3.2 预先准备
crowbar的语法处理器有一定的行数规模(最终版有8000行左右),因此应当预先约定编码规范,并准备好底层的库。
那么让我们暂时离开语法处理器,先准备下面这些事项吧。
3.2.1 模块与命名规则
crowbar由以下3个模块构成:
crowbar主程序(CRB)
内存管理模块(MEM)
Debug模块(DBG)
括号中的CRB、MEM等是模块名。
这里我所指的模块,即可以完成某些特定功能的程序块。一个模块中基本都会包含多个.c文件。
MEM与DBG均为通用模块,并不是crowbar专用的。代码分别位于crowbar文件夹下的memory、debug子文件夹中。
C语言中没有C++和C#的命名空间,也没有Java中的包机制,因此必须制定命名规范来避免可能出现的命名冲突。因此我们使用以下的命名规范。
模块必须有前缀3个字母的缩写(如: CRB)。
类型名,以大写字母开始,并使用大写字母连接单词(如: CRB_Interpreter)。
变量名/函数名,全部使用小写字母,使用下划线连接单词(如: alloc_expression())。
宏命名为全大写字母,使用下划线连接单词(如:IDENTIFIER_TABLE_ALLOC_SIZE)。但如果是带参数的宏,特别是具有函数功能的部分,则要遵循函数的命名规则(如: small(a, b))。
模块中向外公开的函数,命名以模块名(大写字母) + 下划线作为前缀(如: CRB_create_interpreter())。
模块中不对外公开的函数,如果函数的作用域跨文件时,则函数名以模块名(小写字母) + 下划线作为前缀(如: crb_alloc_expression())。
函数外的静态变量名以 st_作为前缀(如: st_string_literal_buffer)。
各模块中向外部公开的接口需要做成 公有头文件 的形式,在头文件中定义了公开函数以及调用模块所需的类型。比如crowbar中,想使用crowbar解释器就需要包含CRB.h,而编写crowbar的内置函数则需要包含CRB_dev.h。
各模块内部使用的类型、宏、函数等,则可以声明为 私有头文件 。比如在crowbar中,crowbar.h就是一个私有头文件,其中声明的类型名或宏无需附加 CRB前缀(因为外部是接触不到的)。但是函数与全局变量,为了以防万一还是需要加上 crb前缀的。
2.3.1节后的补充知识中曾写道,所有的头文件应当尽量只用一个 #include(前提是已经加入了防止多重定义的处理)。因此大多数情况下,私有头文件内部可以用 #include包含公有头文件,反之则不行。内部文件中使用公共信息,而外部文件中则不能含有私有信息,这应该不难理解。
经过上述的处理,各模块的内部细节都可以对其他模块实现隐藏(即面向对象中常提到的封装概念)。此外,在C语言中,头文件修改后包含该头文件的源代码都需要重新编译。将头文件划分为公有及私有,只要保证公有头文件不修改,那么用户利用公有头文件编写的程序也就无需重新编译了。
crowbar的模块与目录结构如图3-2所示。
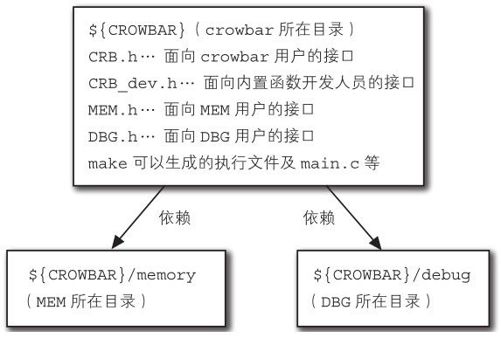
图3-2 crowbar的模块与目录结构
3.2.2 内存管理模块MEM
经常使用C的程序员应该深有体会,用C语言编程时,难免会遇到诸如内存损坏(memory corruption)BUG、忘记释放内存引起内存泄漏、引用的内存区域被释放让BUG难以重现等问题,总之围绕内存经常会发生很多让人讨厌的BUG。
而由于crowbar还设置有字符串型的变量,可以用 +运算符连接字符串,因此我们必须配置某种垃圾回收机制。比如:
a = "a" + "b" + "c"
这个语句运行的时候,首先执行 "a" + "b"语句生成字符串 "ab",然后为了继续生成 "abc", "ab"的内存空间必须自动释放。具体的运行过程请参考3.3.11节。正是由于运行时需要运行很多这样繁复的处理,很容易出现BUG,所以需要有一种方法来确认内存中到底发生了什么。
基于上述理由,我制作了一个具备下列功能的内存管理模块。模块名为MEM,按之前的命名规范,所有的公共函数都以 MEM_为前缀。
通过 MEM_malloc()可以分配内存空间,内存空间开始处默认填充有 0xCC。常规的 malloc()函数开辟的内存空间值为0的情况很多,因此很容易遗漏初始化过程。而 0xCC毫无疑问是个无意义的值,这样就可以确保能够检查出被遗漏的初始化过程。
MEM_realloc()用于扩充内存空间时,也会默认填充 0xCC。
开辟的内存空间用 MEM_free()释放时,被填充的 0xCC也会被释放。由此可以较早地发现由于引用被释放的内存空间而引起的BUG。
MEM模块会以链表形式保存所有开辟的内存空间,可以使用 MEM_dump_block()将其转储。转储后可以将 MEM_malloc调用位置的源文件名及行号显示出来。
用 malloc()开辟的内存空间,在不用的时候一定要用 free()释放,这是我们在编程时一定要遵守的一个准则。那么如果在程序结束时调用 MEM_dump_block()仍然看到有结果输出的话,就可以断定某处发生了内存泄漏。
- MEM_malloc()开辟的内存空间在传递给程序使用时,空间前后会加上 0xCD的记号,检查这些记号就可以知道由于数组越界等问题引起的内存损坏程度了。
这个检查还需要配合使用 MEM_check_block()、 MEM_check_all_blocks()等函数。
内存管理模块MEM会以图3-3的形式管理内存。
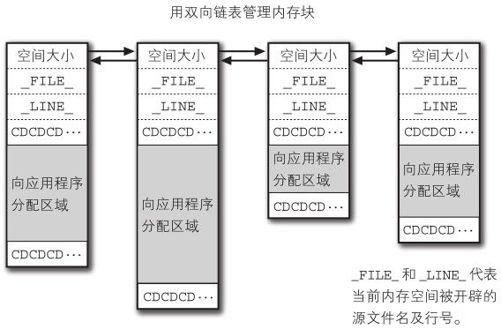
图3-3 通过MEM管理内存
很简单的模块,功能虽然简单,但对于BUG的检查非常有用。
对于动态开辟的内存空间,经常会先开辟若干个小型的区域,然后将这些区域一起释放。分析树的节点就是典型的例子。开辟空间会一点一点地进行,释放则是一次性的。对此,MEM模块引入了存储器(storage),作为开辟内存的常规工具。
由 MEM_open_storage()生成一个新的存储器。
MEM_storage_malloc()可以接受存储器和空间的大小作为入口参数,并返回所请求大小的内存空间。
由 MEM_dispose_storage()将存储器内所有的内存空间全部释放。
MEM_storage_malloc() 会将 MEM_open_storage() 开辟的较大内存空间,从起始处按照请求的尺寸一次性全部返回。因此无法对其中的子空间单独释放,也不能通过 realloc()扩展空间。
补充知识 valgrind
我们手动实现了模块MEM,它可以检查由于C语言操作内存而引起的BUG,其实也有很多其他工具具备同样的功能。
以前这类工具大都是需要付费的,不过在Linux环境下,可以使用免费软件valgrind(许可证为GPL)。
通常我们使用下面的方式启动程序(%是命令行提示符)。
% crowbar test.crb
而执行如下指令的话,
% valgrind crowbar test.crb
可以帮助我们检查是否忘记释放内存(或内存泄漏),以及是否在程序开辟的内存空间外部进行了写入。
可能有读者会问,有这么方便的工具为什么还要制作MEM模块呢?实际上,我在写MEM模块时完全不知道有valgrind这个工具,算是重复发明轮子了。不过自己实现一个这样的工具也是有好处的吧。
valgrind的详细内容,请参考官方主页http://valgrind.org/。
补充知识 富翁式编程
MEM模块中,在应用程序所使用的内存空间前后分别加上了管理专用空间。比如开发环境中 int型或者指针一般占用4字节,double型一般占用8字节,而其管理空间前面占用24字节,后面则有8字节(包含校验信息)。
那么如果生成很多对象时,肯定会浪费很多内存空间。
然而对于现在的电脑来说,这种程度的浪费简直是微不足道的。与其冥思苦想节省内存空间或提高处理速度的小技巧,倒不如专注于如何提高开发效率。这种编程方式就叫作 富翁式编程 [4]。
crowbar 的实现就非常之“富翁”。比如用 crowbar 书写的程序中会出现 hoge_piyo_foo_bar这样一个变量。对于现代编程语言来说,这样长的变量名或函数名是很常见的。在程序中, hoge_piyo_foo_bar 变量名可能还会出现若干次,crowbar的解释器将会预先对所有出现的变量名分配好空间,当然这都是要消耗内存的,最终只需要用 strcmp()简单地对当前变量名做一致性检查就可以了。另外,在检索变量或函数时,都采用线性检索。
这样设计当然可能会出现运行速度慢的情况,即便如此,等到状况发生时再想办法优化也不迟。在前期优先考虑的应该是如何让程序更加容易编写、理解起来更加简单。
补充知识 符号表与扣留操作
刚刚提到过,无论是内存空间还是处理速度,crowbar的内部实现都是比较“富翁式”的。那么如果在此基础上想要进一步提高运行效率的话要怎样做呢?
正如上文所述,crowbar对于程序中多次出现的变量名等,会分别开辟空间将其保存。如果变量名较长时比较浪费,因此将同名变量整合为一处保存,不失为一个提高效率的方法。
具体来说,程序中会存在一个函数,为所有出现的特征符建立数据结构,新出现的特征符如果已经被记录则会返回其指针,如果尚未记录则会新录入并返回指针。这样的操作称为 扣留 (intern)。对一个标识符进行扣留操作时,无需判别该标识符是局部变量还是全局变量,或是函数名(当然进行判别也无妨)。
对程序中出现的所有的标识符一一进行扣留操作的话,在判断两个标识符是否为同一个时,只需要比较它们的指针就可以了。这比用 strcmp()更快。
而crowbar对于局部变量、全局变量和函数则分别使用链表进行管理。一旦语句中出现变量名时,将从链表头部开始检索(采用线性检索)。如果要优化这个部分,可以考虑引入缓存、树或二分法查找等。刚才提到的这些数据结构及算法,都是编程语言语法处理器普遍使用的,读者可以自行查阅相关图书或网站。
一般来说,我们将编译器保存变量名、函数名的数据结构称为“符号表”。
3.2.3 调试模块DBG
DBG是调试时使用的模块,具备若干功能,在crowbar的代码中使用的话,只需要调用宏 DBG_assert()及 DBG_panic()即可。
/ 断言这里a的值应该为5 /
DBG_assert(a == 5, (“a..%d”, a));
这样书写的话,当 a == 5 这一条件不成立时,程序会将该处的源代码行号输出并执行 abort()。第二个入口参数则是将想要输出的东西传递给 printf()并格式化(因为宏无法使用可变长度的参数,因此需要从第二参数起全部用括号括起来)。
DBG 的输出目标可以通过 DBG_set_debug_write_fp() 函数进行更改,标准输出目标是 stderr。而输出目标无论如何更改, stderr仍然会保留一份同样的信息。因此如果不做任何更改的话,会看到 stderr输出的是两行同样的信息。
DBG_panic()函数可以书写在一些程序不应该进入的分支处。典型的例子就是 switch case的 default分支,如:
/* 变量operator通过switch case判断分支条件
default分支在正常情况下不应当进入 */
default:
DBG_panic((“bad case…%d”, operator));
与 DBG_assert()一样,用两层括号包裹,最终会通过 printf()格式化输出。
DBG_assert()与 DBG_panic()都是宏,只要在定义 #define DBG_NO_DEBUG的状态下编译,就可以完全删除执行文件中的调试部分。
