2.3 不借助工具编写计算器
至此我们使用yacc和lex制作了一个计算器,可能会有读者这样想:
我明明是为了弄清楚编程语言的内部机制才要自制编程语言的,但是却将yacc和lex等工具当作黑匣子使用,这样一来岂不是达不到目的了吗?
bison和flex虽然都是自由软件,但是在项目中客户和上级是不允许使用免费软件的;
yacc/lex或bison/flex的版本升级可能会使程序无法工作,这很让人讨厌。
上面每一条理由都足够充分(上级不允许使用免费软件可能有点不讲理,但是光嘴上说不讲理是没法解决这个问题的)。
因此,以下我们将不会借助yacc/lex来制作计算器。
2.3.1 自制词法分析器
首先是词法分析器。
操作本章的计算器时,会将换行作为分割符,把输入分割为一个个算式。跨复数行的输入是无法被解析为一个算式的,因此词法分析器中应当提供以下的函数:
/ 将接下来要解析的行置入词法分析器中 /
void set_line(char *line);
/* 从被置入的行中,分割记号并返回
- 在行尾会返回 END_OF_LINE_TOKEN 这种特殊的记号
*/
void get_token(Token *token);
get_token()接受的入口参数为一个Token结构体指针,函数中会分割出记号的信息装入Token结构体并返回。上面两个函数的声明以及Token结构体的定义位于token.h文件中。
代码清单2-6 token.h
1: #ifndef TOKEN_H_INCLUDED
2: #define TOKEN_H_INCLUDED
3:
4: typedef enum {
5: BAD_TOKEN,
6: NUMBER_TOKEN,
7: ADD_OPERATOR_TOKEN,
8: SUB_OPERATOR_TOKEN,
9: MUL_OPERATOR_TOKEN,
10: DIV_OPERATOR_TOKEN,
11: END_OF_LINE_TOKEN
12: } TokenKind;
13:
14: #define MAX_TOKEN_SIZE (100)
15:
16: typedef struct {
17: TokenKind kind;
18: double value;
19: char str[MAX_TOKEN_SIZE];
20: } Token;
21:
22: void set_line(char *line);
23: void get_token(Token *token);
24:
25: #endif / TOKEN_H_INCLUDED /
词法分析器的源代码如代码清单2-7所示。
代码清单2-7 lexicalanalyzer.c
1: #include <stdio.h>
2: #include <stdlib.h>
3: #include <ctype.h>
4: #include "token.h"
5:
6: static char *st_line;
7: static int st_line_pos;
8:
9: typedef enum {
10: INITIAL_STATUS,
11: IN_INT_PART_STATUS,
12: DOT_STATUS,
13: IN_FRAC_PART_STATUS
14: } LexerStatus;
15:
16: void
17: get_token(Token *token)
18: {
19: int out_pos = 0;
20: LexerStatus status = INITIAL_STATUS;
21: char current_char;
22:
23: token->kind = BAD_TOKEN;
24: while (st_line[st_line_pos] != '\0') {
25: current_char = st_line[st_line_pos];
26: if ((status == IN_INT_PART_STATUS || status == IN_FRAC_PART_STATUS)
27: && !isdigit(current_char) && current_char != '.') {
28: token->kind = NUMBER_TOKEN;
29: sscanf(token->str, "%lf", &token->value);
30: return;
31: }
32: if (isspace(current_char)) {
33: if (current_char == '\n') {
34: token->kind = END_OF_LINE_TOKEN;
35: return;
36: }
37: st_line_pos++;
38: continue;
39: }
40:
41: if (out_pos >= MAX_TOKEN_SIZE-1) {
42: fprintf(stderr, "token too long.\n");
43: exit(1);
44: }
45: token->str[out_pos] = st_line[st_line_pos];
46: st_line_pos++;
47: out_pos++;
48: token->str[out_pos] = '\0';
49:
50: if (current_char == '+') {
51: token->kind = ADD_OPERATOR_TOKEN;
52: return;
53: } else if (current_char == '-') {
54: token->kind = SUB_OPERATOR_TOKEN;
55: return;
56: } else if (current_char == '*') {
57: token->kind = MUL_OPERATOR_TOKEN;
58: return;
59: } else if (current_char == '/') {
60: token->kind = DIV_OPERATOR_TOKEN;
61: return;
62: } else if (isdigit(current_char)) {
63: if (status == INITIAL_STATUS) {
64: status = IN_INT_PART_STATUS;
65: } else if (status == DOT_STATUS) {
66: status = IN_FRAC_PART_STATUS;
67: }
68: } else if (current_char == '.') {
69: if (status == IN_INT_PART_STATUS) {
70: status = DOT_STATUS;
71: } else {
72: fprintf(stderr, "syntax error.\n");
73: exit(1);
74: }
75: } else {
76: fprintf(stderr, "bad character(%c)\n", current_char);
77: exit(1);
78: }
79: }
80: }
81:
82: void
83: set_line(char *line)
84: {
85: st_line = line;
86: st_line_pos = 0;
87: }
88:
89: / 下面是测试驱动代码 /
90: void
91: parse_line(char *buf)
92: {
93: Token token;
94:
95: set_line(buf);
96:
97: for (;;) {
98: get_token(&token);
99: if (token.kind == END_OF_LINE_TOKEN) {
100: break;
101: } else {
102: printf("kind..%d, str..%s\n", token.kind, token.str);
103: }
104: }
105: }
106:
107: int
108: main(int argc, char **argv)
109: {
110: char buf[1024];
111:
112: while (fgets(buf, 1024, stdin) != NULL) {
113: parse_line(buf);
114: }
115:
116: return 0;
117: }
这个词法分析器的运行机制为,每传入一行字符串,就会调用一次 get_token()并返回分割好的记号。由于词法分析器需要记忆 set_line()传入的行,以及该行已经解析到的位置,所以设置了静态变量 st_line与 st_line_pos(第6~7行) [9]。
set_line()函数,只是单纯设置了 st_line与 st_line_pos的值。
get_token()则负责将记号实际分割出来,即词法分析器的核心部分。
第24行开始的while语句,会逐一按照字符扫描 st_line。
记号中的 +、 -、 *、 /四则运算符只占一个字符长度,因此一旦扫描到了,立即返回就可以了。
数值部分要稍微复杂一些,因为数值由多个字符构成。鉴于我们采用的是 while语句逐字符扫描这种方法,当前扫描到的字符很有可能只是一个数值的一部分,所以必须想个办法将符合数值特征的值暂存起来。为了暂存数值,我们采用一个枚举类型 LexerStatus [10]的全局变量 status(第20行)。
首先, status的初始状态是 INITIAL_STATUS。当遇到0~9的数字时,这些数字会被放入整数部分(此时状态为 IN_INT_PART_STATUS)中(第64行)。一旦遇到小数点 ., status 会由 IN_INT_PART_STATUS 切换为 DOT_STATUS(第70行), DOT_STATUS 再遇到数字会切换到小数状态(IN_FRAC_PART_STATUS,第66行)。在 IN_INT_PART_STATUS 或 IN_FRAC_PART_STATUS的状态下,如果再无数字或小数点出现,则结束,接受数值并 return。
按上面的处理,词法分析器会完全排除 .5或 2..3这样的输入。而从第32行开始的处理,除换行以外的空白符号全部会被跳过。
由于是用于计算器的词法分析器,因此除四则运算符与数值外,没有其他要处理的对象了,但如果考虑到将其扩展并可以支持编程语言的话,最好提前想到以下几个要点。
- 数值与标识符(如变量名等)可以按照上例的方法通过管理一个当前状态将其解析出来,比如自增运算符就可以设置一个类似 IN_INCREMENT_OPERATOR的状态,但这样一来程序会变得冗长。因此对于运算符来说,可能为其准备一个字符串数组会更好。比如做一个下面这样的数组:
static char *st_operator_str[] = {
"++",
"—",
"+",
"-",
(以下省略)
};
当前读入的记号可以与这个数组中的元素做前向匹配,从而判别记号的种类。指针部分同样需要比特征对象再多读入一个字符用以判别(比如输入 i+2,就需要将 2也读入看看有没有是 i++的可能性)。做判别时,像上例这样将长的运算符放置在数组前面会比较省事。关于额外读入的一个字符具体应该如何处理,稍后会介绍。
另外,像 if、 while这些保留字,比较简单的做法是先将其判别为标识符,之后再去对照表中查找有没有相应的保留字。
- 本次的计算器是以行为单位的, st_line会保存一行中的所有信息,但在当下的编程语言中,换行一般和空白字符是等效的,因此不应该以行为单位处理,而是从文件中逐字符(使用 getc()等函数)读入解析会更好。
那么,上例中用 while语句逐字符读取的地方就需要替换为用 getc()等函数来读取,比如输入 123.4+2时,判别数值是否结束的时机是读入 +时。
上例的词法分析器是通过 st_line_pos的自增(第46行 st_line_pos++)来实现的。如果直接从文件逐字符读入,C语言中就需要使用 ungetc()等从读入的字符回退,从而产生1个字符的备份,达到预先读入下一字符的效果。
补充知识 保留字(关键字)
在C语言中, if与 while都是保留字,保留字无法再作为变量名使用【C规范中一般不称“保留字”(reserved word),而称为“关键字”(keyword),但是关键字的指代范围太广,所以还是称保留字更加准确】 。
C语言中的保留字是由词法分析器以特殊的标识符方式处理的。保留字的区分以标识符为单位,比如 if不能作为变量名但 ifa就可以。
对于习惯了C语言的人来说,这都是理所当然的事情,但站在其他语言的角度看却未必如此。
比如在我小时候折腾过一门叫BASIC的编程语言 [11],可以这样写:
IFA=10THEN…
会解析为:
IF A = 10 THEN …
向杂志投稿的程序中,注释(英语为remark)都写成了下面这样:
REMARK 这里是注释
BASIC中的注释只需要写 REM语句, REM之后都会被作为注释处理,因此即便写成 REMARK也是可以的。
BASIC是从FORTRAN的基础上发展起来的,以前FORTRAN中空白字符没有任何意义。 GOTO可以写成 GO TO,也可以写成 G OTO,而在写循环的时候,下例等于写了一个1到5的循环。
DO 10 I=1,5
处理
>10 CONTINUE
如果一不小心将逗号输入成句号,写成下面这样:
DO 10 I=1.5
由于FORTRAN中空白没有意义,而且上例中也无需声明变量(D开始的变量默认解析成实数型变量),所以最后会变成 DO10I=1.5这样的赋值语句。有传闻 [12]说就是这样一个BUG最终导致NASA的火箭失控爆炸,当然这多半是谣传了。
另外在C#中还有 上下文关键字 (context keyword),是指一些在特殊的区域内才对编译器有特殊意义的关键字(比如定义属性时使用 get等)。内容关键字并不等同于保留字,在普通的变量名中可以使用。保留字与关键字严格讲有不同的意义,但本书中没有特别区分。
补充知识 避免重复包含
在代码清单2-6中,开头和结尾处有这样的语句:
ifndef TOKEN_H_INCLUDED
define TOKEN_H_INCLUDED
(中间省略)
endif / TOKEN_H_INCLUDED /
这是为了防止token.h多次用 #include包含引起多重定义错误而采用的技巧。
头文件经常会用到其他头文件中定义的类型或宏。比如在a.h中定义的类型在b.h中使用的话,在 b.h 的开头处书写 #include "a.h" 就可以了。如果不这样做,程序用 #include 包含 b.h 时,必须同时书写 #include a.h 与 #include b.h,还会弄得代码到处都是长串 #include,之后如果依赖关系发生改变的话修改起来非常麻烦。
但仅仅在头文件的起始处用 #include包含a.h,如果多个头文件都这样书写,会报出类型或宏的重复定义错误。因此采用上面的小技巧,一旦token.h用 #include包含后会定义 TOKEN_H_INCLUDED,根据开头的 #ifndef 语句,该头文件将被忽略,也就避免了产生多重定义的错误。
下面的两点是编写C头文件的经验之谈,本书中涉及的代码都默认遵循这两点:
- 所有的头文件都必须用 #include包含自己所依赖的其他所有头文件,最终让代码中只需一次 #include;
2. 所有的头文件都必须加入上文的技巧,防止出现多重定义错误。
2.3.2 自制语法分析器
接下来终于要开始做语法分析器了。
在我看来,只要是有一定编程经验的程序员,即使没有自制编程语言的背景,都可以大致想明白词法分析器的运行机制。但换成语法分析器,可能很多人就有点摸不着头脑了。有些人可能会想,总之先只考虑计算器程序,将运算符优先级最低的 + 与 - 分割出来,然后再处理 * 和 /……这样的思路基本是正确的。但是按这样的思路实际操作时会发现,用来保存分割字符串的空间可能还有其他用途,而加入括号的处理也很难。
对于上面的问题,与其自己想破脑袋,不如借鉴一下前人的智慧。因此我们将使用一种叫 递归下降分析 的方法来编写语法分析器。
yacc版的计算器曾使用下面的语法规则:
expression / 表达式的规则 /
: term / 表达式 /
| expression ADD term / 或 表达式 + 表达式 /
| expression SUB term / 或 表达式 - 表达式 /
;
term / 表达式的规则 /
: primary_expression / 一元表达式 /
| term MUL primary_expression / 或 表达式 表达式 */
| term DIV primary_expression / 或 表达式 / 表达式 /
;
primary_expression / 一元表达式的规则 /
: DOUBLE_LITERAL / 实数的字面常量 /
;
这些语法规则可以用图2-5这样的语法图(syntax graph或syntax diagram)来表示。
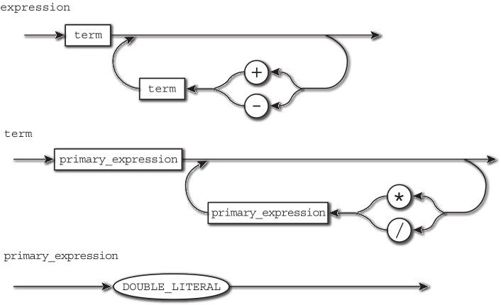
图2-5 计算器的语法图
语法图的表示方法应该一看就能明白,比如项目(term)的语法图代表最初进入一元表达式(primary_expression),一元表达式可以直接结束,也可以继续进行 *或 /运算,然后又有一个一元表达式进入,重复这一流程。作为语法构成规则的说明,语法图要比BNF更容易理解吧。
本书的语法图例中,非终结符用长方形表示,终结符(记号)用椭圆形表示。
正如语法图所示,递归下降分析法读入记号,然后执行语法分析。
比如解析一个项目(term)的函数 parse_term(),如代码清单2-8 所示,按照语法图所示流程工作。
代码清单2-8 parser.c(节选)
/ primary expression的解析函数 /
51: v1 = parse_primary_expression();
52: for (;;) {
53: my_get_token(&token);/ 循环扫描“”、“/”以外的字符 */
54: if (token.kind != MUL_OPERATOR_TOKEN
55: && token.kind != DIV_OPERATOR_TOKEN) {/ 将记号Token退回 /
56: unget_token(&token);
57: break;
58: }/ primary expression的解析函数 /
59: v2 = parse_primary_expression();
60: if (token.kind == MUL_OPERATOR_TOKEN) {
61: v1 *= v2;
62: } else if (token.kind == DIV_OPERATOR_TOKEN) {
63: v1 /= v2;
64: }
65: }
66: return v1;
如同语法图中最开始的 primary_expression 进入一样,第51行的 parse_primary_expression() 会被调用。递归下降分析法中,一个非终结符总对应一个处理函数,语法图里出现非终结符就代表这个函数被调用。因此在第52行下面的 for语句会构成一个无限循环,如果 (MUL_OPERATOR)与 /(DIV_OPERATOR)进入,循环会持续进行(其他字符进入则通过第57行的 break跳出)。而第59行第二次调用 parse_primary_expression(),与语法图中 和 /右边的 primary expression相对应。
比如遇到语句 1 2 + 3,第51行的 parse_primary_expression()将 1读入,第53行 my_get_token()将 读入,接下来第59行的 parse_primary_expression()将 2读入。之后的运算符根据种类不同分别执行乘法(第61行)或除法(第63行)。
至此已经计算完毕 1 * 2,然后第53行的 my_get_token()读入的记号是 +。 +之后再没有 term进入,用 break从循环跳出。但由于此时已经将 +读进来了,因此还需要用第56行的 unget_token() 将这个记号退回。parser. c 没有直接使用lexicalanalyzer.c 中写好的 get_token(),而使用了 my_get_token(), my_get_token()会对1个记号开辟环形缓冲区(Ring Buffer)(代码清单2-9第7行的静态变量 st_look_ahead_token 是全部缓冲),可以借用环形缓冲区将最后读进来的1个记号用 unget_token() 退回。这里被退回的 +,会重新通过 parse_expression() 第78行的 my_get_token() 再次读入。
完整代码如代码清单2-9所示。
根据语法图的流程可以看到,当命中非终结符时,会通过递归的方式调用其下级函数,因此这种解析器称为递归下降解析器。
这个程序作为一个带有运算优先级功能的计算器来说,代码是不是出乎意料地简单呢。那么请尝试对各种不同的算式进行真机模拟,用debug追踪或者 printf()实际调试一下吧。
代码清单2-9 parser.c
1: #include <stdio.h>
2: #include <stdlib.h>
3: #include "token.h"
4:
5: #define LINE_BUF_SIZE (1024)
6:
7: static Token st_look_ahead_token;
8: static int st_look_ahead_token_exists;
9:
10: static void
11: my_get_token(Token *token)
12: {
13: if (st_look_ahead_token_exists) {
14: *token = st_look_ahead_token;
15: st_look_ahead_token_exists = 0;
16: } else {
17: get_token(token);
18: }
19: }
20:
21: static void
22: unget_token(Token *token)
23: {
24: st_look_ahead_token = *token;
25: st_look_ahead_token_exists = 1;
26: }
27:
28: double parse_expression(void);
29:
30: static double
31: parse_primary_expression()
32: {
33: Token token;
34:
35: my_get_token(&token);
36: if (token.kind == NUMBER_TOKEN) {
37: return token.value;
38: }
39: fprintf(stderr, "syntax error.\n");
40: exit(1);
41: return 0.0; / make compiler happy /
42: }
43:
44: static double
45: parse_term()
46: {
47: double v1;
48: double v2;
49: Token token;
50:
51: v1 = parse_primary_expression();
52: for (;;) {
53: my_get_token(&token);
54: if (token.kind != MUL_OPERATOR_TOKEN
55: && token.kind != DIV_OPERATOR_TOKEN) {
56: unget_token(&token);
57: break;
58: }
59: v2 = parse_primary_expression();
60: if (token.kind == MUL_OPERATOR_TOKEN) {
61: v1 *= v2;
62: } else if (token.kind == DIV_OPERATOR_TOKEN) {
63: v1 /= v2;
64: }
65: }
66: return v1;
67: }
68:
69: double
70: parse_expression()
71: {
72: double v1;
73: double v2;
74: Token token;
75:
76: v1 = parse_term();
77: for (;;) {
78: my_get_token(&token);
79: if (token.kind != ADD_OPERATOR_TOKEN
80: && token.kind != SUB_OPERATOR_TOKEN) {
81: unget_token(&token);
82: break;
83: }
84: v2 = parse_term();
85: if (token.kind == ADD_OPERATOR_TOKEN) {
86: v1 += v2;
87: } else if (token.kind == SUB_OPERATOR_TOKEN) {
88: v1 -= v2;
89: } else {
90: unget_token(&token);
91: }
92: }
93: return v1;
94: }
95:
96: double
97: parse_line(void)
98: {
99: double value;
100:
101: st_look_ahead_token_exists = 0;
102: value = parse_expression();
103:
104: return value;
105: }
106:
107: int
108: main(int argc, char **argv)
109: {
110: char line[LINE_BUF_SIZE];
111: double value;
112:
113: while (fgets(line, LINE_BUF_SIZE, stdin) != NULL) {
114: set_line(line);
115: value = parse_line();
116: printf(">>%f\n", value);
117: }
118:
119: return 0;
120: }
补充知识 预读记号的处理
本书中采用的递归下降解析法,会预先读入一个记号,一旦发现预读的记号是不需要的,则通过 unget_token()将记号“退回”。
换一种思路,其实也可以考虑“始终保持预读一个记号”的方法。按照这种思路,代码清单2-9可以改写成代码清单2-10这样:
代码清单2-10 parser.c(始终保持预读版)
/ token变量已经放入了下一个记号 /
parse_primary_expression();
for (;;) {
/ 这里无需再读入记号 /
if (token.kind != MUL_OPERATOR_TOKEN
&& token.kind != DIV_OPERATOR_TOKEN) {
/ 不需要退回处理 /
break;
}
/* token.kind 之后还会使用,所以将其备份
- 而parse_primary_expression() 也就可以读入新的记号
*/
kind = token.kind;
my_get_token(&token);
v2 = parse_primary_expression();
if (token.kind == MUL_OPERATOR_TOKEN) {
v1 *= v2;
} else if (token.kind == DIV_OPERATOR_TOKEN) {
v1 /= v2;
}
}
比较这两种实现方式,会发现两者的实质基本上是一样的。很多编译器入门书籍中列举的实例代码,和本书中的例子相差无几。
不过这里还是会有个人偏好,就我而言,更喜欢“边读入边退回”的方法。在“始终保持预读”的方法中,变量token是一个全局变量,代码中相隔很远的地方也会操作其变量值,追踪数据变化会比较麻烦。
