21.3 模 式 讲 解
21.3.1 认识解释器模式
1.解释器模式的功能
解释器模式使用解释器对象来表示和处理相应的语法规则,一般一个解释器处理一条语法规则。理论上来说,只要能用解释器对象把符合语法的表达式表示出来,而且能够构成抽象的语法树,那都可以使用解释器模式来处理。
2.语法规则和解释器
语法规则和解释器之间是有对应关系的,一般一个解释器处理一条语法规则,但是反过来并不成立,一条语法规则是可以有多种解释和处理的,也就是一条语法规则可以对应多个解释器对象。
3.上下文的公用性
上下文在解释器模式中起着非常重要的作用。由于上下文会被传递到所有的解释器中,因此可以在上下文中存储和访问解释器的状态,比如,前面的解释器可以存储一些数据在上下文中,后面的解释器就可以获取这些值。
另外还可以通过上下文传递一些在解释器外部,但是解释器需要的数据,也可以是一些全局的、公共的数据。
上下文还有一个功能,就是可以提供所有解释器对象的公共功能,类似于对象组合,而不是使用继承来获取公共功能,在每个解释器对象中都可以调用。
4.谁来构建抽象语法树
在前面的示例中,大家已经发现,自己在客户端手工构建抽象语法树,是很麻烦的,但是在解释器模式中,并没有涉及这部分功能,只是负责对构建好的抽象语法树进行解释处理。前面的测试简单,所以手工构建抽象语法树也不是特别困难的事,要是复杂了呢?如果还是手工创建,那跟修改解析xml的代码也差不了多少。后面会给大家介绍,可以提供解析器来实现把表达式转换成为抽象语法树。
还有一个问题,就是一条语法规则是可以对应多个解释器对象的,也就是说同一个元素,是可以转换成多个解释器对象的,这也就意味着同样一个表达式,是可以构成不同的抽象语法树的,这也造成构建抽象语法树变得很困难,而且工作量非常大。
5.谁负责解释操作
只要定义好了抽象语法树,肯定是解释器来负责解释执行。虽然有不同的语法规则,但是解释器不负责选择究竟用哪一个解释器对象来解释执行语法规则,选择解释器的功能在构建抽象语法树的时候就完成了。
所以解释器只要忠实地按照抽象语法树解释执行就可以了。
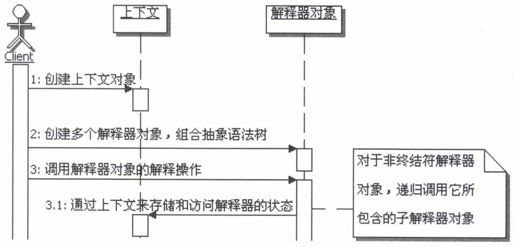
6.解释器模式的调用顺序示意图
解释器模式的调用顺序如图21.4所示。
21.3.2 读取多个元素或属性的值
前面介绍了如何获取单个元素的值和单个元素属性的值,下面应该来看看如何获取多个元素的值,还有多个元素中相同名称的属性的值。
获取多个值和前面获取单个值的实现思路大致相同,只是在取值的时候需要循环整个NodelList,依次取值,而不是只取出第一个来。当然,由于语法发生了变动,所以对应的解释器也需要发生改变。
首先是有了一个表示多个元素作为终结符的语法,比如“root/a/b/d$”中的“d$”;其次有了一个表示多个元素的属性作为终结符的语法,比如“root/a/b/d$.id$”中的“.id$”;最后还有一个表示多个元素,但不是终结符的语法,比如“root/a/b/d$.id$”中的“d$”。
还是看看代码示例吧,会比较清楚。
(1)解释器接口没有变化,原本定义的就是数组,提前做好准备了。
(2)读取xml的工具类XmlUtil也没有任何变化。
(3)上下文做了一点改变,改变如下。
■ 把原来用来记录上一次操作的元素,变成记录上一次操作的多个元素的集合,然后为它提供相应的getter/setter方法。
■ 原来根据父元素和当前元素的名称获取当前元素的方法,变成了根据父元素和当前元素的名称来获取多个元素。
■ 重新初始化上下文的方法里面,初始化的就是记录上一次操作的多个元素的这个集合了。
具体的Context类的代码示例如下:


(4)处理单个非终结符的对象ElementExpression,和以前处理单个元素相比,主要是现在需要面向多个父元素。但是由于是单个非终结符的处理,因此在多个父元素下面去查找符合要求的元素,找到一个就停止。示例代码如下:



(5)用来处理单个元素作为终结符的类也发生了一点改变,主要是从多个父元素去获取当前元素,如果当前元素是多个,就取第一个。示例代码如下:


(6)新添加一个解释器,用来解释处理以多个元素的属性作为终结符的情况,它的实现比较简单,只要获取到最后的多个元素对象,然后循环这些元素,一个一个取出相应的属性值就可以了。示例代码如下:

(7)新添加一个解释器,用来解释处理以多个元素作为终结符的情况。示例代码如下:

(8)新添加一个解释器,用来解释处理以多个元素作为非终结符的情况。它的实现类似于以单个元素作为非终结符的情况。只是这次处理的是多个,需要循环处理,同样需要维护子对象。在我们现在设计的语法中,多个元素后面是可以再加子元素的,最起码可以加多个属性的终结符对象。示例代码如下:




(9)终于可以写客户端来测试一下了,看看是否能实现期望的功能。先测试获取多个元素值的情况。示例代码如下:

测试结果如下:

接下来测试一下获取多个属性值的情况。示例代码如下:


测试结果如下:

也很简单吧。只要学会了处理单个的值,处理多个值也就变得容易了,把原来获取单个值的地方改成循环操作即可。
当然,如果要使用同一个上下文进行连续解析,是同样需要重新初始化上下文对象的。
提示
你还可以尝试一下,如果是想要获取多个元素下的,多个元素的同一个属性的值,能实现吗?自己去测试一下,应该是可以实现的。
21.3.3 解析器
前面是解释器部分的功能,只要构建好了抽象语法树,解释器就能够正确地解释并执行它,该如何得到这个抽象语法树呢?前面的测试都是人工组合好抽象语法树的,如果实际开发中还这样做,那么上工作量跟修改解析xml的代码差不多。
这就需要解析器出场了,这个程序专门负责把按照语法表达的表达式,解析转换成为解释器需要的抽象语法树。当然解析器是和表达式的语法以及解释器对象紧密关联的。
下面来示例一下解析器的实现,把符合前面定义的语法的表达式,转换成为前面实现的解释器的抽象语法树。解析器有很多种实现方式,没有什么定式,只要能完成相应的功能即可,比如表驱动、语法分析生成程序等。这里的示例采用自己来分解表达式以实现构建抽象语法树的功能,没有使用递归,是采用循环实现的。当然也可以用递归来做。
(1)解析器的实现思路。
要实现解析器也不复杂,大约有以下三个步骤。
⑴把客户端传递来的表达式进行分解,分解成为一个一个的元素,并用一个对应的解析模型来封装这个元素的一些信息。
⑵根据每个元素的信息,转化成相对应的解析器对象。
⑶按照先后顺序,把这些解析器对象组合起来,就得到抽象语法树了。
可能有朋友会说,为什么不把步骤⑴和步骤⑵合并,直接分解出一个元素就转换成相应的解析器对象呢?原因有两个。
■ 其一是功能分离,不要让一个方法的功能过于复杂;
■ 其二是为了今后的修改和扩展,现在语法简单,所以转换成解析器对象需要考虑的东西少,直接转换也不难,但要是语法复杂了,直接转换就很杂乱了。
事实上,封装解析属性的数据模型充当了步骤⑴和步骤⑵操作间的接口,使步骤⑴和步骤⑵都变简单了。
(2)下面来看看用来封装每一个解析出来的元素对应的属性对象。示例代码如下:


(3)看看解析器的实现,代码稍微复杂点,注释很详尽。为了整体展示解析器,就不去分开每步单讲了。
注意
不过要注意一点,下面这种实现没有考虑并发处理的情况。如果要用在多线程环境下,需要补充相应的处理,特别提示一下。
示例代码如下:










(4)看完这个稍长点的解析器程序,该来体会一下,有了它对我们的开发有什么好处?写个客户端来测试看看。现在的客户端就非常简单了,主要有以下三步。
⑴首先是设计好想要取值的表达式。
⑵然后是通过解析器解析获取抽象语法树。
⑶最后就是请求解释器解释并执行这个抽象语法树,便得到最后的结果了。
客户端测试的示例代码如下:

这样就简单多了吧!通过使用解释器模式,自行设计一种简单的语法,就可以用很简单的表达式来获取你想要的xml中的值了。有的朋友可能会想到XPath,没错,本章示例实现的功能就是类似于XPath的部分功能。
如果今后xml的结构要是发生了变化,或者是想要获取不同的值,基本上就是修改那个表达式而已,你可以试试看,能否完成前面实现过的功能。比如
■ 想要获取c元素的值,表达式为“root/a/b/c”;
■ 想要获取c元素的name属性值,表达式为“root/a/b/c.name”;
■ 想要获取d元素的值,表达式为“root/a/b/d$”,获取d的属性上面已经测试了。
21.3.4 解释器模式的优缺点
解释器模式有以下优点。
■ 易于实现语法
在解释器模式中,一条语法规则用一个解释器对象来解释执行。对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就可以了,其他的都不用管。
■ 易于扩展新的语法
正是由于采用一个解释器对象负责一条语法规则的方式,使得扩展新的语法非常容易。扩展了新的语法,只需要创建相应的解释器对象,在创建抽象语法树的时候使用这个新的解释器对象就可以了。
解释器模式的缺点是不适合复杂的语法。
如果语法特别复杂,构建解释器模式需要的抽象语法树的工作是非常艰巨的,再加上有可能会需要构建多个抽象语法树。所以解释器模式不太适合于复杂的语法,对于复杂的语法,使用语法分析程序或编译器生成器可能会更好一些。
21.3.5 思考解释器模式
1.解释器模式的本质
解释器模式的本质:分离实现,解释执行。
解释器模式通过一个解释器对象处理一个语法规则的方式,把复杂的功能分离开;然后选择需要被执行的功能,并把这些功能组合成为需要被解释执行的抽象语法树;再按照抽象语法树来解释执行,实现相应的功能。
认识这个本质对于识别和变形使用解释器模式是很有作用的。从表面上看,解释器模式关注的是我们平时不太用到的自定义语法的处理;但从实质上看,解释器模式的思路仍然是分离、封装、简化,和很多模式是一样的。
比如,可以使用解释器模式模拟状态模式的功能。如果把解释器模式要处理的语法简化到只有一个状态标记,把解释器看成是对状态的处理对象,对同一个表示状态的语法,可以有很多不同的解释器,也就是有很多不同的处理状态的对象,然后在创建抽象语法树的时候,简化成根据状态的标记来创建相应的解释器,不用再构建树了。看看这样简化下来,是不是可以用解释器模拟出状态模式的功能呢?
同理,解释器模式可以模拟实现策略模式的功能、装饰器模式的功能等,尤其是模拟装饰器模式的功能,构建抽象语法树的过程,自然就对应成为组合装饰器的过程。
2.何时选用解释器模式
建议在以下情况中选用解释器模式。
当有一个语言需要解释执行,并且可以将该语言中的句子表示为一个抽象语法树的时候,可以考虑使用解释器模式。
在使用解释器模式的时候,还有两个特点需要考虑,一个是语法相对应该比较简单,太复杂的语法不适合使用解释器模式;另一个是效率要求不是很高,对效率要求很高的情况下,不适合使用解释器模式。
21.3.6 相关模式
■ 解释器模式和组合模式
这两个模式可以组合使用。
通常解释器模式都会使用组合模式来实现,这样能够方便地构建抽象语法树。一般非终结符解释器就相当于组合模式中的组合对象;终结符解释器就相当于叶子对象。
■ 解释器模式和迭代器模式
这两个模式可以组合使用。
由于解释器模式通常使用组合模式来实现,因此在遍历整个对象结构的时候,自然可以使用迭代器模式。
■ 解释器模式和享元模式
这两个模式可以组合使用。
在使用解释器模式的时候,可能会造成多个细粒度对象,比如,会有各种各样的终结符解释器,而这些终结符解释器对不同的表达式来说是一样的,是可以共用的,因此可以引入享元模式来共享这些对象。
■ 解释器模式和访问者模式
这两个模式可以组合使用。
在解释器模式中,语法规则和解释器对象是有对应关系的。语法规则的变动意味着功能的变化,自然会导致使用不同的解释器对象;而且一个语法规则可以被不同的解释器解释执行。
因此在构建抽象语法树的时候,如果每个节点所对应的解释器对象是固定的,这就意味着该节点对应的功能是固定的,那么就不得不根据需要来构建不同的抽象语法树。
为了让构建的抽象语法树较为通用,那就要求解释器的功能不要那么固定,要能很方便地改变解释器的功能,这个时候问题就变成了如何能够很方便地更改树形结构中节点对象的功能了,访问者模式可以很好地实现这个功能。
