4.2 制作mark-sweep GC
crowbar book_ver.0.1中采用的引用计数器型GC存在不能释放循环引用的问题,于是在book_ver.0.2中将实现一个mark-sweep型的GC。
4.2.1 引用数据类型的结构
在讨论GC的话题之前,先说明一下crowbar ver.0.2中引用数据类型的处理方式。
crowbar中有以下两种引用数据类型:
数组
字符串
尤其是字符串,它是一个不允许改变内容(immutable)的对象,用户没有必要意识到它是一个引用(请参考4.2.2节的补充知识)。
crowbar的所有值都保存在CRB_Value中。 在crowbar book_ver.0.1里, CRB_Value直接保存着指向 CRB_String的指针。从现在开始,将增加新的 CRB_Object 类型用来统一处理字符串和数组,在 CRB_Value 中将保存指向 CRB_Object的引用。
typedef struct{
CRB_ValueType type;
union{
CRB_Boolean boolean_value;
int int_value;
double double_value;
CRB_NativePointer native_pointer;
CRB_Object object;/ 这个是新增的 */
} u;
} CRB_Value;
用 CRB_Object内的共用体来保存 CRB_String以及为了这次数组而引入的类型 CRB_Array。
typedef enum{
ARRAY_OBJECT = 1,
STRING_OBJECT,
OBJECT_TYPE_COUNT_PLUS_1
} ObjectType;
struct CRB_Object_tag{
ObjectType type;
unsigned intmarked:1;
union{
CRB_Array array;
CRB_String string;
} u;
struct CRB_Object_tag *prev;
struct CRB_Object_tag *next;
};
虽然 CRB_Value 可以明确地区分类型,但是为了在 GC 的时候仅仅使用 CRB_Object 就能区分出来,在 CRB_Object 中保存了一个枚举类型 ObjectType。
CRB_Object的成员 marked作为一个标记对象用的标识符,将用于后面要谈到的mark-sweep GC。至于它的数据类型,由于1个比特就足够了,因此选择了位域(bit field)。
说起位域这个功能,即使在C语言中也不太会用到。现在的免费软件中,应该也有不少自己进行位运算并为 int变量附加各种标识的情况,事到如今也没有理由特意地避开位域这个话题了。不过,如果从富翁式编程的角度出发,就算是1个比特的标志位,可能也得给它分配一个 CRB_Boolean型。
CRB_Object的共用体中保存着 CRB_Array和 CRB_String的引用,它们的定义如下:
struct CRB_Array_tag {
int size;/ 显示用的元素数 /
int alloc_size;/ 实际占用的元素数 /
CRB_Value array;/ 数组元素(数组长度可变)*/
};
struct CRB_String_tag {
CRB_Boolean is_literal;
char *string;
};
为了提高效率,数组在添加元素时一次会多扩展一些空间,所以在 size属性之外还保存了 alloc_size属性。
4.2.2 mark-sweep GC
前面说过,book_ver.0.1中使用的引用计数器式的GC不能释放循环引用。在book_ver.0.1里,GC对象只是为了释放字符串资源,并不会因为循环引用而引起问题。但是有了数组的数组,这样的方式在book_ver.0.2中就有可能引起问题,比如:
a = {1, 2, 3};
b = {4, 5, a};
a[0] = b;
这样一段代码就形成了图4-4中描述的循环引用。
发生循环引用时,即使它们整体上不再被引用,引用计数器此时也不为0。这就是所谓的内存泄漏。
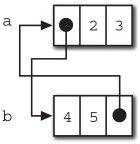
图4-4 循环引用
于是我们抛弃掉引用计数器型的GC,引入 mark-sweep GC。本来所谓的垃圾回收(GC)就是要自动释放不使用的对象占据的内存空间的机制。但是,怎么去定义“不使用的对象”呢?就是“绝对不会被引用到的对象”。比如:
a = {1, 2, 3};
a = {2, 3, 4};
这样一段代码在执行了第二行的赋值语句后, {1, 2, 3}这个数组就不再被引用了,即成为了GC的对象。
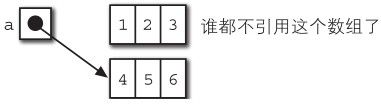
图4-5 对象成为GC目标的例子
所谓mark-sweep GC是一种直接实现定义“不使用的对象”的GC算法。这个算法有以下几个原则。
- 从变量之类的“引用起点”开始,追溯所有能引用到的对象并将其标记。(mark阶段)
2. 将没有被标记的对象全部释放。(sweep阶段)
crowbar里能够成为“引用起点”的有以下几处,我们称这些“引用起点”为 根 (root)。
全局变量
局部变量。包含crowbar中描述的函数的形式参数。
原生函数的形式参数。
表达式计算时的临时引用。
只有从这些根能够追溯到的对象存留下来,其余的对象才能将被视作是GC的目标被释放掉。
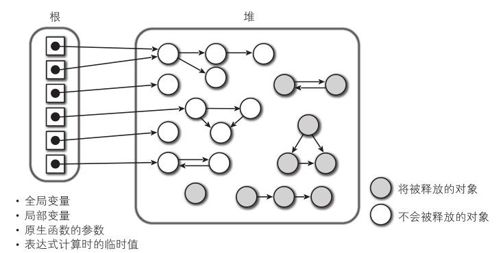
图4-6 成为GC目标的对象
其实这些根中最难处理的就是“表达式计算时的临时引用”。比如有个表达式 "abc" + "def" + "ghi",crowbar的解释器首先会计算 "abc" + "def",生成字符串 "abcdef" [3]。这个字符串的存在是必要的,但不论是全局变量还是局部变量或者原生函数的形式参数都不会引用它,这个时候GC很难决定如何处理。也许有人会想:“在这种关键时刻不要让GC启动不就行了?”下面这个例子就阐述了crowbar为何在此时要启动GC的原因。
print("abc" + "def" + long_long_function());
假如采用了“在表达式计算过程中不进行GC”的原则,但本例中的 long_long_function()在执行过程中不进行GC是不现实的,所以在表达式计算的过程中应该允许启动GC。
crowbar中GC的启动时机将在后面的章节介绍,大概的原则就是,在新分配内存空间的时候有可能会启动。
补充知识 引用和immutable
在crowbar中,整数和实数类型的变量都是把值直接存在 CRB_Value中,但是字符串和数组类型在 CRB_Value中只保存引用。举例来说,Java与crowbar相同,在Java中像 int或者 double这样的类型叫作 原始类型 (primitive type),而像字符串或者数组这样的类型叫作 引用类型 (reference type)。
有人可能会说,存在两个种类的数据类型有违编程之美,可是在crowbar中首先你不必认为字符串是一种引用类型。至于数组,只有像下面这段代码编写出的数组才是一种引用类型。
a = {1, 2, 3};
b = a;
a[1] = 10; ←这行代码也可替换为b[1],效果相同
如果是字符串的话,就没办法改变其内容了(这样的数据类型称为immutable的数据类型)。比如用 +运算符连接字符串,就会得到一个新的字符串对象,之前 A字符串对象的内容不会发生改变。
a = "abc";
b = a;
a = a + "d"; ←a 会变为"abcd",b还是"abc"
另外,crowbar中字符串如果使用==进行比较的话,不是进行引用之间的比较,而是比较字符串的内容。Java在这种情况下比较的就是引用,难不成是特意让人感觉到字符串是一种引用? [4]
按照刚才的思路,可能只能让字符串看起来像是一个原始类型吧,数组仍然是引用类型。但这样的解释并不能让刚才说“存在两个种类的数据类型有违编程之美的人”满意吧。
那么不妨进行一下逆向思维,可以把整数类型和实数类型都看作是引用类型。这样一来,immutable的引用类型和原始类型就看不出区别了。如果先把实现的问题放在一边的话,也可以勉强把整数和实数看作是immutable的引用类型。
不知道上面的解释能否使那些认为“存在两个种类的数据类型有违编程之美的人”满意。不过,在给一个真正的编程新手讲这个问题时,这样的说法还是蛮容易理解的,剩下的问题就应该由我来考虑了。
现在的编程入门书里,基本上都把变量解释为“像是用来放值的盒子”(我曾经也这样写过)。“盒子说”是用来解释原始类型的,如果要说明“一切都是引用”,就不得不引入其他说法了。(也许是“名片说”?)
“盒子说”也不是毫无问题的。(b = a;的时候,a的内容转移到了b里面,那a不是应该变成空的了吗?)对于大多数新手来说,好像很难理解引用的概念。另外,关于“存在两个种类的数据类型有违编程之美”这种说法,新手也不会太在意统一性之类的事情(对编程语言有了一定程度的了解后才会在意)。以我的经验来看,如果是以教会新手编程为目的,与其让他们知道统一性之类的道理,不如用盒子说来得简单。总而言之,试着写代码才是对编程语言的学习最有帮助的。
4.2.3 crowbar栈
让我们继续“表达式计算时的临时引用很难处理”这个话题。
如果你要问在哪儿出现了“表达式计算时的临时引用”,其实crowbar book_ver.0.1里面的eval.c中各函数的局部变量就是。
比如字符串连接时, crb_eval_binary_expression()函数会按照以下顺序执行(具体代码省略)。
CRB_Value left_val;
CRB_Value right_val;
CRB_Value result;
/ 计算左边的值 /
left_val = eval_expression(inter, env, left);
/ 计算右边的值 /
right_val = eval_expression(inter, env, right);
(中间省略)
result.type = CRT_STRING_VALUE;
/ chain_string执行时,GC可能会启动 /
result.u.string_value = chain_string(inter,
left_val.u.string_value,
right_str);
(中间省略)
return result;
像 ["abc" + "def" + "ghi"] 这样的计算表达式,它的分析树如图4-7 所示。因为是从最深层次开始计算, left_val 会暂时持有指向字符串 "abcedf"的引用,然后在调用 chain_string()函数时,由于会申请内存空间,因此也有可能启动GC(关于GC启动的时机,我将在4.3.2节介绍)。此时,虽然会将 left_val指向的对象进行mark(chain_string()会被更深的层级调用),但是从GC的角度,是看不到只作为局部变量的left_val的。
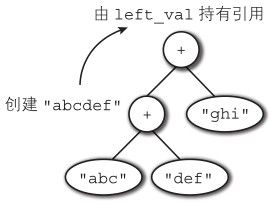
图4-7 字符串连接的分析树
想要解决这个问题倒是有一个办法,就是扫描C的局部变量内存区域(Ruby使用的方法)。C语言的局部变量保存在一般栈中,程序开始运行时(每个CRB_interpret()函数)会记住这些局部变量的地址,如果在调用GC时再取得这些局部变量的地址的话,你会发现它应该与crowbar运行过程中保存的局部变量的地址是一致的(在不优化寄存器分配的情况下)。于是,扫描全部内存区域,如果发现了保存着(或者看上去像是)对象引用的内存区域的话,就把这个区域作为起点标记出来。
只是这个方法有如下缺点,让我不太想用它。
(虽然说移植性相当高,但是)依赖于C语言的处理体系,有违编程之美。
因为不知道是栈中的哪些部分引用的对象,所以不得不采取“把看上去像对象引用的全部当做对象引用来处理”的方法。如果要处理的区域不是引用对象,就会发生内存泄漏。顺便说一句,这种GC叫作conservative GC(保守的GC)。
就内存泄漏而言,我觉得(从Ruby应用的情况来看)在应用上不成问题 [5]。虽说这是C语言,但要让我胡乱地将指针作为地址处理也是万万不能的。
crowbar到底要怎么处理呢?既然C语言的栈这么不好用,那么全部用独立的栈管理不就好了吗?对此,把“表达式运算时的临时引用”放在独立的栈(CRB_Value 数组)中,GC 把这个栈中可以引用到的对象标记起来就可以了。
用 Stack结构体来表示栈。
typedef struct {
int stack_alloc_size;
int stack_pointer;
CRB_Value *stack;
} Stack;
在 CRB_Interpreter 中持有这个结构体(只有 CRB_Interpreter 会持有 Stack 结构体,所以这么做只是为了划分空间)。在这个栈中(以后就称为crowbar栈吧),与是否包含对象的引用无关,它会把表达式运算时产生的所有值都保存起来。
在此之前,所有的eval.c运算函数都将运算的结果值作为返回值,而ver.0.2以后的版本都将由栈返回。因此,之前使用过的 eval_xxx_expression()系列函数的返回值也从 CRB_Value变成 void了。
例如,有如下表达式:
"1+23.." + (1 + 2 3);
会形成如图4-8这样的分析树,表达式运算时栈的变化如图4-9所示。
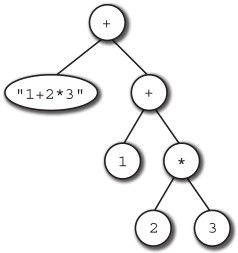
图4-8 表达式的分析树
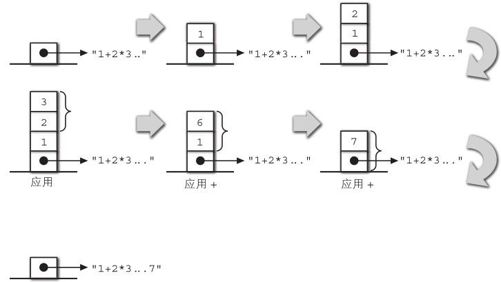
图4-9表达式运算过程中栈的变化
总而言之,就是从栈中获取了 *和 +运算符的操作数,并将运算结果的值留在了栈上。这种做法与JVM栈运行字节码时的栈动作相同。如此一来,我们就向字节码解释器又迈进了一步。
本书的后半部分将介绍字节码解释器型语言的制作方法。
4.2.4 其他根
接下来,将要说明除了“表达式运算时的临时引用”之外的三种根。
1. 全局变量
全局变量可以在 CRB_Interpreter 中以链表的形式追溯,很容易以此为起点进行标记。
2. 局部变量
在 LocalEnvironment结构体中持有局部变量,并作为参数传递。
为了使GC能够全部标记当前生效的局部变量,并且在任何时候都能追踪到这些局部变量,在 LocalEnvironment中增加了成员 next,使之成为链表(因为这个版本的结构体都写在CRBdev.h中,所以加上 CRB作为前缀。请参考4.4.4节)。
struct CRB_LocalEnvironment_tag {
Variable *variable;
GlobalVariableRef *global_variable;
RefInNativeFunc ref_in_native_method;/ 之后会讲到 */
struct CRB_LocalEnvironment_tag next;/ 新增加 */
};
链表的顶端由 CRB_Interpreter 持有。这里的“顶端”指的是最后被调用的函数的 CRB_LocalEnvironment。
struct CRB_Interpreter_tag {
(省略)
CRB_LocalEnvironment *top_environment;
};
值得一提的是,当前的crowbar版本在搜索局部变量的时候,会从最近一次被作为参数传递的 LocalEnvironment开始搜索,顺着 next,按照函数调用的顺序搜索全部 LocalEnvironment。这样一来 [6],就可以引用到函数调用者的变量了。
这样的作用域称为动态作用域(dynamic scope) [7]。说实话,这点确实让人难以理解,所以在最近的语言中已经不流行这种方式了(Emacs Lisp和Perl之类的 local变量都是动态作用域)。
4.2.5 原生函数的形式参数
在调用的时候,没必要特意把crowbar中描述的函数的形式参数保存为局部变量。原生函数的形式参数以数组的形式传递给原生函数,这样一来,即使GC在原生函数执行过程中启动,这些变量也可以被GC追溯到。
原生函数的实际参数存入crowbar栈中,传递给原生函数的只是头地址。crowbar的栈将占用更大的内存地址。因此,从前往后按顺序对参数进行运算,即可将参数数组传递给原生函数。
