2.5.4 实现Hadoop经典实例Word Count
很多人是通过Word Count入门分布式并行计算,该demo演示了Hadoop的经典实例Word Count的实现。
❏ 输入数据:n个数据文件,每个1G大小,为了方便统计,每个文件的数据由"aaa bbb…ccc"(由空格分割的1k单词组)不断复制组成。
❏ 输出数据:输出这n×1G个数据文件中的每个单词总数。
Fourinone简单实现思路:假设有n台计算机,将这n个1G数据文件放置在每台计算机上,每台计算机各自统计1G数据,然后合并得到结果。
❏ WordcountCT:为一个工头实现,它把需要处理的数据文件名称发给各个工人,然后用一个HashMap<String,Integer>wordcount的map用来装结果。
❏ WordcountWK:为一个工人实现,它按照每次读取8M的方式处理文件数据,将文件大小除以8M得到总次数,每次处理过程将字符串进行空格拆分,然后放入本地一个MAP里,完成后将此MAP发给工头。
❏ ParkServerDemo:分布式计算过程的协同服务park。
运行步骤:
1)启动ParkServerDemo(它的IP端口已经在配置文件的PARK部分的SERVERS指定):
- Java –classpath fourinone.jar; ParkServerDemo
2)运行一到多个WordcountWK,通过传入不同的端口指定多个Worker,这里假设在同机演示,IP设置为localhost:
- java -cp fourinone.jar; WordcountWK 2008
- java -cp fourinone.jar; WordcountWK 2009
- java -cp fourinone.jar; WordcountWK 2010
图2-19 WordcountWK
3)运行WordcountCT,传入文件路径(假设多个工人处理相同数据文件):
- java -cp fourinone.jar; WordcountCT D:\demo\comutil\test\data\inputdata.txt
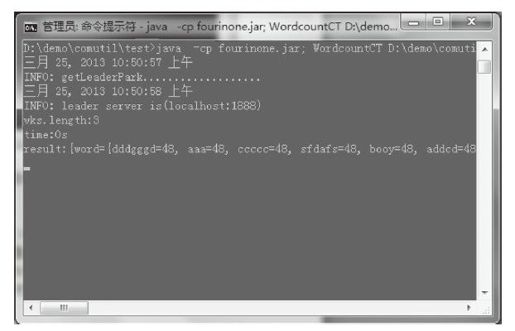
图2-20 WordcountCT
我们可以看到,3个工人每个计算相同的数据文件,总共的单词总数如上所示。现实场景中工人应该分布在不同计算机,每台计算机上的数据文件不相同(如果数据文件不同,每次按照64K获取处理截断单词的情况,请参考6.7节的文件解析处理),这里演示清楚了并行计算原理和过程,可以根据需求去灵活设计。
如果将以上实现部署到分布式环境里,它是1×n的并行计算模式,也就是每台机器一个计算实例,Fourinone可以支持充分利用一台机器的并行计算能力,可以进行n×n的并行计算模式,比如,每台机器4个实例,每个只需要计算256M,总共1G,这样整体的速度会大幅上升。请参见表2-2。
Demo完整源码如下:
- // inputdata.txt
- ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd ccccc world good dddfg word googl booy aaa dddgggd sfdafs addcd
- // ParkServerDemo
- import com.fourinone.BeanContext;
- public class ParkServerDemo{
- public static void main(String[] args){
- BeanContext.startPark();
- }
- }
- // WordcountWK
- import com.fourinone.MigrantWorker;
- import com.fourinone.WareHouse;
- import com.fourinone.FileAdapter;
- import com.fourinone.FileAdapter.ReadAdapter;
- import java.util.StringTokenizer;
- import java.util.HashMap;
- import java.util.ArrayList;
- import java.io.File;
- public class WordcountWK extends MigrantWorker
- {
- public WareHouse doTask(WareHouse inhouse)
- {
- String filepath = inhouse.getString("filepath");
- long n=64;//FileAdapter.m(8)
- long num = (new File(filepath)).length()/n;
- FileAdapter fa = null;
- ReadAdapter ra = null;
- byte[] bts = null;
- HashMap<String,Integer> wordcount = new HashMap<String,Integer>();
- fa = new FileAdapter(filepath);
- for(long i=0;i<num;i++){
- ra = fa.getReader(i*n, n);
- bts = ra.readAll();
- StringTokenizer tokenizer = new StringTokenizer(new String(bts));
- while(tokenizer.hasMoreTokens()){
- String curword = tokenizer.nextToken();
- if(wordcount.containsKey(curword))
- wordcount.put(curword, wordcount.get(curword)+1);
- else
- wordcount.put(curword, 1);
- }
- }
- fa.close();
- return new WareHouse("word", wordcount);
- }
- public static void main(String[] args)
- {
- WordcountWK mw = new WordcountWK();
- mw.waitWorking("localhost",Integer.parseInt(args[0]),"wordcount");
- }
- }
- // WordcountCT
- import com.fourinone.Contractor;
- import com.fourinone.WareHouse;
- import com.fourinone.WorkerLocal;
- import java.util.HashMap;
- import java.util.Iterator;
- import java.util.Date;
- public class WordcountCT extends Contractor
- {
- public WareHouse giveTask(WareHouse inhouse)
- {
- WorkerLocal[] wks = getWaitingWorkers("wordcount");
- System.out.println("wks.length:"+wks.length);
- WareHouse[] hmarr = doTaskBatch(wks, inhouse);
- HashMap<String,Integer> wordcount = new HashMap<String,Integer>();
- for(WareHouse hm:hmarr)
- {
- HashMap<String,Integer> wordhm = (HashMap<String,Integer>)hm.get ("word");
- for(Iterator<String> iter=wordhm.keySet().iterator();iter.hasNext();){
- String curword = iter.next();
- if(wordcount.containsKey(curword))
- wordcount.put(curword, wordcount.get(curword)+ wordhm.
- get(curword));
- else
- wordcount.put(curword, wordhm.get(curword));
- }
- }
- return new WareHouse("word", wordcount);
- }
- public static void main(String[] args)
- {
- Contractor a = new WordcountCT();
- long begin = (new Date()).getTime();
- WareHouse result = a.giveTask(new WareHouse("filepath", args[0]));//eg:
- "D:\\demo\\parallel\\a\\three.txt"
- long end = (new Date()).getTime();
- System.out.println("time:"+(end-begin)/1000+"s");
- System.out.println("result:"+result);
- }
- }
