6.3 Diksam ver.0.1的实现——编译篇
6.3.1 目录结构
Diksam为了使编译器与执行器(DVM)分离,使用了以下的目录(directory)结构。
compiler
包含Diksam的编译器代码。函数名等的前缀为 DKC, main()函数暂时放在这里面。
dvm
包含Diksam的执行器(DVM)代码。函数名等的前缀为 DVM。
share
包含compiler、dvm两个模块共享的代码。函数名等的前缀为 dvm。
严格来说,这里打破了命名规则,这是因为考虑到是否要给只在编译器和DVM中使用的代码加一个公共的前缀,还有编译器也是依赖DVM的。
include
包含在多个目录中被引用的头文件。
memory
在介绍crowbar的时候,在3.2.2节中制作的内存管理的库。函数名等的前缀为 MEM。
debug
在介绍crowbar的时候,在3.2.2节中制作的用于调试的库。函数名等的前缀为 DBG。
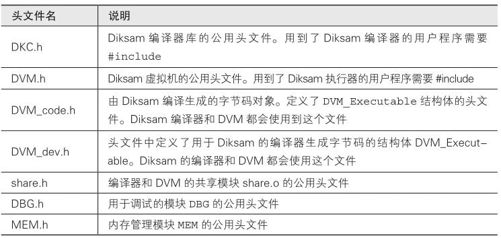
在表6-2中描述了include中包含的头文件。
表6-2 头文件一览表
6.3.2 编译的概要
编译按照下面的顺序进行。
1. 构建分析树
在create.c中实现。
2. 修正分析树
在这个阶段中进行的操作有,为表达式分析树中的各节点加入类型,如果存在不同类型间的运算时加入转换节点,将表达式中用到的变量与其声明绑定。
上述操作会尽量在构建分析树的同时完成,实在不行的话也会在其他阶段中进行。此阶段(也就是所谓的“语义分析”阶段)会在fix_tree.c中执行。
3. 生成字节码
以自上而下的顺序遍历分析树生成字节码。在generate.c中实现。
6.3.3 构建分析树(create.c)
构建分析树其实跟crowbar相比没有什么变化。如果一定要说有什么不同的地方,也只能讲讲“程序块”的处理了。
Diksam局部变量的作用域在它声明的程序块中。
比如,表达式中使用了叫作 a的变量时,编译器会首先探测最内层的程序块中是否声明了 a,如果没有,再逐个探测外层的程序块。为了实现这种处理方式,在程序块的结构体中包含了 outer_block成员。
typedef struct Block_tag {
BlockType type;
struct Block_tag *outer_block; ←这个
StatementList *statement_list;
DeclarationList *declaration_list;
union {
StatementBlockInfo statement;
FunctionBlockInfo function;
} parent;
} Block;
outer_block保存了外层程序块的指针。
为了设定 outer_block,在 Block结构体创建实例的同时,必须要知道哪个是当前程序块(新创建的程序块的外层程序块)。因此,在编译器本体(DKC_Compiler)中保存了 current_block。
struct DKC_Compiler_tag {
MEM_Storage compile_storage;
FunctionDefinition *function_list;
int function_count;
DeclarationList *declaration_list;
StatementList *statement_list;
int current_line_number;
Block *current_block; ←这个
DKC_InputMode input_mode;
Encoding source_encoding;
};
设定这个 current_block 的时机是在程序块开始的时候(解释器读取到 {的时候)。
比如在crowbar中crowbar.y有如下代码。
block
: LC statement_list RC
{
$$ = crb_create_block($2);
}
| LC RC
{
$$ = crb_create_block(NULL);
}
;
这个方法在程序块结束的时候没有任何动作。
为了能够设置 current_block,我们要在 diksam.y 里的规则中插入动作。
/ 总之还是想要实现"LC statement_list RC" /
block
: LC
{
$$ = dkc_open_block();
}
statement_list RC
{
$$ = dkc_close_block($<block>2, $3);
}
还是有"LC RC"的规则,这里省略了。
这样的动作被称为 嵌入动作 。
yacc在处理嵌入动作的时候,会嵌入一个虚拟的目标。嵌入动作将被作为这个虚拟目标的动作进行处理。即为:
block
: LC {嵌入动作} statement_list RC
{
程序块结束时触发的动作。
}
;
上面这段代码,等同于下面的代码。
block
: LC dummy_target statement_list RC
{
程序块结束时触发的动作。
}
;
dummy_target
:
{
嵌入动作
}
;
虚拟目标部分并没有声明类型,(如果想要使用的话)嵌入动作中向 $$设定的值,记作 $<类型>序号。前面写到的diksam.y中向 dkc_close_block()传递的参数 $<block>2, $3,其中 $<block>2 就是嵌入动作中向 $$ 设定的值, statement_list就变成 $3了(由于加入了嵌入动作,向后移动了一个 [6])。
6.3.4 修正分析树(fix_tree.c)
在fix_tree.c中将会扫描create.c生成的分析树,并进行错误检查、添加数据类型、将表达式中的标识符与声明绑定这些操作。
下面的项目将要说明的是这些操作的具体内容。
常量表达式的包装
这个操作在crowbar 中已经存在了,Diksam 表达式中的常量表达式(像 24 * 60这样的表达式)在编译时就会被包装为常量。
在现在的Diksam 中,以数值的加减乘除和模、 + 进行的字符串连接、单目减号、比较、单目!为对象。
为表达式添加类型
在Diksam表达式的分析树中,每个节点都保存着自己的类型。在Diksam编译器中定义了用来表示表达式的结构体(见下面代码,diksamc.h)。
struct Expression_tag {
TypeSpecifier *type; ←这里保存类型
ExpressionKind kind; ←用kind表示表达式的类别
int line_number;
union { ←以共用体的形式保存类别对应的值
DVM_Boolean boolean_value;
int int_value;
double double_value;
DVM_Char *string_value;
IdentifierExpression identifier;
CommaExpression comma;
AssignExpression assign_expression;
BinaryExpression binary_expression;
Expression *minus_expression;
Expression *logical_not;
FunctionCallExpression function_call_expression;
IncrementOrDecrement int_dec;
CastExpression cast;
} u;
};
比如 3 这样的整数值节点被定为 int 型, int 型变量的类型也被定为 int型,但是像 (1 + 0.5)这样的表达式就要同时分析表达式左边和右边的情况来适当地扩展类型。
看了 Expression结构体的定义可能就会明白,这个结构体的 type成员保存了表达式的类型,它所指向的结构体 TypeSpecifier的定义如下(定义在/include/DVM/DVM_code.h中)。
struct TypeSpecifier_tag {
DVM_BasicType basic_type;
TypeDerive *derive;
};
枚举类型DVM_BasicType的定义如下所示。
这个枚举类型能够表示所有“基本类型”。
typedef enum {
DVM_BOOLEAN_TYPE,
DVM_INT_TYPE,
DVM_DOUBLE_TYPE,
DVM_STRING_TYPE
} DVM_BasicType;
另外一个成员 derive以“派生类型”的方式表示,相关的定义如下(类型定义保存在diksamc.h中,但是在DVM_code.h中也有与其相似的定义,两者之间的关系将在后面的章节中介绍)。
typedef enum {
FUNCTION_DERIVE
} DeriveTag;
typedef struct {
ParameterList *parameter_list;
} FunctionDerive;
typedef struct TypeDerive_tag {
DeriveTag tag;
union {
FunctionDerive function_d;
} u;
struct TypeDerive_tag *next;
} TypeDerive;
struct TypeSpecifier_tag {
DVM_BasicType basic_type;
TypeDerive *derive;
};
枚举类型 DeriveTag 是一种派生类型的表现。在现在的Diksam 中还没有数组之类的类型,目前存在的派生类型只有函数类型(FUNCTION_DERIVE)。函数(派生类型)的定义保存在 FunctionDerive中,具体来说就是参数的类型信息。
到底什么是派生类型?这个话题在《征服C指针》中已经举例做了大致地说明 [7]。比如Diksam的 print()函数,它的定义就成了下面这样。
int print(string str);
此时,被称为 print的标识符的类型就是“返回 int的函数(参数为 string类型)” [8]。在应用了函数调用运算符 ()后,可以把“函数(参数为 string类型)”这部分看作是 int型。
因为 TypeDerive包含了成员 next,所以这个派生类型可以用链表形式链接。因此,可以表示为“返回‘返回 int的函数(参数为 string类型)’的函数(无参数)” [9]。如果把数组也看作是派生类型的一种,那么可以表示为“返回‘ int的数组的数组’的函数(参数为 string类型)”。
说起来,现在还不能声明“函数型的变量”,也没有数组。因此,现阶段函数调用的语法规则如果像下面这样定义的话,就没有必要表现为派生类型了。但是因为在下一个版本中考虑到要引入数组,所以进行了如下实现。
primary_expression
: IDENTIFIER LP parameter_list RP
;
增加转换节点
在为表达式添加类型的过程中,会加入如6.2.3节中说明的转换节点。当前编译时默认执行的类型转换如下所示。
双目运算中的类型转换
int和 double在运算时会将 int转换为 double。
还有,左边是 string类型的运算时,会把右边转换为 string。
赋值时的类型转换
赋值时,会根据左边调整右边的类型(+=之类的赋值运算符也是一样)。对于函数的实际参数以及参数的返回值在赋值时也进行同样的转换处理。
函数内的变量声明
在处理 int a;这样的声明语句时,在create.c的阶段会创建 Declaration结构体,其定义如下。
typedef struct {
char *name;
TypeSpecifier *type;
Expression *initializer;
int variable_index;
DVM_Boolean is_local;
} Declaration;
在create.c 的阶段, Declaration 结构体中设置了变量名(name)、类型(type)以及构造函数(initializer)。
由于声明是语句的一种,在 Declaration 结构体中以成员方式保存着 Statement结构体的共用体,但是在fix_tree.c中就另当别论了。fix_tree.c中将 Declaration结构体链接成了一个链表。
/ 将Declaration结构体连成链表的结构体 /
typedef struct DeclarationList_tag {
Declaration *declaration;
struct DeclarationList_tag *next;
} DeclarationList;
在函数以外的变量声明通过链表 DeclarationList保存在 DKC_Compiler中。与此相对,在函数内声明的变量的作用范围是程序块,因此 DeclarationList保存在程序块(即Block)中。
在6.3.3节中讲过,表示程序块的Block结构体的声明,在其中的declaration_list中保存了当前程序块中的声明。
函数的形式参数由于可以被当做函数内的局部变量来使用,因此这些变量的声明被设置在了函数最外层的程序块中。接下来要加入的是局部变量。
与此同时,将对 Declaration 结构体中还没有设置的 variable_index和 is_local进行设置。
is_local用来表示是否有局部变量的标识,在函数内声明变量的同时设置其值, variable_index为函数内声明的局部变量分配编号(最初的形式参数为0)。
局部变量(包括参数)在栈中被创建,栈中的变量可以使用基于 base的偏移量进行引用,具体请见6.2.5 节。 variable_index 就是这个“偏移量”,但是这里稍微有点复杂。
接下来我们看一下Diksam 的栈,它实现了 DVM_Value 类型的数组,并且这个数组可以继续增大下标进行扩展。Diksam此时的状态如图6-5。
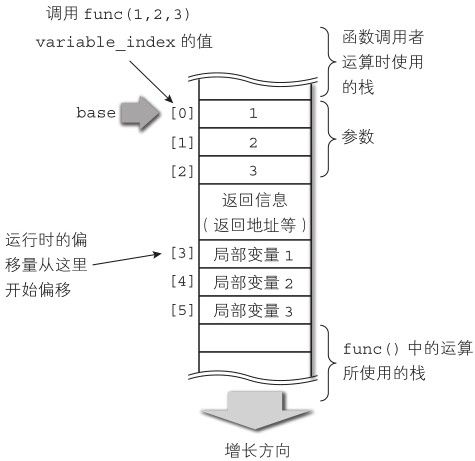
图6-5 Diksam的栈
在现阶段的编译器实现中, variable_index从第一个形式参数开始顺序增长,其中并没有将返回信息考虑进去。因此, variable_index和运行时的偏移量只能直接偏移到返回信息下面的局部变量。
当然,因为已知返回信息的字节大小,所以对于局部变量来说,加上它的大小后继续编号并非难事。但是,返回信息的字节大小依赖于DVM的实现,因此我想尽力避免将依赖于返回信息的值嵌入到字节码中。
最重要的是,现在的字节码只生成在内存中,并没有以文件等形式保存起来,因此即使嵌入了(返回信息的值),实际上也没有什么坏处。但如果将来要生成与Java的class文件类似的产出物时,可能就会出现问题。随着DVM版本升级,返回信息的字节大小也会随之发生变化,会出现之前编译的文件在新版DVM中不能运行的困扰。
于是,Diksam编译器姑且先生成连续的编号,在执行前(加载DVM之后)再进行转换(请参考6.4.1节的小标题3)。
话说回来,因为Diksam中变量的作用域是程序块,因此在下面这段代码生成字节码的时候, a和 b如果分配的是同一个内存空间(同一个 variable_index)的话,就可以节约栈空间了,因此在Diksam中的这种情况下会为它们单独生成索引。
if (a == 10) {
int a;
…
}else {
double b;
…
}
Diksam会为没有初始化的局部变量决定取值,不会出现像C那样的不定值。在调用函数的时候,处理器会用0或者 null之类的值为变量初始化。此时,虽然a和b都处于同一内存空间,但是由于类型不同,因此它们不能够用同样的位模型进行初始化。
标识符和声明的绑定
在表达式中保存变量或者函数名的,是保存在 Expression结构体中的共用体成员 IdentifierExpression结构体。
typedef struct {
char *name;
DVM_Boolean is_function;
union {
FunctionDefinition *function;
Declaration *declaration;
} u;
} IdentifierExpression;
这里的 function或者 declaration中存放的是函数定义或者变量声明。
在搜索局部变量的时候,会在与“当前程序块”相互连接的 Declaration结构体中搜索,因此, ifx_xxx系列的函数会把当前程序块作为参数传递进来。
6.3.5 Diksam的运行形式——DVM_Executable
虽然总算能通过fix_tree.c生成字节码了,但是对于程序的运行来说不只需要字节码,还需要全局变量列表等必不可少的信息。在Diksam中定义了名为 DVM_Executable的结构体用来保存字节码和刚才提到的那些相关信息,generate.c的全部使命就是创建 DVM_Executable结构体。
因此,首先要用下面这段代码来说明一下 DVM_Executable 结构体(DVM_code.h)。
struct DVM_Executable_tag {
int constant_pool_count;
DVM_ConstantPool *constant_pool;
int global_variable_count;
DVM_Variable *global_variable;
int function_count;
DVM_Function *function;
int code_size;
DVM_Byte *code;
int line_number_size;
DVM_LineNumber *line_number;
int need_stack_size;
};
如代码所示,利用可变长数组保存以下信息。
1. 常量池(constant_pool)
保存常量的内存空间。
2. 全局变量(global_variable)
保存全局变量列表。
3. 函数(function)
保存函数定义。将函数里要执行的语句的字节码保存在其内部(DVM_Function结构体)。
4. 顶层结构的代码(code)
因为Diksam可以在顶层结构中书写代码,此成员用来保存这些代码生成的字节码。
5. 行号对应表(line_number)
保存字节码和与之对应的源代码的行号。
6. 栈的需要量(need_stack_size)
保存顶层结构的代码对栈的需要量。
每个函数对栈的需要量都保存在各自的 DVM_Function中。
6.3.6 常量池
保存常量的内存空间被称为“常量池”。
比如,将 double值2.5入栈的时候,Diksam的字节码表示为:
push_double 2.5
在实际输出字节码的时候,命令 push_double 应该会被分配到某个代号(编号)。在DVM中会分配到十进制的6,因此,6被作为一个字节输出到字节码中。那么2.5该怎么办呢?在我的环境中double占8个字节,因此在6后面应该紧接着输出这8个字节。
老实说,因为现在的Diksam只在内存中保存字节码,编译器环境中 double型的字节表现可以直接输出到字节码中。但是,如果将字节码输出到文件的时候就会出问题了。这是因为执行字节码的机器和编译字节码的机器可能会用不同的形式表示 double型数据 [10]。
“字节码中以某种正规化的表现方式进行保存,读取的时候再进行转换。”在进行这个处理的时候,如果字节码中间突然出来一个要转换的2.5,那么处理起来会很麻烦。另外,不止是实数,字符串也是一样,如果在字节码中突然出现了一个嵌入的“hello, world\n”,这在普通的程序员看来也没那么美观吧。
因此我们在这里使用了常量池。常量池数组中的各个元素组成了下面的结构体。
typedef enum {
DVM_CONSTANT_INT,
DVM_CONSTANT_DOUBLE,
DVM_CONSTANT_STRING
} DVM_ConstantPoolTag;
typedef struct {
DVM_ConstantPoolTag tag;
union {
intc_int;
double c_double;
DVM_Char *c_string;
} u;
} DVM_ConstantPool;
如上面代码所示,把保存 int、 double或者字符串的成员定义为一个共用体。
在Diksam的字节码中,下列常量不会被嵌入到其中,而是保存到常量池。字节码中只保存常量池中对应的索引值。
负数或者65536以上的整数
0或者1以外的实数
字符串
1~2字节的整数以及实数0或者1使用下列命令进行处理。
push_int_1byte
在字节码上用这个命令将其后的1个字节作为整数保存。
push_int_2byte
在字节码上用这个命令将其后的两个字节作为整数并以大尾序保存。
push_double_0
实数运算中出现0的时候使用此命令(这里效仿了JVM)。
push_double_1
实数运算中出现1的时候使用此命令(这里也效仿了JVM)。
前面提到过字节码中只保存着常量池中用来引用常量的索引值,因为1个字节存不下这个索引值,所以现在Diksam在实现时使用了两个字节,如果使用 push_double 这样的命令会将其后的两个字节的整数值以大尾序保存起来。可是,两个字节是否就够用了呢?这是最大的悬念。实际上这里也是在效仿JVM,我想可能修正一下这里会更好。
另外,相同的常量在程序中多次出现的时候,虽然在常量池上分配同样的入口可以节约常量池的内存空间,但是现在的Diksam没有这么做。这里照例只是偷了个懒而已。
补充知识 YARV的情况
Diksam将一部分常量的值保存到了常量池中。这个结构体实际上是效仿JVM,但是在Ruby的VM,也就是YARV(Yet Another Ruby VM)中,就把常量值嵌入到了字节码中。
这么做的理由是,像常量池这样把常量值保存在其他地方并通过配置索引指定操作数的方法,可能会对性能产生不利的影响 [6] (因为是间接访问)。
还有,在 YARV 中的指令不止 1 字节,在处理器中为其分配了 1个 int 的大小(这意味着YARV的指令不是一个严格的“字节码”)。虽然可惜了这些内存,但是对速度还是非常有利的。
Diksam如果真的考虑性能的话,也许应该向YARV学习一下 [11]。
6.3.7 全局变量
DVM_Executable 结构体的 global_variable 成员,就如同其字面的含义表示的是全局变量。从字节码引用全局变量的时候,就会使用到这个 DVM_Variable型的数组的索引。
比如,将整数型的全局变量的值 push 到栈中的命令是 push_static_int。
使用上述命令,将其后的两个字节以大尾序存入数组中并延续索引编号。
DVM_Variable的定义如下。
typedef struct {
char *name;
DVM_TypeSpecifier *type;
} DVM_Variable;
一目了然,这里表示的是全局变量的名称和类型。
全局变量的类型是为了在开始运行的时候进行初始化以及垃圾回收时使用的。
变量名到目前为止还没有用到。前面也提到过,利用索引从字节码中引用全局变量。但是我想,在实现调试器的时候,变量名是一个必要的信息。
另外,使用 DVM_TypeSpecifier 结构体来保存全局变量的类型。在编译时类型信息被保存到类型信息 TypeSpecifier 结构体中。也就是说,在generate.c中实现从 TypeSpecifier结构体到 DVM_TypeSpecifier结构体的复制。
6.3.8 函数
表示函数的结构体 DVM_Function,其定义如下所示。
typedef struct {
DVM_TypeSpecifier *type;
char *name;
int parameter_count;
DVM_LocalVariable *parameter;
DVM_Boolean is_implemented;
int local_variable_count;
DVM_LocalVariable *local_variable;
int code_size;
DVM_Byte *code;
int line_number_size;
DVM_LineNumber *line_number;
int need_stack_size;
} DVM_Function;
type是返回值的类型,name是函数名。 parameter和 local_variable用下面给出的结构体保存名称和类型。类型是在初始化局部变量时使用的,但是现在还没有用到。
typedef struct {
char *name;
DVM_TypeSpecifier *type;
} DVM_LocalVariable;
在 DVM_Function 中的 is_implemented 是一个标志。它表示“这个函数是否在这个 DVM_Executable中实现”。
比如 print() 函数由原生函数组成,使用者编写的 Diksam 程序中并没有对其进行过定义,因此,这个函数对应的 DVM_Function 的 is_implemented为 false。即使是这样的函数也要被登记到 DVM_Function的对应表中,因为在函数调用的时候必须要通过 DVM_Function对应表中的索引值。
DVM_Function结构体的成员,指针 code指向该函数对应的字节码。
6.3.9 顶层结构的字节码
DVM_Executable结构体的成员,指针 code指向顶层结构对应的字节码。关于如何生成字节码将在6.3.12节中作介绍。
6.3.10行号对应表
对于执行字节码的语言来说,发生错误时,如果不能提示发生的错误在源文件中的行号,对于使用者来说就太不友好了。因此, DVM_Executable的成员 line_number保存了字节码上的位置对应的源文件的行号。
这种对应关系的类型用 DVM_LineNumber结构体表示,定义如下。
typedef struct {
int line_number;/ 源代码的行号 /
int start_pc;/ 字节码的开始位置 /
int pc_count;/ 从start_pc开始,接下来有几个字节的指令对应着同一line_number /
} DVM_LineNumber;
上述信息,在generate.c 的 generate_code() 函数中与字节码同时生成。因为1行源代码通常会生成多个指令,所以在为同一行源代码生成编码时,不增加 DVM_LineNumber对应表的元素,只增加 pc_count。
这里只保存了顶层结构的行号对应表,函数内的行号保存在各自的 DVM_Function对应表中。
6.3.11 栈的需要量
在crowbar中,在每次进行入栈操作时,都会检查栈的空间。只要空间不足就会用 realloc()进行扩展。
但是,Diksam是执行字节码的语言,因此我们对它的执行速度还是有所期待的,所以我们在这里要避免“每次都进行栈空间检查”的做法。
因此,在 DVM_Executable的成员 need_stack_size中保存了顶层结构所需的栈空间大小。各函数需要的栈空间大小保存在 DVM_Function对应表中。
这里的重点是:不论是顶层结构还是函数,它们所需要的栈空间大小都是在编译时决定的。
虽然在前面已经提到过,但是在这里还要再说一下,DVM将完全信任编译器生成的字节码。另外,Diksam的编译器绝对不会生成下例这样的字节码。
10 push_int_1byte 5
12 jump 10
在这个例子中,会无限循环地将5入栈,直到内存溢出。但是,Diksam从语法上就杜绝了编写这种(能生成类似于上述例子中字节码的)源代码的可能。因此,扫描全部 push系列的指令,并计算出push所需内存总量,用此方法就可以计算出顶层结构或者各函数所需的栈空间的大小了(在现在的实现中,并没有把出栈的内存计算在内,因此这个值会略大一些,但是多一些的空间并不会造成问题,所以就保持现状了)。各个指令消耗的栈空间量将会保存在 dvm_opcode_info数组中(请参考6.3.12节)。
基于上述做法,检查栈大小有以下两个最佳时机。
程序开始执行时,检查栈空间是否能满足顶层结构的需要。
函数开始执行时,检查栈空间是否能满足这个函数的需要。在出现深层递归需要消耗大量栈空间的情况下,会数度进行检查,对栈空间的需求也会迅速地增长。
6.3.12 生成字节码(generate.c)
对于生成字节码来说,大部分麻烦事已经在fix_tree.c中做完了,因此generate.c要做的事情,大概就只剩下“按照自上而下的顺序遍历分析树然后吐出字节码”了。
下面我们就来看一下到底要“吐出”的是什么样的字节码。
字节码的结构
在这个小节我将整理出至此为止一直没有明确的字节码的结构。
字节码由命令(指令,instruction)和操作数(operand)组成。
操作数可以想成是C 等语言中函数的参数。比如在例子 push_int 10 中push_int指令处理了一个操作数,这个指令的操作数是常量池中的索引值,这个值是10。
Diksam的字节码以字节为单位(否则就不能叫“字节码”了)。指令也用一个字节来表示。
还是以上面的例子来说, push_int 对应的值是3。这里用枚举类型 DVM_Opcode来表示(DVM_code.h)。
typedef enum {
DVM_PUSH_INT_1BYTE = 1,
DVM_PUSH_INT_2BYTE,
DVM_PUSH_INT, ←这个是push_int(也就是3)
DVM_PUSH_DOUBLE_0,
DVM_PUSH_DOUBLE_1,
DVM_PUSH_DOUBLE,
DVM_PUSH_STRING
(中间省略)
} DVM_Opcode;
操作数有以下三种。
1个字节的整数。直接保存跟在指令后面的操作数。
两个字节的整数。把跟在指令后面的操作数作为大尾序保存。
常量池的索引值。该值现在是两个字节,把跟在指令后面的索引值作为大尾序保存。
什么样的命令处理什么样的操作数都定义在了/share/opcode.c中。
OpcodeInfo dvm_opcode_info[] = {
{"dummy", "", 0},
{"push_int_1byte", "b", 1},
{"push_int_2byte", "s", 1},
{"push_int", "p", 1},
{"push_double_0", "", 1},
{"push_double_1", "", 1},
{"push_double", "p", 1},
{"push_string", "p", 1},
(以下省略)
这个数组用于调试时反编译功能(disassemble.c)之外的必须顺序分析字节码的情况。
这里的 b代表1个字节的整数, s代表两个字节的整数, p代表常量池的索引值。在表示字符串的时候,必须要使用取得多个操作数的指令。接下来的0和1的数值就是它们指令本身所需的栈空间。请参考6.3.11节。
生成字节码
为了生成字节码,在generate.c中包含了以下函数。
static void
generate_code(OpcodeBuf *ob, int line_number, DVM_Opcode code, …)
这个函数在获取指令和行号的同时,采用可变长参数来传递操作数。使用的例子如下。
/* 生成push_int的代码。
- cp_idx是常量池的索引值。
*/
generate_code(ob, expr->line_number, DVM_PUSH_INT, cp_idx);
6.3.13 生成实际的编码
本节将要介绍Diksam源代码的组成元素实际会转换成什么样的字节码。
标识符
标识符有以下几种。
局部变量
全局变量
函数
局部变量(是左值的情况下)将会生成如表6-3的字节码。操作数全部用两个字节的整数、栈上的索引值(基于base的偏移量)表示。
表6-3 局部变量相关的指令

这三个指令只是针对不同的类型,但做的事情都一样。在枚举类型 DVM_Opcode中,指令以 int、 double、 string的顺序排列,因此生成字节码的操作可以用如下的方式进行。
/ push_stack_int /
generate_code(ob, expr->line_number,
DVM_PUSH_STACK_INT
- get_opcode_type_offset(expr->u.identifier
.u.declaration
->type->basic_type),
expr->u.identifier.u.declaration->variable_index);
get_opcode_type_offset() 函数,如果参数是 boolean 或者 int 则返回0。如果是 double则返回1, string则返回2 [12]。
当参数是 boolean 的时候也返回 0,这是因为虽然在 Diksam 语言中有 boolean类型,但是DVM中并没有 boolean类型,所以用 int代替。
在全局变量中使用 push( 类型名)_static 指令代替 push( 类型名)_stack指令。操作数是全局变量的索引值。
在函数的情况下,根据 push_function 的索引(DVM_Function 数组的下标)入栈,但是在执行时被改写成了别的方式。详细请参考6.4.1节。
双目运算符
双目运算符生成的指令如表6-4所示。表中 (类型)的部分,请看作是 int、double或者 string,但是string只有相加和比较的运算。
表6-4 双目运算符的指令
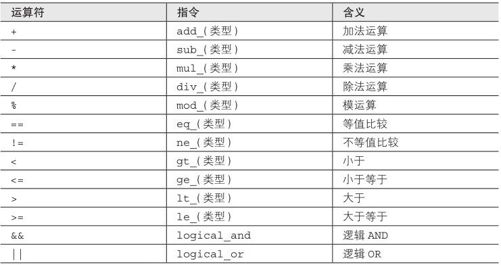
这些指令没有操作数。
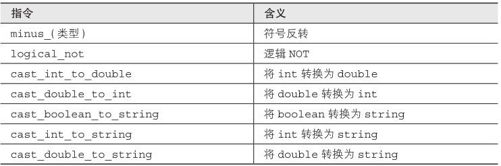
单目运算符
单目运算符有单目的减号和逻辑非(!)。也可以把类型转换看作是一种单目运算符(目前会由编译器自动插入)。
单目运算符的指令如表6-5所示。
表6-5 单目运算符的指令
赋值
现阶段的Diksam中还没有数组和对象的成员,因此赋值必然是以“ 变量名 = 表达式; ”的形式。
所以,我们首先计算右边,其结果值可以从栈中取得后,使用 pop_stack_xxx或者 pop_static_xxx让变量出栈。
与C语言相同,Diksam的赋值本身也是在获取表达式的值(因此也有可能出现像 a = b = c;这样的赋值方式)。也就是说,在赋值结束后,栈上肯定会留下一个值。计算右边的值,在出栈赋给变量后栈上就没有值了,因此需要使用 duplicate指令复制栈顶的值并将其入栈。
但是,实际上很少有人会写 a = b = c;这样的赋值语句(也可以说是因人而异吧),大部分的情况没有必要特意使用 duplicate复制栈上的值。
因此,生成赋值表达式的时候,要把“这个表达式是否是表达式语句的顶级表达式”作为标识进行传递,如果(当前表达式)是表达式语句的顶级就不需要使用 duplicate了。
函数调用
再看一下图6-5中的例子,Diksam中函数调用时,栈会像图6-6所示进行增长。
首先,按照从前向后的顺序对参数进行计算,并将其入栈(Diksam中没有可变长参数,因此没有必要像C语言一样从后面开始入栈)。
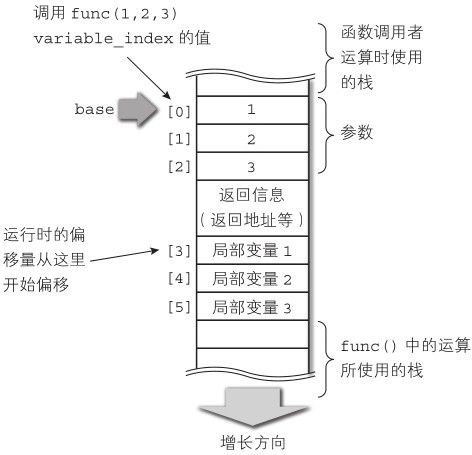
图6-6 函数调用时的栈
接着,将“函数”入栈(这个“函数”其实是 DVM_VirtualMachine 结构体中 Function 的索引值。详细请参考6.4.1 节)。正如前面写到的,Diksam中调用函数使用 () 运算符,函数名本身就是一个表达式。使用 push_function将这个表达式的值入栈。
然后,执行 invoke,从而执行被调用的函数。 invoke 将保存着 push_function的值从栈中移出,创建承载着返回信息的局部变量的内存空间,并让开始函数执行其一系列动作。
详细请参考6.4.3节。
控制结构
如6.2.4节中所述,像 if语句这样的控制结构在字节码中是使用跳转命令来实现的。
为了实现跳转,就必须要知道跳转目标的地址。这里说的“地址”是指在 DVM_Executable中的每个函数,或者是保存在顶层结构中的字节码的数组(DVM_Byte *code)的下标。
比如有下面这样一段代码。
int a;
if (a == 0) {
a = 1;
} else {
a = 5;
}
编译后生成如下字节码。
0 push_static_int 0 # 将变量a的值入栈
3 push_int_1byte 0 # 将0入栈
5 eq_int # 比较
6 jump_if_false 17 # 如果不相等则跳转到17
9 push_int_1byte 1 # 为了赋值将1入栈
11 pop_static_int 0 # 将1出栈赋值给a
14 jump 22 # 跳到22(这段代码的末尾)
17 push_int_1byte 5 # 为了赋值将5入栈
19 pop_static_int 0 # 将5出栈赋值给a
这段代码中,最左边的数字就是“地址”。为了迎合机器语言中的说法,某些特定的地址使用“地址码XX”的说法表示。
在上面的例子中, a和0比较后,在地址码6的地方判断如果相等就跳转到地址码17。但是问题在于,在地址码6 的 jump_if_false 命令生成的时候,还不知道要跳转的目标就是“地址码17”。
因此,Diksam的编译器采用了以下的方法。
1. 跳转命令等在必须使用地址的时候,使用 get_label()函数取得一个“标签”。 这里取得的“标签”是指,标签对应表的下标。
2. 字节码生成的最初阶段,在要写入跳转目标地址的地方写入暂定的标签。
确定下来标签要代替的位置的地址后,使用 set_label()函数,将地址存入标签对应表。
字节码全部生成后,根据标签对应表,将写入暂定的标签的地方替换成真正的地址。
