6.11 基于整型读写的上亿排序
在第2章我们讲述了一个上亿排序的例子,那是基于内存方式的,那么在真实的场景中,数据到达一定的量级后,仅使用内存方式是很难完成的,本节我们基于本章学习的文件和整型数据操作,来实现一个更接近真实场景的上亿数据排序的例子。
根据第2章上亿排序的例子中的分类规则,我们知道,每台计算机的内存有限,我们必须设置好一个最小处理单元,按照最小处理单元来分类、合并,最后在最小处理单元内排序,我们下面举例说明。
假设有一台计算机,上面有2500万数据,要将这2500万数据直接导入内存排序是不行的,因为内存太小,每次最多只能处理625万的数据排序,那么625万就是一个最小处理单元。我们需要将2500万数据按照取值范围分成4类,每类大约625万,然后逐个排序。如果数据的取值范围均匀地分布在0~10万内,那么可以按如下进行分类。
❏ 0~25000内的数据:大约625万,导入内存排序
❏ 25000~50000内的数据:大约625万,导入内存排序
❏ 50000~75000内的数据:大约625万,导入内存排序
❏ 75000~100000内的数据:大约625万,导入内存排序
虽然我们的内存有限,但是只要划分好数据分类,最后还是能利用有限的内存得到整体排序的结果。
上面的例子只是针对单台计算机的,如果我们有更多的数据,这些数据分布存储在多台计算机上,那么分类和排序过程就更加复杂了,比如有1亿数据分布存储在4台计算机上,每台计算机存储2500万,要求这1亿数据整体排序,那么按照第2章上亿排序的思路,需要进行如下分类拆分和合并:
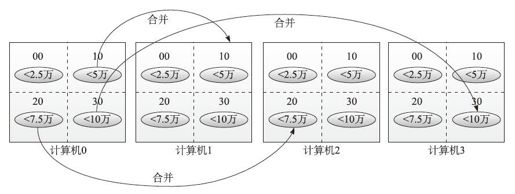
图6-9 整型文件排序1
从图6-9我们可以看到每台计算机将各自的2500万数据分成了4类,在实现上,分别将数据分到4个文件中去,依次是:
❏ 00文件,装0~25000内的数据。
❏ 10文件,装25000~50000内的数据。
❏ 20文件,装50000~75000内的数据。
❏ 30文件,装75000~100000内的数据。
然后我们可以看到,对于00文件,每台计算机都有一个,我们可以指定每台计算机负责收集一个分类,比如第0台计算机负责收集00文件(25000内的数据),第1台计算机负责收集10文件(50000内的数据)……为了达到收集目的,各计算机之间需要进行互相合并,将属于其他计算机的分类发给对方,过程如下:
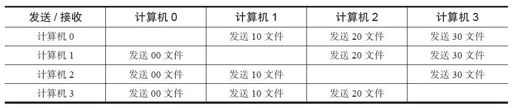
也就是每台计算机发送分类文件给相应的其他计算机时,同时也接收其他计算机发给属于自己的分类文件,并将文件追加到本地该分类文件中。该过程完成后,形成以下结果:

在完成合并后,每台计算机只剩下属于自己分类的文件,由于每个文件内的数据范围都是划分好的,此时再对每个文件进行内存排序就可以得到整体的排序数据了。
这里会有个问题,我们从最开始的每台计算机将数据分类成4个文件,到最后合并为1个文件,如果数据均匀分布,文件还是大约有2500万数据,按照我们之前的假设,每台计算机的内存最多只能处理625万的数据排序,那么对于2500万的大数据文件,仍然无法将其加载到内存中一次性完成。
这个时候又涉及之前我们提到的最小处理单元的问题了,现在的最小处理单元还是2500万,如果需要降低到625万,我们要重新对数据进行分类,如图6-10所示。
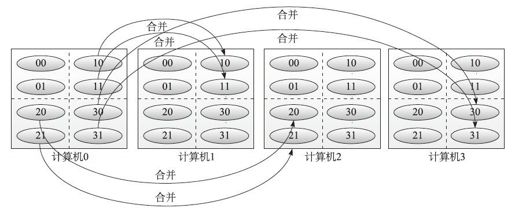
图6-10 整型文件排序2
如果我们将每台计算机上2500万数据分成8类,计算机0负责收集00、01分类文件、计算机1负责收集10、11文件……然后互相合并完成,最后每台计算机上剩下2个分类文件,每类文件有1250万数据,降低了一倍最小处理单元。按照该思路,如果将每台计算机上2500万数据分类16类,那最后每台计算机就剩下4个分类文件,每个文件有625万数据,就刚好达到我们的内存能接受的大小了。
但是我们要注意,分类越多意味着合并的过程越长,耗用网络发送文件越多,对排序性能会有影响,因此要在内存处理最小单元和分类数量之间权衡尝试,以达到性能最优化。
下面的demo完整演示了以上介绍的基于文件方式排序的思路。
❏ SortFileData:负责原始数据的生成和排序结果的验证,creatData方法按照每50万一批生成10000000范围内的随机整数到指定数据文件中,累计生成4个各自包含2500万整数的数据文件,用于模拟排序计算。在完成了排序后,可以通过checkData抽取前100个数字进行结果验证。
❏ SortFileCtor:是一个工头实现,它先后发出"分类"、"合并"、"排序"三个环节的调度命令,指挥工人完成整个排序过程,在每个环节都使用doTaskBatch的栅栏机制,等待该环节结束再进行下一步,最后输出整体结果和耗用时间。
❏ SortFileWorker:是一个工人实现,相应于工头的三个环节调度命令进行实现,SortFileWorker的构造函数有4个重要参数:
- SortFileWorker(int n, int max, int every, String path)
其中4个参数依次代表"分成多少类、随机数据范围、每次处理多少数据、输入数据文件",这4个参数会影响到排序过程中的相关计算。除此外,当前计算机在集群中的位置也是重要的计算参数,在程序中是通过index=getSelfIndex();获取的。
在doTask实现中首先获取int step=(Integer)wh.getObj("step");,得到工头调度命令,然后判断step的值进行每个环节的任务处理。
对于step==1,进行分类环节。从数据文件中按照每批读取every数量的整数,先放到warehouse中,然后根据分类写入到不同的分类文件中去,完成分类环节。
对于step==2,进行合并环节。合并环节会计算每个分类文件所属哪台计算机,然后调用对方工人的receive方法传递分类文件数据,同时,对于其他计算机工人传递给自己的文件数据,在receive方法中进行实现,将接收到的数据追加写入到本地文件中去。
对于step==3,进行排序环节。将本地的分类文件读到ListInt中进行内存排序,然后再写回结果到分类文件中。最后统计当前工人完成的排序总数并返回给工头。
下面介绍具体的运行步骤。
1)启动ParkServerDemo:
- java -cp fourinone.jar; ParkServerDemo
2)启动SortFileData,结果如图6-11所示。
- java -cp fourinone.jar; SortFileData
图6-11 启动SortFileData
SortFileData在运行data的目录下建立了4个文件夹2008、2009、2010、2011,每个文件夹下面创建了一个data文件,写入2500万整型数据。然后验证这些数据是随机无序的。
3)启动SortFileWorker:
- java -cp fourinone.jar; SortFileWorker localhost 2008 4 10000000 500000 data\\2008\\data
- java -cp fourinone.jar; SortFileWorker localhost 2009 4 10000000 500000 data\\2009\\data
- java -cp fourinone.jar; SortFileWorker localhost 2010 4 10000000 500000 data\\2010\\data
- java -cp fourinone.jar; SortFileWorker localhost 2011 4 10000000 500000 data\\2011\\data
我们启动了4个工人实例,为了方便在本地演示,使用locahost和不同端口号区分,分别占用2008、2009、2010、2011端口,跟上面建立的各数据文件对应,除此之外,“410000000500000”这三个运行传入的参数,分别代表了“分类数、数据取值范围、每次处理多少数据”,用来构造SortFileWorker。启动完成后如图6-12所示。
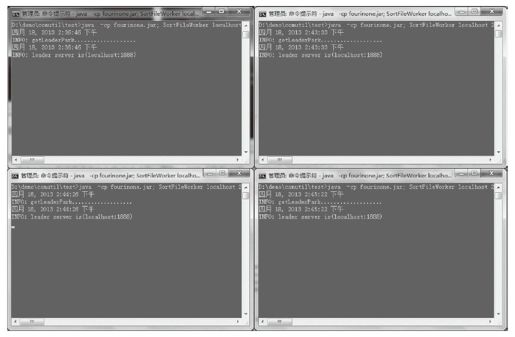
图6-12 启动SortFileWorker
4)启动SortFileCtor:
- java -cp fourinone.jar; SortFileCtor
工头运行后,调度每个工人进行并行计算,可以看到当完成三个环节步骤之后,各工人窗口输出了排序的过程,如图6-13所示。
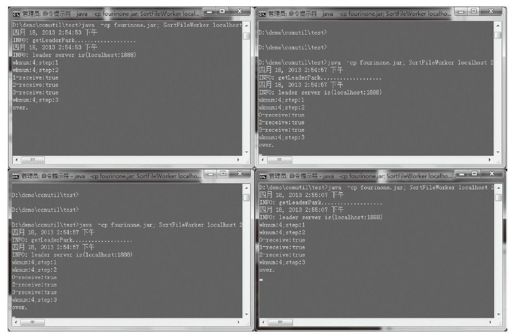
图6-13 SortFileWorker结果
同时,工头窗口也输出了最后的统计和整体时间,1亿个整数排序时间大约在37秒,用了单机4个工人实例,普通pc配置(2.4GHz CPU,4G内存),如图6-14所示。

图6-14 运行SortFileCtor
我们再打开数据存放目录,发现每个工人目录的output目录下都有一个排序结果的数据文件,我们抽取4个工人目录下排序结果的前100条数据验证,如图6-15所示
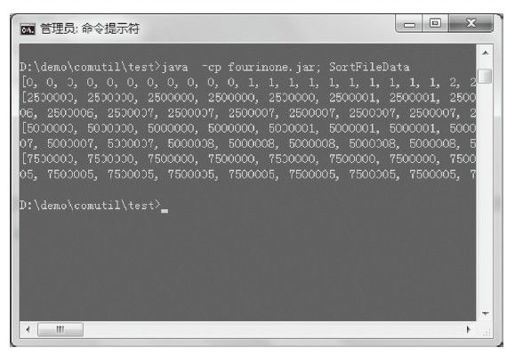
图6-15 排序结果验证
可以看到,原始1亿条整型数据,按照(0,2500000,5000000,7500000,10000000)的区间被拆分成4个文件(00,10,20,30)存放,每个文件内部都是区间内排序好的,4个文件合起来,就是完整的1亿条整型数据排序结果。
前面我们分析过,如果内存小,可以将分类分的更细降低最小处理单元大小,下面我们看看分类数为8的情况。
1)启动SortFileWorker:
- java -cp fourinone.jar; SortFileWorker localhost 2008 8 10000000 500000 data\\2008\\data
- java -cp fourinone.jar; SortFileWorker localhost 2009 8 10000000 500000 data\\2009\\data
- java -cp fourinone.jar; SortFileWorker localhost 2010 8 10000000 500000 data\\2010\\data
- java -cp fourinone.jar; SortFileWorker localhost 2011 8 10000000 500000 data\\2011\\data
除了第3个参数从"4"改为"8"外,其他参数不变,然后我们再运行一下工头执行计算。
2)启动SortFileCtor:
- java -cp fourinone.jar; SortFileCtor
可以查看到各工人窗口输出的排序过程,如图6-16所示。
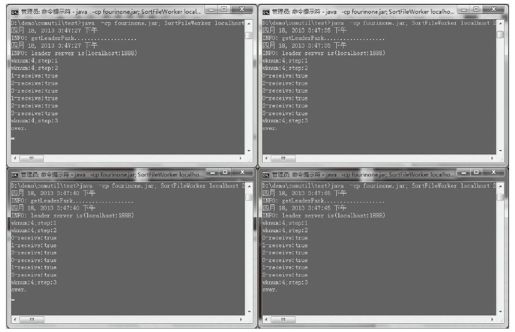
图6-16 8个分类工人运行结果
我们发现分类数为8后,工人之间合并的环节耗时更多,因为生成了更多分类文件,需要更多的文件合并传送。
同时我们查看工头的窗口输出,如图6-17所示。

图6-17 8个分类工头运行结果
发现整体的排序时间为43秒,比起之前4个分类的37秒要长,主要是合并环节更加耗用时间。因此,虽然分类多会减轻内存的负担,降低内存最小排序处理单元大小,但是也会耗用更多的时间在文件网络传送和文件IO读写上。
我们打开output结果目录,发现每个目录下有两个分类的结果文件,我们抽取各个文件夹下面两个分类文件的前100条验证结果,如图6-18所示。

图6-18 8个分类排序的结果验证
我们发现分类从4个区间变成了8个区间:(0,1250000,2500000,3750000,5000000,6250000,7500000,8750000,10000000),每个区间的数据量也减少了将近一倍,这样更有利于我们做分布式存储和计算。
不仅是分类数可以根据内存大小调整,也可以调整工人数量,采取多机多实例n×n的方式调整并观察性能效果,最后得到一个最优的排序计算参数。
完整demo源码如下:
- // ParkServerDemo
- import com.fourinone.BeanContext;
- public class ParkServerDemo
- {
- public static void main(String[] args)
- {
- BeanContext.startPark();
- }
- }
- // SortFileData
- import com.fourinone.FileAdapter;
- import com.fourinone.FileAdapter.IntReadAdapter;
- import com.fourinone.FileAdapter.IntWriteAdapter;
- import java.util.Random;
- import java.util.List;
- public class SortFileData
- {
- public static void creatData(int total, int max, String path)
- {
- System.out.println("create "+total+" number(max:"+max+") to "+path+"...");
- int every = 500000;
- FileAdapter fa = new FileAdapter(path);
- fa.delete();
- Random rad = new Random();
- while(total>0){
- IntWriteAdapter wa = fa.getIntWriter();
- int[] nums = new int[total-every<0?total:every];
- for(int i=0;i<nums.length;i++){
- nums[i]=rad.nextInt(max);
- }
- wa.writeInt(nums);
- total-=nums.length;
- }
- System.out.println("create done.");
- fa.close();
- }
- public static void checkData(String path)
- {
- FileAdapter fa = new FileAdapter(path);
- List<Integer> rls = fa.getIntReader(0,100).readListIntAll();
- System.out.println(rls+"...");
- }
- public static void main(String[] args)
- {
- creatData(25000000,10000000,"data\\2008\\data");
- checkData("data\\2008\\data");
- creatData(25000000,10000000,"data\\2009\\data");
- checkData("data\\2009\\data");
- creatData(25000000,10000000,"data\\2010\\data");
- checkData("data\\2010\\data");
- creatData(25000000,10000000,"data\\2011\\data");
- checkData("data\\2011\\data");
- }
- }
- // SortFileWorker
- import com.fourinone.MigrantWorker;
- import com.fourinone.WareHouse;
- import com.fourinone.Workman;
- import com.fourinone.FileAdapter;
- import com.fourinone.FileAdapter.ReadAdapter;
- import com.fourinone.FileAdapter.WriteAdapter;
- import com.fourinone.FileAdapter.IntReadAdapter;
- import com.fourinone.FileAdapter.IntWriteAdapter;
- import com.fourinone.ArrayAdapter;
- import com.fourinone.ArrayAdapter.ListInt;
- import java.io.File;
- import java.util.List;
- import java.util.ArrayList;
- import java.util.HashMap;
- import java.util.Random;
- public class SortFileWorker extends MigrantWorker
- {
- private int n=-1,max=-1,every=-1,m=-1,index=-1;
- private String path;
- private HashMap<Integer,List<Integer>> wharr=new HashMap<Integer,List <Integer>>();
- private Random rad = new Random();
- private Workman[] wms = null;
- private FileAdapter[] faws = null;
- public SortFileWorker(int n, int max, int every, String path){
- this.n = n;
- this.max = max;
- this.every = every;
- this.path = path;
- faws = new FileAdapter[n];
- }
- public WareHouse doTask(WareHouse wh){
- try{
- int step = (Integer)wh.getObj("step");
- if(wms==null){
- wms = getWorkerAll();
- m = wms.length;
- for(int l=0;l<n;l++){
- faws[l] =newFileAdapter(new File(path).getParent()+"\\ output\\"+l*m/n+l%(n/m));//"output/"+l*m/n+l%(n/m)
- faws[l].delete();
- }
- }
- index = getSelfIndex();
- System.out.println("wknum:"+m+";step:"+step);
- WareHouse resultWh = new WareHouse("ok",1);
- if(step==1){
- FileAdapter fa = new FileAdapter(path);
- IntReadAdapter ira = null;
- int begin = 0;
- int[] rls = null;
- while(true){
- ira = fa.getIntReader(begin,every);
- rls = ira.readIntAll();
- if(rls!=null){
- for(int i:rls){
- Integer numi = (int)(new Long(i)*new Long(n)/new Long(max));
- List<Integer> arr = wharr.get(numi);
- if(arr==null)
- arr = new ArrayList<Integer>();
- arr.add(i);
- wharr.put(numi, arr);
- }
- for(int j=0;j<n;j++){
- if(wharr.containsKey(j))
- faws[j].getIntWriter().writeListInt(wharr.remove(j));
- }
- begin+=rls.length;
- }else break;
- }
- fa.close();
- }else if(step==2){
- for(int j=0;j<n/m;j++){
- for(int i=0;i<m;i++){
- if(i!=index){
- if(faws[i*n/m+j].exists()){
- int[] itsn = faws[i*n/m+j].getIntReader().readIntAll();
- Workman wm = wms[i];
- WareHouse whij = new WareHouse();
- whij.put("i",i);
- whij.put("j",j);
- whij.put("v",itsn);
- System.out.println(i+"-receive:"+wm.receive(whij));
- faws[i*n/m+j].close();
- }
- }
- }
- }
- }else if(step==3){
- int[] arrl = null;
- int total = 0;
- for(int j=0;j<n/m;j++){
- if(faws[index*n/m+j].exists()){
- arrl = faws[index*n/m+j].getIntReader().readIntAll();
- ListInt is = ArrayAdapter.getListInt();
- is.sort(arrl);
- total+=arrl.length;
- faws[index*n/m+j].getIntWriter(0,arrl.length).writeInt(arrl);
- faws[index*n/m+j].close();
- }
- for(int i=0;i<m;i++)
- if(i!=index&&faws[i*n/m+j].exists())
- faws[i*n/m+j].delete();
- }
- resultWh.setObj("total",total);
- System.out.println("over.");
- }
- return resultWh;
- }catch(Exception ex){
- System.out.println(ex);
- return null;
- }
- }
- protected boolean receive(WareHouse inhouse)
- {
- Integer i = (Integer)inhouse.get("i");
- Integer j = (Integer)inhouse.get("j");
- int[] v = (int[])inhouse.get("v");
- faws[i*n/m+j].getIntWriter().writeInt(v);
- return true;
- }
- public static void main(String[] args)
- {
- SortFileWorker mw = new SortFileWorker(Integer.parseInt(args[2]),Integer. parseInt(args[3]),Integer.parseInt(args[4]),args[5]);
- mw.waitWorking(args[0],Integer.parseInt(args[1]),"SortWorker");
- }
- }
- // SortFileCtor
- import com.fourinone.Contractor;
- import com.fourinone.WareHouse;
- import com.fourinone.WorkerLocal;
- import java.util.Date;
- public class SortFileCtor extends Contractor
- {
- public WareHouse giveTask(WareHouse wh)
- {
- WorkerLocal[] wks = getWaitingWorkers("SortWorker");
- System.out.println("wks.length:"+wks.length+";"+wh);
- int total=0;
- wh.setObj("step", 1);//1:group;
- doTaskBatch(wks, wh);
- wh.setObj("step", 2);//2:merge;
- doTaskBatch(wks, wh);
- wh.setObj("step", 3);//3:sort
- WareHouse[] hmarr = doTaskBatch(wks, wh);
- for(int i=0;i<hmarr.length;i++){
- Object num = hmarr[i].getObj("total");
- if(num!=null)
- total+=(Integer)num;
- }
- wh.setObj("total",total);
- return wh;
- }
- public static void main(String[] args)
- {
- Contractor a = new SortFileCtor();
- WareHouse wh = new WareHouse();
- long begin = (new Date()).getTime();
- a.doProject(wh);
- long end = (new Date()).getTime();
- System.out.println("total:"+wh.getObj("total")+",time:"+(end- begin)/1000+"s");
- }
- }
