4.4 其他修改
接下来要介绍的是crowbar ver.0.2中除了GC之外的其他修改的地方。
4.4.1 修改语法
对语法作了如下修改。
数组——表达式之后可以加 [表达式]。
函数调用——表达式后面可以加函数名(参数列表)。
自增/自减——表达式后面可以加 ++或 —。
增加了很多可以追加在表达式后面的语法。在语法结构上引入了非终结符 postfix_expression(这个名字是从K&R [2] 的附录C中得来的)。
unary_expression
: postfix_expression
| SUB unary_expression
;
postfix_expression
: primary_expression
/ 引用数组元素 LB,RB是“[”和“]” /
| postfix_expression LB expression RB
/ 调用函数 /
| postfix_expression DOT IDENTIFIER LP argument_list RP
| postfix_expression DOT IDENTIFIER LP RP
/ 自增,自减 /
| postfix_expression INCREMENT
| postfix_expression DECREMENT
;
句柄LB 和RB 是Left.Bracket 和Right.Bracket 的简写,分别代表“ [”和“ ]”。
根据这个语法结构创建的结构体如下所示(crowbar.h)。因为都是表达式,所以都加入到了 Expression结构体的共用体中。
/ 引用数组元素 /
typedef struct {
Expression *array;
Expression *index;
} IndexExpression;
/ 自增/自减 /
typedef struct {
Expression *operand;
} IncrementOrDecrement;
/ 调用函数 /
typedef struct {
Expression *expression;
char *identifier;
ArgumentList *argument;
} MethodCallExpression;
4.4.2 函数的模拟
crowbar ver.0.2的数组配备了下面这些“像函数一样的函数”。
给数组增加元素
a.add(3);
取得数组的大小
size = a.size();
改变数组的大小
a.resize(10);
另外,(顺便)也给字符串添加了函数。
取得字符串的长度
len = "abc".length();
之所以说起函数的“模拟”,是因为现在在crowbar中还没有为类型(或者对象)分配函数的通用方法。book_ver.0.2的实现虽说属于偷工减料,但也算是用了嵌入代码的方式,处理得还不错。(截取自eval.c,见代码请单4-6。)
代码清单4-6 eval_method_call_expression()
static void
eval_method_call_expression(CRB_Interpreter inter, CRB_LocalEnvironment env,
Expression *expr)
{
CRB_Value *left;
CRB_Value result;
CRB_Boolean error_flag = CRB_FALSE;
eval_expression(inter, env, expr->u.method_call_expression.expression);
left = peek_stack(inter, 0);
if (left->type == CRB_ARRAY_VALUE) {
if (!strcmp(expr->u.method_call_expression.identifier, "add")) {
CRB_Value *add;
check_method_argument_count(expr->line_number,
expr->u.method_call_expression
.argument, 1);
eval_expression(inter, env,
expr->u.method_call_expression.argument
->expression);
add = peek_stack(inter, 0);
crb_array_add(inter, left->u.object, *add);
pop_value(inter);
result.type = CRB_NULL_VALUE;
} else if (!strcmp(expr->u.method_call_expression.identifier,
"size")) {
check_method_argument_count(expr->line_number,
expr->u.method_call_expression
.argument, 0);
result.type = CRB_INT_VALUE;
result.u.int_value = left->u.object->u.array.size;
} else if (!strcmp(expr->u.method_call_expression.identifier,
"resize")) {
CRB_Value new_size;
check_method_argument_count(expr->line_number,
expr->u.method_call_expression
.argument, 1);
eval_expression(inter, env,
expr->u.method_call_expression.argument
->expression);
new_size = pop_value(inter);
if (new_size.type != CRB_INT_VALUE) {
crb_runtime_error(expr->line_number,
ARRAY_RESIZE_ARGUMENT_ERR,
MESSAGE_ARGUMENT_END);
}
crb_array_resize(inter, left->u.object, new_size.u.int_value);
result.type = CRB_NULL_VALUE;
} else {
error_flag = CRB_TRUE;
}
} else if (left->type == CRB_STRING_VALUE) {
if (!strcmp(expr->u.method_call_expression.identifier, "length")) {
check_method_argument_count(expr->line_number,
expr->u.method_call_expression
.argument, 0);
result.type = CRB_INT_VALUE;
result.u.int_value = strlen(left->u.object->u.string.string);
} else {
error_flag = CRB_TRUE;
}
} else {
error_flag = CRB_TRUE;
}
if(error_flag) {
crb_runtime_error(expr->line_number, NO_SUCH_METHOD_ERR,
STRING_MESSAGE_ARGUMENT, "method_name",
expr->u,method_call_expression.identifier,
MESSAGE_ARGUMENT_END);
}
pop_value(inter);
push_value(inter, &result);
}
说点题外话,最初在获取数组元素数的时候使用的是 get_size(),作为一个getter函数,为了统一性着想,名字理所当然是 get_xxx()。但是,考虑到这个函数使用频繁,并且经常要放在 for语句中使用,函数的名字如果太长使用起来不太方便,因此还是取名为 size()了。
我常常在想,虽然统一性很重要,但是方便性一样重要。不论是制作语言还是程序库,要想兼顾这两个方面还真是不容易。
不过,取得数组大小为什么不是只用 length就可以了,而要用函数呢?取字符串长度时用的是 length(),而 Vector和 ArrayList这样取大小的为什么用的是 size()呢?我想这只是为了兼容之前的内容而产生的不统一。
4.4.3 左值的处理
在一般的表达式中,一个变量表示该变量储存的值。比如,将5 赋值给 a,当表达式中的 a 替换为5 时表达式的结果保持不变。但是,变量在赋值的左边时,此时将
a = 10;
变为
5 = 10;
是行不通的。总之,变量在赋值语句的左边时,变量代表的不是它所储存的值,而是储存值的地方(即变量的内存地址),我们称其为左值(left value)。
book_ver.0.1中,赋值语句的左边只能放变量。赋值语句的语法规则如下所示:
expression
: IDENTIFIER ASSIGN expression
;
但是在引入了数组之后,赋值语句的左边就可以写稍微复杂一点的表达式了。
给二维数组a赋值,其中一个下标为以b[i]为参数
调用函数func()后的返回值
a[i][func(b[i])] = 5;
当然,使用老的语法结构不能对应这种情况,于是,我们将语法结构改写成下面这样。
expression
: postfix_expression ASSIGN expression
;
左边变成了 postfix_expression,而现在能成为赋值语句的对象的,只有 primary_expression(变量名)和 postfix_expression(数组元素)了。
接着,在eval.c 中首先计算右边的值,然后调用 get_lvalue() 函数取得左边表达式的地址,详见代码清单4-7。并且,这里调用的 peek_stack() 函数会在不清除栈的情况下获取值,这样一来右边的值会作为赋值表达式整体的值残留在栈中,也是件好事。
代码清单4-7 eval_assign_expression
static void
eval_assign_expression(CRB_Interpreter inter, CRB_LocalEnvironment env,
Expression left, Expression expression)
{
CRB_Value *src;
CRB_Value *dest;
/ 首先计算右边值 /
eval_expression(inter, env, expression);
src = peek_stack(inter, 0);
/ 取得左边的地址 /
dest = get_lvalue(inter, env, left);
dest = src;
}
那么, eval_assign_expression()中调用的函数 get_lvalue()又是什么样子呢?请见代码清单4-8。将标识符和数组分开进行处理,如果是数组的话,可以利用 get_array_element_lvalue()(见代码清单4-9)函数返回数组元素对应的地址。
代码清单4-8 get_lvalue()
CRB_Value *
get_lvalue(CRB_Interpreter inter, CRB_LocalEnvironment env,
Expression *expr)
{
CRB_Value *dest;
if (expr->type == IDENTIFIER_EXPRESSION) {
dest = get_identifier_lvalue(inter, env, expr->u.identifier);
} else if (expr->type == INDEX_EXPRESSION) {
dest = get_array_element_lvalue(inter, env, expr);
} else {
crb_runtime_error(expr->line_number, NOT_LVALUE_ERR,
MESSAGE_ARGUMENT_END);
}
return dest;
}
代码清单4-9 get_array_element_lvalue()
{
CRB_Value array;
CRB_Value index;
/ 运算[]左边的表达式 /
eval_expression(inter, env, expr->u.index_expression.array);
/ 运算[]中的表达式 /
eval_expression(inter, env, expr->u.index_expression.index);
/ 取得两个变量的值 /
index = pop_value(inter);
array = pop_value(inter);
/ 检查数据类型 /
if (array.type != CRB_ARRAY_VALUE) {
crb_runtime_error(expr->line_number, INDEX_OPERAND_NOT_ARRAY_ERR,
MESSAGE_ARGUMENT_END);
}
if (index.type != CRB_INT_VALUE) {
crb_runtime_error(expr->line_number, INDEX_OPERAND_NOT_INT_ERR,
MESSAGE_ARGUMENT_END);
}
/ 检查下标范围 /
if (index.u.int_value < 0
|| index.u.int_value >= array.u.objext->u.array.size) {
crb_runtime_error(expr->line_number, ARRAY_INDEX_OUT_OF_BOUNDS_ERR,
INT_MESSAGE_ARGUMENT,
"size", array.u.object->u.array.size,
INT_MESSAGE_ARGUMENT, “index”, index.u.int_value,
MESSAGE_ARGUMENT_END);
}
/ 返回地址 /
return &array.u.object->u.array.array[index.u.int_value];
}
另外,在没有左值的情况下,取得数组元素值的引用时调用的函数 eval_index_expression(),它的内部也使用了 get_array_element_lvalue()。
static void
eval_index_expression(CRB_Interpreter *inter,
CRB_LocalEnvironment env, Expression expr)
{
CRB_Value *left;
left = get_array_element_lvalue(inter, env, expr);
push_value(inter, left);
}
自增/自减运算符也同样适用于 get_lvalue()取得目标变量的地址。
4.4.4 创建数组和原生函数的书写方法
前面已经说过,用原生函数 new_array()可以创建常量数组 {1, 2, 3}。该原生函数的定义请见代码清单4-10。
代码清单4-10 new_array()
/ 递归调用子例程 /
CRB_Value
new_array_sub(CRB_Interpreter inter, CRB_LocalEnvironment env,
int arg_count, CRB_Value *args, int arg_idx)
{
CRB_Value ret;
int size;
int i;
if(args[arg_idx]. type != CRB_INT_VALUE) {
crg_runtime_error(0, NEW_ARRAY_ARGUMENT_TYPE_ERR,
MESSAGE_ARGUMENT_END);
}
size = args[arg_idx]. u.int_value;
ret.type = CRB_ARRAY_VALUE;
ret.u.object = CRB_create_array(inter, env, size);
if (arg_idx == arg_count-1) {
for (i = 0; i < size; i++) {
ret.u.object->u.array.array[i]. type = CRB_NULL_VALUE;
}
} else {
for (i = 0; i < size; i++) {
ret.u.object->u.array.array[i]
= new_array_sub(inter, env, arg_count, args, arg_idx+1);
}
}
return ret;
}
/ 原生函数本体 /
CRB_Value
crb_nv_new_array_proc(CRB_Interpreter *interpreter,
CRB_LocalEnvironment *env,
int arg_count, CRB_Value *args)
{
CRB_Value value;
if (arg_count < 1) {
crb_runtime_error(0, ARGUMENT_TOO_FEW_ERR,
MESSAGE_ARGUMENT_END);
}
value = new_array_sub(interpreter, env, arg_count, args, 0);
return value;
}
首先,这次修改在原生函数的参数中增加了 CRB_LocalEnvironment。
上面代码中的处理只是递归地创建了数组的数组,数组所需内存空间的开辟工作由 CRB_create_array() 完成。另外,为原生函数增加了形式参数,从而使 CRB_LocalEnvironment 可以作为参数传递进去。那么, CRB_LocalEnvironment用途是什么呢?在创建多维数组的时候,会多次调用 new_array_sub()开辟内存空间。如果GC在进行上述操作的中途启动的话,就可能会立刻将刚分配好的数组释放掉。因此,为了把在函数中创建的对象标记为不回收的目标,我们需要把 CRB_LocalEnvironment传递到函数中。
具体来说, CRB_LocalEnvironment的成员 ref_in_native_method中保存了在原生函数中创建的对象(具体请参考4.2.4节的定义)。
类型 RefInNativeFunc 的定义如下,它以链表的形式保存着指向对象的数组。
typedef struct RefInNativeFunc_tag {
CRB_Object *object;
struct RefInNativeFunc_tag *next;
} RefInNativeFunc;
这种设计的问题在于,创建于原生函数内部的对象在函数结束前不能被释放。如果在原生函数中存在大量多次循环时,就会出现很多对象在创建后立即被丢弃的现象。有些对象在函数结束前不能被释放,由此造成了内存空间的浪费。但是,如果只是在原生函数内部使用的对象,那么比起使用麻烦的crowbar对象,使用C的 malloc()更为方便。因此,实际情况下像上面那样的问题并不多见,所以还是维持了这样的设计。
4.4.5 原生指针类型的修改
crowbar book_ver.0.1的原生指针类型的值(CRB_Value结构体)中包含了 void*的指针和数据类型的标识信息。在3.3.9节中提到过,这个方法在“一个地方用fclose()关闭了文件指针,可能还会在另一个地方被使用”的情况下会存在问题。
在book_ver.0.2中,原生指针类型的值不再指向实际的原生对象(FILE结构体等),而是在中间加入了一个crowbar对象进行“隔离”(如图4-12)。
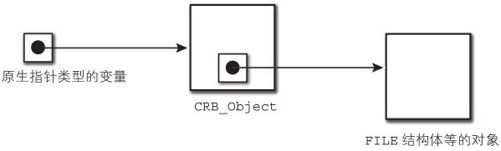
图4-12 原生指针的构造(修改版)
运用上面的方法,例如在调用 fclose()的时候,将 CRB_Object中指向原生对象的指针同时置为 NULL,就能够立刻判断出文件已被关闭。也许有人会想,在以前的做法中,没有将 CRB_Value直接指向 FILE结构体,而是在它们中间夹了一个别的结构体,不是也起到同样的作用了吗?假设真的这么做了,那么在对这个结构体进行 free()的时机就又成了一个问题。何不借着实现GC的机会,让它们中间夹一个可以作为GC目标的对象呢?
顺便说一下,虽然这样一来就可以实现针对原生指针类型的 终结器 (finalizer)了(GC在释放原生指针类型的对象时调用之前注册的函数就可以了),但是由于mark-sweep型的GC中终结器“不知何时启动”,因此使用crowbar的用户最好不要编写依赖于终结器的程序。但是对于一门编程语言来说,提供终结器也不是什么坏事。
注 释
[1]. 不考虑crowbar的MEM实际会占用更大的管理空间。
[2]. C语言中只有“数组的数组”,数组也不属于引用类型,在这里道理是一样的。
[3]. 现在的crowbar并没有在编译时处理多个字符串常量的加法运算(虽然可以这么做),所以在这个例子中,使用字符串常量进行加法运算的效果与使用字符串变量相同,这里并不是为了说明变量和常量的差异。
[4]. 也不知道Java这样的设计方便性在哪里?可能是会提升 intern()的效率吧。
[7]. 关于动态作用域的策略,“对一个名字x的使用指向的是最近被调用但还没有终止且声明了x的过程中的这个声明”。(摘自“龙书”[1]P19)——译者注
