6.2 什么是静态的/执行字节码的语言
6.2.1 静态类型的语言
如前所述,Diksam是静态类型的执行字节码的语言。这样的语言有以下优点。
1. 能够高速执行(通常情况下)
理由会在之后详述。对于静态类型的执行字节码的语言来说,如果能够朴素地实现这两个方面的话,会比无类型并通过分析树执行的语言拥有更快的速度。
2. 编译阶段和执行阶段分离
例如在Java中,事先使用javac把源代码生成为class文件,这样在执行时就不需要再编译了。
实际上crowbar由源代码生成分析树的处理并不耗时,(Diksam要想比crowbar强的话)速度上没有什么可期待的。相反,如果想要在不发布源代码的情况下运行程序倒还是有希望的。话虽如此,实际上因为现在的Diksam是在内存上构建字节码并执行的,结果还是必须要发布源代码。
3. 相比之下使用静态类型的语言编写的代码更易读
静态类型的语言通常要将变量和类型一起声明(比如 int a;)。也许会有人觉得这样很麻烦(这就是为什么无类型的LL语言这么有人气的原因),实际上也不是很费事,因为还是把变量类型明确化以提高源代码的可读性更为重要。至少我是这么想的,但这句话是一个泥潭,还是赶快结束这个话题吧。
6.2.2 什么是字节码
字节码是在被称为虚拟机(Virtual Machine)的虚拟CPU上执行的机器语言。机器语言直接通过CPU执行,而字节码通过虚拟机执行。
字节码和机器语言一样,实际上都是数字的序列(这点也和机器语言一样)。为了让大家更好的理解,各个命令将以一种被称为 助记符 (mnemonic)的字符串形式表现出来。
比如在Java虚拟机(JVM)中运行的字节码就是下面这个样子。(再来回看一下代码清单1-4)
0: bipush 10
2: istore_1
3: iload_1
4: bipush 10
6: if_icmpne 20
9: getstatic
12: ldc
14: invokevirtual
17: goto 28
20: getstatic
23: ldc
25: invokevirtual
可能有人会认为,就算是为了让读者能够更好地理解才使用了字符串的表现方式,可这种根本就不知所云的东西如果想要从源代码生成出来,简直就是做梦,更不要说作一个可以生成字节码的编译器了。但实际上并没有那么难,具体步骤请见下节。
6.2.3 将表达式转换为字节码
crowbar从ver.0.2版本开始把计算过程中的值存入栈中(为了确保GC可以追踪指针)。在这种情况下,执行字节码的语言也会进行大致同样的实现。关于此事,4.2.3节的最后部分中有如下记载。
这种做法与JVM堆栈机运行字节码时的栈动作相同。如此一来,我们就向字节码解释器又迈进了一步。
具体来说,分析树优先从最深层次开始遍历,从而生成下面这样的代码。
1. 常量/变量类会直接把值保存到栈中。
- 双目运算符以先左后右的顺序保存到栈上,从栈顶端的两个元素开始计算,并将结果保存到栈中。
比如:
1 + 2 * 3 - 4
这个表达式会展开成图6-1所示的分析树。
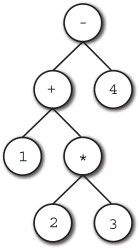
图6-1 分析树
这个分析树以自上而下的顺序遍历,同时,常量的节点会生成字节码 push值,运算符节点生成代表运算符的字节码,生成的字节码如下所示。(下面的代码只是用作说明的模拟代码。这些字节码既不是Java的,也不是Diksam的。)
1: push 1 # 将[1]入栈
2: push 2 # 将[2]入栈
3: push 3 # 将[3]入栈
4: mul # 将栈顶的两个元素进行乘法运算,并将结果入栈。
5: add # 将栈顶的两个元素进行加法运算,并将结果入栈。
6: push 4 # 将[4]入栈
7: sub # 将栈顶的两个元素进行减法运算,并将结果入栈。
此时栈的动作如图6-2所示。
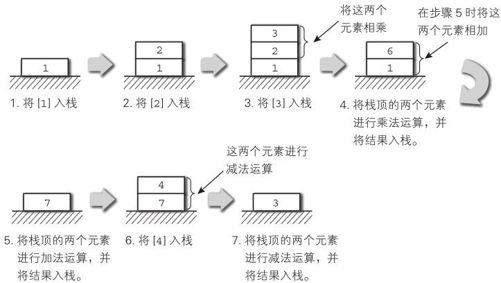
图6-2 执行字节码时的栈动作
在表达式中不止有上例中的双目运算符,还有单目运算符,而且它们的思路是一样的。比如单目运算符的减号,在栈中执行的操作是“将栈顶的值取出,反转符号再存入栈中”。
但是,上述例子中只处理了整数。在实际的编程语言中还必须要处理实数,也有可能会出现“整数和实数相加”这样的混合运算。在这种情况下,必须要将参与运算的整数转换为实数再进行加法运算。在有些语言中,字符串和整数也可以进行加法运算 [3]。接下来的操作就变成了将整数转换为字符串然后再将其连接。
在执行这样的操作时,有两种方法。
第一种是在向栈中保存值的时候就加入能够区分类型的标识,在运行时再进行判断。crowbar使用的就是这个方法。 CRB_Value结构体的成员 type保存的就是类型的标识,在运行时根据这个标识进行转型和运算。
另外一种方法是,在编译时进行类型判断。
如果有必要转型的话,类型转换处理将在编译时进行。那么,像图6-3这样一个分析树就能够实现类型的转换了。
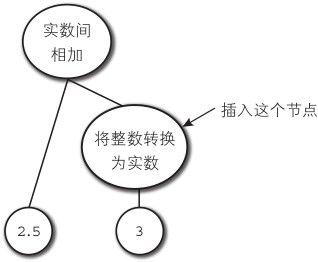
图6-3 类型转换的分析树
这个分析树生成的字节码如下。
1: push_double 2.5
2: push_int 3
3: cast_int_to_double
4: add_double
第三行的 cast_int_to_double命令将栈顶的 int值转换为 double。
在这种方法中,如果是加法运算,究竟要如何区分是整数之间相加,还是实数之间相加或者是字符串连接呢?在编译完成之后就完全清楚了。因此,在执行时无需加入多余的判断,也可以加快执行速度。
但是这样一来,在编译时就必须要知道变量的类型,因此必须要让用户进行带变量类型的 声明 [4]。
6.2.4 将控制结构转换为字节码
像 if和 while之类的控制结构,在字节码中使用 goto这样的跳转(jump)命令实现。
比如下面这段 if语句。
if (a == 10) {
条件成立时的处理
条件成立时的处理
}
后续的处理
将这段代码用字节码来表示。
1: push变量a的值
2: push_int 10
3: eq_int # 栈顶的两个int之间进行比较(==),并将结果入栈
4: jump_if_false 7 # 栈顶的值如果是false就跳转到第7行
5: 条件成立时的处理
6: 条件成立时的处理
7: 后续的处理 # 从第4行跳转到本行
在crowbar中,控制结构也是用分析树来表现的。程序在执行的同时对分析树进行递归,为了实现 break 和 continue 这样的语句,程序必须要从递归的最深层开始(使用特殊的返回值)。在执行字节码的语言中可以更简单地实现 break 和 continue,(如果必要的话) goto 也可以简单地实现(递归)。
6.2.5 函数的实现
在C等语言中,通常情况下函数的调用也是用栈来实现的。
这种情况在拙著《征服C指针》中有详细的介绍,请各位读者参考。其中大致说明了在C的情况下,(简单实现的话)函数的调用遵循以下步骤(如图6-4)。
1. 将参数(从后面开始)入栈
2. 将返回地址等返回信息入栈
3. 将局部变量所占内存区域入栈
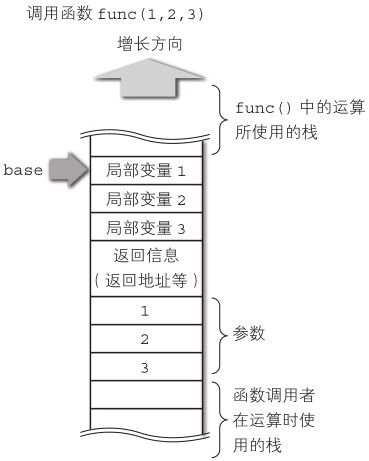
图6-4 语言中的函数调用
C语言的参数从后面开始入栈是为了实现像 printf()这样可变长参数的函数。这次制作的Diksam语言中没有可变长参数,因此没有必要特意从后面开始(向栈内)保存参数(实际上Diksam是从前面开始保存参数的)。
所谓返回地址,和字面意思一样,指向了函数终结时返回的地址。当函数从(栈的)某处开始调用之后,如果不将返回地址保存到栈中,在函数结束时就不知道要返回到哪里去了。
当所有局部变量保存到栈中的时候,栈的顶部就在图中 base箭头所指的位置。利用以 base为基准的偏移量,可以指定局部变量或者参数 [5]。
在之前的 if语句字节码的例子中,如果把中文“ push变量 a的值”写成字节码的话,应该像下面这样(当 a是局部变量的情况下)。
push_statck_int 0 # 0是变量a基于base的偏移量
在需要声明变量的语言中,全局变量也要在编译时全部决定下来,因此不能为这些全局变量指定偏移量的编号。比如 int型的全局变量的值向栈中保存的字节码应该是下面这样。
push_static_int 0 # 0是这个全局变量的索引
