1.2 分布式产品Hadoop、ZooKeeper、HBase概述
1.Hadoop
说到云计算技术和产品,不能不提到Google这家企业。曾经,微软是IT行业的象征,号称只招最聪明的人。十年后,微软逐渐疲软了下来,Google这家企业取而代之号称只招最聪明的人。
从搜索引擎到卫星地图,到云计算,到风靡世界的Android,到现在的无人汽车、Google眼镜,以及传说中的机器人之父和在他家里满地爬的机器人……这个行业总有这么一家企业成为最高科技的领袖,控制着大部分的核心技术,聚拢着大部分的一流人才,垄断着最大份额的市场,几乎让其他公司望而却步。
因此,我们不难理解这个行业的结果,第一的企业吃肉,第二喝点汤,其他都亏损。
也许在学校读书时,考试成绩前十名都是好学生,但是IT行业的社会竞争,必须要做到第一,成为所在领域的老大才有利可图。
再简单回顾一下云计算相关技术产品的发展史:
❏ 2002~2004:Apache Nutch。
❏ 2004~2006:Google发表GFS和MapReduce相关论文。Apache在Nutch中实现HDFS和MapReduce。
❏ 2006~2008:Hadoop项目从Nutch中分离。
❏ 2008年7月,Hadoop赢得Terabyte Sort Benchmark。
从上面我们可以看到早在2004~2006年,Google就发表了两篇与GFS和MapReduce相关的论文,分别是分布式文件系统和基于它的Map/Reduce并行计算。Apache的开源项目Hadoop便是根据这两篇论文的思想实现的Java版本,Hadoop引起关注是在它赢得了一次TB排序比赛:Hadoop Wins Terabyte Sort Benchmark:One of Yahoo's Hadoop clusters sorted 1 terabyte of data in 209 seconds,which beat the previous record of 297 seconds in the annual general purpose(Daytona)terabyte sort benchmark.This is the first time that either a Java or an open source program has won.
用了大量的机器在209秒完成1TB排序,提升了之前297秒的记录。
值的一提的是,Hadoop的作者Doug Cutting同时也是Lucene和Nutch的作者,早年供职Yahoo,后来担任Apache软件基金会主席。
Hadoop的名字来源于Doug Cutting儿子的一个宠物名。Hadoop从最初的HDFS分布式文件系统发展到后来的Hadoop+ZooKeeper+Hive+Pig+HBase生态体系。
HDFS提供了一个可扩缩的、容错的、可以在廉价机器上运行的分布式文件系统,按行进行存储,按64MB块进行文件拆分。
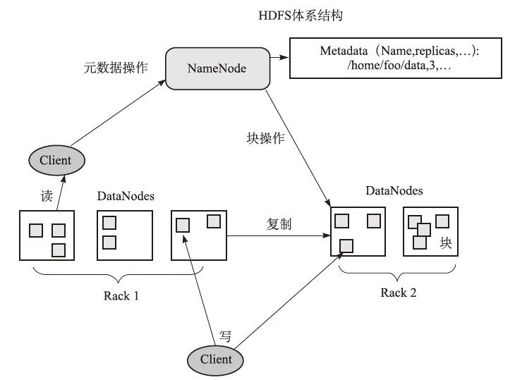
图1-5 HDFS体系结构
我们可以看到,HDFS的架构是一个NameNode和多个DataNode的结构(参见图1-5):
❏ NameNode
存储HDFS的元数据(metadata)。
管理文件系统的命名空间(namespace)。
创建、删除、移动、重命名文件和文件夹。
接收从DataNode来的Heartbeat和Blockreport。
❏ DataNode
存储数据块。
执行从NameNode来的文件操作命令。
定时向NameNode发送Heartbeat和Blockreport。
除了提供分布式文件存储外,Hadoop还提供基于Map/Reduce的框架,进行按行的并行分析,可以用来查询和计算。
图1-6是以Word Count为例子演示Map/Reduce机制的图,学习过Hadoop的人一般都看到过,有趣的是,我们在2.1.4节也会基于Fourinone的方式实现一个Word Count。
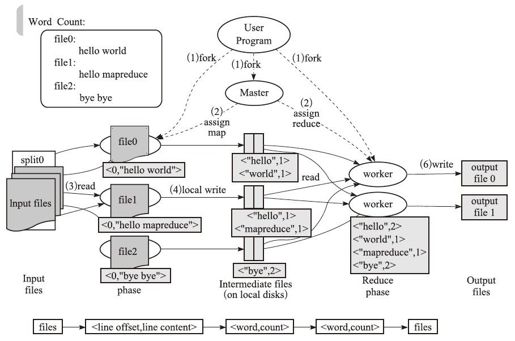
图1-6 Word Count
图1-7中Hadoop的Map/Reduce实际上是1.0版,也许Hadoop项目组也意识到该框架的局限性,在目前Map/Reduce2.0(Yarn)版中实际上已经完全进行了重构,整个设计思想是做成一个资源和任务的调度框架,再也不是Google的Map/Reduce相关论文阐述的内容了。关于Yarn我们在7.4.2节也会谈到。
关于Hadoop的详细资料可以参考以下信息:
http://hadoop.apache.org/hdfs/docs/current/hdfs_design.html
http://labs.google.com/papers/gfs.html
2.ZooKeeper
ZooKeeper在Hadoop生态体系中是作为协同系统出现的,为什么会独立出一个协同系统呢?我们看看跟分布式协同相关的一些重要概念。
❏ 分布式协同系统:大型分布式应用通常需要调度器、控制器、协同器等管理任务进程的资源分配和任务调度,为避免大多数应用将协同器嵌入调度控制等实现中,造成系统扩充困难、开发维护成本高,通常将协同器独立出来设计成为通用、可伸缩的协同系统。
❏ ZooKeeper:Hadoop生态系统的协同实现,提供协调服务,包括分布式锁、统一命名等。
❏ Chubby:Google分布式系统中的协同实现和ZooKeeper类似。
❏ Paxos算法:1989年由莱斯利·兰伯特提出,此算法被认为是处理分布式系统消息传递一致性的最好算法。
❏ 领导者选举:计算机集群中通常需要维持一个领导者的服务器,它负责进行集群管理和调度等,因此集群需要在启动和运行等各个阶段保证有一个领导者提供服务,并且在发生故障和故障恢复后能重新选择领导者。
当前业界分布式协同系统的主要实现有ZooKeeper和Chubby,ZooKeeper实际上是Google的Chubby的一个开源实现。ZooKeeper的配置中心实现更像一个文件系统,文件系统中的所有文件形成一个树形结构,ZooKeeper维护着这样的树形层次结构,树中的结点称为znode,每个znode存储的数据有小于1MB的大小限制。ZooKeeper提供了几种znode类型:临时znode、持久znode、顺序znode等,用于不同的一致性需求。在znode发生变化时,通过“观察”(watch)机制可以让客户端得到通知。可以针对ZooKeeper服务的“操作”来设置观察,该服务的其他操作可以触发观察。ZooKeeper服务的“操作”包括一些对znode添加修改获取操作。ZooKeeper采用一种类似Paxos的算法实现领导者选举,以解决集群宕机的一致性和协同保障。总体上说,ZooKeeper提供了一个分布式协同系统,包括配置维护、名字服务、分布式同步、组服务等功能,并将相关操作接口提供给用户。
ZooKeeper的结构如图1-7所示。
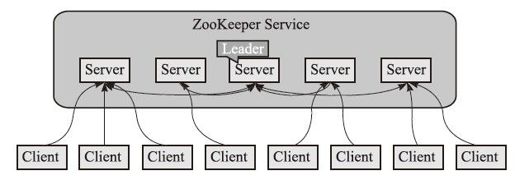
图1-7 ZooKeeper的结构示意
ZooKeeper大致工作过程如下:
1)启动ZooKeeper服务器集群环境后,多个ZooKeeper服务器在工作前会选举出一个Leader,若在接下来的工作中这个被选举出来的Leader死了,而剩下的ZooKeeper服务器会知道这个Leader死掉了,系统会在活着的ZooKeeper集群中会继续选出一个Leader,选举出Leader的目的是在分布式的环境中保证数据的一致性。
2)另外,ZooKeeper支持watch(观察)的概念。客户端可以在每个znode结点上设置一个watch。如果被观察服务端的znode结点有变更,那么watch就会被触发,这个watch所属的客户端将接收到一个通知包被告知结点已经发生变化。若客户端和所连接的ZooKeeper服务器断开连接时,其他客户端也会收到一个通知,也就是说一个ZooKeeper服务器端可以服务于多个客户端,当然也可以是多个ZooKeeper服务器端服务于多个客户端。
我们这里只是讲述了ZooKeeper协同的基本概念,第3章我们还会详细讲如何实现这样的协同系统,并与ZooKeeper进行一些对比。
3.HBase
HBase是NoSQL技术的产物,NoSQL风行后,很多互联网应用需要一个面向键/值的列存储数据库,并可以支持水平扩充,当然Google在这个领域又走在了前面。
HBase是Google Bigtable的开源实现。Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用ZooKeeper作为对应的功能。
图1-8是HBase的架构,里面的HDFS也就是Hadoop中的分布式文件系统。对里面主要的核心组件简单介绍如下:
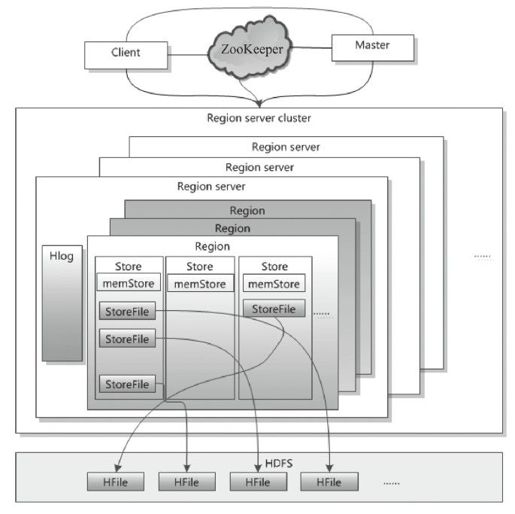
图1-8 HBase
(1)Client
Client包含访问HBase的接口,维护着一些cache来加快对HBase的访问,比如Regione的位置信息。
(2)ZooKeeper
保证任何时候,集群中都只有一个Master。存储所有Region的寻址入口。实时监控Region server的状态,将Region server的上线和下线信息实时通知给Master。存储HBase的schema包括有哪些表,每个表有哪些列。
(3)Master
为Region server分配Region。负责Region server的负载均衡。发现失效的Region server并重新分配其上的Region。GFS上的垃圾文件回收。处理schema更新请求。
(4)Region server
Region server维护Master分配给它的Region,处理对这些Region的IO请求。Region server负责切分在运行过程中变得过大的Region。
我们走马观花般地过了一遍Hadoop主要的技术和产品,当然Hadoop体系包括的还有很多,我们只是描述了它最主要的部分,图1-9是Hadoop产品的生态图,有十多个,估计需要工程师们挑灯苦学了。
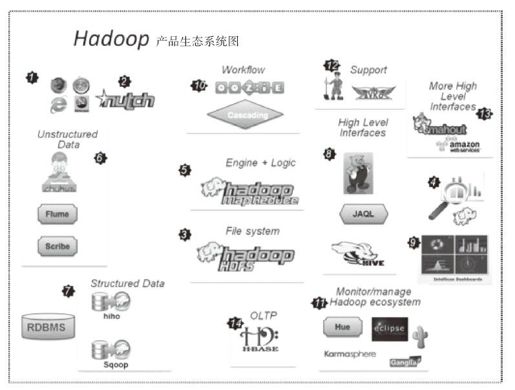
图1-9 Hadoop产品生态环境
