6.4 Diksam虚拟机
编译(生成字节码)完成以后,就要放到Diksam虚拟机(DVM:Diksam Virtual Machine)中执行了。
DVM在实现上使用 DVM_VirtualMachine结构体来表示(dvm_pri.h)。
struct DVM_VirtualMachine_tag {
Stack stack;
Heap heap;
Static static_v;
int pc;
Function *function;
int function_count;
DVM_Executable *executable;
};
结构体的前三个成员保存了DVM运行时的记忆空间。如代码所示,DVM具有以下三个记忆空间。
1. 栈
前面已经说过,需要在栈上创建空间的有局部变量、函数的参数或函数返回的返回信息等。
DVM_VirtualMachine结构体的成员 stack,它的类型 Stack如下所示。
typedef struct {
int alloc_size;
int stack_pointer;
DVM_Value *stack;
DVM_Boolean *pointer_flags;
} Stack;
一目了然,栈的实体就是 DVM_Value类型的数组。
DVM_Value 相当于crowbar 中的 CRB_Value,是一个能够保存所有(在Diksam中可以使用的)类型的共用体(DVM.h)。
typedef union {
int int_value;
double double_value;
DVM_Object *object;
} DVM_Value;
DVM_Value与 CRB_Value不同,不会根据类型打上不同标记。静态语言中类型是可以被识别的,因此不再需要标记类型了。
但是,在垃圾回收的时候,仅依靠静态的信息判断栈上的值是否是指针还是有些困难的,但也可以通过函数定义取得局部变量或者参数的类型。同样是保存在栈上,计算过程中的值的类型却很难弄清楚。
因此, Stack 结构体的 pointer_flags 数组保存着栈上的值是否是指针。 pointer_flags数组和 stack的大小相同,可以使用同一个下标进行引用。
Stack结构体的成员 stack_pointer是 栈指示器 (stack pointer),它保存着栈顶的索引值。
栈指示器所指的是下次要入栈的元素的索引值。实际上已入栈元素的索引值是一个小于栈指示器-1的值。
2. 堆
堆是一个通过引用进行访问的内存区域。现在的Diksam中并不存在类和对象,因此现在的堆中只保存字符串。
和crowbar一样,堆上的对象以链表形式保存。
/ 保存对象的结构体 /
struct DVM_Object_tag {
ObjectType type;
unsigned int marked:1;
union {
DVM_String string;
} u;
struct DVM_Object_tag *prev;
struct DVM_Object_tag *next;
};
/ 堆的结构体 /
typedef struct {
int current_heap_size;
int current_threshold;
DVM_Object *header;
} Heap;
3. 静态(static)空间
DVM_VirtualMachine 的static_v成员用来保存全局变量(因为static和C语言的关键字冲突,所以成员的名字用 static_v表示)。
Static结构体的定义如下。
typedef struct {
int variable_count;
DVM_Value *variable;
} Static;
如代码所示,结构体中保存着 DVM_Value的数组。
在使用 push_static_int 等指令引用全局变量时,作为操作数传递给指令的就是这个数组的下标。
另外,在 DVM_VirtualMachine 内用于嵌入到字节码中的值只能来自同一个数组的下标,也就是说,在现在的Diksam语言中,一个DVM只能对应一个 DVM_Executable。
但是很明显,在 DVM_VirtualMachine内不只保存了一个 DVM_Executable。为了解决这个问题,有必要在多个源文件链接并执行的时候进行纠正(请参考8.1.5节)。
DVM_VirtualMachine 还有一个属性pc用来表示程序计数器(program counter)。
程序计数器在字节码中起到保存当前正在执行的指令地址的作用(这里说的“地址”是指保存着字节码的数组的下标)。
因此,在使用跳转命令时,只需要把程序计数器改写为要跳转的目标就可以了。但是,实际上 DVM_VirtualMachine结构体的成员 pc在程序开始执行后立刻就被复制到了局部变量,但在之后却并没有被回写回来,所以现在这个成员派不上什么用场。
其余的两个成员 function和 executable将在后面的章节中进行介绍。
6.4.1 加载/链接DVM_Executable到DVM
在程序执行前,首先必须要为 DVM_VirtualMachine绑定 DVM_Executable,用函数 DVM_add_executable() 来完成这项工作。由于一个 DVM_VirtualMachine只能对应一个 DVM_Executable,因此这个函数的名字有点挂羊头卖狗肉的意思。
在 DVM_add_executable()中会进行以下几个处理。
1. 将函数添加到DVM_VirtualMachine中
在这里我要重申一下,一个 DVM_VirtualMachine 只对应一个 DVM_Executable。但是,像 print()这样的原生函数储存在了别的地方(即 DVM_Executable以外的地方),因此有必要将函数以某种方式进行链接。
DVM_VirtualMachine 结构体的 function 数组正是为此而存在的对应表。
其类型 Function的定义如下所示。
/ 将Function进行分类的标签 /
typedef enum {
NATIVE_FUNCTION,
DIKSAM_FUNCTION
} FunctionKind;
/ 保存print()之类的原生函数 /
typedef struct {
DVM_NativeFunctionProc *proc;
int arg_count;
} NativeFunction;
/ 引用在Diksam中定义的函数 /
typedef struct {
DVM_Executable *executable;
int index;/* 上层executable内(译注:与本函数对应的)DVM_
Function的下标 */
} DiksamFunction;
/ Function结构体本身 /
typedef struct {
char *name;
FunctionKind kind;
union {
NativeFunction native_f;
DiksamFunction diksam_f;
} u;
} Function;
DVM_Executable中保存的函数在执行时使用对应表进行引用。
这个引用表中同样登记着像 print()这样的原生函数,因此利用这个对应表的索引,不论是Diksam中定义的函数还是原生函数,全部可以引用到。
在字节码中调用函数的时候,使用 push_function 指令将函数对应的索引值入栈,这个被嵌入的值,就是在编译时 DVM_Executable 内 DVM_Function数组的下标。
DVM_Function数组中不包含当前源代码中使用的原生函数,因此 Function数组和索引值就会出现差异。下一步就是要修正这个问题。
2. 替换函数的索引
如前面所述,在编译阶段函数的索引对于当前 DVM_Executable来说是局部的,在执行时会被汇总到一个数组中,因此必须要将索引进行转换。
这个操作会直接替换字节码中的操作数。
但是,如果直接调整成与某个 DVM_VirtualMachine匹配的字节码的话,当一个 DVM_Executable 对应多个 DVM_VirtualMachine 时就会出现问题。这个问题将在9.3.4节中修正。
3. 修正局部变量的索引值
在进行上述操作的同时,也会修正局部变量的索引值。
如图6-5所示,引用局部变量时,索引与参数之间隔着返回信息。但是,编译器并不知道返回信息的大小(其实是可以知道的,但是为了信息保密而使编译器不能获取到返回信息的大小),因此在编译时,参数的索引会接着引用后面的索引值。
DVM_add_executable() 中会使用 push_stack_xxx 和 pop_stack_xxx指令对此进行修正。
4. 将全局变量添加到DVM_VirtualMachine中
只是用 DVM_Executable 结构体的 global_variable 数组的个数创建 DVM_VirtualMachine 结构体的 static_v.variable 数组,并初始化数组的值。
6.4.2 执行——巨大的switch case
接下来就要开始执行了。
DVM是一个将编译器生成的字节码逐个执行的虚拟机。也就是说,只要循环地执行一个与字节码的指令种类一样多的巨大 switch case就可以了。
关于这个话题,可能直接看代码会更形象(代码清单6-2)。
代码清单6-2 execute()
static DVM_Value
execute(DVM_VirtualMachine dvm, Function func,
DVM_Byte *code, int code_size)
{
int pc;
int base;
DVM_Value ret;
DVM_Value *stack;
DVM_Executable *exe;
stack = dvm->stack.stack;
exe = dvm->executable;
for (pc = dvm->pc; pc < code_size; ) {
switch (code[pc]) {
case DVM_PUSH_INT_1BYTE:
STI_WRITE(dvm, 0, code[pc+1]);
dvm->stack.stack_pointer++;
pc += 2;
break;
case DVM_PUSH_INT_2BYTE:
STI_WRITE(dvm, 0, GET_2BYTE_INT(&code[pc+1]));
dvm->stack.stack_pointer++;
pc += 3;
break;
case DVM_PUSH_INT:
STI_WRITE(dvm, 0,
exe->constant_pool|[GET_2BYTE_INT(&code[pc+1])]. u.c_int);
dvm->stack.stack_pointer++;
pc += 3;
break;
case DVM_PUSH_DOUBLE_0:
STD_WRITE(dvm, 0, 0.0);
dvm->stack.stack_pointer++;
pc++;
break;
case DVM_PUSH_DOUBLE_1:
STD_WRITE(dvm, 0, 1.0);
dvm->stack.stack_pointer++;
pc++;
break;
case DVM_PUSH_DOUBLE:
STD_WRITE(dvm, 0,
exe->constant_pool|[GET_2BYTE_INT(&code[pc+1])]. u.c_double);
dvm->stack.stack_pointer++;
pc += 3;
break;
case DVM_PUSH_STRING:
STO_WRITE(dvm, 0,
dvm_literal_to_dvm_string_i(dvm,
exe->constant_pool
[GET_2BYTE_INT(&code[pc+1])]
.u.c_string));
dvm->stack.stack_pointer++;
pc += 3;
break;
(之后省略)
现在这个函数(execute.c的 execute()函数)就已经有400多行了,并且还会不断增加。如果有“一个函数必须少于XX行”等这样机械的编码规约的话,那么在实际工程中程序员们肯定会违反这个规则。
但我觉得把一个函数分割开并没有让它变得更易读。即使是规定了“一个函数必须少于XX行”这样机械的编码规约,也不能说编程本身是一项机械的工作。
更重要的是,由于这个函数的内部引用了栈,因此用到了以下这些宏。
STI(dvm, sp), STD(dvm, sp), STO(dvm, sp)
以当前栈指针加上 sp为索引值,返回栈上对应元素值。主要用于四则运算等,也用于双目/单目运算符操作栈顶附近的值。
STI用于 int, STD用于 double, STO用于 string (对象)。下述三个方法同理。
STI_I(dvm, sp), STD_I(dvm, sp), STO_I(dvm, sp)
直接以 sp为索引值,取得栈上对应元素值。使用了 push_stack_xxx、 pop_stack_xxx系列的指令。
这些指令不是用来引用栈顶附近的值的,而是用来引用以 base为起点的索引值对应的栈元素的。
STI_WRITE(dvm, sp, r), STD_WRITE(dvm, sp, r), STO_WRITE(dvm, sp, r)用与 STI()等相同的方法来指定栈上的元素,并在对应元素的位置写入 r。因为使用了 STI()等宏命令,所以可以用 STI(dvm, 0) == xxx的形式进行赋值。但是,由于必须要根据类型是否为指针来设定栈的 pointer_flag,因此特意制作了用来写入的宏。
STI_WRITE_I(dvm, sp, r), STD_WRITE_I(dvm, sp, r), STO_WRITE_I(dvm, sp, r)
直接以 sp为索引值的 STx_WRITE()。
6.4.3 函数调用
作为程序的起始点, execute()函数确实是一个巨大的函数,逐个地执行每个指令绝对不是几行代码就能解决的。
这里将要说明的是一个稍微复杂一些的话题——函数调用。
函数调用按照以下的顺序执行。
1. 将参数以从前向后的顺序入栈。
2. 使用push_function将函数的索引值入栈。
上述操作执行后,栈的状态如图6-7所示。
然后执行invoke指令。
3. 执行invoke,调用栈顶的函数。
如果被调用的函数是一个原生函数,那么上述操作就会实际地执行这个原生函数。
Diksam原生函数的调用形式如下(以 print()为例)。
static DVM_Value
nv_print_proc(DVM_VirtualMachine *dvm,
int arg_count, DVM_Value *args)
{
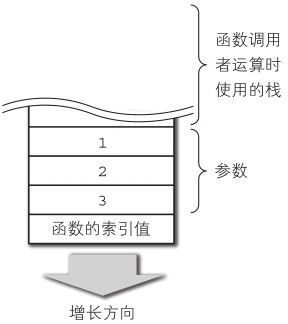
图6-7 函数调用(1)
这里把 DVM_Value的数组作为参数传递给了 nv_print_proc函数,但其实,参数在栈上正好是按顺序排列的,因此这里也可以只传第一个参数的指针。
如果要调用Diksam的函数,要进行以下操作。
4. 将返回信息入栈。
5. 设置base的值。
6. 初始化局部变量。
7. 替换执行中的executable和函数。
8. 将程序计数器置为0并开始执行。
使用 CallInfo结构体来表示之前一直在说的返回信息的实体。
typedef struct {
Function *caller;
int caller_address;
int base;
} CallInfo;
caller指向当前函数的调用者(也是函数), caller_address指向函数内字节码上的地址。 base 指向调用者的 base 值(引用参数或者局部变量的起点)。
在函数被调用的时候,因为栈中还保存着很多运算过程中的值,所以如果 CallInfo中不保存 base的话,函数结束后就无法返回了(因为不知道返回到哪里)。
对于 CallInfo结构体来说,首先要被覆盖设置调用函数的索引(由push_function入栈的)。之后设置新base,创建局部变量的内存区域。在被调用的函数开始执行时,栈的状态如图6-8所示。
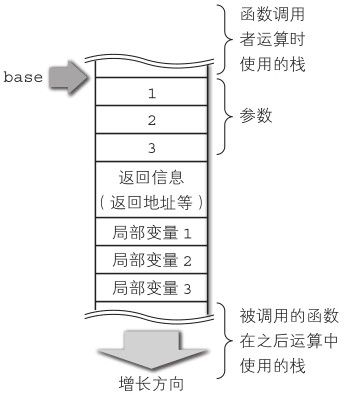
图6-8 函数调用(2)
被调用的函数在达到这个状态后就可以开始执行了。
反过来,从函数中 return的时候是怎样操作的呢?函数在最后结束之前要先执行 return,因此函数在结束时必须在局部变量的下一个位置中保存返回值(如图6-9)。
将参数、 CallInfo、局部变量全部移除后,将返回值移动到栈顶。这样做,即使函数是在表达式的计算过程中被调用的,也可以让它正确地使用函数的返回值(如图6-10)。
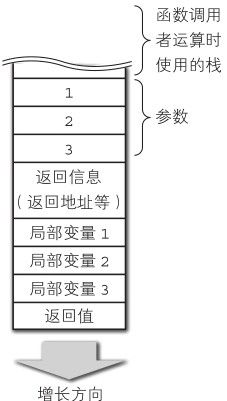
图6-9 函数调用(3)

图6-10 函数调用(4)
注 释
[1]. 虽然现在可能基本上都以 JIT(Just In Time)的方式运行,但是本书中不考虑这种情况。
[3]. 有些语言使用 +,有些使用 .作为运算符。顺便说一下,在crowbar和Diksam中使用的都是 +。
[4]. 静态类型的函数式语言,即使不声明类型,编译器也可以根据类型推论 推测出来。
[7]. 在《征服数组和指针》一书中也做了介绍,可以访问下面的网址阅读。http://avnpc.com/pages/devlang#pointer
[8]. 在C语言的情况下,函数名在表达式中会被转换为“指向函数的指针”,但是在Diksam中没有做这种费力不讨好的事。
[9]. 但是,现在还没有这样的语法结构支持这种类型的声明,所以无法使用。Diksam最终会引入 delegate类型,但与函数的派生无关。
