示:
+——————-+
|avg(amount)|
+——————-+
|54.985002|
+——————-+
要获取更详细的信息,可以使用GROUP BY子句。这使我们可以按分组浏览订单总量的平均值。例如,按照顾客数分组浏览。我们将知道哪些顾客的订单总金额最大:
select customerid,avg(amount)
from orders
group by customerid;
当通过合计函数使用GROUP BY子句的时候,它实际上改变了该函数的行为。该查询并不是给出表中的平均订单总量,而是给出每个顾客(或者,更具体地说,是每个customerid)的平均订单总金额:
+——————+——————-+
|customerid|avg(amount)|
+——————+——————-+
|1|49.990002|
|2|74.980003|
|3|47.485002|
+——————+——————-+
在使用分组和合计函数的时候,需要注意的是:在ANSI SQL中,如果使用了一个合计函数或GROUP BY子句,出现在SELECT子句中的必须是合计函数名称和GROUP BY子句的列名称。同样,如果希望在一个GROUP BY子句中使用一列,该列名称必须在SELECT子句中列出。
MySQL实际上留了一点回旋余地。它支持一种扩展语法(extended syntax),该语法可以在SELECT子句中略去一些实际上并不需要的项目。
除了分组与合计数据,我们实际上还可以使用HAVING子句测试一个合计的结果。它可以直接放在GROUP BY子句后,有些类似于只用于分组与合计的WHERE子句。
对前面的例子进行扩展,如果希望知道哪些顾客的平均订单总金额超过$50,可以使用如下所示的查询:
select customerid,avg(amount)
from orders
group by customerid
having avg(amount)>50;
请注意,HAVING子句应用于这些组。该查询将返回如下所示的输出:
+——————+——————-+
|customerid|avg(amount)|
+——————+——————-+
|2|74.980003|
+——————+——————-+
