4.3 一致性哈希算法的原理、改进和实现
在淘宝网的很多内部应用中,都涉及分布式的负载均衡,一个简陋的做法就是按机器数量取模,为了保证扩容后不出问题,往往采用成倍扩容的方式去解决,但是这样容易造成机器资源浪费。那有没有更好的方法呢?很多人都会想到一致性哈希算法,包括很多人也问及在Fourinone的分布式缓存的负载均衡设计中,为什么不采用一致性哈希算法。因此,我们有必要先看看一致性哈希算法的原理和实现。
一致性哈希算法最初由麻省理工学院在1997年提出,用于解决因特网中的热点(Hot spot)问题,后来广泛用于分布式应用的负载均衡。
一致性哈希算法提出了一个环的思想。很多人第一次看到出现一个环会觉的奇怪,我们后面会试图猜测一下算法作者是如何想到这个环的设计。算法思想是:服务器节点通过哈希值key将环分成多个区域,存储的数据计算哈希值key后,按顺时针方向存储到离它的key最近的服务器节点上去。如图4-8所示。
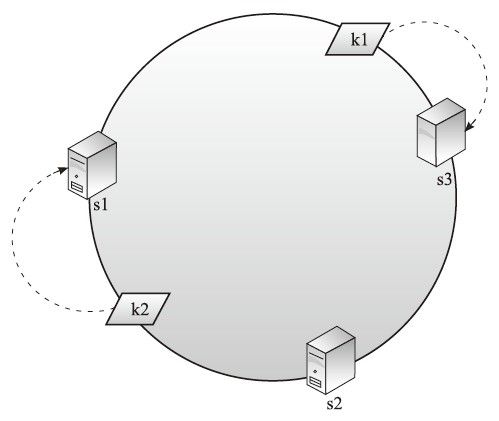
图4-8 一致性哈希1
图中s1、s2、s3代表三台数据服务器的key,k1、k2代表两条数据的key,这里key通常是“数据内容”、“服务器编号或者IP”,通过哈希函数得到。
下面考虑两个问题:
1)如何存放数据?我们通过计算发现k1离顺时针方向的s3最近,那么k1代表的数据存到s3数据服务器上,同理,k2数据存放到s1服务器上。
2)如何获取数据?跟存放的方式一样,通过计算k1发现顺时针方向的s3最近,那么到s3上获取k1对应的数据。
我们再看看如果集群发生故障、扩容、分布不均的时候,会受到什么样的影响?
1.数据服务器发生故障的时候
如图4-9所示,假设s3服务器故障,那么按照算法k1被导向s2,虽然s2并没有k1的数据,但是受到影响的只有k1,k2并不会受到影响。按照一致性哈希算法的说法,只是局部范围受影响,整体容错性提升了。
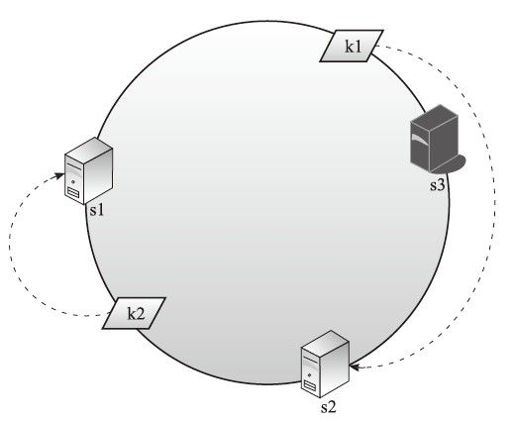
图4-9 一致性哈希2
2.集群服务器扩容的时候
如图4-10所示,如果在s1和s2之间新加入了一台数据服务器new,那么按照算法,k2被导向new,其他的(比如k1)不受影响。
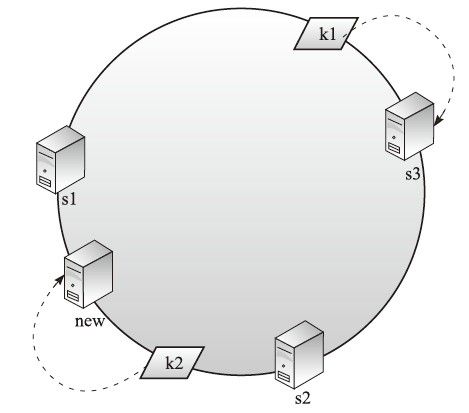
图4-10 一致性哈希3
3.集群服务器分布不均的时候
如果数据服务器key都互相接近挤在一起,那么容易出现多个数据key都落到一台数据服务器上的情况,如图4-11所示,k1、k2、k3都指向s2服务器,导致集群数据分布不均衡。
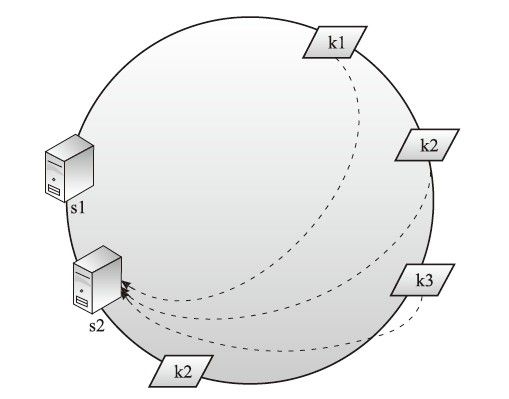
图4-11 一致性哈希4
4.一致性哈希算法的改进
针对上面受影响的情况,一致性哈希算法并没有定义出标准的处理做法,为了改进一致性哈希算法,增加故障的容错能力,可以为每个服务器节点增加备份节点,改进后的一致性哈希算法如图4-12所示
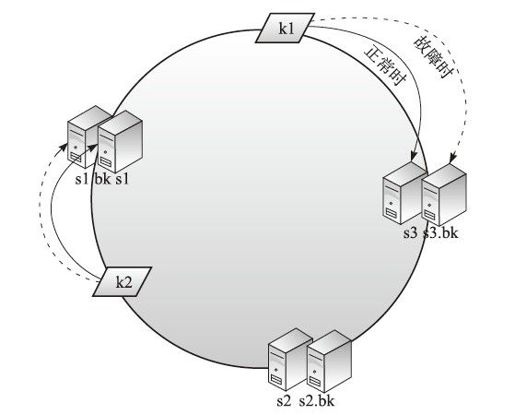
图4-12 一致性哈希5
数据服务器主备节点保持数据同步,故障时,算法切换到备份节点上获取数据。这样s1、s2、s3只作为数据存储节点,而不同时作为相邻节点的备份节点,这样职责更分明,容易管理和维护,减少数据迁移复杂度,只不过这样会牺牲更多的机器做备份。
我们再看看当s3故障时如何处理。我们先按照一致性哈希算法将k1导向s3,发现s3故障既不能写也不能读,这个时候算法改进,会找到s3的备份节点进行写或者读。如果s3恢复,根据数据同步,它会从备份节点获取最新信息,这样针对数据服务器故障的情况便不会再受影响。
那么对于增加了新的数据服务器造成影响的情况如何改进处理呢?
如图4-13所示,如果在s3前增加了一组new的数据服务器主备节点,对于新增数据不存在问题,直接写入新的节点机器即可。对于获取数据,采取如下步骤:
1)k1会首先导向new节点获取数据,但是获取不到;
2)继续按顺时针方向向下寻找,如果有多个新增节点继续向下,直到在s3找到数据,获取到数据后从s3删除;
3)将k1数据写入到自己的顺时针方向第一个节点new上。
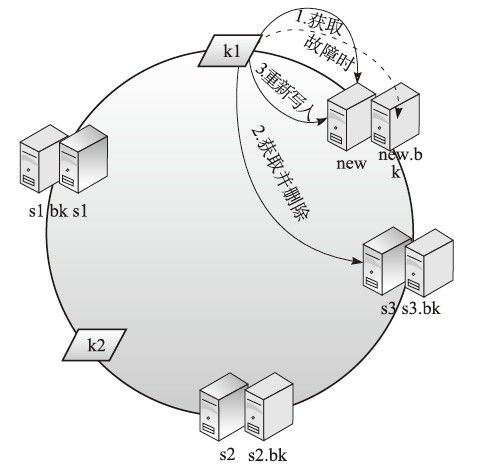
图4-13 一致性哈希6
通过以上步骤我们可以看到,由于新增数据服务器对集群位置的改变,k1在新增节点上寻找不到数据,会顺时针往下轮询直到找到之前存放的服务器。并且在找到后将该数据从之前存放的服务器删除,而改写入到自己顺时针最近的服务器上,这样做的目的是为了避免下次获取k1数据时再次轮询多台服务器导致的延时。当然如果能承受延时,也可以不调整k1数据位置,每次采取顺时针逐个轮询获取。
另外,对于环上集群服务器分配不均情况的改进做法有以下几个:
❏ 计算服务器的key时,尽可能让key值平衡分布,不要靠得太近;
❏ 采用虚拟化手段将一台服务器物理机隔离成多个虚拟机,在形式上增加出多个服务器节点维持分布平衡。
图4-14所示,s1-1、s1-2、s1-3都是s1的虚拟节点,s2-1、s2-2、s2-3都是s2的虚拟节点,在增加了数据服务器虚拟节点后,达到一个相对平衡分布的效果。
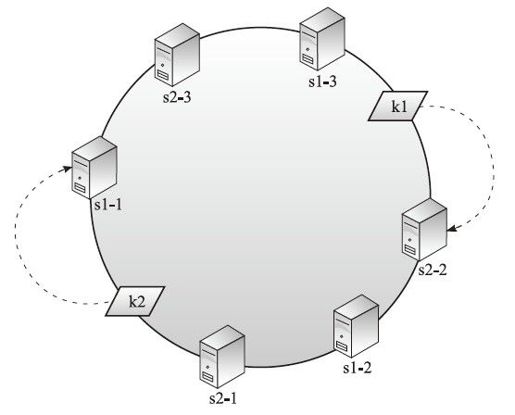
图4-14 一致性哈希7
接下来简单描述一下一致性哈希算法的实现。上面以环图方式表示算法原理,但是如果涉及实现,我们可以换一种方式理解该算法。我们用一个数组表示服务器节点的key值,如下所示:
- S[] = {10,20,30}
代表3个服务器key节点分别是s1=10,s2=20,s3=30。这时,我们有个数据key=15,跟上面这个数组比对,发现在s1和s2之间,根据算法,它应该顺时针导向到s2上。
假设集群扩容,新增加了一个s=17~s=18的服务器:
- S[] = {10,17,18,20,30}
那么,数据key=15会从s1后向下找,s2=17,s3=18,直到s4=20,如果还未找到,会按顺时针方向一直向下,直到回到s1形成一个循环。
于是我们不难理解为什么画出来是一个圆环的设计了,因为实现上多半是从头到尾又返回,轮询这个服务器key数组,轮询的方向是从左往右,是顺时针方向。
算法都是人创造的,都是灵活的,千万不要教条化,为了实现算法本身而实现。在某种算法上花费了学习成本,以后就抱着这种算法的步骤僵化套用是不好的。应该多观察我们需要解决的问题,然后思考合适的算法,如果思考过程中碰到问题,再回头参考前人已经总结出来的算法寻求借鉴,这样的才能有更深刻的体会。
在Fourinone的分布式缓存负载均衡实现中,我们并没有采用一致性哈希算法,而采用了一种基于日期key取模的方式。基于日期分组策略实现扩容后数据分布均匀,也能达到目的和解决问题。
