2.1.7 计算集群模式和兼容遗留计算系统
从上面我们知道多个包工头外部可以分环节处理,虽然每个包工头可以调用多个工人并行处理,但是多个包工头之间是一种串式处理,我们能否让多个包工头之间也并行处理呢?比如一个包工头带领几个工人做饭,另外一个包工头带领几个工人炒菜,做饭和炒菜不需要先后顺序,可以并行进行。
曾经收到一些开发者的反馈,说框架应该增加一个总工头角色,总工头可以给多个工头分配任务,再由每个工头给多个工人分配任务,最后所有工人和工头都是并行作业。
我们顺着这个思路完善,如果总工头分配了任务,各个工头完成后,需要任务合并怎么办,都汇集到总工头这个角色来合并吗,这样对于数据大的结果并不妥,各工头之间能否合并呢,如果要支持,那么是否跟工人之间的合并机制类似了呢,能否避免重复设计?
另外,随着计算集群的扩充,总工头负责的计算任务的范围也需要扩大,能否不改变设计便集成到另外一个包括它的计算集群中去,那么是否还需要总-总工头,总工头上面又总工头,总工头和总工头之间是否也要考虑增加合并机制呢?
这样设计会越来越复杂和臃肿。
实际上灵活运用工头工人组合机制就可以解决这个问题,组成计算集群模式不需要额外设计其他角色。如图2-8所示。
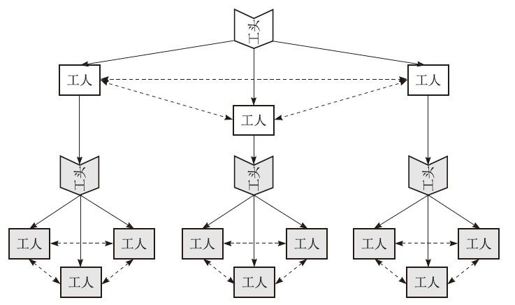
图2-8 计算集群模式
我们通过图2-8可以看到:这里总共示范了4组“工头-工人”计算单元,它们之间是有层级的,下面阴影部分的3组计算单元是任务执行者,上面白色部分相当于一个“总工头”角色,我们发现它是通过上层工人调用下层工头方式集成其他并行计算单元的,在工人的doTask实现内部,新增一个其他计算单元的工头类,管理该工头的生命周期,并且等待该工头完成并行计算任务后,获取结果,这个中间结果可以返回给最上层的工头汇总,也可以上层工人之间再进行合并。
通过这样的计算单元组件衔接的方式,我们可以横向扩充更多的“工头-工人”计算单元进来,也可以纵向延升到更高级的工头,工头上面集成更多的工头,组成一个大的计算集群。
同时,每一个并行计算单元并不一定都是同一时期开发的,也不一定是同一套Java技术或者基于Fourinone计算框架开发的,它可以是MPI的,也可以是其他一个多台计算机的计算集群,我们可以在工人实现里面通过脚本调用方式启动它(详见下面章节2.5.9节和2.5.10节),这样就能实现新旧系统、将不同技术平台的历史遗留系统统一集成。
为了深刻理解该并行计算集群结构,我们联想一下现实加工生产行业的类似情形:
假设我们是苹果公司,我们将手机生产组装的任务外包给中国的企业做,假设富士坑组装手机壳、比阿迪生产摄像头、还有一些小公司组装其他配件,苹果公司内部跟这些外包公司对接的都是各个部门,这些部门的负责人就好比是上层的工人,他们直接指挥下层公司的老板——计算单元的包工头,每个生产外包公司的老板分配任务让各自工厂成千上万的工人生产。每个生产外包公司都在并行生产各种配件,每个公司的工人都在并行生产某种配件,整体就是一个大的并行计算集群,最后汇总到苹果公司形成最终的手机产品。
几乎完全吻合我们现实社会中的生产加工原材料半成品承包模式。
实际上在上层工人调用下层工头时,可以根据一些条件流向的,比如满足a条件,分配给A工头,满足b条件,分配给B工头,最后形成一个作业流,我们在后面2.3节讲DAG时,也会谈到这个问题。
