2.5.15 使用并行计算实现上亿排序
1.为什么需要并行计算来排序
对于大型互联网应用中经常面临对上亿大数据的排序处理等需求,并且上亿大数据量的排序处理能力也是检验分布式系统的计算能力的经典指标之一。
通常在单台计算机上的排序算法有插入排序、快速排序、归并排序、冒泡排序、二叉树排序等等。但是如果是上亿规模的数据,也就是大概G以上数量级的排序。超出了单台计算机内存和CUP的能力,实现起来很困难。为了实现上亿的大数据量快速排序,需要考虑利用多台计算机的协同计算能力实现,将多台计算机的内存和CUP等资源利用起来,建立分布式的计算,通过分布式协作方式,由一台调度的主计算机命令各负责任务处理的计算机先将海量数据首先进行分组归类,然后合并归类,再用逐个排序的方式去完成。
如果有10台计算机,每台上有5GB数据文件,如何对这50GB的数据排序?
对于上亿的数据,数量很大,通常无法在一台计算机上保存,数据本身就分布在多台计算机硬盘上,它本身就是分布式存储的,这里为了方便理解整个排序原理,我们不采用分布式文件系统存储,而假设每台计算机上已经放置好了几G的数据文件。
2.数据取值范围
假设这50GB的数据都是整数,而且取值范围属于0到max,这个max我们可以自由指定,比如max=10万,这50GB的数据都是10万以内的数字。
3.输入输出数据
输入数据是放置在每台机器上的5GB的无序数据,那么输出数据是怎么样放置的呢,将这50GB排好序的数据放置到其中一台计算机上去吗,这也是不合理的,如果数据量再大一点,一台计算机的硬盘也不够放,实际上,输出数据也是分布式地放在每台计算机上,只不过是排好了顺序的。
4.并行计算排序的详细过程
按照并行计算的思想,首先我们需要对问题进行拆分和合并,体现在首先对数据进行分类,每台计算机只管某个范围的数据,比如第一台计算机只管10000以下大小的数据,第二台计算机只管10000~20000大小的数据……第10台计算机只管90000~100000大小的数据。
然后合并,将属于其他计算机范围的数据发给对方,最后各自在本机中完成本范围内的数据。我们可以归纳为“分类、合并、排序”三个阶段。

图2-45 分类阶段
第一阶段:将原始数据分组分类(见图2-45)
1)杂乱无序的原始数据分散在各个工人计算机上,等待进行分组分类。
2)工头计算机发出处理原始无序数据的命令,该命令是并发调度,每台工人计算机无须先后等待完成,同时进行。
3)每台工人计算机同时对各自的原始数据进行分组分类处理。
分类规则
由于原始数据数量太大,需要分散到不同任务计算机存储和处理,因此需要进行两个维度的划分,每台任务计算机将自己的原始数据共分为n组,n为工人计算机的总数,同时每组的数据不能太大,还需要根据最小处理单元进一步分类为s份,比如每次最小处理十万条,那总数据量除于十万获得s份,最小处理单元可以根据计算机不同而设置。最后的结果就是将原始数据处理后得到一个n组,每组又有多类的数据格式存放。
那如何判断一个数字x是属于哪组哪类的呢?规则如下:
假设原始数据里的数字最大值为m,那么xn/m得到所属分组,xs/m得到所在分类。
4)完成后返回通知工头计算机进行下一阶段任务分配。
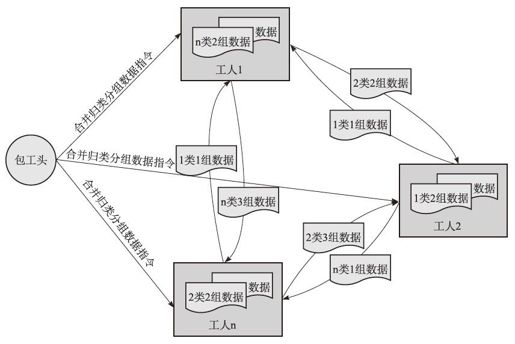
图2-46 合并阶段
第二阶段:分组分类后的数据的合并处理(见图2-46)
1)工头计算机发出合并归类分组数据的命令,并通过命令将“工人计算机的总数”以及“被命令的计算机所在的位置序号”发给被命令的工人计算机(实际上这两个信息可以由工人自己获取,不一定需要工头发送)。
2)每台工人计算机收到命令后,根据分组分类的标示信息,将属于哪台工人计算机的数据取出并发给该计算机,属于自己的继续保存。每次只发一类数据,每类数据包括“组信息、类信息、数据本身”内容。通过合并后,每台工人计算机上保存着属于自己范围的数据,虽然每份里的数据仍然是无序的,但是粗的分组分类使得这些范围是有序的。
3)完成后返回通知工头计算机进行下一阶段任务分配。
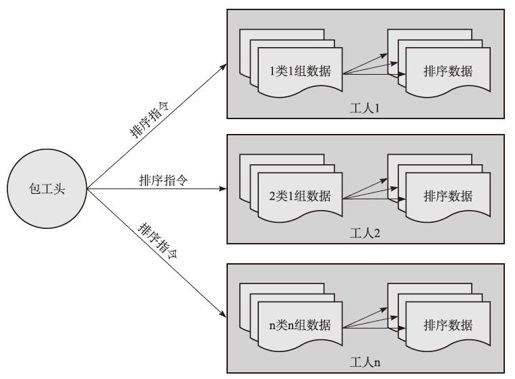
图2-47 排序阶段
第三阶段:分组分类后的数据的排序处理(见图2-47)
1)工头计算机发出排序数据的命令。
2)工人计算机对属于自己范围的分组分类数据进行排序,最后得到一个整体原始数据的排序结果,但是它是根据范围分散到不同任务计算机上存放的。
3)完成后返回通知工头计算机完成排序。
下面是一个按照这个三阶段并行计算排序思想的demo,由于这里旨在抛砖引玉,通过尽量简单的示例,将并行计算的排序思想阐述清楚,所以demo都是基于内存完成,并且以输入数据的方式进行了简化。由各工人机器生成一定数量的随机数字,中间分类结果的数据保存在map变量里,输出结果数据则直接打印出来。实际上,一个完整的上亿排序程序,使用内存保存输入数据和中间分类结果都是不够的,会导致内存溢出,需要参考上面第一、二阶段描述的分类规则,根据每台工人计算机的内存能力,设置最小处理单元,并且输入数据、中间结果数据、输出数据都使用文件方式存储,只有最小处理单元的数据才能通过内存排序。(详见第6章对分布式文件的简化操作。)
❏ SortCtor:是一个工头实现,可以看到它的程序结构很简单,总共分为三个步骤,每步通过发送一个step的命令通知工人去做,并且都是使用doTaskBatch批量完成,也就是每一步必须全部工人做完才能进行下一步。前两个步骤是分类与合并,工头不关心结果,只关心是否做完。最后一步各自排序完成后,工头会匹对一下总数,并输出排序时间。
❏ SortWorker:是一个工人实现,它对照工头的三步命令执行三阶段任务,第一阶段生成一定数量(由参数传入)的随机数据,并将数据分类后存放在一个HashMap里,key为分类id,由通过对工人总数取模获取,value为属于这一分类的所有数字;第二个阶段将不属于自己的分类发给其他工人(通过对比自身的index),所有工人通过receive同时互相发送,可以看到receive方法的实现里,将收到的数据合并到该工人所属的分类中(工人互相合并及receive使用可参见sayhello demo)。
运行步骤:
1)编译demo的java类:
- Javac –classpath fourinone.jar; *.java
2)启动ParkServerDemo(它的IP端口已经在配置文件的PARK部分的SERVERS指定):
- Java –classpath fourinone.jar; ParkServerDemo
3)运行SortWorker(依次传入ip、端口号、生成数字数量、数字取值范围):
- Java –classpath fourinone.jar; SortWorker localhost 2008 1000 100000
- Java –classpath fourinone.jar; SortWorker localhost 2009 1000 100000
- Java –classpath fourinone.jar; SortWorker localhost 2010 1000 100000
- Java –classpath fourinone.jar; SortWorker localhost 2011 1000 100000
上面表示运行4个工人,每个工人生成1000个取值范围为100000的数字,然后开始对这4000个数字进行排序。
4)运行SortCtor
- Java –classpath fourinone.jar; SortCtor
可以看到工头窗口会输出总共完成排序的数量和时间,如图2-48所示。
各工人窗口会输出各自排好序的数字,发现各工人数字依次遵循0~25000,25000~50000,50000~75000,75000~100000取值范围的分类,如图2-49所示。
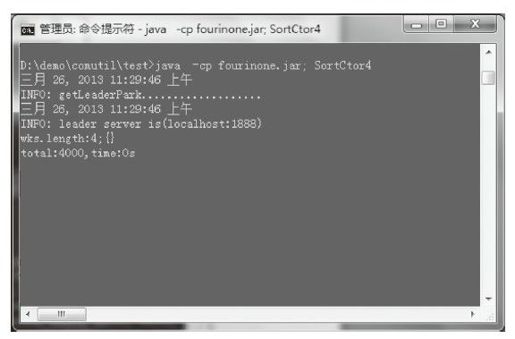
图2-48 SortCtor
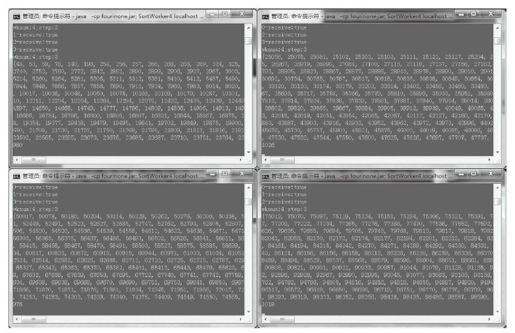
图2-49 SortWorker
完整demo源码如下:
- // ParkServerDemo
- import com.fourinone.BeanContext;
- public class ParkServerDemo
- {
- public static void main(String[] args)
- {
- BeanContext.startPark();
- }
- }
- //SortWorker
- import com.fourinone.MigrantWorker;
- import com.fourinone.WareHouse;
- import com.fourinone.Workman;
- import java.util.List;
- import java.util.ArrayList;
- import java.util.HashMap;
- import java.util.Random;
- import java.util.Collections;
- public class SortWorker extends MigrantWorker
- {
- private final int rammax;//1000000 排序数据的取值范围最大值
- private int totalmax;//排序数据的总量(每个工人)
- private int total = 0;//记录当前生成随机数据的数量
- private HashMap<Integer,List<Integer>> wharr = new HashMap<Integer,List<Integer>>();
- //用来存放分类信息
- private Random rad = new Random();
- private int wknum=-1;
- private int index=-1;
- private Workman[] wms = null;
- public SortWorker4(int totalmax, int rammax)
- {
- this.totalmax = totalmax;
- this.rammax = rammax;
- }
- public Integer[] getNumber()
- {
- if(total++<totalmax){
- int thenum = rad.nextInt(rammax);
- int numi = (thenum*wknum)/rammax;//通过对工人总数取模获取分类
- return new Integer[]{numi,thenum};
- }
- else return new Integer[]{-1,-1};
- }
- public WareHouse doTask(WareHouse wh)
- {
- int step = (Integer)wh.getObj("step");
- if(wms==null){
- wms = getWorkerAll();
- wknum = wms.length;
- }
- index = getSelfIndex();
- System.out.println("wknum:"+wknum+";step:"+step);
- WareHouse resultWh = new WareHouse("ok",1);
- if(step==1){
- Integer[] num = null;
- while(true){
- num = getNumber();
- if(num[0]!=-1){
- List<Integer> arr = wharr.get(num[0]);//取出该分类的list
- if(arr==null)
- arr = new ArrayList<Integer>();
- arr.add(num[1]);
- wharr.put(num[0], arr);
- }
- else break;
- }
- }else if(step==2){
- for(int i=0;i<wms.length;i++){
- if(i!=index&&wharr.containsKey(i)){
- List<Integer> othernum = wharr.remove(i);
- Workman wm = wms[i];
- System.out.println(i+"-receive:"+wm.receive(new
- WareHouse(i, othernum)));//将不属于自己的分类发给其他工人
- }
- }
- }else if(step==3){
- List<Integer> curlist = wharr.get(index);
- Collections.sort(curlist);//对属于自己分类的数据进行内存内排序
- System.out.println(curlist);
- System.out.println(curlist.size());
- resultWh.setObj("total",curlist.size());
- }
- return resultWh;
- }
- protected boolean receive(WareHouse inhouse)
- {
- List<Integer> thisnum = wharr.get(index);
- thisnum.addAll((List<Integer>)inhouse.get(index));
- return true;
- }
- public static void main(String[] args)
- {
- SortWorker mw = new SortWorker(Integer.parseInt(args[2]),Integer.
- parseInt(args[3]));
- mw.waitWorking(args[0],Integer.parseInt(args[1]),"SortWorker");
- }
- }
- // SortCtor
- import com.fourinone.Contractor;
- import com.fourinone.WareHouse;
- import com.fourinone.WorkerLocal;
- import java.util.Date;
- public class SortCtor extends Contractor
- {
- public WareHouse giveTask(WareHouse wh)
- {
- WorkerLocal[] wks = getWaitingWorkers("SortWorker");
- System.out.println("wks.length:"+wks.length+";"+wh);
- wh.setObj("step", 1);//1:group;
- doTaskBatch(wks, wh);
- wh.setObj("step", 2);//2:merge;
- doTaskBatch(wks, wh);
- wh.setObj("step", 3);//3:sort
- WareHouse[] hmarr = doTaskBatch(wks, wh);
- int total=0;
- for(int i=0;i<hmarr.length;i++){
- Object num = hmarr[i].getObj("total");
- if(num!=null)
- total+=(Integer)num;
- }
- wh.setObj("total",total);
- return wh;
- }
- public static void main(String[] args)
- {
- Contractor a = new SortCtor();
- WareHouse wh = new WareHouse();
- long begin = (new Date()).getTime();
- a.doProject(wh);
- long end = (new Date()).getTime();
- System.out.println("total:"+wh.getObj("total")+",time:"+(end-begin)/
- 1000+"s");
- }
- }
