9.2 异常处理机制
在现在的语言中,当程序运行过程中发生了预期之外的情况时,一般会发生 异常 (exception)。在C语言中,多数情况下会通过返回值不停地给调用者返回“错误状态”。这种做法不仅很麻烦,还会使代码由于嵌入了异常处理程序而变得难以阅读。
因此,我考虑在crowbar和Diksam中引入异常的概念。
9.2.1 为crowbar引入异常
在crowbar中引入了与Java相同的 try~catch~finally处理方式。
在Java和C#的 catch子句中虽然可以对应不同的异常类型并进行处理,但是因为crowbar中本来就没有类型,所以也就只写一个 catch子句。具体的示例请参考代码清单9-6。
代码清单9-6 crowbar的异常处理示例
1: try {
2: zero = 0;
3: a = 3 / zero;
4: } catch (e) {
5: # 通过child_of方法判断异常种类
6: if(e.child_of(DivisionByZeroException)) {
7: print("不能被0除。\n");
8: } else {
9: throw e;
10: }
11: }
代码清单9-6的第3行试图用3除以0,这样做会发生被0除的异常(这里特意使用变量 zero的原因是,如果直接使用 3/0的话在编译时会出现错误)。
第4行的 catch子句捕捉了这个异常。
第6行中,通过调用捕获异常对象的 child_of()方法来检查异常的类型。这段代码里检查了异常是否是 DivisionByZeroException类型,如果是则输出错误信息。
如果不是处理器定义的异常,而是自己认为发生了异常情况,可以使用 throw抛出自定义异常。
e = new_exception("错误信息");
throw e;
new_exception()是一个原生函数。返回值为异常对象,是一个assoc。调用 new_exception()时,会在返回值中保存栈轨迹(stack strace)。这个异常如果没有被 catch的话,会一直传播到顶层结构。处理器会记录栈轨迹,也可以通过 print_stack_trace()方法从程序中输出栈轨迹。
像被0除这种在处理器中发生的异常通常都会有父子关系,例如 DivisionByZeroException 就是 ArithmeticException 的子类。因此, 在 代 码 清 单 9-6 的 第6行 可 以 将 DivisionByZeroException 替 换为 ArithmeticException, child_of()方法仍然会返回真。
通过在各“异常类”中保存父异常的方式来实现这种父子关系。另外,当然无论是 ArithmeticException 还是 DivisionByZeroException 都不是关键字,只是全局变量而已。说了这么多,还是快点来看一段代码吧(代码清单9-7)。
代码清单9-7 “异常类”的实现
1: function create_exception_class(parent) {
2: this = new_object();
3: this.parent = parent;
4: this.create = closure(message) {
5: e = new_exception(message);
6: e.stack_trace.remove(0);
7: e.child_of = this.child_of;
8: return e;
9: };
10: this.child_of = closure(o) {
11: for (p = this; p != null; p = p.parent) {
12: if (p == o) {
13: return true;
14: }
15: }
16: return false;
17: };
18: return this;
19: }
20:
21: RootException = create_exception_class(null);
22: BugException = create_exception_class(RootException);
23: RuntimeException = create_exception_class(RootException);
24: ArithmeticException = create_exception_class(RuntimeException);
25: VariableNotFoundException = create_exception_class(BugException);(之后省略)
代码清单9-7的源文件在buitin目录下的builtin.crb中。具体是如何加载它的将在9.3节中介绍。
从第1行开始的 create_exception_class()函数是“异常类”的构造函数。各种异常类型从第21行开始被定义为全局变量。异常类对于程序来说只存在一个,可以通过调用异常类的 create()方法来创建这个异常类的实例。
父异常通过“异常类”的构造函数接收的参数 parent被保存起来。因此,第10行的 child_of()方法可以检查异常的层级。只是,由于 child_of()是“异常类”的方法,因此在创建异常的实例时要把它设置到异常的实例中(第7行)。异常实例中的 parent成员即使什么都没有,也可以调用 child_of()方法,这就是闭包的魔力。
另外,第6行移除了栈轨迹的第一个元素,这样做是为了不让栈轨迹中包含调用 create()方法的痕迹。
在crowbar中,异常的栈轨迹以下面的格式输出。
不能被0除。
func at 6
func at 3
func at 3
func at 3
top_level at 9
上面这段输出来自代码清单9-8。在递归调用 func()时, DivisionByZero Exception异常会发生在程序的深处。
代码清单9-8 exception.crb
1: function func(count) {
2: if (count < 3) {
3: func(count + 1);
4: }
5: zero = 0;
6: a = 3 / zero;
7: }
8:
9: func(0);
9.2.2 setjmp()/longjmp()
crowbar的程序是一边递归分析树一边执行的。因此,在发生异常的时候,会一下子追溯到C语言的调用层级中。
crowbar 的控制结构 return、 break、 continue 有着同样的问题,在使用上述控制结构时,会通过返回值将各种状态返回给调用者。但是,相对于 return 和 break 只会发生在“语句”级别,异常有可能发生在“表达式”的深处,因此要将它对应返回值会比较麻烦。这种情况下,我们可以使用 setjmp()/ longjmp()。
普通的C语言使用者可能大多数还不太熟悉 setjmp()/ longjmp()。更确切地说,有的人认为“它是一个比 goto还要邪恶的,可以跨越函数界限进行长距离(long)跳转(jmp)的可怕函数!”
但是,无论什么事情,无论是好是坏,都要好好的研究一下才能下结论。如果自己连用都没用过就说“这个不好用”,那这人也实在是荒唐。
所以,以下我们先简单地看一下 setjmp()/ longjmp()。
setjmp()的参数是 jmp_buf类型的变量,调用函数时在参数中保存程序的上下文。
longjmp()用于返回到使用 setjmp()保存的位置。
即使通过多次函数调用进行到了很深的级别,也可以瞬间返回。
从 longjmp() 这个名字就可以看出来,它可以跨越函数界限随意跳转到任何位置。但实际上,它只能“返回”到使用 setjmp() 标记过的位置。在 longjmp()看来, setjmp()标记的必须是“调用者”。在 longjmp()的时候,被 setjmp()标记了的函数在没有返回的情况下会从栈中删除。基于以上操作,我觉得这个方法叫 longjmp() 有点不太合适,应该叫 longreturn() 才更加贴切。
更重要的是,setjmp()在保存程序上下文的时候返回0。在使用longjmp()返回时,longjmp()的第2个参数也会跟着返回。根据第2个参数返回的值,可以判断出当前执行的程序是从哪个 longjmp()返回的。
使用这两个函数编写下面这段代码的时候,可以从深层的函数调用中瞬间返回回来。
/ 为了保存调用者的程序上下文,声明了一个变量 /
jmp_buf recovery_environment;
if (setjmp(recovery_environment) == 0) {
/* setjmp()在第一次调用的时候返回0,进入这个分支
在这个分支中进行正常情况下的处理
在这里调用了longjmp()后,会执行下面的else子句。
对于longjmp()的调用,在这里即使进行了
深层次的函数调用,其结果也不会改变。
*/
long_jmp(recovery_environment, 1);
} else {
/* 执行了longjmp()之后会进入这个分支进行处理
*/
}
作为参数被传入 setjmp()的 jmp_buf类型变量中保存着“当前程序的上下文”。“当前程序的上下文”中包含了当前寄存器的值等很多东西,但首当其冲要记录的我认为就是 setjmp()被调用的地点。再把这个 jmp_buf当做参数传递给 longjmp()的话,就应该能返回到 jmp_buf记录的地点了。
另外,可能有人会有这样的疑问:“ setjmp()的参数并没有加上 &传递,为什么还能保存程序的上下文呢?C的参数不是按值传递的吗?”这是因为 jmp_buf类型被 typedef成了数组。请务必检查您环境的头文件。我觉得这是一个会招致混乱的设计。
实际上crowbar的异常处理在代码清单9-9中进行了实现(execute.c)。
代码清单9-9 execute_try_statement()函数
1: static StatementResult
2: execute_try_statement(CRB_Intercepter inter, CRB_LocalEnvironment env,
3: Statement *statement)
4: {
5: StatementResult result;
6: int stack_pointer_backup;
7: RecoveryEnvironment env_backup;
8:
9: / 备份crowbar栈的栈指针和jmp_buf /
10: stack_pointer_backup = crb_get_stack_pointer(inter);
11: env_backup = inter->current_recovery_environment;
12: if (setjmp(inter->current_recovery_environment.environment) == 0) {
13: / 执行try子句 /
14: result = crb_execute_statement_list(inter, env,
15: statement->u.try_s.try_block
16: ->statement_list);
17: } else {
18: / 发生异常时的处理。首先恢复crowbar的栈和jmp_buf /
19: crb_set_stack_pointer(inter, stack_pointer_backup);
20: inter->current_recovery_environment = env_backup;
21:
22: if (statement->u.try_s.catch_block) {
23: / 执行catch子句 /
24: CRB_Value ex_value;
25:
26: ex_value = inter->current_exception;
27: CRB_push_value(inter, &ex_value);
28: inter->current_exception. type = CRB_NULL_VALUE
29:
30: assign_to_variable(inter, env, statement->line_number,
31: statement->u.try_s.exception, &ex_value);
32:
33: result = crb_execute_statement_list(inter, env,
34: statement->u.try_s.catch_block
35: ->statement_list);
36: CRB_shrink_stack(inter, 1);
37: }
38: }
39: inter->current_recovery_environment = env_backup;
40: if (statement->u.try_s.finally_block) {
41: / 执行finally子句 /
42: crb_execute_statement_list(inter, env,
43: statement->u.try_s.finally_block
44: ->statement_list);
45: }
46: if (!statement->u.try_s.catch_block
47: && inter->current_exception.type != CRB_NULL_VALUE) {
48: / 如果没有catch子句的话,创建新的throw直接抛出异常 /
49: longjmp(env_backup.environment, LONGJMP_ARG);
50: }
51:
52: return result;
53: }
crowbar使用自己的栈计算表达式,在第10行备份了这个栈。因为如果表达式执行到深处时发生了异常的话,就必须要抛弃那个时候的栈。
另外,在第11行使用变量 evn_backup 进行了备份,这个变量的类型是 RecoveryEnvironment,因此它的实体只包含了一个 jmp_buf 的结构体(这里特意声明了一个结构体以备将来扩展)。
这两个用于备份的局部变量被放在了C的栈上。因此,没有 catch子句或从 catch子句中再 throw后,无论返回到任何阶段(第49行),都需要依次从C栈上的备份中恢复这两个变量。
并且,无论从 try子句中调用什么阶段的函数,如果在深层发生异常,是不能瞬间返回到catch中,而是顺着函数调用的顺序返回的。因此,在调用crowbar函数的时候也会执行 setjmp()。这样做的前提是 CRB_LocalEnvironment在必要的时候能够开放(基于eval.c的 eval_function_call_expression())。
stack_pointer_backup = crb_get_stack_pointer(inter);
env_backup = inter->current_recovery_environment;
if (setjmp(inter->current_recovery_environment.environment) == 0) {
do_function_call(inter, local_env, env, expr, func);
} else {
/ 如果在函数内发生异常的话,抛弃LocalEnvironment /
dispose_local_environment(inter);
crb_set_stack_pointer(inter, stack_pointer_backup);
/ 紧接着调用longjmp() /
longjmp(env_backup.environment, LONGJMP_ARG);
}
inter->current_recovery_environment = env_backup;
dispose_local_environment(inter);
另外,在代码清单9-9 的第47行检查了 inter->current_exception. type,这样做是为了保证它保存的是“当前的异常”,以便在 throw的时候进行设置。因此,它会在 catch子句中被抛弃(第28行),并在catch子句执行(第33~35行)并且发生异常的时候被重新设置。
再来说说 finally子句,一旦进入了 try子句就“必须”要执行 finally子句。例如在下面这段代码中使用 break跳出了 for语句,即使是在这种情况下,在跳出循环之前也必须要执行 finally子句。
for (;;) {
try {
break;
} finally {
即使进行了break,这里的代码也会执行
}
}
在crowbar 中出现了 break 等跳转语句时,将把语句的执行结果(CRB_StatementResult)作为返回值返回给调用者(请参考3.3.6节)。在代码清单9-9中,无论 try子句得到怎样的执行结果都会执行 finally子句,以保证“必须执行 finally”。但是,另一方面,如果 try子句中进行了 break的话,在 finally执行结束后还是要执行 break。还有,如果在 try中 return 3;、在finally 中有 return 5; 的时候,到底要返回哪个才对呢?在Java 中,如果在 finally子句中写了 return、 break等控制语句的话, javac会发出警告。C#中则会直接发生编译错误。
在crowbar中, try语句最终执行结果的原则是,无论finally中是什么结果都会被忽略,要优先使用 try或者 catch子句的执行结果。
补充知识 Java和C#异常处理的不同
关于Java和C#异常处理的不同点,通过搜索引擎搜索“Java C# 异常 不同”这样的关键字就能得到“有无检查异常”的相关资料。
这点会在9.2.6节的补充知识中做介绍。除此之外,C#的异常和Java的异常还有很多区别,Java的程序员如果使用C#的话会很容易上手(反过来就不一定了)。
首先,在Java中,异常的栈轨迹创建于“异常 new出来的时候”。比如下面这段程序中,异常一被new出来后马上就输出栈轨迹,此时可以把当前的栈轨迹完全输出出来。
Exception e = new Exception();
e.printStackTrace();
多数人可能会在调试的时候编写这样的代码。 与此相对在 C# 中,栈轨迹在“throw之后返回到方法调用的层级的时候”被依次组装起来的。可以通过代码清单9-10的示例代码来确认这个问题。
代码清单9-10 C#的异常
1: using System;
2: using System.Collections.Generic;
3: using System.Text;
4:
5: namespace ExceptionTest
6: {
7: class Program
8: {
9: static void Sub(int count)
10: {
11: if (count == 0)
12: {
13: throw new Exception();
14: }
15: try
16: {
17: Sub(count - 1);
18: }
19: catch (Exception e)
20: {
21: // 进行递归调用使异常发生在较深的层级
22: // 每一个层级catch到异常后,再继续throw。
23: // 在每次catch的时候,栈轨迹都会随之增长,从这点就可以看出
24: // C#中异常的栈轨迹,是在返回到调用者的层级后
25: // 再进行组装的。
26: Console.WriteLine("** count.." + count + "*");
27: Console.Write(e.ToString());
28: throw;
29: }
30: }
31:
32: static void main (string[] args)
33: {
34: try
35: {
36: Sub(10);
37: }
38: catch (Exception e)
39: {
40: Console.WriteLine("** final *");
41: Console.Write(e.ToString());
42: }
43: }
44: }
45: }
说到这样做的理由,比如创建异常在某个工具类中的时候,如果栈轨迹中只包含了这个工具类的方法的话,就会让调试人员摸不着头脑。实际上,crowbar也采用Java的方式(见代码清单9-7),为了从栈轨迹中删除第4行的 create()方法,不得不在第6行做那样奇怪的事情。
在 C# 中,调试时如果想看一下栈轨迹的话,可以使用 Environment.StackTrace。
另外,在Java中被 catch到的异常如果想再次抛出的话,要编写下面这段代码:
} catch(HogeException e) {
·
·
·
throw e;
}
但是,在C#中 throw的时候,会重新设置 e中的栈轨迹,从而在C#中只需要这样写就可以了:
throw;
C#中增加了“将在 catch子句中捕获的异常直接抛出”的语法。
在crowbar中既然采用了Java的方式,那么在Diksam中让我们来试试看C#的方式。具体的实现方式将在下一节中介绍。
9.2.3 为Diksam引入异常
说完了crowbar,本节就要为Diksam引入异常的概念了。
下面就为Diksam引入与Java和C#相同的异常处理机制。
try {
/ try子句 /
} catch (HogeException e) {
/ 与HogeException对应的catch子句 /
} catch (PiyoException e) {
/ 与PiyoException对应的catch子句 /
} finally {
/ finally子句,这里的代码必然会执行 /
}
由于crowbar 中没有类的概念 [8],因此只能编写一个 catch 子句。但是在Diksam中与Java相同,可以编写与各种异常类对应的 catch子句。
另外,和Java、C#等相同的地方是,也可以通过 throw抛出异常。
throw e; // throw异常e
crowbar 使用了Java 的风格,即在 new 异常的时候创建栈轨迹,因此在Diksam中要使用C#的风格,即在 throw的时候创建栈轨迹(请参考9.2.2节的补充知识)。所以,在catch子句中抛出异常的时候可以只写 throw;。
另外,和Java、C#等相同的可以被 throw和 catch的只有 Exception的子类 [9]。
补充知识 catch的编写方法
如前面所述,在crowbar中只能编写一个 catch子句,但是在Diksam中就可以编写与各种异常类对应的 catch子句。“可以编写”看上去是一个很方便的功能,但是实际使用起来就不是那么方便了。
例如,异常A和异常B想要进行同样的处理,但是这种时候根据Java的风格,就只能把同样的 catch子句编写多次了。这样一来就违反了“同样的代码不能在多个位置编写”的编码大原则。
当然,如果异常A和异常B用同样的超类的话,可以通过 catch超类的方式达到目的,但是异常的层级通常都是从提供异常类的角度、而不是从异常使用者的角度出发的。
假设“想要对异常A和异常B进行同样的处理”的时候,就必须要简单地描述OR条件,只有这样才可以考虑在 catch子句中用逗号分隔的方式指定要处理的类(先忽略如何将异常赋值给变量的事情)。还有一种情况,那就是“异常A和异常B使用同样的处理方式,异常C使用另外的处理方式,但无论是什么样的异常,都会有输出日志的通用处理”。基于上面这些考虑,我想还是像下面这样,在一个 catch子句中使用 if语句来判断可能更好。
try{
·
·
·
} catch (Exception e) {
// 通用处理
if (e instanceof A || e instanceof B) {
// 处理异常A或者是异常B
} elsif (e instanceof C) {
// 处理异常C
} else {
// 预想外的异常向上throw
throw;
}
}
但这个方法要想处理发生的意料之外的异常,就必须要在 if语句的 else子句中继续 throw异常。这段代码非常容易被忘记。
更重要的是,使用者既可以像Java那样编写多个 catch子句,也可以像上面的代码那样编写一个 catch子句,但如果只写一个 catch子句的话,编码方式就不能像Java一样了。这意味着给了使用者更多的选择,在这点上Diksam和Java是一致的。
9.2.4 异常的数据结构
try语句中包含了 try、 catch和 finally三个子句。用 DVM_Try结构体表示的话如下所示。
/ catch子句 /
typedef struct {
int class_index; / 使用了catch的类的索引值 /
int start_pc; / catch开始位置的PC(程序计数器)/
int end_pc; / catch结束位置的PC /
} DVM_CatchClause;
/ try语句 /
typedef struct {
int try_start_pc; / try开始位置的PC /
int try_end_pc; / try结束位置的PC /
int catch_count; / catch子句的数量 /
DVM_CatchClause catch_clause; / catch子句的可变长数组 */
int finally_start_pc; / finally开始位置的PC /
int finally_end_pc; / finally结束位置的PC /
} DVM_Try;
在 DVM_Try结构体的可变长数组中可以添加顶层结构和 DVM_Function。另外,由于顶层结构和函数(的程序块)增加了一些附加信息,因此这次把“程序块”也作为结构体抽取了出来。
typedef struct {
int code_size;
DVM_Byte *code;
int line_number_size;
DVM_LineNumber *line_number;
int try_size; / try子句的数量 /
DVM_Try try; / try子句的可变长数组 */
int need_stack_size;
} DVM_CodeBlock;
虽然除了新增的 try 子句的相关成员外,其他成员都在以前的 DVM_Executable(顶层结构部分)和 DVM_Function(各函数部分)中出现过了,但这里还是应该把它作为单独的结构体区分出来。DVM_Try 中的数组(在generate.c 中)在后续遍历(post-order traversal)分析树时,每当遇到 try 语句的时候就在数组末尾增加元素(generate_try_statement())。因此,这个数组是按照程序层级的深度来排列try语句的(越深层级的try就越被排在前面)。
在发生异常的时候,首先将这个异常设置到 DVM_VirtualMachine结构体的 current_exception成员(新增)中,再将DVM设置为“异常状态”。
基于以上介绍,我们以从0开始按顺序扫描 DVM_Try的数组,寻找包含这个位置的程序计数器的 try语句。结果有以下几种情况。
1. 异常发生在 try语句的 try子句中
在这种情况下,首先要寻找捕捉已发生异常的 catch子句,如果发现了,就解除异常状态并将控制权移交给相应的 catch子句。
如果没有与异常对应的 catch子句,就把控制权移交给 finally子句。
2. 异常发生在 try语句的 catch子句中
在这种情况中,不解除异常状态并将控制权移交给 finally子句。
3. 异常发生在 try语句的 finally子句中
在这种情况中,和4.的处理方式相同。
4. 异常发生在 try语句之外
强制从当前函数中返回,并试图从基于当前位置的 DVM_Try中寻找包含当前程序计数器的 try语句,以此方式修正异常。
Diksam的编译为了处理起来简单,不论 try语句中是否有 finally子句,都将为它创建一个 finally。这个将在后面介绍。
这个处理的代码如代码清单9-11 所示。第14行调用的函数 throw_in_try(),会在上述1、2的情况下返回真。
代码清单9-11 发生异常时的处理
1: static DVM_Boolean
2: do_throw(DVM_VirtualMachine *dvm,
3: Function func_p, DVM_Byte code_p, int code_size_p,int pc_p,
4: int base_p, ExecutableEntry *ee_p, DVM_Executableexe_p,
5: DVM_ObjectRef *exception)
6: {
7: DVM_Boolean in_try;
8:
9: dvm->current_exception = *exception;
10:
11: for (;;) {
12: /* 当异常发生在try语句的try子句或catch子句的时候,
13: throw_in_try函数会将设置跳转地址并返回真。*/
14: in_try = throw_in_try(dvm, exe_p, ee_p, *func_p, pc_p,
15: &dvm->stack.stack_pointer, *base_p);
16: if (in_try)
17: break;
18:
19: if (*func_p) {
20: /* 当异常发生在finally子句或者try语句外的时候,
21: 把发生异常的位置记录到栈轨迹中并强制返回。
22: 在返回之后,将再次使用throw_in_try进行修复。*/
23: add_stack_trace(dvm, exe_p, func_p, *pc_p);
24: / do_return在要程序返回原生函数时返回真,这里不做详细说明。/
25: if(do_return(dvm, func_p, code_p, code_size_p, pc_p,
26: base_p, ee_p, exe_p)){
27: return DVM_TRUE;
28: }
29: } else {
30: / 在返回到顶层结构的时候将栈轨迹输出并终止程序的执行。 /
31: int func_index
32: = dvm_search_function(dvm,
33: DVM_DIKSAM_DEFAULT_T_PACKAGE,
34: DIKSAM_PRINT_STACK_TRACE_FUNC);
35: add_stack_trace(dvm, exe_p, func_p, *pc_p);
36:
37: invoke_diksam_function_from_native(dvm, dvm->function[func_index],
38: dvm->current_exception, NULL);
39: exit(1);
40: }
41: }
42: return DVM_FALSE;
43: }
9.2.5 异常处理时生成的字节码
首先,在使用者编写了像 throw e;这样的代码在抛出异常的时候,这里将会创建 throw指令。编译器会将眼前的 e入栈,因此这个指令会抛出保存在栈顶的异常。
Diksam 的异常与C# 风格相似,只需要写 throw; 就可以将当前 catch 的异常抛出去(请参考9.2.2节的补充知识)。在这个时候会创建指令 rethrow,但是在 rethrow指令中依旧不变地抛出保存在栈顶的异常(编译器会悄悄地把在 catch子句中定义的变量入栈)。和 throw动作不同的只是不会重新设置栈轨迹。
try子句通常会生成下面这样的字节码(为了方便说明,使用了仿真代码,并在左边添加了行号)。
1: # 在这里加入try子句的指令
2: go_finally 14
3: jump 16
4: # 第一个catch子句
5: pop_stack_object n # 将异常赋值给变量
6: # 这里插入catch子句的指令
7: go_finally 14
8: jump 16
9: # 第二个catch子句
10: pop_stack_object n # 将异常赋值给变量
11: # 这里插入catch子句的指令
12: go_finally 14
13: jump 16
14: # 这里插入finally子句的指令
15: finally_end
16: # 之后的处理
首先,请看一下每个 catch子句开头的 pop_stack_object。这是为了在下面这种情况时,把异常的引用赋值给变量 e。
} catch (HogeException e) {
…
}
也就是说,DVM 将异常入栈为栈顶并将控制权移交给各 catch 子句。当然, e作为函数外的变量被 pop_static_object创建。
在 try子句、 catch子句的末尾都要生成 go_finally指令。这意味着通过在一个函数内部调用子例程的方式来调用finally [10]。
乍看之下,我认为不需要特意增加这个指令,只要跳转到第14行就可以了。但是,正如 9.2.2 节中写到的,即使在 try 子句中进行了 break 或者 return, finally 子句也必然会执行。因此,如果 try 子句中包含了 break,编译器也会在 break前面输出 go_finally指令。执行 finally子句后,如果没有异常状态的话,就会执行 finally_end 指令返回到原来的位置。如果调用了 finally_end后不能返回到原来的位置的话,就会执行和再次抛出异常时同样的动作。
go_finally 会将返回的目的地的 pc 入栈。之所以必须要使用栈是因为在 finally中也可以编写 try语句。
9.2.6 受查异常
Java具有 受查异常 的功能。这是一种在方法声明时对方法可能抛出的异常进行声明的功能(下面这段代码就表明了“这个方法有抛出 HogeException和 PiyoException的可能”)。
void hoge() throws HogeException, PiyoException {
…
}
这样一来,在调用上面的 hoge()方法的时候,对于该方法的调用者来说,要么 catch 所有已经被声明的异常,要么自己也通过 throws 抛出这些异常,将处理异常的任务交给自己的调用者。如果你什么都不做,就会在编译时报错(除非是 Error 或者 RuntimeException 的子类)。Java 利用这个功能保证应该处理的异常已经全都被处理掉(至少是以此为目标)。
正如后面会介绍到的,对于这个功能也有一些异议,但我认为这是一个重要的功能,因此在Diksam中也进行了实现。
Diksam中受查异常的设计和Java相同。
首先,要让函数和方法能够描述 throws子句。
// 为函数添加throws
void func() throws HogeException, PiyoException {
…
}
在上述例子中,由于 func()已经声明了它可能会发生 HogeException和PiyoException,这时候如果在函数内发生了上述两个异常之外的异常,并且又没有 catch的话,就会发生编译错误。
但是,像 NullPointerException 这样的在程序各处都会发生的异常应该被另行处理。在Diksam 中异常的层级有三个,它们分别是 BugException、 RuntimeException 和 ApplicationException。 其 中, 只有 ApplicationException是受查异常检查的对象(图9-8)。
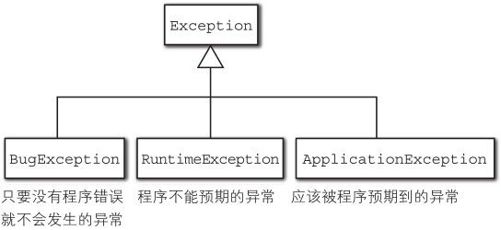
图9-8 Diksam的异常层级
例如,引用了 null的时候会发生 NullPointerException,或者当访问的元素超出了数组的返回时会发生 ArrayIndexOutOfBoundsException,这些异常在Diksam中都被归类为 BugException。这是因为这些异常在调试结束后的正式应用程序中是不应该发生的(我是这么认为的)。因此, BugException不应该被 catch。因为如果这么做就相当于在“掩盖程序错误”。
与此相对,即使没有程序错误也可能发生 RuntimeException,这是由于在写程序的时候只考虑了一般的情况,没有考虑周全,从而发生了(我是这么认为的)异常。在Diksam中,整数被0除也被归为这类异常 [11]。这样的异常应该在调用的层级上被 catch并进行适当地处理。
ApplicationException的发生是被充分预期的。在Diksam中,像NumberFormatException这样的异常被归入此类 [12]。像这样的异常一般会在发生的地方立即由应用程序做适当地处理。
话说回来,由于在Diksam 中 BugException“不应该被 catch”,因此,还是“一旦 catch了 BugException就会发生编译错误”容易一点。但是现在之所以没有这么做,是因为考虑到了像Servlet和Applet之类的在浏览器中运行的程序,即使其中一个Servlet或者Applet中出现了程序错误也不应该导致整个程序的崩溃。但是,在将来也可能会引入像 pragma这样的功能,也许到了那个时候,除了特殊的程序之外,再 catch了 BugException的话,编译就要报错了。
受查异常的实现在f ix_tree.c中进行。
Diksam编译器(在f ix_tree.c中)会对递归分析树“确认”(请参考6.3.4节)。与此同时,也会进行受查异常的检查。
在递归扫描分析树的时候,在递归的路径上(也就是越深越优先)会创建语句或表达式下级可能会发生的异常列表。此时,在 try子句中发生的异常,除了会被 catch子句捕捉之外,剩下的都会被当做是 try语句发生的异常 [13]。这样一来,在函数内发生异常的时候,没有声明 throws的就会导致编译错误。
补充知识 受查异常的是与非
在Java中有受查异常,但是在C#中没有。C#是晚于Java面世的编程语言,因此很多地方都模仿了Java,所以可以断定这个功能是有意被剔除的。关于这点,C#的作者安德斯·海尔斯伯格(Anders Hejlsberg)例举了下面两个理由(应笔者邀请)。
The Trouble with Checked Exceptions [11]
方法升级的时候 throws子句中的异常可能也会随之增加,这样就会影响所有的使用者。实际上,在很多情况下,调用者并不会关心异常的种类,也不会对它们做个别处理。
在扩展性上存在问题。受查异常在很小的程序中可以顺利运行,但是在构建有4个到5个子系统的系统时,每个子系统又返回4~10种异常的话,在多个子系统集成的时候就不得不在 throws后面写上很多的异常。
另外,在下一页中,在上面这些理由的基础上又追加了以下理由(这里也是应笔者邀请)。
《Java理论与实践:关于异常的争论 要检查,还是不要检查》 [12]
throws子句暴露了实现的详细内容。如果在“搜索用户”方法的 throws中有一个 SQLException,这可不是一件好事。
(只要是有受查异常)使用者编写了空的 catch子句,异常也会被当做处理掉了。
上面说了这么多的问题,其实可以通过异常包装的方式来应对。以“搜索用户方法”为例,应该抛出像 NoSuchUserException这样的、对于当前方法层级有意义的异常。从而,如果发生异常的原因是 SQLException的话,应该抛出一个以成员形式保存了 SQLException的 NoSuchUserException。
这个机制,在Java1.4中被引入,C#一开始也有这样的功能。以此为前提的话,我认为受查异常也不是特别“坏”的功能 [14]。
另外,在受查异常中最让人反感的就是,所有方法都只写一句 throws Excep-tion。对于这点,虽然编程语言支持这么做,但是在不需要使用受查异常的时候还是不用为好。至于在Diksam中如何使用,就交给使用者来选择了。
补充知识 异常处理本身的是与非
既然说到了受查异常的是与非,让我们再来看看关于异常处理的两派的论调。
在一本叫作Joel on Software(很有名)的书中,作者Joel Spolsky关于异常的论述如下(拙译):
Exceptions[13]
在源代码中很难看到异常。因为不知道哪里会发生异常,所以即使很缜密地检查了代码,还是很难发现其中的错误。
异常赋予了程序多个“出口”。在编写正确的代码中,程序一定能够掌握执行的路径,但是加入了异常后这件事就办不到了。
Windows的开发者Raymond Chen把异常和早先在返回值中返回错误编码的方式做了比较,请见表9-1和表9-2[14](拙译)。
表9-1 错误编码和异常的比较1

表9-2 错误编码和异常的比较2

下面就举一个实际的例子。
1: NotifyIcon CreateNotifyIcon()
2: {
3: NotifyIcon icon = new NotifyIcon();
4: icon.Text = "Blah blah blah";
5: icon.Visible = true;
6: icon.Icon = new Icon(GetType(), "cool.ico");
7: return icon;
8: }
这段程序本来应该将第5行和第6行反过来写。这是因为在图标创建失败的时候,第6行会发生异常,此时就没有必要把icon.Visible设置为true了 [15]。
可能上述这个Windows编程的经验之谈不太好理解,我再(要举的话还有很多呢)举一个其他的例子。在构建树结构的时候,给父增加子的代码。
node.children = new Node[5];
for (i = 0; i < 5; i++) {
node.children[i] = new Node();
}
在这段代码中,如果前三次循环都正常地执行、第四次的时候发生了异常的话,数组 node.children就会从中间开始变成 null。从数据结构上讲,这种情况大多是不被允许的。在这种情况下,即便是在上层的某处捕获到了异常也很难修复这个错误。为了避免这种情况的发生,应该像下面这样编写代码 [16]。
Node[] nodeArray = new Node[5];
for (i = 0; i < 5; i++) {
nodeArray[i] = new Node();
}
node.children = nodeArray;
但是,如何能够在程序的所有地方都防止这样的错误发生呢?
结果,话题还是回到是不是应该存在异常处理机制的问题上。当然,完美的异常处理是非常困难的。但是,现实中在对信任关系的要求没有那么严格,使用异常处理还可以准确地将错误传递给上层的情况下,我认为异常处理机制还是有必要的 [17]。
对于编写一个将许多数据搜集起来并每日打印一次的小脚本来说,异常可真是个好东西,它可以忽略掉所有会引起问题的地方。我非常喜欢做的就是,利用try/catch整理程序,并在发生异常的时候将问题通过邮件发给我。但是异常只适合一些粗略的工作或者脚本,并不适合关键性的任务和与维持生命相关的程序。假如在操作系统、核能发电或者心脏手术中使用的高速旋转骨锯的控制软件中使用异常的话,是相当危险的事情。
——Joel Spolsky 《软件随想录:程序员部落酋长Joel谈软件》[15]
