4.3 实现GC本身
之前介绍了mark-sweep GC的基本原理和crowbar中对象引用的“根”。本节开始介绍究竟在crowbar里运行着什么样的GC以及它的实现方式。
另外,与GC相关的代码大部分收录在heap.c中。
4.3.1 对象的管理方法
crowbar 中像字符串和数组这样的对象可以通过 CRB_Object 结构体保存在堆 [8]中。CRB_Object需要逐个使用MEM_malloc()申请内存空间。
前面已经给出了CRB_Object结构体的定义,它在成员中持有指针prev和next。由名字可以联想到,CRB_Object是作为双向链表进行管理的。
CRB_Interpreter中持有这个链表的头节点。为了方便管理堆相关的信息,我们定义了结构体 Heap。
typedef struct {
int current_heap_size;
int current_threshold;
CRB_Object *header;
} Heap;
header指向 CRB_Object链表的开头。 current_heap_size和 current_threshold用于控制GC的启动时机。
4.3.2 GC何时启动
在程序运行的过程中,mark-sweep GC会在某个时机启动,释放不需要的对象。那么究竟要在何时启动GC呢?
其中一种方案就是内存不足的时候(即 malloc()返回 NULL时)。我们先不考虑 MEM_malloc()在 malloc()返回NULL时会调用 exit()的情况,若是到了 malloc()返回 NULL的地步,那就说明内存空间是真的不足了,此时再运行GC为时已晚。像后面说到的那样,现在的mark-sweep GC需要使用大量的栈空间,因此,如果真是到了 malloc()返回 NULL的时候,也不知道GC是否能启动。大多数的操作系统即使调用了 free()函数,也不会将释放出来的内存空间还给操作系统,只是可以再次使用 malloc()而已。因此即使GC将内存空间释放,其他应用(进程)也不能使用,所以GC要是坚持到内存被占满时才启动的话,会给其他程序带来很大的麻烦。
于是,crowbar使用了这样一种方式,即耗费了一定量的内存后,就启动GC。这个一定量在 Heap 结构体的 current_threshold* 中保存,初始值由宏 A HEAP_THRESHOLD_SIZE进行定义(#define),暂定为256KB。
crowbar 每次创建对象,都要把所创建对象的大小值叠加到 CRB_Interpreter中 Heap结构体的 current_heap_size上。这个大小值也就是要传给 MEM_malloc()的大小值,所以这个值不包含 malloc()和 MEM模块的管理空间(毕竟是相似的)。
而且,在创建对象前,要先调用 check_gc()。
static void
check_gc(CRB_Interpreter *inter)
{
/ 堆耗费量超过阈值的话…… /
if(inter->heap.current_heap_size > inter->heap.current_threshold) {
/ 启动GC /
crb_garbage_collect(inter);
/ 设定下一个阈值 /
inter->heap.current_threshold
= inter->heap.current_heap_size + HEAP_THRESHOLD_SIZE;
}
}
上面的函数中,如果堆的消耗量超过了当前的阈值就启动GC。GC执行的时候, current_heap_size 的值会变小,将变小后的 current_heap_size和 HEAP_THRESHOLD_SIZE相加,就得出了下一个阈值。
至于函数 crb_garbage_collect()就没有必要详细说明了。
void
crb_garbage_collect(CRB_Interpreter *inter)
{
gc_mark_objects(inter);/ mark /
gc_sweep_objects(inter);/ sweep /
}
上面调用的gc_mark_objects()都做了哪些事,请参见代码清单4-2。在清除了所有对象mark的基础上,从各个根(前面介绍过)开始调用 gc_mark()。
代码清单4-2 gc_mark_objects()
static void
gc_mark_objects(CRB_Interpreter *inter)
{
CRB_Object *obj;
Variable *v;
CRB_LocalEnvironment *lv;
int i;
/ 清除全部标记(mark) /
for (obj = inter->heap.header; obj; obj = obj->next) {
gc_reset_mark(obj);
}
/ 全局变量 /
for (v = inter->variable; v; v = v->next) {
if (dkc_is_object_value(v->value.type)) {
gc_mark(v->value.u.object);
}
}
/ 局部变量 /
for (lv = inter->top_environment; lv; lv = lv->next) {
for (v = lv->variable; v; v = v->next) {
if (dkc_is_object_value(v->value.type)) {
gc_mark(v->value.u.object);
}
}
gc_mark_ref_in_native_method(lv); / ←这里稍后再做说明 /
}
/ crowbar栈 /
for (i = 0; i < inter->stack.stack_pointer; i++) {
if (dkc_is_object_value(inter->stack.stack[i].type)) {
gc_mark(inter->stack.stack[i]. u.object);
}
}
}
gc_mark()相关内容请参见代码清单4-3。如果对象已经被标记,就直接 return(为了防止发生循环引用时出现死循环),然后将自己打上标记。如果是数组的话就遍历每个元素,并以此为参数递归调用 gc_mark()。
代码清单4-3 gc_mark()
static void
gc_mark(CRB_Object *obj)
{
if (obj->marked)
return;
obj->marked = CRB_TRUE;
if (obj->type == ARRAY_OBJECT) {
int i;
for (i = 0; i < obj->u.array.size; i++) {
if (dkc_is_object_value(obj->u.array.array[i]. type)) {
gc_mark(obj->u.array.array[i]. u.object);
}
}
}
}
4.3.3 sweep阶段
在sweep阶段释放那些链表中没有被标记的管理对象,并对链表进行维护(见代码清单4-4)。
代码清单4-4 gc_sweep_objects()
static void
gc_sweep_objects(CRB_Interpreter *inter)
{
CRB_Object *obj;
CRB_Object *tmp;
for (obj = inter->heap.header; obj; ) {
if (!obj->marked) {
if(obj->prev) {
obj->prev->next = obj->next;
} else {
inter->heap.header = obj->next;
}
if (obj->next) {
obj->next->prev = obj->prev;
}
tmp = obj->next;
gc_dispose_object(inter, obj);
obj = tmp;
} else {
obj = obj->next;
}
}
}
这其中调用的 gc_dispose_object()把数组和字符串区分进行处理,释放 CRB_Object顶端指向的区域(见代码清单4-5)。
代码清单4-5 gc_dispose_object()
static void
gc_dispose_object(CRB_Interpreter inter, CRB_Object obj)
{
switch (obj->type) {
case ARRAY_OBJECT:
inter->heap.current_heap_size
-= sizeof(CRB_Value) * obj->u.array.alloc_size;
MEM_free(obj->u.array.array);
break;
case STRING_OBJECT:
if (!obj->u.string.is_literal) {
inter->heap.current_heap_size -= strlen(obj->u.string. string) + 1;
MEM_free(obj->u.string.string);
}
break;
case OBJECT_TYPE_COUNT_PLUS_1:
default:
DBG_assert(0, (“bad type..%d\n”, obj->type));
}
inter->heap.current_heap_size -= sizeof(CRB_Object);
MEM_free(obj);
}
补充知识 GC现存的问题
crowbar的GC最简单地实现了mark-sweep GC。因为是最简单的实现,所以还存在以下问题。
1.运行GC时,程序会停止运行。
2.进行标记(mark)时的递归调用会消耗大量的栈空间。
首先是问题1。因为是简单实现了mark-sweep算法,所以在进行mark-sweep时会完全停止主程序的运行(crowbar也是如此)。为了避免(减轻)这个问题,大概有以下两种方法:
让GC和主程序异步(并行)执行;
使用新一代GC技术。
如果让GC和主程序异步(并行)执行,虽然GC占用CPU的总耗时不变,但是可以避免程序停止的情况,这对于一个互动程序来说是非常重要的。但是,实际上GC在异步执行时,肯定会发生当GC标记对象时,主程序中的对象引用关系同时发生改变的情况,这样一来有些对象就可能被遗漏而没有打上标记。避免这种情况发生的方法是有的(请用“write barrier”等词搜索一下),但是实现起来有点难度。
新一代的GC技术基于“经过一段时间后依然存活的对象有可能一直存活下去”的经验,将对象分为不同世代进行管理。经过一段时间后依然被引用的对象,被当做“老年代”处理,对于老年代的对象,GC执行得不会很频繁。
比如需要编辑一个很大的文本时,实际需要编辑的内容只是全文的一小部分,但是在简单实现的GC中,却要对全部文本进行标记,这样会做很多无用功。而新一代的GC避免了这样的无用功,缩短了对于GC来说很重要的时间,提高了总体的处理速度。
问题是,新生代的对象向老年代对象转变的过程中,在对象的新生代标记被取消,又没有标记为老年代时,就发生了漏标记的情况。这当然是不允许的,必须要有对策。
下面我们再来看一下mark-sweep的第二个问题,即进行标记(mark)时的递归调用会消耗大量的栈空间。明明是因为内存不足才启动的GC,但是GC又消耗了大量的栈空间,这让人有种本末倒置的感觉。数据结构决定了到底要消耗多少栈空间,像“将巨大的文件全部读入链表中,再进行一些处理”的程序,可想而知是很简单的(特别是使用脚本语言来做)。大量的小对象链接构成链表,再递归进行标记,光是对象的数量就足以占用大量的栈空间了。
我们使用称为链接反转法的思考方式来避免这个问题。在标记对象时,为了方便递归,以及在一个对象标记结束后能够更容易返回到持有它的对象,我们在栈中使用局部变量来记录已经处理了对象中的哪个引用。链接反转法用下面的方法实现在对象内的记录。
按照对象A→对象B的顺序进行标记,在移动到下一个对象C时,将对象B中指向C的引用指向A。
每个对象都要增加成员“已经处理了哪个引用”。
补充知识 Coping GC
Coping GC是一种已知的(经典的)垃圾回收器实现方法。 Coping GC有以下策略(如图4-10)。
一开始就创建一个大的堆区域,并将它一分为二。
创建对象的时候,从其中一半的区域划分出内存投入使用。
当另一半区域被装满时,使用和mark-sweep的mark阶段相同的方式跟踪对象,只将生存的对象复制到另一半区域中即可。此时,由于对象的地址发生了变化,因此需要维护指向它们的所有指针。
复制之后,将对象复制的目标区域切换为创建对象时使用的区域。当这半边区域被装满时,再向另一半区域复制,如此循环往复。
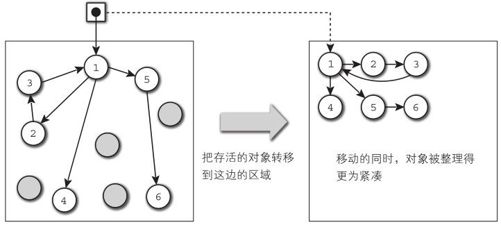
图4-10 Coping GC
一目了然,这个方法把最初的内存区域一分为二,在一个时间点只使用其中的一半,另外一半内存就浪费了。
看上去也许是一个效率极差的方法,但是这个方法和mark-sweep的GC相比有以下优点。
复制对象的同时进行压缩(compaction),由此,消除了碎片(fragmentation),提高了虚拟内存和高速缓存的效率。
舍弃了mark-sweep的sweep过程,因此,在生存对象占比较小的情况下效率较高。
碎片是指像 malloc()这样的函数多次对内存进行申请/释放的时候,内存如图4-11所示,出现极小且不连续的空间的状态。
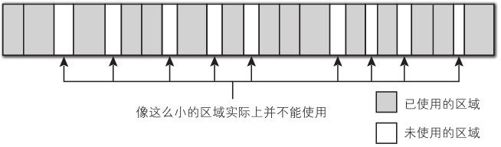
图4-11 碎片
这样一来,对象之间存在间隙的内存区域实际上不能使用,就造成了内存的浪费 [9]。
Coping GC在复制的时候将这些“间隙”消除。另外,一边追溯指针一边进行复制的方式使得相互指向的对象很可能被复制到临近的区域。因此,同时使用的对象也很有可能被放在一起,并写到虚拟内存的同一页中以减少翻页的几率,提升了性能。
