8.1 分割源文件
本章的标题是“将类引入Diksam”,在现在的Diksam中源代码不能分散地写在多个文件中。即使在编程语言中引入了类的概念,如果必须把所有代码都写在一个源文件中,那么这个语言又能有多大用处呢?
因此,首先要实现对源文件的分割。
8.1.1 包和分割源代码
分割源代码的方法,最简单的就是和C 语言里面的 #include 一样,嵌入来自于其他源文件的代码。这个方法既简单又直接,非常实用。
但是,使用这个方法嵌入多个库文件时,函数名、变量名等很可能发生冲突。因此,在分割源代码的同时,加入相当于Java的包或者C++和C#的命名空间的功能。
Diksam的包的设计方式如下所示。
1. require
一些源文件如果需要其他源文件提供的功能时,应在该源文件的开头加入如下代码。
require hoge;
在这个例子中,编译器会在编译时搜索文件名为hoge.dkh的文件。和Java的 import一样, require也只能写在代码的开头。另外, require读取的文件必须以.dkh为后缀,它是与C语言的头文件相似的文件。
搜索源文件的目录配置在环境变量 DKM_REQUIRE_SEARCH_PATH中,多个搜索目录之间在UNIX中用冒号、在Windows中用分号分割。如果没有配置这个环境变量的话,将在当前目录(.)中进行搜索。这里的设计方式基本上和Java的 CLASSPATH相同。
被 require的文件有可能还要 require其他文件,这时不会对同一个文件进行重复读取。
2. 动态加载
对于 require的文件来说,虽然也可以把必要的函数的源代码全都写在里面,但是函数只要像下面这样进行 签名声明 也可以编译通过。
int print(string str);
如果是像 print()这样的原生函数,签名声明后就可以直接使用了。
如果不是原生函数的话,只有在函数 被调用的时候 才会加载对应的源代码。这种方式称为 动态加载 (dynamic load)。因为程序中总有些功能是不常用的,使用了动态加载后相信能够实现高速化启动。
如果在hoge.dkh中进行了签名声明,那么在函数被调用的时候会对hoge.dkm进行搜索。在创建库文件时,.dkm实现了.dkh中定义的设计。
动态加载时搜索的目录并不配置在环境变量 DKM_REQUIRE_SEARCH_PATH中,而是从 DKM_LOAD_SEARCH_PATH中获取。在这里,特意使用两个不同的物理路径来区分库文件的设计和实现。另外,也可以使用“在测试过程中将实现文件作为存根”的方法。
实际上,.dkh文件作为设计公开的大小与其实现(.dkm文件)后的大小相差悬殊,.dkh和.dkm的对应关系应该是1∶n的样子,但是这样一来,在动态加载时就需要另外指定搜索源代码的方法了,因此这里先让它们保持1∶1的状态。我认为动态加载是能够使用Diksam编写大程序的一个先决条件。
3. 包
在Diksam中,一个源文件就对应着一个包(在.dkh和.dkm分开编写的情况下,它们两个的代码要在一个包中)。
像Java那样在每个源文件的开头都要逐个对包进行声明是非常麻烦的,通常情况下,Java的目录层级和包的层级一致,也就是把同样的信息体现在了两个地方。这样一来,在修改时就会出现问题(尤其是Java的包名,使用起来像是互联网的域名)。既然如此,单纯地使用源文件名和包名的组合可能更简单。
Diksam的包名使用点(.)进行分割,根据包名就可以简单地分清层级。
require hoge.piyo.foo.bar;
上面这段代码,会以 DKM_LOAD_SEARCH_PATH 中设置的目录为起点,以包名的最后一个名字之外的部分(即上述例子中的“hoge/piyo/foo”)为目录进行搜索。总之和Java一样,Diksam的包层级也要和目录层级一致。
另外,在C++或者C#中,一个源文件可以对应多个 namespace,但是一般情况下都不会这么做。我觉得在这种事情上节省没有任何意义。相反,一个包可能希望由多个源文件构成。我想就像前面说到的,这是能够使用Diksam编写大程序的一个先决条件,也正因如此,我们才需要用最简单的办法来解决眼前实现和使用上的问题。
另外,像 print() 这样标准的程序库被收录在了 diksam.lang 中。在这次要制作的Diksam的版本(Diksam book_ver.0.3)中,使用者必须要手动进行 require。
4. rename
在进行 require时,如果引入了多个包中的同名函数时会发生命名冲突。
在Java中,可以通过指定全限定类名(FQCN,Fully Qualified Class Name)避免这个冲突(如java.util.List和java.awt.List)。但是,这样编写代码时会很麻烦,而且编写出来的代码也会显得杂乱无章。
因此,在Diksam中没有指定FQCN的方法。解决冲突的方法是利用 rename进行如下操作。
rename com.kmaebashi.util.print myprint;
上面这段代码将 com.kmaebashi.util包的 print函数改名为 myprint。
rename 必须写在源代码的开头和 require 之后。还有, rename 的有效范围仅在当前源文件中,即使在被 require的文件中使用了 rename,也不会影响到进行 require的文件。这是因为,被改名后的名字只在当前源文件内可见,这样做的目的是为了可以让每个源文件都能识别出函数的真正身份。
5. 开始执行
在现在的Diksam中,如果执行下面这段代码,程序将从hoge.dkm的顶层结构开始执行。
% diksam hoge.dkm
即使引入了 require,这个设计仍然没有改变。总之,程序总是会从指定源代码的顶层结构开始执行。一旦程序开始执行,就可以调用被 require的源代码中的函数了。即使被 require的文件有顶层结构,也是不会执行的。
可以把Diksam的顶层结构看作是Java中的 main()方法。 main()方法在程序库中大多是充当测试驱动的角色吧 [1]。
6. 关于全局变量
在Diksam中,全局变量是在函数外(顶层结构中)声明的变量,但是其他源文件是引用不到这个全局变量的。也就是说,如果只有在多个源文件中能够被任意引用的变量才可以称为全局变量的话,那么Diksam中就不存在全局变量。
但是,多个源文件之间可以进行函数调用,因此使用 get_xxx()、 set_xxx()也是可以访问全局变量的。一般来说,应该尽可能不使用全局变量,因此我认为这种方式再适合不过了。
补充知识 #include、文件名、行号
虽然和本节的主题无关,但这里还是要提一下,在8.1.1节的开头写道:
分割源代码的方法,最简单的就是和C语言里面的#include一样,嵌入来自于其他源文件的代码。这个方法既简单又直接,非常实用。
这个方法非常实用,那么这个方法就是个好方法吗?你可能会认为,像C语言的预处理那样,如果事先进行了处理,编译器就无需在执行时再进行校正了。实际却不是这样的。值得注意的一点就是,必须要通过某种方法知道被 require的文件的文件名和行号。
使用 #include将其他文件嵌入进来的话,行号自然会发生变化。在出现报错信息的时候,将变化后的行号输出给使用者的行为是很不友好的(JSP,即Java ServerPages,它就是这样,会将自动生成的Java代码的行号直接输出)。
例如,C语言的预处理会通过下面的形式,将行号和文件名传递给预处理后的文件 [2]。
line 2 "hello.c"
8.1.2 DVM_ExecutableList
一个Diksam编译器和一个源文件会生成出一个 DVM_Executable。在之后可能会对一个源文件进行分割,因此编译后也可能生成多个 DVM_Executable。
为了管理这些 DVM_Executable,我们引入了 DVM_ExecutableList 结构体(DVM_code.h)。
typedef struct DVM_ExecutableItem_tag {
DVM_Executable *executable;
struct DVM_ExecutableItem_tag *next;
} DVM_ExecutableItem;
struct DVM_ExecutableList_tag {
DVM_Executable *top_level;
DVM_ExecutableItem *list;
};
这是一个通过 DVM_ExecutableItem 保存 DVM_Executable 的链表的类。成员 top_level 在通过 list 保存了 DVM_Executable 的同时,也保存了顶层结构(编译器启动时设定的)。
8.1.3 ExecutableEntry
如前面所述,Diksam中没有跨文件的全局变量。函数外声明的变量被保存在独立的命名空间中,没有进行链接。
在以前的数据结构中,全局变量运行时的内存空间保存在 DVM_VirtualMachine中,如下所示。
typedef struct {
int variable_count;
DVM_Value *variable;
} Static;
struct DVM_VirtualMachine_tag {
(中间省略)
Static static_v;
(中间省略)
};
但是,正因为没有进行链接,所以对于DVM来说(全局变量)没有必要保存为一个数组。一个 DVM_Executable中保存一个数组就可以了。
在和编译器共用的 DVM_Executable 中,不能只保存运行时使用的数据,因此引入了 ExecutableEntry结构体,如下所示(dvm_pri.h)。
struct ExecutableEntry_tag {
DVM_Executable *executable;
Static static_v; ←函数外声明的变量所使用的内存空间
struct ExecutableEntry_tag *next;
};
运行时,只为每个 DVM_Executable 分配一个 ExecutableEntry 数据结构。如上所述,其中保存着之前在 DVM_VirtualMachine中保存的全局变量(函数外声明的变量)的内存空间。
8.1.4 分开编译源代码
接下来要解决的问题是,在一个源文件使用 require请求了其他源文件的情况下,如何进行编译比较好?
比较直接的想法,我想是在解析器发现 require 的时候递归调用编译器。但是,因为在yacc/lex的内部使用了很多全局变量,所以不能使用递归。也就是说,在解析一个文件的中途不能再去解析其他文件 [3]。
Diksam的编译顺序是,在一个源文件完成编译后,再按顺序编译被 require的源文件。
DKC_Compiler结构体作为Diksam编译的核心,其内部保存着顶层结构的语句列表和函数(FunctionDefinition)的列表等。在编译的最后阶段,会根据这个结构体生成 DVM_Executable。从结构上来说, DKC_Compiler和 DVM_Executable是1:1的关系,因此在源文件中编译被 require的源文件时,会为其创建一个新的 DKC_Compiler结构体。
编译Diksam的代码时,应用程序会调用 DKC_Compile()函数。这个函数会调用 do_compile()方法,如下所示。
yyin = fp; / 将源代码fg(作为起点)赋值到yyin中 /
/ 生成空的DVM_ExecutableList /
list = MEM_malloc(sizeof(DVM_ExecutableList));
list->list=NULL;
/ 调用do_compile()。第三个参数为源文件的路径,但在这个层级不适用。 /
exe = do_compile(compile, list, NULL, DVM_FALSE);
do_compile()的内容如代码清单8-1所示(节选)。
代码清单8-1 do_compile()
1: static DVM_Executable *
2: do_compile(DKC_Compiler compiler, DVM_ExecutableList list,
3: char *path, DVM_Boolean is_required)
4: {
5: (省略局部变量的声明部分)
6: / 在C的栈中回避当前编译器 /
7: compiler_backup = dkc_get_current_compiler();
8: dkc_set_current_compiler(compiler);
9:
10: / 执行解析 /
11: if (yyparse()) {
12: fprintf(stderr, "Error!Error!Error!\n");
13: exit(1);
14: }
15:
16: / 遍历所有被require的源文件 /
17: for (req_pos = compiler->require_list; req_pos;
18: req_pos = req_pos->next) {
19: / 检查正在编译的源文件是否有相应的编译器 /
20: req_comp = search_compiler(st_compiler_list, req_pos->package_name);
21: if (req_comp) {
22: compiler->required_list
23: = add_compiler_to_list(compiler->required_list, req_comp);
24: countinue;
25: }
26: / 如果没有,创建一个新的编译器并进行编译 /
27: req_comp = DKC_create_compiler();
28:
29: (中间省略。这里将搜索到的源文件路径设置到found_path中。)
30: req_exe = do_compile(req_comp, list, found_path, DVM_TRUE);
31: }
32:
33: dkc_fix_tree(compiler);
34: exe = dkc_generate(compiler);
35: if (path) {
36: exe->path = MEM_strdup(path);
37: } else {
38: exe->path = NULL;
39: }
40:
41: exe->is_required = is_required;
42: if (!add_exe_to_list(exe, list)) {
43: dvm_dispose_executable(exe);
44: }
45:
46: / 从备份中恢复当前编译器 /
47: dkc_set_current_compiler(compiler_backup);
48:
49: return exe;
50:}
在函数中,yyin的值被设置为源文件的文件指针,并在第11~14行解析这个文件。之后,按照顺序循环地编译从第17行开始的代码。
前面已经提到过,当前版本的Diksam会为每个源文件生成一个编译器(DKC_Compiler)。然后,执行过一次编译的编译器被保存在名为 st_compiler_list 的 static 的链表中。在第20行被调用的函数 search_compiler()是为了在第1个参数 st_compiler_list中搜索是否有编译过当前包的编译器。 DKC_Compiler保存着包名,如果包已经被编译过,将对应的编译器添加到正在编译的编译器的 require_list中(第22~23行)。这个结构很像树结构,但是这个结构是为了共享同一个被多次 require的源文件,因此实际上它并不是树结构,而是DAG(有向无循环图,Directed Acyclic Graph)结构。
如果有没有编译过源文件的话,从第27行开始的代码会创建一个新的编译器并进行编译。
并且,第一次启动时, st_compiler_list的生命周期是从第一次编译结束到开始运行之前。因此,在动态加载的时候同样的源代码会被再次编译。详细请参考8.1.5节的补充知识。
第29行中间省略了通过DKM_REQUIRE_SEARCH_PATH搜索被require的源文件并返回文件指针等一连串的处理。之后将返回的文件指针作为参数,递归调用 do_compile()函数(第30行)。
所有的子文件都编译过后,将使用 dkc_generate() 创建 DVM_Executable,然后将其注册到 DVM_ExecutableList中(第42行)。
最终状态的 DKC_Compiler的结构如图8-1所示。
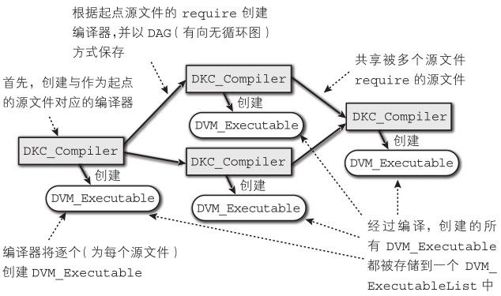
图8-1 编译器编译后的结构
8.1.5 加载和再链接
由于编译是以源文件为单位进行的,因此完成编译之后,还需要进行链接。 链接 是指把不同源文件中出现的同名函数进行对应的操作。本节是继续6.4.1节的内容作介绍。
在C等语言中,全局变量也必须进行链接,但是在Diksam中并没有可以跨源文件的全局变量,因此有必要和其他源文件进行链接的就只有函数了(虽然后面会出现类的概念)。
现在,“函数”的数据保存在以下三个地方。
- DKC_Compiler 中的 FunctionDefinition 列表
这个对应表中保存了在当前源文件中定义的原型声明函数。如果只是签名声明的话,指向实现程序块的成员 block应为 NULL。
这其中并不保存被 require的.dkh文件中声明的函数。这些函数将保存在自己所在.dkh文件对应的编译器中,因此,在搜索函数的工具函数 dkc_search_function()中,为了搜索参数指定的函数,需要递归地遍历所有子编译器(util.c)。
- DVM_Executable 中的 DVM_Function 数组
DVM_Executable的 DVM_Function数组中,保存着当前源文件中出现的所有函数。
假设在源文件a.dkh中 require了b.dkh,并且调用了b.dkh中声明的函数 b_func()。此时, b_func()并没有保存在a.dkh的 FunctionDefinition中,而是保存在 DVM_Executable中。
就像6.4.1节中介绍过的那样,在完成编译时,指令 push_function指定的函数的索引值就是这个数组的下标。因此,一般情况下所有需要被调用的函数都会保存在这个对应表中。
至于索引值,加载时会在字节码中直接替换为 DVM_VirtualMachine中 Function数组的下标(请参考6.4.1节)。
3. DVM_VirtualMachine中的Function数组
DVM_VirtualMachine 中的 Function 数组保存着链接后的函数,每个DVM中只有一个该数组。
因为Diksam是动态加载的,所以这个对应表中保存的函数还是没有实现的状态。此时,成员 is_implemented都是 false。
并且,这个数组在以前的版本中以可变长数组的形式保存在了 DVM_VirtualMachine结构体中,但是,现在变成了“指针的可变长数组”。后面将会说到,基于动态加载,这个数组会使用 realloc()进行扩展。之前的结构如果使用了 realloc()会使 Function结构体的地址发生变化。因此,我们需要一个即使扩展了数组的元素地址也不会改变的结构(如图8-2)。
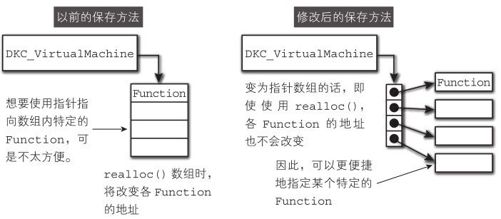
图8-2 修改为即使使用了realloc()元素,地址也不会改变的结构
具体的实例请参考以下三段源代码(hoge.dkm,piyo.dkh,piyo.dkm)。
hoge.dkm:
require piyo;
int hoge_func() {
piyo_func();
}
hoge_func();
piyo.dkh:
int piyo_func();
piyo.dkm:
require diksam.lang;
int piyo_func() {
print("piyo piyo\n");
}
各个源文件在对应表中的注册状态如图8-3所示。
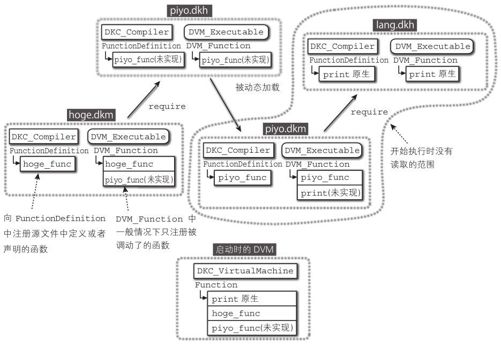
图8-3 函数在对应表中注册的状态
由于在hoge.dkh中仅定义或者签名声明了函数 hoge_func(),因此 FunctionDefinition 也只注册了一个函数。但是, DVM_Executable 的 DVM_Function中只注册了被调用的 piyo_func()函数。 push_function指令创建不了的函数不会注册到这里。
hoge.dkm 中被 require 的 piyo.dkh 也会被同时编译。在这里被声明的 piyo_func() 会同时注册到 piyo.dkh 的 FunctionDefinition 和 DVM_Executable两个地方。
在执行开始时只编译了这两个文件。在这个状态中,会根据 DVM_VirtualMachine 的 Function 创建对应表,并将经常以原生函数形式出现的 print()、 hoge_func()和 piyo_func()注册进来。但是,虽然piyo.dkm描述了实现但还没有被加载,因此还没有实现 piyo_func()。
一旦 piyo_func()被调用,就会进行动态加载。动态加载功能首先新创建一个piyo.dkm的编译器,然后再创建一个被 require的lang.dkh的编译器,最后将创建出来的 DVM_Executable链接到 DVM_VirtualMachine中,并开始执行 piyo_func()。
补充知识 动态加载时的编译器
只需一次编译,就可以让同一个文件在任何地方都能被 require,与此相对,只创建一个 DKC_Compiler 就可以了。在代码清单 8-1 中说明了其实现方法,即使用 static的变量 st_compiler_list保存所有编译器。
但是,也会发生这样的情况,在a.dkm中 require了b.dkh,b.dkh中动态加载的b.dkm又调用了a.dkm中的函数。在现在的实现中,只会为a.dkm创建一个 DVM_Executable,但是却会多次创建 DKC_Compiler。a.dkm 的 DKC_Compiler 在第一次编译后将被销毁,但编译b.dkm时又必须使用a.dkm的编译器。在b.dkm的 FunctionDefinition中只注册了a.dkm中被调用的函数,但请记住它是会搜索子编译器的。
同一个源文件被编译多次确实很浪费,但是现在的Diksam还不能把字节码保存在文件中,因此在执行时必须要有源代码。考虑到这样的情况,虽然很浪费但也没有什么坏处,在实用性上也不会有问题。
等到日后字节码可以保存到文件中的时候,只需使用 DVM_Executable 中包含的 DVM_Function等信息就可以完成源代码的编译了。
