3.3 crowbar ver.0.1的实现
预先准备已经差不多了,终于可以开始阅读crowbar.book_ver.0.1的代码了。
3.3.1 crowbar的解释器——CRB_Interpreter
一般来说,程序的数据结构要比运行流程更加重要,因此我们就从crowbar解释器所用的结构体 CRB_Interpreter开始看起。
想使用crowbar,首先需要生成解释器,然后将解释器的源码传递给编译器(生成分析树),就可以运行了。
解释器的定义如下所示(位于 crowbar.h)。注意 CRB.h 中公开的 CRB_Interpreter是这个结构体的不完全定义,下面这个结构体定义本身对外是隐藏的。
struct CRB_Interpreter_tag {
MEM_Storage interpreter_storage;
MEM_Storage execute_storage;
Variable *variable;
FunctionDefinition *function_list;
StatementList *statement_list;
int current_line_number;
};
解释器会保存以下内容:
1. 与解释器相同生命周期的 MEM_Storage(interpreter_storage)
不再需要分析树时,需要将其释放,如3.2.2节所述,可以使用内存管理模块MEM提供的存储器功能来管理。
interpreter_storage存储器,在解释器生成时被生成,解释器废弃的同时被释放。通过 CRB_Interpreter自己来开辟这个存储器。
该存储器在内存中的开辟,是通过位于util.c中的 crb_malloc()工具函数实现的。
2. 运行时使用的 MEM_Storage(execute_storage)
execute_storage是运行时使用的存储器。不过由于运行时必备的数据结构大多数都没有固定的释放顺序,因此 execute_storage现阶段主要用于存放全局变量。
3. 全局变量链表(variable)
Variable结构体的定义如下所示:
typedef struct Variable_tag {
char name; / 变量名 */
CRB_Value value; / 变量值 /
struct Variable_tag next; / 指向下一个变量的指针 */
} Variable;
首先这个结构体中有 next 这一成员,这是为了构建链表用的。 CRB_Interpreter的成员 variable保存在最开头。通过这样的链表,可以得到所有的全局变量。
crowbar中变量是在首次赋值时生成的,因此在运行时会有变量逐一进入,链表也会越来越长。
Variable结构体的 name成员顾名思义会保存变量名,而 value成员则会保存该变量的值,具体请参考3.3.8节对 CRB_Value的说明。
4. 函数定义链表(function_list)
function_list是记录crowbar中编写函数的链表。语法解析时会创建这个 function_list以及下面的 statement_list。
FunctionDefinition类型的定义如下所示:
typedef enum {
CROWBAR_FUNCTION_DEFINITION = 1, / crowbar中定义过的函数 /
NATIVE_FUNCTION_DEFINITION / 内置函数 /
} FunctionDefinitionType;
typedef struct FunctionDefinition_tag {
char name; / 函数名 */
FunctionDefinitionType type; / 函数的类型 /
union {
struct {
ParameterList parameter; / 参数的定义 */
Block block; / 函数的主体 */
} crowbar_f;
struct {
CRB_NativeFunctionProc proc; / 后文详述 */
} native_f;
} u;
struct FunctionDefinition_tag next; / 链表用 */
} FunctionDefinition;
FunctionDefinition 类型的 type 成员中,会区分crowbar 定义的函数以及内置函数。crowbar定义的函数会使用下面联合体 u的 crowbar_f,而内置函数则会使用 native_f。通过这种方法,可以让没有继承概念的C语言实现类似继承的功能(具体方法之后会慢慢提到)。
crowbar 定义的函数会通过 crowbar_f 成员保存其函数参数及函数主体(执行语句)。 ParameterList 结构体如下所示,会将变量名做成链表并保存(crowbar是无类型语言,无需保存变量类型)。
typedef struct ParameterList_tag {
char name; / 变量名 */
struct ParameterList_tag next; / 链表所用指针 */
} ParameterList;
用block成员保存函数的执行语句。block是Block类型的结构体,Block类型的定义如下所示:
typedef struct {
StatementList*statement_list;
} Block;
StatementList正如其名称,是语句的链表。其结构体内容请参考第5项。
5. 语句链表(statement_list)
statement_list是语句的链表。其类型与上面的 Block结构体保存时所用的 StatementList类型相同。无论是函数定义 { }内的语句,还是顶层结构中的语句,从内部来讲都保存在 StatementList中。
crowbar 的解释器在语法解析后,顶层结构的语句,也就是 statement_list最开头保存的语句会按照顺序开始执行。
6. 编译时当前的行号(current_line_number)
出现错误信息需要行号。 current_line_number 可以在编译时显示当前的行号。
current_line_number在编译结束后不会再使用。运行时如果发生错误当然也需要显示行号,这里的行号保存在分析树的语句节点中。
补充知识 不完全类型
CRB_Interpreter类型结构体是在crowbar的私有头文件crowbar.h中定义的。不过这是供解释器内部使用的数据结构,不应该向外部公开。
而生成解释器的函数 CRB_create_interpreter(),它的原型定义则是在公有头文件CRB.h中:
CRB_Interpreter *CRB_create_interpreter(void);
CRB_create_interpreter() 返回值的类型为 CRB_Interpreter*,为了支持这样的原型定义必须首先定义 CRB_Interpreter结构体。但是我们不能把解释器的内部定义直接拿出来放在公有头文件中。
应对这种情况可以使用 不完全类型 。公有头文件中只定义结构体的标识符,实际的定义是由私有头文件传递给公有头文件的。
比如上面的 CRB_Interpreter类型,在CRB.h中可以做如下的标识符定义,并用 typedef命名。
typedef struct CRB_Interpreter_tag CRB_Interpreter;
这种状态的 CRB_Interpreter就是不完全类型。
不完全类型只能使用指针,即指向不完全类型的指针的变量无法被声明,不完全类型本身也无法声明变量,对不完全类型无法使用 sizeof。因此,我们是无法知道一个不完全类型的大小的,当然也无法引用其成员。
而crowbar.h是类型初始定义所在的地方,因此没有这些限制(详见3.3.1节)。这里的 CRB_Interpreter类型就不是不完全类型。
上述都是C语言编程中必须掌握的一些技巧,但我意外地发现似乎了解的人不多,因此写了下来。
3.3.2 词法分析——crowbar.l
crowbar的lex定义文件是crowbar.l。源代码的摘录版本如代码清单3-4所示。
代码清单3-4 crowbar.l
1: %{
省略C编码部分
19: %}
开始条件
20: %start COMMENT STRING_LITERAL_STATE
21: %%
保留字的定义
22: <INITIAL>"function" return FUNCTION;
23: <INITIAL>"if" return IF;
省略其他的保留字定义
符号类的定义。LP,RP是Left/Right Paren的缩写
LC,RC是Left/Right Curly(花括号)的缩写
35: <INITIAL>"(" return LP;
36: <INITIAL>")" return RP;
37: <INITIAL>"{" return LC;
38: <INITIAL>"}" return RC;
省略其他的符号定义
标识符(变量名、函数名等)
55: <INITIAL>[A-Za-z_][A-Za-z_0-9]* {
56: yylval.identifier = crb_create_identifier(yytext);
57: return IDENTIFIER;
58: }
数值。整数类型与实数类型分别处理,与mycalc.y相同
59: <INITIAL>([1-9][0-9]*)|"0" {
60: Expression *expression = crb_alloc_expression(INT_EXPRESSION);
61: sscanf(yytext, "%d", &expression->u.int_value);
62: yylval.expression = expression;
63: return INT_LITERAL;
64: }
65: <INITIAL>[0-9]+.[0-9]+ {
66: Expression *expression = crb_alloc_expression(DOUBLE_EXPRESSION);
67: sscanf(yytext, "%lf", &expression->u.double_value);
68: yylval.expression = expression;
69: return DOUBLE_LITERAL;
70: }
定义字符串开始
71: <INITIAL>\" {
72: crb_open_string_literal();
73: BEGIN STRING_LITERAL_STATE;
74: }
75: <INITIAL>[ \t] ;
遇到换行符则增加行号
76: <INITIAL>\n {increment_line_number();}
定义注释的开始
77: <INITIAL># BEGIN COMMENT;
如果不符合上述定义,则为非法字符并报错
78: <INITIAL>. {
79: char buf[LINE_BUF_SIZE];
80:
81: if (isprint(yytext[0])) {
82: buf[0] = yytext[0];
83: buf[1] = '\0';
84: } else {
85: sprintf(buf, "0x%02x", (unsigned char)yytext[0]);
86: }
87:
88: crb_compile_error(CHARACTER_INVALID_ERR,
89: STRING_MESSAGE_ARGUMENT, "bad_char", buf,
90: MESSAGE_ARGUMENT_END);
91: }
92: <COMMENT>\n {
93: increment_line_number();
94: BEGIN INITIAL;
95: }
96: <COMMENT>. ;
97: <STRING_LITERAL_STATE>\" {
98: Expression *expression = crb_alloc_expression(STRING_EXPRESSION);
99: expression->u.string_value = crb_close_string_literal();
100: yylval.expression = expression;
101: BEGIN INITIAL;
102: return STRING_LITERAL;
103: }
104: <STRING_LITERAL_STATE>\n {
105: crb_add_string_literal('\n');
106: increment_line_number();
107: }
108: <STRING_LITERAL_STATE>\\" crb_add_string_literal('"');
109: <STRING_LITERAL_STATE>\n crb_add_string_literal('\n');
110: <STRING_LITERAL_STATE>\t crb_add_string_literal('\t');
111: <STRING_LITERAL_STATE>\\ crb_add_string_literal('\');
112: <STRING_LITERAL_STATE>. crb_add_string_literal(yytext[0]);
113: %%
crowbar.l与之前计算器的例子mycalc.l相比(代码清单2-1)要长很多,但本质上没有太大变化,只是使用了新的 开始条件 功能。与mycalc.l不同的是,在crowbar.l的大部分规则前都要书写 <INITIAL>,这就是开始条件。
在crowbar中,开始条件主要用于分割注释与字面常量(literal)。
crowbar的注释由 #开头直到行尾,可以用简单的正则表达式 #.*$将其分割,分割出的注释暂时保存在全局变量 yytext中。
在以前的lex 处理器中,给 yytext 分配了一个固定大小的 char 数组,而且数组的大小是无法扩展的。不过包含flex在内,最近发布的lex处理器中, yytext已经更改为 char*,当一个很长的记号进入时,也可以动态扩展储存空间,注释最终也是要被丢弃的,如果还在这里特意去扩展存储空间的话,就显得有点笨了。
crowbar的字面常量与C语言一样,是包含 \n和 \t的,还可以通过 \"显示双引号本身,因此简单通过 \".*\"的正则表达式规则进行匹配是不行的。
应对这种情况可以使用开始条件。在动作中书写 BEGIN COMMIT 切换lex 的状态,其对应的规则就变成后面用 <COMMENT> 开始的部分了。lex 使用 INITIAL定义了开始条件的初始状态。
crowbar.l中,通过下面的处理将注释读入并丢弃。
77: <INITIAL># BEGIN COMMENT;
中间省略
92: <COMMENT>\n {
93: increment_line_number();
94: BEGIN INITIAL;
95: }
96: <COMMENT>. ;
代码第77行, INITIAL 状态下如果有 # 进入,则转换为 COMMENT 状态。crowbar的注释由 #开始直至行尾,因此在 COMMENT状态下如果遇到换行则切换回 INITIAL 状态(第92~95行的 increment_line_number() 会在后文详述)。所以, COMMENT状态下会将除换行符以外的字符全部丢弃(第96行)。
关于字符串的字面常量处理,开始时调用 crb_open_string_literal(),中间的字符通过 crb_add_string_literal()追加,最后通过 crb_close_string_literal()结束一个字符串的处理。
在这个过程中,字符串会被保存在 string.c 的 st_string_literal_buffer 这一 static 变量中。我本人对于使用 static 变量还是有些抵制的,但是鉴于我们只能把yacc/lex作为工具来使用,即使有什么想法也无法修改(至少老版本是不允许修改的),因此crowbar最终还是允许在编译器中使用静态变量的(请参考本节的补充知识)。
语法处理器在编译时如果发生错误,需要显示错误信息,因此错误信息中必须包含行号。
在crowbar.l中的对应处理是,每换行一次,行号都会进行计数。具体来说有以下三处:
76: <INITIAL>\n {increment_line_number();}
…
92: <COMMENT>\n {
93: increment_line_number();
94: BEGIN INITIAL;
95: }
…
104: <STRING_LITERAL_STATE>\n {
105: crb_add_string_literal('\n');
106: increment_line_number();
107: }
这里进行计数的行号保存在 CRB_Interpreter 的 current_line_number中。
补充知识 静态变量的许可范围
如上文所写,在词法分析中,正在读入的字符串会保存在string.c的 st_string_literal_buffer 中。在编译时,当前的编译器会保存在 util.c 的 st_current_interpreter中。而在yacc/lex中,还会使用 yytext等全局变量。
使用如此多的静态变量,首当其冲会遇到的就是多线程问题。
当下多线程的程序已经很普及了,静态变量可以在多线程之间共享,因此多个线程如果同时进行编译的话可能会引发问题。
不过一般来说,编译过程都是一下子就能结束的,因此在这样短的时间内通过加一个全局锁的方式就可以解决问题了。正因为有这样既简单又实用的方法,crowbar才放心地允许在编译过程中使用静态变量。而静态变量仅在编译过程中被使用,一旦程序开始运行后就无法使用了。具体来说,由于MEM模块会静态地保存内存块链表,这原本就是以调试为目的创建的链表,可以随时删除,而由于MEM模块位于系统最底层,因此可以对 MEM_malloc()的运行进行加锁处理。
使用静态变量还会造成另一个问题,就是编译器无法递归运行。比如crowbar中的库函数都书写在独立文件中,在C语言中理论上只需要用 #include就能很简单地把功能包含进来。但是实际应用中就会发现,使用 #include包括进来的独立文件,在编译过程中如果再开始一个解析器,之前的静态变量就会被覆盖。
标准版的yacc/lex,由于使用了yytext等全局变量,因此也无法支持多线程或使用递归。不过bison有单独的扩展可以让其支持多线程。 [5]
3.3.3 分析树的构建——crowbar.y与create.c
crowbar中yacc的定义文件为crowbar.y。从构成来说,与计算器版的mycalc.y没有什么变化。
但是在计算器中,归约是在实际进行计算时才进行的,而crowbar.y则是在构建分析树时进行的。
比如一个加法算式(如 10 + a)会按照以下的规则构建:
additive_expression
(中间省略)
| additive_expression ADD multiplicative_expression
{
$$ = crb_create_binary_expression(ADD_EXPRESSION, $1, $3);
}
这里的 additive_expression对应mycalc.y中的 expression, multi-plicative_expression对应 term。
在动作中, crb_create_binary_expression() 被调用,其实际运行代码在create.c中。这个函数负责常量折叠(参考3.3.4节),所以稍微有些复杂,将这部分以外的核心代码精简一下,可以看到这个函数的主要逻辑如下所示:
Expression *
crb_create_binary_expression(ExpressionType operator,
Expression left, Expression right)
{
Expression *exp;
exp = crb_alloc_expression(operator);
exp->u.binary_expression.left = left;
exp->u.binary_expression.right = right;
return exp;
}
crb_alloc_expression()将开辟一个存放 Expression类型结构体的内存空间,并将其返回。 Expression类型在crowbar.h中的定义如下所示:
struct Expression_tag {
ExpressionType type; ←表示表达式的类别
int line_number;
union { ←用联合体保存不同种类对应的值
CRB_Boolean boolean_value;
int int_value;
double double_value;
char *string_value;
char *identifier;
AssignExpression assign_expression;
BinaryExpression binary_expression;
Expression *minus_expression;
FunctionCallExpression function_call_expression;
} u;
};
这个结构体在分析树中用来表示“表达式”的类型。与 CRB_Value 一样,用枚举类型的 ExpressionType表示表达式的类型,用联合体保存各种类型对应的值。
ExpressionType具体定义如下:
typedef enum {
BOOLEAN_EXPRESSION = 1, / 布尔型常量 /
INT_EXPRESSION, / 整数型常量 /
DOUBLE_EXPRESSION, / 实数型常量 /
STRING_EXPRESSION, / 字符串型常量 /
IDENTIFIER_EXPRESSION, / 变量 /
ASSIGN_EXPRESSION, / 赋值表达式 /
ADD_EXPRESSION, / 加法表达式 /
SUB_EXPRESSION, / 减法表达式 /
MUL_EXPRESSION, / 乘法表达式 /
DIV_EXPRESSION, / 除法表达式 /
MOD_EXPRESSION, / 求余表达式 /
EQ_EXPRESSION, / == /
NE_EXPRESSION, / != /
GT_EXPRESSION, / > /
GE_EXPRESSION, / >= /
LT_EXPRESSION, / < /
LE_EXPRESSION, / <= /
LOGICAL_AND_EXPRESSION, / && /
LOGICAL_OR_EXPRESSION, / || /
MINUS_EXPRESSION, / 单目取负 /
FUNCTION_CALL_EXPRESSION, / 函数调用表达式 /
NULL_EXPRESSION, / null表达式 /
EXPRESSION_TYPE_COUNT_PLUS_1
} ExpressionType;
这其中从 ADD_EXPRESSION到 LOGICAL_OR_EXPRESSION,都在使用联合体的 binary_expression成员。
binary_expression的类型是 BinaryExpression,其定义如下所示:
typedef struct {
Expression *left;
Expression *right;
} BinaryExpression;
crb_create_binary_expression()最终返回这样构建出的 Expression的指针,并在crowbar.y中将其赋值给 $$。
$$ = crb_create_binary_expression(ADD_EXPRESSION, $1, $3);
比如 10 + a + b这样的语句,按上面的处理就会构建出如图3-4的分析树。
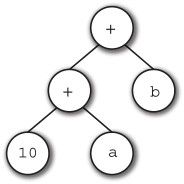
图3-4 10+a+b的分析树
那么,接下来是 crb_alloc_expression() 函数,这个函数只是简单地用 crb_malloc()开辟 Expression的空间,并且将 type连同刚被设置的行号一起返回。
crb_alloc_expression(ExpressionType type)
{
Expression *exp;
exp = crb_malloc(sizeof(Expression));
exp->type = type;
exp->line_number = crb_get_current_interpreter()->current_line_number;
return exp;
}
在分析树中,不单是表达式,语句(statement)也很重要。构建语句的思路与表达式基本是一样的,关联的结构体定义从crowbar.h中摘录如下:
struct Statement_tag {
StatementType type;
int line_number;
union {
Expression expression_s; / 表达式语句 */
GlobalStatement global_s; / global语句 /
IfStatement if_s; / if语句 /
WhileStatement while_s; / while语句 /
ForStatement for_s; / for语句 /
ReturnStatement return_s; / return语句 /
} u;
};
随便举一个联合体的例子,比如 WhileStatement的定义如下所示:
typedef struct {
Expression condition; / 条件表达式 */
Block block; / 可执行块 */
} WhileStatement;
Block在3.3.1节中已经出现过一次,即一段用花括号包裹的代码段类型。
StatementType的一览表如下所示:
typedef enum {
EXPRESSION_STATEMENT = 1,
GLOBAL_STATEMENT,
IF_STATEMENT,
WHILE_STATEMENT,
FOR_STATEMENT,
RETURN_STATEMENT,
BREAK_STATEMENT,
CONTINUE_STATEMENT,
STATEMENT_TYPE_COUNT_PLUS_1
} StatementType;
BREAK_STATEMENT和 CONTINUE_STATEMENT现阶段都没有信息需要保存(如果想像Java那样支持标签或break语句的话就需要保存了),因此没有对应的联合体成员。
3.3.4 常量折叠
比如
a = a + 10 * 2;
这样一个表达式,其实与
a = a + 20;
是同值的。诸如这种纯常量构成的表达式或部分表达式,在编译时提前被计算出来的处理方式叫作 常量折叠 (constant folding)。由于编译时这部分计算就已经完成了,所以能有效地提高运行速度。
crowbar中也部分引入了常量折叠的处理。具体来说,在进行整数型与实数型相关的四则运算或者单目取负时会进行常量折叠 [6]。这部分代码本书不会进行详细说明,请参考create.c 的 crb_create_binary_expression() 和 crb_create_minus_expression()。
crowbar中的常量折叠其实可以归入所谓程序最优化(optimization)的范畴,在语言的制作阶段考虑最优化本来为时尚早,但是由于crowbar的目标是类似C的语言,这种优化在部分场景中是必须的。比如C语言在一些特定地方只能写常量表达式(static变量的初始化或数组的大小指定等 [7]),这些地方需要支持常量折叠的处理。
程序优化是指通过不断调整程序以提高代码的运行速度,但是调整的结果到底是不是“最优”其实不好评判,因此有些人提出“最优化”这个用词是不恰当的。
3.3.5 错误信息
错误信息考虑到需要支持多语言 [8],所以一般尽可能避免硬编码出现在代码中,最好以提供外部文件的方式实现。但是在开始设计crowbar这样的脚本语言时,我非常希望crowbar只通过一个可执行文件就能运行。比如我想去别的地方做一些文字处理工作,那么只需要把crowbar的唯一一个可执行文件拷入U盘就可以拿去用了。 [9]
因此crowbar还是选择将错误信息硬编码在error_message.c的源文件中,参看代码清单3-5。
代码清单3-5 error_message.c
MessageFormatcrb_compile_error_message_format [ ]={
{ "dummy"},
{ "($(token)附近有语法错误)"},
{ "错误的字符($(bad_char))"},
{ "函数名重复($(name))"},
{ "dummy"},
};
MessageFormat crb_runtime_error_message_format[] = {
{ "dummy"},
{ "找不到变量($(name))。"},
{ "找不到函数($(name))。"},
{ "传递的参数多于函数所要求的参数。"},
{ "传递的参数少于函数所要求的参数。"},
{ "条件语句类型必须为boolean型"},
…
{ "dummy"},
};
通过这种方式,将来如果要支持多语言的话,可以简单地通过修改外部文件来实现。而设置 crb_compile_error_message 与 crb_runtime_error_message这两个数组,是为了将编译时的错误信息与运行时的错误信息区分开来。这些数组的索引,与crowbar.h中对应的枚举型的值是一致的。
代码清单3-6 crowbar.h的错误信息枚举型定义
typedef enum {
PARSE_ERR = 1,
CHARACTER_INVALID_ERR,
FUNCTION_MULTIPLE_DEFINE_ERR,
COMPILE_ERROR_COUNT_PLUS_1
} CompileError;
typedef enum {
VARIABLE_NOT_FOUND_ERR = 1,
FUNCTION_NOT_FOUND_ERR,
ARGUMENT_TOO_MANY_ERR,
…
RUNTIME_ERROR_COUNT_PLUS_1
} RuntimeError;
代码清单3-6中的错误信息,包含了一个 $(token)这样的字符串,这是错误信息中的可变部分。比如找不到一个名为 hoge的变量时,如果能报出“找不到变量(hoge)”,要比只报“找不到变量”对用户更加友好。
为了实现错误信息中可以包含变量,显示错误信息时会调用下面的函数 crb_runtime_error() [10]。
crb_runtime_error(expr->line_number, /行号 /
VARIABLE_NOT_FOUND_ERR, / 枚举错误信息类别 /
STRING_MESSAGE_ARGUMENT, / 可变部分的类型 /
"name", / 可变部分的标识符 /
expr->u.identifier, / 所要显示的值 /
MESSAGE_ARGUMENT_END);
第一个参数是行号(在create.c 中 Expression 结构体中设定),下一个参数是错误类别(crowbar.h 中的 RuntimeError 枚举型),之后的三个参数为一组,对应错误信息的可变部分。 STRING_MESSAGE_ARGUMENT 代表信息类型(相当于 printf()中使用的 %s), name即错误信息中的 $(name), expr->u. identifier则表示可变部分要显示的字符串。由于可变部分可以有多个,因此 crb_runtime_error为一个变长参数,所以可以用 MESSAGE_ARGUMENT_END表示参数输入结束。
当前版本无论是编译错误还是运行错误,显示错误信息后都会立即调用 exit()终止程序。这样的处理其实还远远不够,如果用于扩展应用程序的话这样做更是致命的,因此应当参考9.2.1节加入异常处理机制。
补充知识 关于crowbar中使用的枚举型定义
比如在代码清单 3-6 中的 CompileError 类型,我特意将第一个元素 PARSE_ERR设置为1,而最后一个元素引入了名为 COMPILE_ERROR_COUNT_PLUS_1的可变元素。
typedef enum {
PARSE_ERR = 1, ←特意设置为1
CHARACTER_INVALID_ERR,
FUNCTION_MULTIPLE_DEFINE_ERR,
COMPILE_ERROR_COUNT_PLUS_1 ←可变元素
} CompileError;
类似这样的处理方式不只有 CompileError类型。比如用于显示 Expression类别的 ExpressionType类型也采用同样的构造。
特意这样设置的理由有下面几个。
假如忘记进行初始化时,变量中被置入0的概率是非常高的,那么枚举类型如果从1开始的话,可以更早地发现异常状态。
有了 COMPILE_ERROR_COUNT_PLUS_1 这个可变元素,就可以借助其遍历所有枚举元素,并在后续程序中利用这一特性进行更丰富的处理。
当然实际使用时,我发现这两处设置似乎也不是特别有效。
另外在错误信息中,错误信息数组的第一个和最后一个元素都是 dummy,这是为了防止在以后修改时只改了crowbar.h中的枚举类型,而忘记修改error_message.c中的对应错误信息,这样设置的话能在一定程度上自动检测这种遗漏(请参考error.c中的 self_check()函数)。
MessageFormat crb_compile_error_message_format[] = {
{"dummy"},
…
{"dummy"},
};
3.3.6 运行——execute.c
crowbar程序的运行是从 CRB_interpret()开始的,其函数实现如下:
void
CRB_interpret(CRB_Interpreter *interpreter)
{
interpreter->execute_storage = MEM_open_storage(0);
crb_add_std_fp(interpreter);
crb_execute_statement_list(interpreter, NULL, interpreter->statement_list);
}
第一行准备了运行时要用的 MEM_Storage,第二行的函数 crb_add_std_fp() 注册了三个内部全局变量 STDIN、 STDOUT 和 STDERR,然后通过 crb_execute_statement_list()将解释器中保存的语句链表按顺序执行。
那么我们就来看一看 crb_execute_statement_list()函数(代码清单3-7)。
代码清单3-7 crb_execute_state-ment_list()
StatementResult
crb_execute_statement_list(CRB_Interpreter *inter, LocalEnvironment
env, StatementList list)
{
StatementList *pos;
StatementResult result;
result.type = NORMAL_STATEMENT_RESULT;
for (pos = list; pos; pos = pos->next) {
result = execute_statement(inter, env, pos->statement);
if (result.type != NORMAL_STATEMENT_RESULT)
goto FUNC_END;
}
FUNC_END:
return result;
}
即按照链表的顺序,调用 execute_statement()。
execute_statement() 则会根据不同的 Statement 类型执行不同的处理(代码清单3-8)。
代码清单3-8 execute_statement()
static StatementResult
execute_statement(CRB_Interpreter inter, LocalEnvironment env,
Statement *statement)
{
StatementResult result;
result.type = NORMAL_STATEMENT_RESULT;
switch (statement->type) {
case EXPRESSION_STATEMENT:
crb_eval_expression(inter, env, statement->u.expression_s);
break;
case GLOBAL_STATEMENT:
result = execute_global_statement(inter, env, statement);
break;
case IF_STATEMENT:
result = execute_if_statement(inter, env, statement);
break;
case WHILE_STATEMENT:
result = execute_while_statement(inter, env, statement);
break;
…
case STATEMENT_TYPE_COUNT_PLUS_1: / FALLTHRU /
default:
DBG_panic(("bad case…%d", statement->type));
}
return result;
}
execute_statement()的第二个参数需要传递 LocalEnvironment 类型的结构体(指向其的指针)。这个结构体保存了当前运行中的函数的局部变量,如果函数还没有运行,则传递 NULL。
execute_statement()内部采用了 switch case来区分条件处理。如果将其调用的函数全部进行分析的话有点浪费篇幅了,这里以 while语句调用的 execute_while_statement()为代表进行说明(代码清单3-9,移除了错误检查等与核心功能无关的代码):
代码清单3-9 execute_while_statement()
static StatementResult
execute_while_statement(CRB_Interpreter *inter, LocalEnvironment
env, Statement statement)
{
StatementResult result;
CRB_Value cond;
result.type = NORMAL_STATEMENT_RESULT;
for (;;) { / 首先是一个无限循环 /
/ 通过条件语句判别 /
cond = crbeval_expression(inter, env, statement->u.while
s.condition);
/ 条件为真则结束循环 /
if (!cond.u.boolean_value)
break;
/ 条件不为真则执行内部语句 /
result = crb_execute_statement_list(inter, env,
statement->u.while_s.block
->statement_list);
/ break, continue, return的处理 /
if (result.type == RETURN_STATEMENT_RESULT) {
break;
} else if (result.type == BREAK_STATEMENT_RESULT) {
result.type = NORMAL_STATEMENT_RESULT;
break;
}
}
return result;
}
if语句或 while语句都会包含一些内部的语句,这些内部语句被称为嵌套(nest)。在crowbar中,如果存在嵌套,则不会进行递归,而是转向运行嵌套内的语句。
事实上,实现上面的机制主要用到的是 break、 continue、 return等,从某种程度上来说用 goto实现结构控制反而非常麻烦。
break、 continue、 return等出现时,必须从递归的最深处强制返回上层。
break 或 continue 的作用是从最内层的循环中跳出,当然 break或 continue很可能会出现在很多层嵌套的 if语句中,而无论其出现在哪里,正在进行的递归都必须从最底层一次性返回,这是不会改变的。
为了实现这一点,我们有一个“必杀技”可以使用—— setjmp()/ longjmp() [11]。这个必杀技还被应用到异常处理机制中,因此在crowbar中,返回值与结束状态会逐步返回。
execute_statement()以及内部被调用的函数群 execute_XXX_statement(),返回值均为 StatementResult的结构体。 StatementResult 的定义如下:
typedef enum {
NORMAL_STATEMENT_RESULT = 1,
RETURN_STATEMENT_RESULT,
BREAK_STATEMENT_RESULT,
CONTINUE_STATEMENT_RESULT,
STATEMENT_RESULT_TYPE_COUNT_PLUS_1
} StatementResultType;
typedef struct {
StatementResultType type;
union {
CRB_Value return_value;
} u;
} StatementResult;
通常, type会返回一个装入 NORMAL_STATEMENT_RESULT的 StatementResult,而 当 执行 return、 break、 continue 时, 则 分 别 在 RETURN_STATEMENT_RESULT、 BREAK_STATEMENT_RESULT、 CONTINUE_STATEMENT_RESULT装入对应的 StatementResult并返回。此外,在代码清单3-9的 execute_while_statement()等中会根据执行语句的返回值不同而所有不同,如果是 BREAK_STATEMENT_RESULT 或 RETURN_STATEMENT_RESULT 则会中断循环,而如果是 continue的话,只会中断 crb_execute_statement_list()中的运行。
如果是 return,那么不只要中断函数的运行,还要携带其返回值返回,此时会将返回值放入 StatementResult的 return_value中。
3.3.7 表达式评估——eval.c
表达式评估在eval.c中进行。
表达式评估,是在调用分析树进行递归下降分析后,通过对分析结果进行运算来实现的。其运算结果会装入 CRB_Value 结构体中并返回。关于 CRB_Value的定义请参考3.3.8节。
语句的运行是通过 execute_statement()中的 switch case判断分支条件来实现的,而表达式评估则是通过 eval_expression()来执行的(代码清单3-10)。
代码清单3-10 eval_expression()
static CRB_Value
eval_expression(CRB_Interpreter inter, LocalEnvironment env,
Expression *expr)
{
CRB_Value v;
switch (expr->type) {
case BOOLEAN_EXPRESSION: / 布尔型变量 /
v = eval_boolean_expression(expr->u.boolean_value);
break;
case INT_EXPRESSION: / 整数型变量 /
v = eval_int_expression(expr->u.int_value);
break;
case DOUBLE_EXPRESSION: / 实数型变量 /
v = eval_double_expression(expr->u.double_value);
break;
case STRING_EXPRESSION: / 字符串变量 /
v = eval_string_expression(inter, expr->u.string_value);
break;
case IDENTIFIER_EXPRESSION: / 变量 /
v = eval_identifier_expression(inter, env, expr);
break;
case ASSIGN_EXPRESSION: / 赋值表达式 /
v = eval_assign_expression(inter, env,
expr->u.assign_expression.variable,
expr->u.assign_expression.operand);
break;
/ 大部分二元运算符都整合在 eval_binary_expression()中 /
case ADD_EXPRESSION: / FALLTHRU /
case SUB_EXPRESSION: / FALLTHRU /
case MUL_EXPRESSION: / FALLTHRU /
case DIV_EXPRESSION: / FALLTHRU /
case MOD_EXPRESSION: / FALLTHRU /
case EQ_EXPRESSION: / FALLTHRU /
case NE_EXPRESSION: / FALLTHRU /
case GT_EXPRESSION: / FALLTHRU /
case GE_EXPRESSION: / FALLTHRU /
case LT_EXPRESSION: / FALLTHRU /
case LE_EXPRESSION:
v = crb_eval_binary_expression(inter, env,
expr->type,
expr->u.binary_expression.left,
expr->u.binary_expression.right);
break;
/ 逻辑与,逻辑或 /
case LOGICAL_AND_EXPRESSION:/ FALLTHRU /
case LOGICAL_OR_EXPRESSION:
v = eval_logical_and_or_expression(inter, env, expr->type,
expr->u.binary_expression.left,
expr->u.binary_expression.right);
break;
case MINUS_EXPRESSION: / 单目取负运算符 /
v = crb_eval_minus_expression(inter, env, expr->u.minus_expression);
break;
case FUNCTION_CALL_EXPRESSION: / 调用函数 /
v = eval_function_call_expression(inter, env, expr);
break;
case NULL_EXPRESSION: / 常数null /
v = eval_null_expression();
break;
case EXPRESSION_TYPE_COUNT_PLUS_1: / FALLTHRU /
default:
DBG_panic(("bad case. type..%d\n", expr->type));
}
return v;
}
比如 Expression结构体的 type是 INT_EXPRESSION(整数的常数)时会调用 eval_int_expression(),其实现如下所示。最后在 CRB_Value 结构体中装入值并返回。
static CRB_Value
eval_int_expression(int int_value)
{
CRB_Value v;
v.type = CRB_INT_VALUE;
v.u.int_value = int_value;
return v;
}
再比如分析树的加法节点(ADD_EXPRESSION)对于其左右项目会分别调用 eval_expression(),然后对其值进行加法运算,最后装入 CRB_Value并返回。
上面看起来只有很简单的一句话,其实对于加法运算来说,左右项目的组合有以下几种情况:
1. 左边是整数,右边也是整数(整数相加,返回整数)
2. 左边是实数,右边也是实数(实数相加,返回实数)
3. 左边是整数,右边是实数(左边转换为实数,最后返回实数)
4. 左边是实数,右边是整数(右边转换为实数,最后返回实数)
5. 左边是字符串,右边也是字符串(返回连接后的字符串)
6. 左边是字符串,右边是整数(右边转换为字符串,返回连接后的字符串)
7. 左边是字符串,右边是实数(右边转换为字符串,返回连接后的字符串)
- 左边是字符串,右边是布尔型(右边转换为内容是 true或 false的字符串,返回连接后的字符串)
9. 左边是字符串,右边是null(右边转换为内容是 null的字符串,返回连接后的字符串)
对于1~4项来说,不只是加法,减法和乘法也都必须进行这样的类型转换 [12],因此单独将评估加法表达式的函数独立出来并不是好的处理方式。crowbar使用 eval_binary_expression()函数对所有的二元运算符进行评估(代码清单3-11),实际上这个函数中已经将同为整数、同为实数的运算单独划分为函数处理了,但代码整体还是很长(虽然有点长不过并不难,请读者尝试阅读一下)。这其中调用的子函数 eval_binary_int()请参考代码清单3-12。
代码清单3-11 eval_binary_expression()
CRB_Value
crb_eval_binary_expression(CRB_Interpreter *inter, LocalEnvironment
env, ExpressionType operator, Expression left, Expression *right)
{
CRB_Value left_val;
CRB_Value right_val;
CRB_Value result;
left_val = eval_expression(inter, env, left);
right_val = eval_expression(inter, env, right);
if (left_val.type == CRB_INT_VALUE
&& right_val.type == CRB_INT_VALUE) {
eval_binary_int(inter, operator,
left_val.u.int_value, right_val.u.int_value,
&result, left->line_number);
} else if (left_val.type == CRB_DOUBLE_VALUE
&& right_val.type == CRB_DOUBLE_VALUE) {
eval_binary_double(inter, operator,
left_val.u.double_value, right_val.u.double_value,
&result, left->line_number);
} else if (left_val.type == CRB_INT_VALUE
&& right_val.type == CRB_DOUBLE_VALUE) {
left_val.u.double_value = left_val.u.int_value;
eval_binary_double(inter, operator,
left_val.u.double_value, right_val.u.double_value,
&result, left->line_number);
} else if (left_val.type == CRB_DOUBLE_VALUE
&& right_val.type == CRB_INT_VALUE) {
right_val.u.double_value = right_val.u.int_value;
eval_binary_double(inter, operator,
left_val.u.double_value, right_val.u.double_value,
&result, left->line_number);
} else if (left_val.type == CRB_BOOLEAN_VALUE
&& right_val.type == CRB_BOOLEAN_VALUE) {
result.type = CRB_BOOLEAN_VALUE;
result.u.boolean_value
= eval_binary_boolean(inter, operator,
left_val.u.boolean_value,
right_val.u.boolean_value,
left->line_number);
} else if (left_val.type == CRB_STRING_VALUE
&& operator == ADD_EXPRESSION) {
char buf[LINE_BUF_SIZE];
CRB_String *right_str;
if (right_val.type == CRB_INT_VALUE) {
sprintf(buf, "%d", right_val.u.int_value);
right_str = crb_create_crowbar_string(inter, MEM_strdup(buf));
} else if (right_val.type == CRB_DOUBLE_VALUE) {
sprintf(buf, "%f", right_val.u.double_value);
right_str = crb_create_crowbar_string(inter, MEM_strdup(buf));
} else if (right_val.type == CRB_BOOLEAN_VALUE) {
if (right_val.u.boolean_value) {
right_str = crb_create_crowbar_string(inter,
MEM_strdup("true"));
} else {
right_str = crb_create_crowbar_string(inter,
MEM_strdup("false"));
}
} else if (right_val.type == CRB_STRING_VALUE) {
right_str = right_val.u.string_value;
} else if (right_val.type == CRB_NATIVE_POINTER_VALUE) {
sprintf(buf, "(%s:%p)",
right_val.u.native_pointer.info->name,
right_val.u.native_pointer.pointer);
right_str = crb_create_crowbar_string(inter, MEM_strdup(buf));
} else if (right_val.type == CRB_NULL_VALUE) {
right_str = crb_create_crowbar_string(inter, MEM_strdup("null"));
}
result.type = CRB_STRING_VALUE;
result.u.string_value = chain_string(inter,
left_val.u.string_value,
right_str);
} else if (left_val.type == CRB_STRING_VALUE
&& right_val.type == CRB_STRING_VALUE) {
result.type = CRB_BOOLEAN_VALUE;
result.u.boolean_value
= eval_compare_string(operator, &left_val, &right_val,
left->line_number);
} else if (left_val.type == CRB_NULL_VALUE
|| right_val.type == CRB_NULL_VALUE) {
result.type = CRB_BOOLEAN_VALUE;
result.u.boolean_value
= eval_binary_null(inter, operator, &left_val, &right_val,
left->line_number);
} else {
char *op_str = crb_get_operator_string(operator);
crb_runtime_error(left->line_number, BAD_OPERAND_TYPE_ERR,
STRING_MESSAGE_ARGUMENT, "operator", op_str,
MESSAGE_ARGUMENT_END);
}
return result;
}
代码清单3-12 eval_binary_int()
static void
eval_binary_int(CRB_Interpreter *inter, ExpressionType operator,
int left, int right,
CRB_Value *result, int line_number)
{
if (dkc_is_math_operator(operator)) {
result->type = CRB_INT_VALUE;
} else if (dkc_is_compare_operator(operator)) {
result->type = CRB_BOOLEAN_VALUE;
} else {
DBG_panic(("operator..%d\n", operator));
}
switch (operator) {
case BOOLEAN_EXPRESSION: / FALLTHRU /
case INT_EXPRESSION: / FALLTHRU /
case DOUBLE_EXPRESSION: / FALLTHRU /
case STRING_EXPRESSION: / FALLTHRU /
case IDENTIFIER_EXPRESSION: / FALLTHRU /
case ASSIGN_EXPRESSION:
DBG_panic(("bad case…%d", operator));
break;
case ADD_EXPRESSION:
result->u.int_value = left + right;
break;
case SUB_EXPRESSION:
result->u.int_value = left - right;
break;
case MUL_EXPRESSION:
result->u.int_value = left * right;
break;
case DIV_EXPRESSION:
result->u.int_value = left / right;
break;
case MOD_EXPRESSION:
result->u.int_value = left % right;
break;
case LOGICAL_AND_EXPRESSION: / FALLTHRU /
case LOGICAL_OR_EXPRESSION:
DBG_panic(("bad case…%d", operator));
break;
case EQ_EXPRESSION:
result->u.boolean_value = left == right;
break;
case NE_EXPRESSION:
result->u.boolean_value = left != right;
break;
case GT_EXPRESSION:
result->u.boolean_value = left > right;
break;
case GE_EXPRESSION:
result->u.boolean_value = left >= right;
break;
case LT_EXPRESSION:
result->u.boolean_value = left < right;
break;
case LE_EXPRESSION:
result->u.boolean_value = left <= right;
break;
case MINUS_EXPRESSION: / FALLTHRU /
case FUNCTION_CALL_EXPRESSION: / FALLTHRU /
case NULL_EXPRESSION: / FALLTHRU /
case EXPRESSION_TYPE_COUNT_PLUS_1: / FALLTHRU /
default:
DBG_panic(("bad case…%d", operator));
}
}
类似这样,在运行表达式评估时,会进行值的类型判定等很多处理,这也就是crowbar这样的无类型语言运行速度慢的原因之一 [13]。
在评估其他表达式时,比较重要的是调用函数。调用函数时会执行 eval_function_call_expression()(代码清单3-13)。
代码清单3-13 eval_function_call_expression()
static CRB_Value
eval_function_call_expression(CRB_Interpreter *inter, LocalEnvironment
env, Expression expr)
{
CRB_Valuevalue;
FunctionDefinition *func;
char *identifier = expr->u.function_call_expression.identifier;
func = crb_search_function(identifier);
if (func == NULL) {
crb_runtime_error(expr->line_number, FUNCTION_NOT_FOUND_ERR,
STRING_MESSAGE_ARGUMENT, "name", identifier,
MESSAGE_ARGUMENT_END);
}
switch (func->type) {
case CROWBAR_FUNCTION_DEFINITION:
value = call_crowbar_function(inter, env, expr, func);
break;
case NATIVE_FUNCTION_DEFINITION:
value = call_native_function(inter, env, expr, func->u.native_f.proc);
break;
default:
DBG_panic(("bad case..%d\n", func->type));
}
return value;
}
这个函数本身只负责将crowbar中的函数和C语言中的函数(内置函数)按条件区分处理。
如果是crowbar 中的函数,会调用 call_crowbar_function()(代码清单3-14)。
代码清单3-14 call_crowbar_function()
static CRB_Value
call_crowbar_function(CRB_Interpreter inter, LocalEnvironment env,
Expression expr, FunctionDefinition func)
{
CRB_Value value;
StatementResult result;
ArgumentList *arg_p;
ParameterList *param_p;
LocalEnvironment *local_env;
/ 开辟空间用于存放被调用函数的局部变量 /
local_env = alloc_local_environment();
/* 对参数进行评估,并存放到局部变量中
arg_p指向函数调用的实参链表
param_p指向函数定义的形参链表 */
for (arg_p = expr->u.function_call_expression.argument,
param_p = func->u.crowbar_f.parameter;
arg_p;
arg_p = arg_p->next, param_p = param_p->next) {
CRB_Value arg_val;
if (param_p == NULL) { / param_p被用尽:说明实参过多 /
crb_runtime_error(expr->line_number, ARGUMENT_TOO_MANY_ERR,
MESSAGE_ARGUMENT_END);
}
arg_val = eval_expression(inter, env, arg_p->expression);
crb_add_local_variable(local_env, param_p->name, &arg_val);
}
if (param_p) { / param_p剩余:说明实参数量不够 /
crb_runtime_error(expr->line_number, ARGUMENT_TOO_FEW_ERR,
MESSAGE_ARGUMENT_END);
}
/ 运行函数内部语句 /
result = crb_execute_statement_list(inter, local_env,
func->u.crowbar_f.block
->statement_list);
/ 如果return语句已经运行,则返回其返回值 /
if (result.type == RETURN_STATEMENT_RESULT) {
value = result.u.return_value;
} else {
value.type = CRB_NULL_VALUE;
}
dispose_local_environment(inter, local_env);
return value;
}
crowbar与C语言一样,是局部变量的生命周期,在函数被销毁时截止(局部变量生成的时机与C语言不同,是在变量被赋值时生成的)。因此在一个函数开始时,需要为这个函数准备一个运行环境,随着赋值开始注册新生成的局部变量,同时在函数结束后将其运行环境一同废弃。按照这个思路,我们为函数的运行环境准备了 LocalEnvironment结构体。
LocalEnvironment结构体的定义如下:
typedef struct {
Variable variable; / 保存局部变量的链表 */
GlobalVariableRef global_variable; / 根据global语句生成的引用全局变量的链表 */
} LocalEnvironment;
Variable是为了保存全局变量而使用的结构体(参考3.3.1节)。该结构体是通过链表构建的,链表内保存了函数内的局部变量。
函数的参数中包含了所有函数内要用到的局部变量,通过调用 call_crowbar_function() 中评估的 crb_add_local_variable() 函数将变量装入 LocalEnvironment。
全局变量在函数内被引用时,crowbar中需要使用 global语句进行声明(参考3.1.4 节)。 LocalEnvironment 结构体的 global_variable 成员中保存了 global语句声明的指向全局变量的引用链表,其类型 GlobalVariableRef的定义如下所示:
typedef struct GlobalVariableRef_tag {
Variable variable; / 指向全局变量 */
struct GlobalVariableRef_tag *next;
} GlobalVariableRef;
GlobalVariableRef 结构体在 global 语句运行时生成,同时被追加到 LocalEnvironment结构体中。
3.3.8 值——CRB_Value
执行表达式评估的函数 eval_XXX_expression(),它的返回值类型为 CRB_Value。 CRB_Value类型的定义如下:
/ 类型的类别枚举 /
typedef enum {
CRB_BOOLEAN_VALUE = 1, / 布尔型 /
CRB_INT_VALUE, / 整数型 /
CRB_DOUBLE_VALUE, / 实数型 /
CRB_STRING_VALUE, / 字符串型 /
CRB_NATIVE_POINTER_VALUE, / 原生指针型 /
CRB_NULL_VALUE / NULL /
} CRB_ValueType;
typedef struct {
CRB_ValueType type; / 这个成员用于区别类型 /
union { / 实际的值保存在联合体中 /
CRB_Boolean boolean_value;
int int_value;
double double_value;
CRB_String *string_value;
CRB_NativePointer native_pointer;
} u;
} CRB_Value;
CRB_Value结构体用于保存crowbar中的每个值,并用枚举型区别值的类型,实际的值最终保存在联合体中。
对于无类型语言处理器来说,通常都需要像这样在值中保存值本身的类型。
3.3.9 原生指针型
原生指针型的值,通过 CRB_Value结构体中的联合体成员 CRB_Native-Pointer类型体现出来,其定义如下所示:
typedef struct {
CRB_NativePointerInfo *info;
void *pointer;
} CRB_NativePointer;
pointer成员是指向一些内部对象的指针。比如可以用原生指针型来做文件指针,此时指针实际会指向 FILE类型。为了可以容纳任何类型的指针,这里特意设置为 void。
另一个成员 info保存了原生指针型的信息,因此原生指针型本身就可以获得自己的类型。如果没有 info成员只保存 void*的话,当错误的类型传递给原生指针型时,内置函数将失去类型检查的方法,引起程序崩溃。作为crowbar的解释器,如果还会被crowbar程序的BUG弄崩溃就有点说不过去了。
info成员的类型 CRB_NativePointerInfo的定义如下所示:
typedef struct {
char *name;
} CRB_NativePointerInfo;
这里的 name 成员中,如果原生指针为文件指针时,成员值为 crowbar. lang.file的字符串。
虽然经过上面的处理,可以对原生指针型进行类型检查,但这还不算是万全之策。比如为 FILE 类型时,一个地方用 fclose() 关闭了文件指针,可能还会在另一个地方被使用。为了规避这种情况,原生指针型不应该直接指向 FILE,而是需要经过一个第三方对象。不过当前版本的crowbar对第三方对象的释放处理仍然存在问题。之后的版本会引入mark-sweep GC,届时这个问题会一并解决,请参考4.4.5节。
3.3.10 变量
我们先后提到了局部变量与全局变量,那么接下来,我再对变量做一些介绍。
变量名在表达式中出现时,通过 eval_expression()(参考代码清单3-10)调用 eval_identifier_expression()(代码清单3-15)。
代码清单3-15 eval_identifier_expression()
static CRB_Value
eval_identifier_expression(CRB_Interpreter *inter,
LocalEnvironment env, Expression expr)
{
CRB_Value v;
Variable *vp;
/ 首先查找局部变量 /
vp = crb_search_local_variable(env, expr->u.identifier);
if (vp != NULL) {
v = vp->value;
} else {
/* 如果没有找到,则通过CRB_Interpreter或LocalEvironment连接
GlobalVariableRef,在其中查找全局变量 */
vp = search_global_variable_from_env(inter, env, expr->u.identifier);
if (vp != NULL) {
v = vp->value;
} else {
/ 仍然没有找到则报错 /
crb_runtime_error(expr->line_number, VARIABLE_NOT_FOUND_ERR,
STRING_MESSAGE_ARGUMENT,
"name", expr->u.identifier,
MESSAGE_ARGUMENT_END);
}
}
refer_if_string(&v); / 这里下文会详述 /
return v;
}
crb_search_local_variable()会从 LocalEnvironment中查找局部变量。另外, crb_search_global_variable()的第二个参数 LocalEnvironment为空的话(即在顶层结构中),会从 CRB_Interpreter中查找。如果两者都没有找到,则从第二个参数 LocalEnvironment连接的 GlobalVariableRef中查找全局变量。
变量赋值时的处理通过 eval_assign_expression() 进行(代码清单3-16)。
代码清单3-16 eval_assign_expression()
static CRB_Value
eval_assign_expression(CRB_Interpreter inter, LocalEnvironment env,
char identifier, Expression expression)
{
CRB_Value v;
Variable *left;
/ 首先评估右边 /
v = eval_expression(inter, env, expression);
/ 查找局部变量 /
left = crb_search_local_variable(env, identifier);
if (left == NULL) {
/ 没有找到则查找全局变量 /
left = search_global_variable_from_env(inter, env, identifier);
}
if (left != NULL) { / 找到变量 /
release_if_string(&left->value); / 本行后文会详述 /
left->value = v; / 在这里赋值 /
refer_if_string(&v); / 本行后文会详述 /
} else { / 因为没有变量,所以新生成 /
if (env != NULL) {
/ 函数内注册局部变量 /
crb_add_local_variable(env, identifier, &v);
} else {
/ 函数外注册全局变量 /
CRB_add_global_variable(inter, identifier, &v);
}
refer_if_string(&v); / 本行后文详述 /
}
return v;
}
赋值处理的流程已经写入注释,其中后文详述的部分会在之后的章节中说明。
当前的语法规则中,赋值表达式的左边必须保证为变量名。如果之后可以使用数组等新语法元素,可能会有下面这样的赋值:
a[b[func()]] = 10;
左边可能为非常复杂的表达式,因此还需要进一步考虑。
3.3.11 字符串与垃圾回收机制——string_pool.c
如上文所写,字符串类型通过 + 连接的同时,需要配合某种垃圾回收机制(garbage collector,GC)。当前版本的crowbar是通过 引用计数 这种原始的垃圾回收机制实现的。
引用计数,即通过管理指向某些对象(这里是字符串)的指针数量,在计数为零时将其释放的回收机制。
crowbar的字符串保存在 CRB_String结构体中。
typedef struct CRB_String_tag {
int ref_count; / 引用计数 /
char string; / 字符串本身 */
CRB_Boolean is_literal; / 是否为字面常量 /
} CRB_String;
这个结构体的 string最终指向存放字符串的区域。
CRB_String会在下列的时机中生成,生成时引用计数被置为1。
字符串字面常量被评估时。
通过 +运算符生成新的字符串时。
通过 +运算符将整数型或实数型转换为字符串类型时。
通过 fget()函数读入文件时。
引用计数为零时回收。此时字符串本身(即 string 成员的指向)一般来说也需要被释放,但如果字符串为字面常量(literal,即被 "" 包裹的出现在crowbar代码中的字符串)则不释放。字面常量不是通过 MEM_malloc()而是通过 MEM_storage_malloc()在 interpreter_storage中开辟的。区别字符串是否为字面常量,通过其成员 is_literal即可,也就是说,字符串字面常量所对应的 CRB_String,生成于赋值表达式的字符串字面常量被评估时,但是其指向的字符串本身,还会在分析树构建时被重复使用。
引用 CRB_String的指针会存在于以下几处地方:
局部变量
全局变量
函数的参数
4. eval.c中的局部变量、参数、返回值等,eval.c运行时的C栈
那么只需要在这些指针被引用时将引用计数自增,引用解除时将引用计数自减即可。
因此,在程序中需要在以下的时机对引用计数进行自增处理(条目编号与上文 CRB_String生成的编号一一对应)。
局部变量被赋值为字符串时。
全局变量被赋值为字符串时。
函数的参数被赋值为字符串时。这里有个例外,如果入口参数为实参时,其表达式评估结束时会伴随一次自减,会与本应进行的计数自增两相抵消。
字符串的变量被评估时。除此之外,当字符串出现在表达式中时,会新生成 CRB_String。
而程序中还需要在以下的时机对引用计数进行自减处理。
存放字符串的局部变量被复写时,以及退出函数,局部变量被释放时。
存放字符串的全局变量被复写时,以及程序运行完毕,全局变量被释放时。
从内置函数退出,释放入口参数时(如果是crowbar函数,入口参数是作为局部变量处理的,此时的处理参考上面的条件1)。
返回字符串的表达式会对其进行表达式/语句评估,评估处理结束时。通过 +运算符对字符串进行连接时。通过比较运算符比较字符串后,两边的字符串需要释放时。
在实际处理中,引用计数的自增通过 refer_if_string()函数实现,其自减则通过 release_if_string()函数(类似这种函数名中有 if_string的函数,仅限于对象为字符串时才会进行处理)实现。参考代码清单3-16可以明显看到:
当变量被复写时,原来变量中字符串的引用计数会自减;
当变量被赋值为字符串时,该字符串的引用计数会自增。
再举一个复杂一点的例子,比如有如下语句时(hoge()函数的返回值为字符串类型):
a = b = c = hoge(“piyo”);
首先,在评估 piyo时生成 CRB_String,引用计数被置为1。将其传递给函数时,由于入口参数为实参,所以会与本应进行的计数自增相抵消,引用计数仍然保持为1 不变。赋值给 c 后计数为2,赋值给 b 后计数为3,最后赋值给 a后计数为4。同时,由于对表达式语句的评估结束,又会进行一次自减,所以计数为3。通过 a、 b、 c3个变量的引用,应用计数最终为3。
但是引用计数这种垃圾回收机制存在一个致命的缺陷,那就是无法释放 循环引用 。
循环引用如图3-5所示,即几个对象之间相互进行引用。
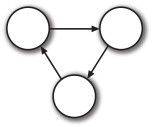
图3-5 循环引用
这种状态下,所有对象的引用计数均为1,因此通过引用计数的方式进行垃圾回收显然是行不通的。其实,如果能控制局部变量和全局变量令其无法引用的话,这种循环引用本来是不应该出现的。也就是说,以引用计数方式进行垃圾回收时,循环引用会引起内存泄漏。
当前的crowbar中,垃圾回收的对象只有字符串一种,而字符串是无法引用其他对象的,所以还不存在循环引用的问题。但是当下几乎所有的实用编程语言,都可以用一个对象保存指向另一个对象的引用,因此如果想扩展并支持这样的功能的话,引用计数式的垃圾回收机制就必须做出改进。
3.3.12 编译与运行
如1.6.2节所写,本书中所涉及的代码都可以在以下URL下载:
http://avnpc.com/pages/devlang#download
将下载的文件解压缩后,进入该文件夹并运行make [14]即可生成执行文件。
本书涉及的程序所需的包也附加在Makefile中了,只是在Windows所用的Makefile中,C编译器名称已经设置为了gcc,make名称也设置为gmake了(参考1.6.1节)。如果你的系统环境不一样的话,请根据实际情况作适当调整。
解压的文件夹中还放入了一个test.crb的示例代码,可以通过下面的指令运行:
% crowbar test.crb
注 释
[2]. 上面的语句在Perl中如果加上 -w 参数并运行的话会出现警告。
[3]. 不过我还是有些介意, Ruby中连类或方法的定义都是动态可执行的,为什么偏偏变量的定义要做成静态的呢。
[4]. 参考URL:http://www. pitecan.com/fugo.html
[5]. 在后面写到的Diksam中,具备与C语言的#include相对应的功能 require,同样由于解析器不能进行递归,会在解析完一个文件后,才开始解析被 require的文件。
[6]. 字符串的加法不会做折叠处理。确实代码中有时候需要有长文本信息,但是按当前版本的处理方式,连接前的字符串是无法被释放的,也就是说其实这里是我偷懒了。
[7]. ISO-C99规范中, auto的数组也可以不是常量。
[8]. 可能很多读者会认为显示错误信息只有英语就足够了,不过对于初级用户来说,英文的错误信息可能有点难以理解吧。更重要的理由是:我觉得自己的英语水平还不够。
[9]. 不过一般公司对于数据的管理都是比较严格的,可能没有办法用U盘携带数据吧。
[10]. 只适用于运行出错。如果是编译出错,则调用 crb_compile_error()。
