6.1 FTTP架构原理解析
目前在云计算和大数据浪潮的推动下,分布式文件存储技术的发展已经如火如荼,不论大企业还是小创业公司都想推自己的云存储产品和服务,下面我们来关注一下这个领域背后的落地技术实现,从市场上已有的分布式文件系统实现技术入手分析,先做一个背景铺垫,再以此对照阐述FTTP的分布式文件技术架构。
目前市场上已有的分布式文件系统的元数据实现主要有Google提出的GFS的论文理论和按照该论文实现的Hadoop的HDFS分布式文件系统。在HDFS分布式文件系统中,NameNode是分布式文件元数据管理的中心服务器,负责管理文件系统的目录命名和客户端对文件的访问。
在HDFS分布式文件系统中,要存储一个文件,其内容会被拆分成多个块,这些块数据散落存储在不同的计算机节点上,而该文件的路径目录名称等元数据存放在NameNode机器上,该文件被拆分的块位置信息等也存放在其上。当客户端读取该文件时,会访问NameNode查找该文件路径并获取拆分的块位置信息,然后直接到存放各块的计算机上读取块内容合并得到结果。
可见,NameNode负责保存和管理所有的HDFS元数据,它维持着一个像操作系统文件资源管理器一样的树状目录结构,通过它可以访问、查询、获取文件的元数据信息。
但是Hadoop单一NameNode的设计会严重制约整个Hadoop的可扩展性和可靠性。首先,NameNode是整个系统中明显的单点故障源,单一NameNode的内存容量有限,使得Hadoop集群的节点数量被限制到2000个左右,能支持的文件系统大小被限制在10~50PB,最多能支持的文件数量大约为1.5亿左右(注:实际数量取决于NameNode的内存大小)。同时,在集中式的NameNode造成数据块存储计算机的心跳报告也会对NameNode的性能造成严重的影响。对于这样的系统,有1800个存储节点,每个存储节点有3T存储,整个集群大约有1.8PB有效存储(1800×3T/3,假设每个数据块有3份备份),那么每个存储节点上有大约50000个左右的数据块(假设数据块大小是64MB,然而有的数据块并没有达到64MB大小)。如果存储节点每小时会发送一次块信息的心跳报告,那么Namenode每两秒会收到一次报告信息,每个报告信息包含50000条数据,处理这些数据无疑会占用相当资源。实际上,集群的NameNode重启需要数小时,这大大降低了系统的可用性。
由此可见目前已有技术,如Hadoop的NameNode管理文件元数据的方式,面临单点故障、容量限制、内存限制、性能限制等问题。为此,Fourinone尝试通过FTTP分布式文件技术屏蔽这些问题,并让设计具有高可扩展性和高可靠性。
FTTP对于分布式文件系统的元数据管理设计不同于Hadoop的NameNode,它自己不维持一个随着扩容而逐渐庞大的元数据信息的存储,而是在底层利用操作系统本身已有的文件元数据信息,因为操作系统本身已经实现了对所有文件的元数据管理和存储,所以像NameNode这样自身维持一个庞大的分布式元数据信息是一种重复建设,而且实现复杂,容易产生问题。如果利用操作系统的元数据信息,会大大减少目录节点的存储量,目录节点仅仅只需要维持一个存储计算机的集群信息,它背后联系着集群每台存储计算机的元数据信息,这样不存在节点数量限制,可以无限扩充。当客户端需要获取文件元数据信息时,会向目录节点提交一个集群路径(FTTP路径),目录节点解析该路径,并找到背后关联的存储计算机上的文件元数据信息,然后返回给客户端节点。在整个过程中目录节点只是一个解析和中转的角色,它本身不维持元数据存储,它是虚拟的,松耦合的,所以也不存在过多数量的数据块元数据心跳报告导致性能低下。FTTP架构的设计结构和过程描述参见图6-1。
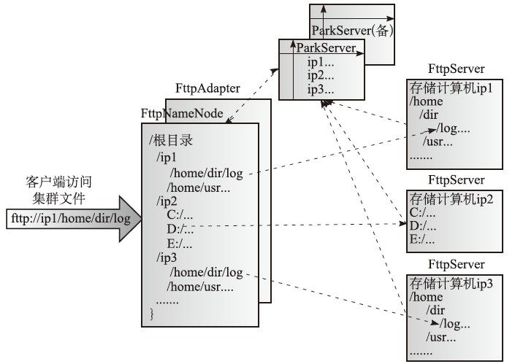
图6-1 FTTP架构
从图6-1可以看到,FTTP分布式文件系统的架构主要由FttpAdapter、FttpServer、FttpNameNode、ParkServer组成。
说明:
1)"ParkServer"在这里主要提供协调服务,它可以部署在一台独立的计算机节点上,用来管理存储计算机节点的集群信息。存储计算机节点在加入集群时首先在"ParkServer"中进行登记,然后"ParkServer"不断检测各存储计算机节点的在线状况。
2)"FttpServer"为一个存储计算机节点,可以部署在多个机器上,它主要操作所在计算机的操作系统的存储文件和获取文件元数据信息并返回给"FttpExploer"。
3)"FttpNameNode"是集群存储文件浏览器,可以和客户端在同一台计算机上。通过"FttpNameNode"可以浏览获取集群中所有计算机的文件元数据。"FttpNameNode"看似提供一个完整的文件目录树结构,包括了整个集群文件系统,但实际上只是一个虚拟的、动态的结构,它先从"ParkServer"获取集群可用于存储的计算机节点,将它们按照IP进行显示,并且根据客户端提交的FTTP访问请求,通过"FttpAdapter"进行FTTP的协议解析,然后即时访问后端的"FttpServer",获取操作系统的文件元数据,通过包装转换发回客户端。"FttpNameNode"本身不维护集群文件元数据的存储。
4)"FttpAdapter"提供对远程文件的所有操作和协议转换,客户端通过统一的FTTP文件协议访问元数据,FTTP保持操作系统文件目录的原始结构,比如:
❏ Windows:fttp://ip/d:/log/
❏ Linux:fttp://ip/home/dir/log/
客户端以FTTP的方式访问文件元数据,发送请求给"FttpAdapter",之后"FttpAdapter"解析客户端的请求并返回它需要的元数据,在整个过程中客户端不需要与背后各存储计算机上的真实文件数据直接交互。"FttpNameNode"对客户端来说就是一个大的虚拟的集群文件目录,可以通过"FttpAdapter"获取到它需要的一切分布式文件元数据。
有以下一些问题需要考虑。
❏ 关于单点问题:由于FttpNameNode是一个虚拟动态的实现,它是可以随时被复制和替换,因此不存在单点问题。FttpNameNode获取集群文件元数据时会依赖ParkServer,ParkServer存储着最新集群里存储计算机节点的信息,由于ParkServer是一主多备的关系,当ParkServer出现故障,可以及时从它的备份获取节点信息。因此整体设计结构有效地避免了单点故障问题。
❏ 关于文件拆分:如果将一个大的文件拆分后散落在不同FttpServer节点上保存,那么它们的元数据如何保存呢?对于FttpNameNode来说,它也仅仅增加一些文件拆分的信息存储,而每个拆分的块文件元数据也保存在FttpServer的操作系统上,FttpNameNode本身不维持这些块文件的元数据存储,因此FttpNameNode没有一个容量的限制。
❏ 关于增容减容:由于FttpServer和FttpNameNode之间是一个松散的结构关系,因此FttpServer可以自由增加或者减少,FttpNameNode会及时获取到集群存储节点的改变。这些改变对元数据的管理没有影响,因为FttpNameNode本身不维持整个分布式文件系统的元数据的存储,所以FttpServer的增加或减少没有太大影响,FttpNameNode会动态地获取到最新的元数据状况,FttpServer所在计算机的操作系统维持着文件元数据的原始存储。
❏ FTTP与FTP/HTTP的区别:FTP是一种文件上传下载的协议,有一套完整的命令规范,比如登录、put、get等,但是它不能用于获取文件元数据信息,并且也只支持本地服务器两台计算机之间的文件传输,因此FTP不用于分布式文件系统。超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到Web浏览器。HTTP允许以二进制的方式上传下载文件,但是封装在HTTP报文中,并指定特定的内容格式的方式。不过HTTP也只支持浏览器和Web服务器两者之间的文件内容的上传下载,不能获取文件元数据和管理文件元数据,因此它也不用于分布式文件系统。
