4.6 分布式Session的架构设计和实现
如果建立一个网站,经常用到Session,Web中的Session指的就是用户在浏览某个网站时,从进入网站到浏览器关闭所经过的这段时间,也就是用户浏览这个网站所花费的时间。一个Session的概念需要包括特定的客户端、特定的服务器端以及不中断的操作时间。A用户和C服务器建立连接时所处的Session同B用户和C服务器建立连接时所处的Session是两个不同的Session。Session的概念还包括在会话的这段时间内,用户可以往服务器缓存写入和读取信息,该信息只在Session有效时间内存在,失效就被删除。大型网站应用中为了减少数据库负载,提升访问速度,通常将属于某次用户会话的频繁操作的数据存放在Session中。因此,当网站服务器是跨多台服务器的分布式环境时,则相应需要分布式Session结构去解决。
目前市场上的Tomcat等J2EE Web服务器实现了分布式Session机制,但是Tomcat等Web服务器Session只是在单台服务器环境上有效,不能满足集群多服务器的分布式环境,需要借助分布式缓存系统实现,但是较多存在故障容错能力弱、易丢失内存数据、无法动态切换备份机等问题,并且集群部署上复杂,需要成倍扩容,缓存容易不命中。
我们接下来构思一下分布式Session的架构设计,能够基于该设计实现大型分布式Session系统,并可以自由扩容缓存容量,用来解决大型互联网等应用面临的分布式跨多计算机的Session问题。
 提示
提示
我们分析分布式Session系统的特点后发现,Session系统其实就是一个基于分布式缓存系统的应用,可以把缓存key当作Cookie ID的实现,它只不过是保存在浏览器客户端,每次浏览器访问网站服务器时会携带这个Cookie ID信息。
回顾一下我们前面讲述的分布式缓存技术,采用一组相同的FacadeServer+不同的CacheServer的分布式设计模型,可以具备良好的负载均衡和可扩充性,并且有很好的故障容错能力。它对外通过FacadeServer分解负载,并通过生成含有日期信息的key,对集群扩容增加日期配置,通过key和集群配置的日期匹配计算出覆盖范围的机器数,再以取模的方式准确得到负载的计算机,这样能准确将数据分散存放在不同的CacheServer上,它的规模和缓存能力可以随计算机的扩充而扩充。
我们基于上面的分布式缓存设计稍做调整后得到下面的分布式Session系统架构,如图4-16所示。
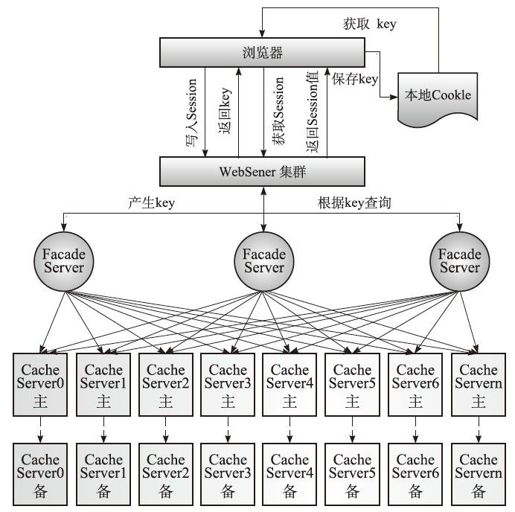
图4-16 分布式Session系统架构
架构的详细实现过程如下:
1)首先,浏览器提交Session的写入请求,比如用户登录,写入用户信息。
2)当外部访问请求非常大时,首先通过WebServer集群进行请求疏导,物理上负载均衡器是部署在WebServer集群中,可以有一个到多个。WebServer集群将写入请求负载到后端的FacadeServer上。
3)FacadeServer和CacheServer的结构即前面讲述的分布式缓存结构,它由Session系统的底层Cache支撑。
4)如果是第一次写入,请求中没有携带key信息,FacadeServer会自动依据生成key并返回给浏览器,浏览器将key信息保存在本地Cookie中。
5)当浏览器在下次发出Session的读请求时,会从本地Cookie将key信息携带并进行请求提交,FacadeServer会根据key信息直接判断出属于哪台CacheServer,并将读取的Session结果返回给客户端。
6)Session系统的负载和扩容实现。当浏览器将Cookie里的key信息携带发出请求时,FacadeServer并不需要根据key去一个配置服务器查询关联到哪台存储服务器,因为当请求量很大时,配置服务器的查询会成为瓶颈,并且传统的key取模方式有很大的缺陷,比如对于集群数量为n,那么数字ID的key,按照key%n得到路由的目标计算机,当集群数量扩充时,取模变得不准确,如果要维持准确,通常需成倍去扩容,这会造成成本增加和浪费。这里采用前面讲述的日期取模算法,将含有日期信息的key和集群配置的日期匹配计算出覆盖范围的机器数,再以取模的方式准确得到负载的计算机,对于集群的任意数量的扩容都不会受到影响。
