20.3 模 式 讲 解
20.3.1 认识享元模式
1.变与不变
享元模式设计的重点就在于分离变与不变。把一个对象的状态分成内部状态和外部状态,内部状态是不变的,外部状态是可变的。然后通过共享不变的部分,达到减少对象数量并节约内存的目的。在享元对象需要的时候,可以从外部传入外部状态给共享的对象,共享对象会在功能处理的时候,使用自己内部的状态和这些外部的状态。
事实上,分离变与不变是软件设计上最基本的方式之一,比如预留接口,为什么在这个地方要预留接口,一个常见的原因就是这里存在变化,可能在今后需要扩展或者是改变已有的实现,因此预留接口作为“可插入性的保证”。
2.共享与不共享
在享元模式中,享元对象又有共享与不共享之分,这种情况通常出现在和组合模式合用的情况,通常共享的是叶子对象,一般不共享的部分是由共享部分组合而成的,由于所有细粒度的叶子对象都已经缓存了,那么缓存组合对象就没有什么意义了。这在后面将给大家一个示例。
3.内部状态和外部状态
享元模式的内部状态,通常指的是包含在享元对象内部的、对象本身的状态,是独立于使用享元的场景的信息,一般创建后就不再变化的状态,因此可以共享。
外部状态指的是享元对象之外的状态,取决于使用享元的场景,会根据使用场景而变化,因此不可共享。如果享元对象需要这些外部状态的话,可以从外部传递到享元对象中,比如通过方法的参数来传递。
也就是说享元模式真正缓存和共享的数据是享元的内部状态,而外部状态是不应该被缓存共享的。
还有一点,内部状态和外部状态是独立的,外部状态的变化不应该影响到内部状态。
4.实例池
在享元模式中,为了创建和管理共享的享元部分,引入了享元工厂。享元工厂中一般都包含有享元对象的实例池,享元对象就是缓存在这个实例池中的。
简单介绍一点实例池的知识。所谓实例池,指的是缓存和管理对象实例的程序,通常实例池会提供对象实例的运行环境,并控制对象实例的生命周期。
延伸
工业级的实例池在实现上有两个最基本的难点,一个是动态控制实例数量;另一个是动态分配实例来提供给外部使用。这些都是需要算法来做保证的。
假如实例池中已有了3个实例,但是客户端请求非常多,有些忙不过来,那么实例池的管理程序就应该判断,到底几个实例才能满足现在的客户需求,理想状况是刚刚好,就是既能够满足应用的需要,又不会造成对象实例的浪费。假如经过判断5个实例正好,那么实例池的管理程序就应该能动态地创建2个新的实例。
这样运行了一段时间,客户端的请求减少了,这个时候实例池的管理程序又该动态地判断,究竟几个实例是最好的,多了明显浪费资源。假如经过判断只需要1个实例就可以了,那么实例池的管理程序应该销毁掉多余的4个实例,以释放资源。这就是动态控制实例数量。
对于动态分配实例,也说明一下。假如实例池中有3个实例,这个时候来了一个新的请求,到底调度哪一个实例去执行客户的请求呢?如果有空闲实例,那就调度空闲实例去执行客户的请求,如果没有空闲实例呢,是新建一个实例,还是等待运行中的实例,等它运行完了就来处理这个请求呢?具体如何调度,也是需要算法来保障的。
回到享元模式中来,享元工厂中的实例池并没有这么复杂,因为共享的享元对象基本上都是一个实例,一般不会出现同一个享元对象有多个实例的情况。这样就不用去考虑动态创建和销毁享元对象实例的功能;另外因为只有一个实例,也就不存在动态调度的麻烦,反正就是它了。
这也主要是因为享元对象封装的多半是对象的内部状态,这些状态通常是不变的,有一个实例就够了,不需要动态控制生命周期,也不需要动态调度,它只需要做一个缓存而已,没有上升到真正的实例池的高度。
5.享元模式的调用顺序示意图
享元模式的使用上,有两种情况,一种是没有“不需要共享”的享元对象,就如同前面的示例那样,只有共享享元对象的情况;还有一种是既有共享享元对象,又有不需要共享的享元对象的情况,这种情况后面再示例。
下面看看只有共享享元对象的情况下,享元模式的调用顺序,如图20.3所示。
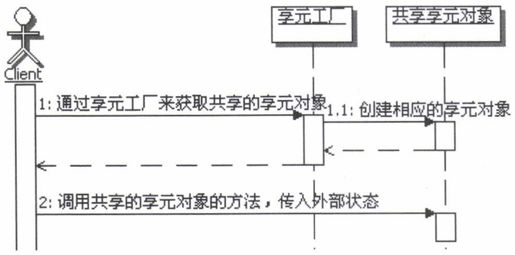
图20.3 只有共享享元对象的情况下享元模式的调用顺序示意图
6.谁来初始化共享对象
在享元模式中,通常是在第一次向享元工厂请求获取共享对象的时候,进行共享对象的初始化,而且多半都是在享元工厂内部实现,不会从外部传入共享对象。当然可以从外部传入一些创建共享对象需要的值,享元工厂可以按照这些值去初始化需要共享的对象,然后把创建好的共享对象的实例放入享元工厂内部的缓存中,以后再请求这个共享对象的时候就不用再创建了。
20.3.2 不需要共享的享元实现
可能有些朋友看到这个标题会很疑惑,享元不就是要共享的对象吗?不共享,叫什么享元啊?
确实有不需要共享的享元实现,这种情况多出现在组合结构中,对于使用已经缓存的享元组合出来的对象,就没有必要再缓存了。也就是把已经缓存的享元当做叶子结点,组合出来的组合对象就不需要再被缓存了。也把这种享元称为复合享元。
比如上面的权限描述,如果出现组合权限描述,在这个组合对象中包含很多个共享的权限描述,那么这个组合对象就不用缓存了,该组合对象的存在只是为了在授权的时候更加方便。
具体点说吧,比如要给某人分配“薪资数据”这个安全实体的“修改”权限,那么一定会把“薪资数据”的“查看权限”也分配给这个人。如果按照前面的做法,需要分配两个对象,为了方便,干脆把这两个描述组合起来,打包成一个对象,命名为“操作薪资数据”,那么分配权限的时候,可以这样描述:
把 “操作薪资数据” 分配给 张三
这句话的意思就相当于:
把 “薪资数据” 的 “查看”权限 分配给 张三
把 “薪资数据” 的 “修改”权限 分配给 张三
这样一来,“操作薪资数据”就相当于是一个不需要共享的享元,它实际由享元“薪资数据的查看权限”和享元“薪资数据的修改权限”这两个享元组合而成,因此“操作薪资数据”本身也就不需要再共享了。
这样分配权限的时候就会简单一点。
但是这种组合对象在权限系统中一般不用于验证,也就是说验证的时候还是一个一个进行判断,因为在存储授权信息的时候是一条一条存储的。但也不排除有些时候始终要检查多个权限,干脆把这些权限打包,然后直接验证是否有这个组合权限,只是这种情况应用得比较少而已。
还是用示例来说明吧。在上面已经实现的系统中添加不需要共享的享元实现。此时系统结构如图20.4所示。
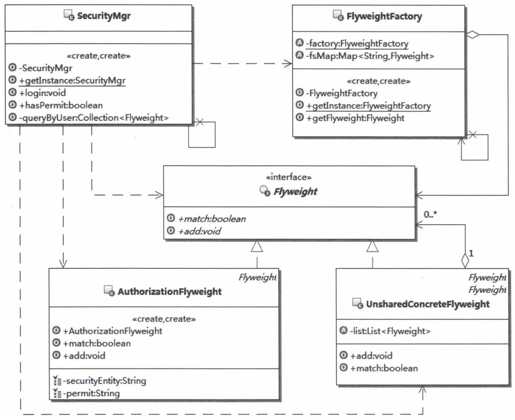
图20.4 不需要共享享元的示例机构示意图
(1)首先要在享元接口上添加对组合对象的操作,主要是添加向组合对象中加入子对象的方法。示例代码如下:

(2)享元接口改变了,那么原来共享的享元对象也需要实现这个方法,这个方法主要是针对组合对象的,因此在叶子对象中抛出不支持的例外就可以了。示例代码如下:

(3)接下来实现新的不需要共享的享元对象,其实就是组合共享享元对象的对象,这个组合对象中,需要保存所有的子对象,另外它在实现match方法的时候,是通过递归的方式,在整个组合结构中进行匹配。示例代码如下:

(4)在继续实现之前,先来准备测试数据,也就是TestDB,需要有一些改变。
首先是授权数据要区分是单条的授权还是组合的授权,这个在每条授权数据后面添加一个标识来描述。
然后增加一个描述组合数据的记录,使用一个Map来存放。
具体的示例代码如下:


(5)享元工厂不需要变化,这里就不再赘述。
(6)接下来该实现安全管理的类了,这个类相当于享元模式的Client角色。这次在这个类中,不仅会使用共享的享元对象,它还会使用不需要共享的享元对象。
主要的变化集中在queryByUser方法中,。原本只是通过享元工厂来获取共享的享元对象即可,但这次还需要在这里创建不需要共享的享元对象。示例代码如下:




(7)客户端测试没有太大的变化,增加一条测试“李四对薪资数据的修改权限”。示例代码如下:


可以运行测试一下,看看效果。结果示例如下:

20.3.3 对享元对象的管理
虽然享元模式对于共享的享元对象实例的管理要求没有实例池对实例管理的要求那么高,但是也还是有很多自身的特点功能,比如,引用计数、垃圾清除等。所谓垃圾,就是在缓存中存在,但是不再需要被使用的缓存中的对象。
所谓引用计数,就是享元工厂能够记录每个享元被使用的次数;而垃圾清除,则是大多数缓存管理都有的功能,缓存不能只往里面放数据,在不需要这些数据的时候,应该把这些数据从缓存中清除,释放相应的内存空间,以节约资源。
在前面的示例中,共享的享元对象是很多人共享的,基本上可以一直存在于系统中,不用清除。但是垃圾清除是享元对象管理的一个常见的功能。继续通过示例给大家讲一下,看看如何实现这些常见的功能。
1.实现引用计数的基本思路
要实现引用计数,就在享元工厂中定义一个Map,它的key值与缓存享元对象的key是一样的,而value就是被引用的次数,这样当外部每次获取该享元的时候,就把对应的引用计数取出来加上1,然后再记录回去。
2.实现垃圾回收的基本思路
要实现垃圾回收就比较麻烦点,首先要能确定哪些是垃圾?其次是何时回收?还有由谁来回收?如何回收?解决了这些问题,也就实现了垃圾回收。
(1)为了确定哪些是垃圾,一个简单的方案是这样的,定义一个缓存对象的配置对象,在这个对象中描述了缓存的开始时间和最长不被使用的时间,这个时候判断是否垃圾的计算公式如下:当前的时间-缓存的开始时间≥最长不被使用的时间。当然,每次这个对象被使用的时候,就把那个缓存开始的时间更新为使用时的当前时间,也就是说如果一直有人用的话,这个对象是不会被判断为垃圾的。
(2)何时回收的问题,当然是判断出来是垃圾了就可以回收了。
提示
关键是谁来判断垃圾,还有谁来回收垃圾的问题。一个简单的方案是定义一个内部的线程,这个线程在享元工厂被创建的时候就启动运行。由这个线程每隔一定的时间来循环缓存中所有对象的缓存配置,看看是否是垃圾,如果是垃圾,那就可以启动回收了。
(3)怎么回收呢?这个比较简单,就是直接从缓存的Map对象中删除相应的对象,让这些对象没有引用的地方,那么这些对象就可以等着被虚拟机的垃圾回收来回收了。
3.代码示例
(1)分析了这么多,还是看代码示例会比较清楚,先看缓存配置对象。示例代码如下:


(2)对享元对象的管理工作,是由享元工厂来完成的,因此上面的功能,也集中在享元工厂中来实现,在上一个例子的基础之上,来实现这些功能。改进后的享元工厂相对而言稍复杂一点,大致有如下改变。
■ 添加一个Map,来缓存被共享对象的缓存配置的数据。
■ 添加一个Map,来记录缓存对象被引用的次数。
■ 为了测试方便,定义了一个常量来描述缓存的持续时间。
■ 提供获取某个享元被使用的次数的方法。
■ 在获取享元的对象中,就要设置相应的引用计数和缓存设置了,示例采用的是内部默认设置一个缓存设置。其实也可以改造一下获取享元的方法,从外部传入缓存设置的数据。
■ 提供一个清除缓存的线程,实现判断缓存数据是否已经是垃圾了,如果是,那就把它从缓存中清除掉。
基本上重新实现了享元工厂。示例代码如下:






提示
getUseTimes、removeFlyweight和getFlyweight这几个方法是加了同步的,原因是在多线程环境下使用它们,容易出现并发错误,比如一个线程在获取享元对象,而另一个线程在删除这个缓存对象。
(3)要想看出引用计数的效果来,SecurityMgr需要进行一些修改,至少不要再缓存数据了,需要直接从享元工厂中获取数据,否则就没有办法准确引用计数了。大致改变如下。
■ 去掉了放置登录人员对应权限数据的缓存。
■ 不需要实现登录功能,在这个示意程序里面,登录方法已经不用实现任何功能,因此直接去掉。
■ 原来通过map获取值的地方,直接通过queryByUser获取就好了。
示例代码如下:



(4)还是写个客户端来试试看,上面的享元工厂能否实现对享元对象的管理,尤其是对于垃圾回收和计数方面的功能。对于垃圾回收的功能不需要新添加任何的测试代码,而对于引用计数的功能,需要写代码来调用才能看到效果。示例代码如下:


进行缓存的垃圾回收功能的是个线程在运行,所以你不终止该线程运行,程序会一直运行下去,运行部分结果如下:

解释一下引用次数是怎么计算出来的,目前实现的引用次数,是通过享元工厂获取一次享元对象就计算一次。那么什么时候会通过享元工厂去获取一次享元对象呢?
那就是一个hasPermit的请求,在进行权限判断的时候,会查询TestDB,然后通过享元工厂去获取一次享元对象。因此最后的结果就是看调用一次hasPermit,这个用户在TestDB中对应哪些数据,这些数据就会被调用一次。具体用上面的示例来说就是:
(1)当运行到Client下面这句话的时候:
boolean f1=mgr.hasPermit("张三","薪资数据","查看");
根据用户名“张三”到TestDB中查找,看他具有哪些权限。根据TestDB,“张三”这个人员只会影响到“人员列表,查看”,因此以“人员列表,查看”为key的享元对象被引用一次,当前次数为1。
(2)Client继续运行,到下面这句话的时候:
boolean f2=mgr.hasPermit("李四","薪资数据","查看");
同理,根据用户名“李四”到TestDB中查找,“李四”这个人员会影响到“人员列表,查看”、“薪资数据,查看”和“薪资数据,修改”,因此以这三个描述为key的享元对象都被引用一次。此时“人员列表,查看”对应的享元对象当前被引用次数为2;“薪资数据,查看”对应的享元对象当前被引用次数为1;“薪资数据,修改”对应的享元对象当前被引用次数为1。
(3)Client继续运行,到下面这句话的时候:
boolean f3=mgr.hasPermit("李四","薪资数据","修改");
同理,根据用户名“李四”到TestDB中查找,然后计数。结果是:以“人员列表,查看”、“薪资数据,查看”和“薪资数据,修改”为key的享元对象都再次被引用一次。此时“人员列表,查看”对应的享元对象当前被引用次数为3;“薪资数据,查看”对应的享元对象当前被引用次数为2;“薪资数据,修改”对应的享元对象当前被引用次数为2。
(4)Client继续运行,执行那个循环,每次运行都只会影响到以“人员列表,查看”为key的享元对象的引用计数,每次增加1次,因此,循环3次后,以“人员列表,查看”为key的享元对象被引用的次数为3+3=6次了。
运行客户端测试,体会一下,你还可以在Client中加入让线程休息几秒,然后再运行访问权限的数据,这样的话,这些被使用的数据应该会重新计算开始计时的时间,去试试看。当然休息不要超过6秒,超过6秒就已经清除了。
20.3.4 享元模式的优缺点
享元模式的优点是:减少对象数量,节省内存空间。
可能有的朋友认为共享对象会浪费空间,但是如果这些对象频繁使用,那么其实是节省空间的。因为占用空间的大小等于每个对象实例占用的大小再乘以数量,对于享元对象来讲,基本上就只有一个实例,大大减少了享元对象的数量,并节省不少的内存空间。
节省的空间取决于以下几个因素:因为共享而减少的实例数目、每个实例本身所占用的空间。假如每个对象实例占用2个字节,如果不共享数量是100个,而共享后就只有一个了,那么节省的空间约等于(100-1)×2字节。
享元模式的缺点是:维护共享对象,需要额外开销。
如同前面演示的享元工厂,在维护共享对象的时候,如果功能复杂,会有很多额外的开销,比如有一个线程来维护垃圾回收。
20.3.5 思考享元模式
1.享元模式的本质
享元模式的本质:分离与共享。
分离的是对象状态中变与不变的部分,共享的是对象中不变的部分。享元模式的关键之处就在于分离变与不变,把不变的部分作为享元对象的内部状态,而变化部分则作为外部状态,由外部来维护,这样享元对象就能够被共享,从而减少对象数量,并节省大量的内存空间。
理解了这个本质后,在使用享元模式的时候,就会考虑,哪些状态需要分离?如何分离?分离后如何处理?哪些需要共享?如何管理共享的对象?外部如何使用共享的享元对象?是否需要不共享的对象?等等。
把这些问题都思考清楚,找到相应的解决方法,那么享元模式也就应用起来了,可能是标准的应用,也可能是变形的应用,但万变不离其宗。
2.何时选用享元模式
建议在以下情况中选用享元模式。
■ 如果一个应用程序使用了大量的细粒度对象,可以使用享元模式来减少对象数量。
■ 如果由于使用大量的对象,造成很大的存储开销,可以使用享元模式来减少对象数量,并节约内存。
■ 如果对象的大多数状态都可以转变为外部状态,比如通过计算得到,或是从外部传入等,可以使用享元模式来实现内部状态和外部状态的分离。
■ 如果不考虑对象的外部状态,可以用相对较少的共享对象取代很多组合对象,可以使用享元模式来共享对象,然后组合对象来使用这些共享对象。
20.3.6 相关模式
■ 享元模式与单例模式
这两个模式可以组合使用。
通常情况下,享元模式中的享元工厂可以实现成为单例。另外,享元工厂中缓存的享元对象,都是单实例的,可以看成是单例模式的一种变形控制,在享元工厂中来单例享元对象。
■ 享元模式与组合模式
这两个模式可以组合使用。
在享元模式中,存在不需要共享的享元实现,这些不需要共享的享元通常是对共享的享元对象的组合对象。也就是说,享元模式通常会和组合模式组合使用,来实现更复杂的对象层次结构。
■ 享元模式与状态模式
这两个模式可以组合使用。
可以使用享元模式来共享状态模式中的状态对象。通常在状态模式中,会存在数量很大的、细粒度的状态对象,而且它们基本上都是可以重复使用的,都是用来处理某一个固定的状态的,它们需要的数据通常都是由上下文传入,也就是变化部分都分离出去了,所以可以用享元模式来实现这些状态对象。
■ 享元模式与策略模式
这两个模式可以组合使用。
可以使用享元模式来实现策略模式中的策略对象。和状态模式一样,在策略模式中也存在大量细粒度的策略对象,它们需要的数据同样是从上下文传入的,所以可以使用享元模式来实现这些策略对象
