2.1.4 基于网状直接交互的计算模式
“包工头-职介所-手工仓库-工人”的基本结构和角色已经在前面介绍过了,这里重点介绍计算过程中的工头和工人的交互机制。先看看框架默认和推荐的网状直接交互模式。
前面我们基本了解到工头通过在giveTask实现中,调用工人的doTask来分配任务,并轮询检查doTask结果是否完成,如果选择网状直接交互模式,也就是默认的设置:
- <MODE DESC="DEFAULT">0</MODE>
那么这个调用过程是直接调用,而不会通过消息中枢中转,也就是如果计算过程中,把parkserver关掉,对计算也没有影响,反之则不行。
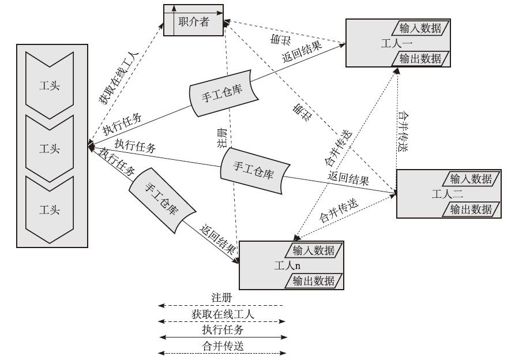
图2-4 网状直接交互模式
通过图2-4我们观察到一个重要的特性,就是工人之间也是可以直接交互的。这个机制主要使用在并行计算过程中的合并,各个工人在计算过程中互相进行数据合并。在每个工人的doTask实现里,框架提供了一系列API帮助获取到集群中其他工人集合,如下所示:
- //获取除该工人外其他所有相同类型的工人
- protected abstract Workman[] getWorkerElse();
- //获取其他某个相同类型的工人,index为在集群中序号
- protected abstract Workman getWorkerIndex(int index);
- //获取除该工人外其他所有工人,workerType为工人类型
- protected abstract Workman[] getWorkerElse(String workerType);
- //获取其他某个工人,workerType为工人类型,index为在集群中序号
- protected abstract Workman getWorkerIndex(String workerType, int index);
- //获取某台机器上的工人,workerType为工人类型,host为ip,port为端口
- protected abstract Workman getWorkerElse(String workerType, String host, int port);
- //获取集群中所有工人,包括该工人自己
- protected abstract Workman[] getWorkerAll();
- //获取集群中所有类型为workerType的工人
- protected abstract Workman[] getWorkerAll(String workerType);
- //获取自己在集群中的位置序号
- protected abstract int getSelfIndex();
- //接收来自其他工人的发送内容
- protected abstract boolean receive(WareHouse inhouse);
上面API中获取集群其他工人返回结果是Workman,代表该名其他工人,Workman有一个receive方法可供调用,通常调用该工人的receive方法向它发送数据,同时每个工人都需要实现receive接口,工人之间的整个交互过程如图2-5所示。
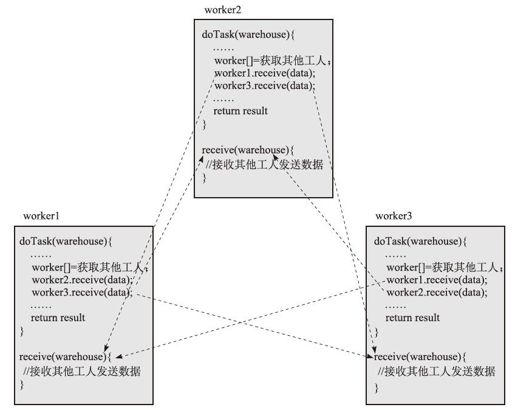
图2-5 工人间互相交互
图中示例了3个工人间的交互过程:
1)包工头会并发地调用3个工人的doTask,让他们完成任务;
2)每个工人在计算过程中,如果需要跟其他工人交互,应先获取其他工人集合;
3)依次调用其他工人的receive方法,将数据发送给该工人;
4)在各自的receive方法实现中,接收其他工人发送过来的数据;
5)如果所有工人的doTask调用完成了,那么所有工人的receive接收也完成了。
 注意
注意
对比前面的介绍,我们发现这里工人获取其他工人并且交互都是独立一套API,为什么不直接使用包工头的getWaitingWorkers获取工人集合,再调用每个工人的doTask传递数据呢?如果工头和工人共用一套交互机制,很容易出现工头工人都在等待doTask执行完成,会产生死锁问题(可以参考银行家算法),下面谈及跟MPI的区别时也会提到,因此框架从设计上就避免了开发者使用产生死锁问题,分别用独立的API将“工头-工人”、“工人-工人”的交互隔离开来。这样让开发者可以轻松设计并行计算而完全不用考虑死锁等复杂问题,这些让框架去考虑,开发者专注在实现计算逻辑本身上即可。
我们总结一下并行计算过程中数据和计算的关系:
比如Hadoop的方式,是将计算jar包发到数据节点上执行,计算向数据移动;
还有的实时计算Storm,是将数据通过消息发到节点上计算,数据向计算移动。
一般这类计算平台软件会将数据和计算的关系固化下来,开发者无法自己决定,必须按照计算平台规范开发,上传job进行执行。
但是Fourinone的数据和计算的关系相当灵活,可以根据需求自由设计,几乎不受限制,如下所示:
❏ 如果数据小,可以由工头分配任务时放在Warehouse里直接传给工人。
❏ 如果数据大,可以直接保存在工人机器上,Warehouse里只放工头的命令,工人收到命令后直接在本地读取数据计算;或者工头把数据地址、数据库表连接信息等发给工人用于计算,但是不传数据。
❏ 如果计算结果小,各工人可以直接返回结果给工头汇总。
❏ 如果计算结果大,各工人直接存放本地,返回完成状态告诉工头。
❏ 如果中间结果小,可以返回工头合并再做为条件重新安排任务。
❏ 如果中间结果大,可以多次通过receive方式跟其他工人合并。
❏ 怎么做完全取决于开发者的需求和设计。
