9.1 为crowbar引入对象和闭包
在第8章中为Diksam引入了类,但是目前的crowbar还不支持面向对象功能。
而在当今的编程语言中,大有如果不支持面向对象就不会被认可的架势,因此也要让crowbar支持面向对象。
但是,crowbar的面向对象与Diksam、C++、Java、C#等相比会有一些不同。它没有类的概念。
本节将要介绍的,就是crowbar的面向对象具体是怎样设计和实现的。
9.1.1 crowbar的对象
像前面提到的,crowbar中没有类的概念。因此,创建对象的时候也不需要指定类和使用 new指令,只是单纯地调用原生函数 new_object()即可。
o = new_object();
crowbar中的对象与C对象的结构体相同,也可以保存 成员 。但是,由于没有类声明也没有结构体声明,因此成员将在运行时以赋值的方式增加。
p = new_object();
p.x = 10;
p.y = 20;
print("p..(" + p.x + "," + p.y + ")\n");
肯定有人会说(我必须承认我也是其中一员):“没有类型声明感觉真是别扭。”但起码这个方式实现了类似C的结构体的功能。
并且,与 Diksam、Java 一样,这个对象也是引用类型的,使用 new_object()返回了一个指向对象的引用。因此,下面的代码将输出20。
o1 = new_object();
o1.hoge = 10;
o2 = o1;
o2.hoge = 20;
print(o1.hoge);
上面这段代码的内存映像如图9-1所示。
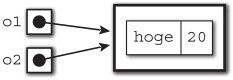
图9-1 crowbar的对象是引用类型
9.1.2 对象实现
首先,关于“对象”这个词无论是在crowbar中还是在Diksam中,都是指“在堆中被创建的”字符串、数组、类的“对象”。像crowbar 的 CRB_Object、Diksam的 DVM_Object结构体,这些都是通过共用体保存的“在堆中被创建的对象”。
在Diksam中,堆中类的实例的对象被称为“类对象”或者“类的实例”。但是,crowbar中并没有类的概念。
对于使用者来说,应该把数组叫作数组,把字符串叫作字符串才对吧。因此, new_object() 函数返回的也应该叫作“对象”。但是,从crowbar 的实现上来看,由于已经引入了叫作 CRB_Object 的结构体,因此不得不给 new_object()返回的东西起一个其他的名字。
这里把这个东西叫作assoc。assoc是关联数组(associative array)的简称。
之所以被称为关联数组(最近不知道为什么有很多语言叫它“哈希” [1]),是因为它是可以以字符串(等)为键从中取出值来的数组。正是由于可以以字符串为键取值这点,crowbar的对象最终使用了关联数组的方式 [2]。
assoc的结构体定义如下(crowbar.h)。
typedef struct {
char *name;
CRB_Value value;
CRB_Boolean is_final; ←现阶段不需要在意它。
} AssocMember;
struct CRB_Assoc_tag {
int member_count;
AssocMember *member;
};
assoc的成员是名称和值的组合,因此assoc中只保存了 AssocMember的可变长数组。 AssocMember中的 is_final是个谜一样的成员,因为它是一个不能赋值的局部变量,所以现阶段不需要在意它。
在现在的实现中,每次增加成员都会使用 realloc() 来扩展可变长数组,并且以线性的方式搜索。当然它的速度不快,这时候只要拿出富翁式编程的免死金牌来就好了。
因为要引用assoc,所以要修改 CRB_Object。
typedef enum {
ARRAY_OBJECT = 1,
STRING_OBJECT,
ASSOC_OBJECT, ←增加了这行代码
SCOPE_CHAIN_OBJECT, ←将在后面说明
NATIVE_POINTER_OBJECT,
OBJECT_TYPE_COUNT_PLUS_1
} ObjectType;
struct CRB_Object_tag {
ObjectType type;
unsigned int marked:1;
union {
CRB_Array array;
CRB_String string;
CRB_Assoc assoc; ←增加了这行代码
ScopeChain scope_chain; ←将在后面说明
NativePointer native_pointer;
} u;
struct CRB_Object_tag *prev;
struct CRB_Object_tag *next;
};
与此同时还增加了 ScopeChain和 NativePointer这两个怪东西,还是留在后面介绍吧。
9.1.3 闭包
对于对象来说不能够只有数据成员,还得有方法吧?我好像听见有人问我:“方法怎么着了?”但是,我还是要把这些急脾气的人放在一边,先讨论一下别的话题。
在crowbar中可以使用 闭包 (closure)功能。所谓闭包,就是可以在表达式中定义函数。
创建闭包
c = closure(a) {
print("a.." + a);
};
调用闭包
c(10);
closure是创建闭包的关键字。通过在后面的括号内定义形式参数、在程序块中编写代码来创建闭包。上面的代码中把创建的闭包赋值给了变量 c。
利用代码 c(10)可以调用闭包。因此,这段代码会输出 a..10。
C语言的程序员看了这个可能会想,“什么嘛!这不就是函数指针吗?”(当然,闭包可以在表达式中任意编写,比函数指针容易上手)。闭包确实有与函数指针相似的一面,实际上使用方法也是一样的。
但是,决定性的区别在于,闭包可以引用到闭包声明所在位置的局部变量。
举一个关于 foreach 的例子。在crowbar 中循环数组的全部元素时需要编写如下代码:
for (i = 0; i < array.size(); i++) {
处理
}
这种编码方式依赖于数组概念的实现。如果此时改变设计思路,不用数组而改用链表了,那么与之相关的所有地方都要进行修改。这是一件很烦人的事,因此在C#中出现了一个叫作 foreach的语法。
foreach (Object o in hogeCollection)
{
// 处理
}
Java从J2SE5.0开始也增加了同样的语法。有了这个语法确实方便了不少,虽说方便了但是还是要考虑如何把它调整为语法规则。
但是,在可以使用闭包的语言中,是可以把代码写成下面这样的 [3]。
foreach(hoge_collection, closure(o){
处理
});
这里的foreach并不是关键字,而是单纯程序库的函数。第1个参数是集合对象,第2个参数可以接收闭包。 foreach函数将第1个参数(集合对象)中的元素依次取出,并以此为参数调用第2个参数(闭包)。
如果只是满足调用 foreach函数时的这个功能的话,那么C的函数指针也是可以实现的。但是,在通过这种方式使用闭包的时候,如果可以从循环的内部引用外部的变量的话,就是一件不寻常的事情了。
fp = fopen("hoge.txt", "w");
foreach(hoge_collection, closure(o) {
fputs(o.name, fp); # 引用循环外部的变量fp
});
闭包使这种调用方式成为可能。这就是闭包与C语言的函数指针之间决定性的不同。
9.1.4 方法
对象和闭包组合起来,就变成了下面这段代码(代码清单9-1)。
代码清单9-1 Point.crb(之一)
1: # 创建“点”的函数(构件方法)
2: function create_point(x, y) {
3: this = new_object();
4: this.x = x;
5: this.y = y;
6:
7: # 定义输出坐标的方法print()
8: this.print = closure() {
9: print("(" + this.x + ", " + this.y + ")\n");
10: };
11: # 定义移动坐标的方法move()
12: this.move = closure(x_vec, y_vec) {
13: this.x = this.x + x_vec;
14: this.y = this.y + y_vec;
15: };
16: return this;
17: }
18:
19: # 创建对象
20: p = create_point(10, 20);
21:
22: # 调用move()方法
23: p.move(5, 3);
24:
25: # 调用print()方法
26: p.print();
由于crowbar中没有专门的“方法”功能,因此通过上面的方式让对象的成员持有闭包,也就实现了与Diksam、Java、C++等语言类似的方法功能。
代码清单9-1 的第3行出现的 this 也不是关键字,其实只是取什么名字都可以的局部变量,只不过使用 this 的话,对于习惯了C++ 或Java 的人来说比较容易理解。重点在于,从闭包内部可以访问到外部的局部变量,因此在 print()和 move()的内部可以引用到this。
如果想要继承或者多态的话,只需要在调用 create_point()的基础上增加新的方法覆盖原有的方法就可以了。
代码清单9-2 Point.crb(子类)
1: # 生成“子类”
2: function create_extended_point(x, y) {
3: this = create_point(x, y);
4:
5: # 重写print()
6: this.print = closure() {
7: print("override (" + this.x + ", " + this.y + ")\n");
8: };
9:
10: return this;
11: }
另外,现在的 create_point()方法外面如果书写代码 p.x的话是可以引用到 x的。也就是说, p的成员 x、 y的默认是 public的。如果实在是不喜欢这种方式,也可以不在 this中保存 x和 y,而是使用代码清单9-3的方式增加访问器就可以了。
代码清单9-3 Point.crb(封装版)
1: # 创建“点”的函数(构件方法)
2: function create_point(x, y) {
3: this = new_object();
4:
5: this.print = closure() {
6: print("(" + x + ", " + y + ")\n"); #←即使不是this.x也可以引用
7: };
8: this.move = closure(x_vec, y_vec) {
9: x = x + x_vec;
10: y = y + y_vec;
11: };
12: # 增加访问器(省略了get_y())
13: this.get_x = closure() {
14: return x;
15: };
16: return this;
17: }
在 create_point() 内创建的闭包拥有可以引用参数(或者说局部变量) x和 y的特性。
上面这些就是基于crowbar的面向对象。
9.1.5 闭包的实现
看了前一节的代码,可能有人会有下面这样的疑问。
如果this、x、y都是局部变量的话,在函数create_point()退出的时候不是就该被释放了吗?就算是在闭包中可以引用到外部的局部变量,但如果被释放了的话不是就不能引用了吗?
真是一个不错的问题,但上面的担心并不会发生,这才是闭包有趣的地方。
在C语言中,进入函数的时候会在栈上创建局部变量的内存空间,函数退出的时候会被释放。此时,被创建/释放的单块内存被称为 帧 (frame)。
在crowbar中,到book_ver.0.3为止,本质上都是相同的(只不过帧不是在栈上被创建的而是在堆上)。然而在上述示例中的 print() 和 move() 方法,在 create_point() 结束后才被调用,而且在方法里面还能引用到 this。如果使用“函数退出时帧也会被释放”这个老规则,是不能满足这种变量访问方式的。
在现在的crowbar中,创建帧的时机和往常一样,但是释放的时机却不是“函数退出的时候”,而是“帧不再被引用的时候”。也就是说,帧的释放是通过GC进行的。
但是,请思考一下实际的实现方式。
首先,帧是某一次函数调用时保存局部变量的地方,对于局部变量(群)来说,由于存在着多个变量名和值的组合,因此使用assoc再适合不过了。也就是说,在调用函数的时候创建一个assoc,并将局部变量保存在其中就可以了。
接下来就是闭包了。像之前所说的,闭包具有如下特性。
- 闭包是一个值,可以像C的函数指针一样赋值给变量,并且在之后可以通过函数调用的方式投入使用。
2. 可以引用创建其位置的局部变量。
首先,先来介绍一下第一个特征。
由于闭包是一个值,必然可以保存在 CRB_Value 中,因此,在 CRB_Value的共用体定义中需要增加 CRB_Closure(代码清单9-4)
代码清单9-4 CRB_Closure结构体
typedef enum {
CRB_BOOLEAN_VALUE = 1,
CRB_INT_VALUE,
CRB_DOUBLE_VALUE,
CRB_STRING_VALUE,
CRB_NATIVE_POINTER_VALUE,
CRB_NULL_VALUE,
CRB_ARRAY_VALUE,
CRB_ASSOC_VALUE,
CRB_CLOSURE_VALUE, ←新增
CRB_FAKE_METHOD_VALUE, ←将在后面的章节中介绍
CRB_SCOPE_CHAIN_VALUE
} CRB_ValueType;
·
·
·
typedef struct {
CRB_ValueType type;
union {
CRB_Boolean boolean_value;
int int_value;
double double_value;
CRB_Object *object;
CRB_Closure closure; ←新增
CRB_FakeMethod fake_method; ←将在后面的章节中介绍
} u;
} CRB_Value;
这里增加了 FAKE_METHOD,我会在后面的章节中介绍(抱歉,要在后面介绍的内容太多了)。
然后是第二个特性。闭包虽然与函数指针相似,但是它拥有可以引用创建其位置的局部变量的特性(对于这点,也有闭包保存了其创建位置的环境 [4]的说法)。局部变量被保存在assoc中,因此,我想 CRB_Closure结构体可以定义成下面这样。
typedf struct {
CRB_FuntionDefinition *function;
CRB_Object environment; / 指向帧的assoc */
} CRB_Closure;
成员 function 指向了函数定义的实体 CRB_FunctionDefinition,environment则指向了创建闭包的位置的帧。
但是,这里有一个必须要注意的地方,就是闭包是可以嵌套的。
下面这段代码中,在注释的位置肯定可以同时引用到 a和 b。
function f() {
a = 10;
c1 = closure() {
b = 20;
c2 = closure() {
这里可以同时引用到a和b
print("a.." + a + "\n");
print("b.." + b + "\n");
};
c2();
};
return c1;
}
虽说闭包是一个函数,但又不同于函数,因此它既可以访问保存了a的帧(函数 f() 的帧),又可以访问保存 b 了的帧(闭包 c1 的帧)。因此可以看出,闭包要保存的帧不止一个。
于是,引入了作用链(scope chain)这个概念。作用链是以链表方式管理的帧的assoc(图9-2)。
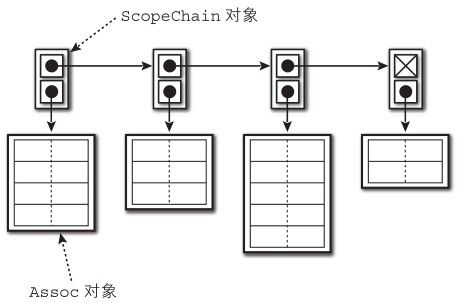
图9-2 作用链
为了构建这个链表,我们引入了 ScopeChain 结构体。 ScopeChain 作为GC的目标,也因此成为了 CRB_Object的共用体的成员(这个是前面写到的要在后面章节中做介绍的内容之一)。
ScopeChain结构体的定义如下。
typedef struct {
CRB_Object frame; / 指向CRB_Assoc */
CRB_Object next; / 指向ScopeChain */
} ScopeChain;
但是, CRB_Closure 并没有直接指向代表帧的 assoc,而是指向了ScopeChain。
typedef struct {
CRB_FunctionDefinition *function;
CRB_Object environment; / 指向ScopeChain */
} CRB_Closure;
不好意思各位,结果最后都是 CRB_Object,除了被注释的内容之外没有任何改变 [5]。
另外, LocalEnvironment 结构体中也同样没有指向assoc,而是指向了 ScopeChain。
至于具体怎么去使用上面定义的这些结构体,我想在跟踪程序实际执行时考虑的话,可能会更容易理解。
9.1.6 试着跟踪程序实际执行时的轨迹
在crowbar中,调用函数、创建闭包、调用闭包,都要进行以下动作。
[规则1] 在调用函数的时候,会创建新的 LocalEnvironment并将其入栈为栈顶 [6]。在这个 LocalEnvironment中,为了保存在当前函数中声明的局部变量,创建并分配(元素被作为一个作用链)了一个新的assoc。
[规则2] 在创建闭包的时候,这个闭包保存着栈顶 LocalEnvironment中的作用链。
[规则3] 在调用闭包的时候,会在规则1中创建新的作用链之后,再将其链接到保存着闭包的作用链上。
这些规则在实际上是怎样操作的,请参考代码清单9-5。
代码清单9-5 试着追踪闭包执行的轨迹
1: function f() {
2: a = 10;
3: c1 = closure() {
4: b = 20;
5: c2 = closure() {
6: # 这里可以同时引用到a和b
7: print("a.." + a + "\n");
8: print("b.." + b + "\n");
9: };
10: c2();
11: };
12: return c1;
13: }
14:
15: c = f();
16: c();
1. 普通的函数调用
首先,在第15行调用 f()的时候,会根据规则1创建一个 LocalEnvironment,并生成第一个帧。在第2行的赋值语句中,声明了 a并保存在新创建的帧中。之后的动作就跟调用一般的函数一样了(图9-3)。另外,为了更清楚地描述这个过程,图中没有出现 ScopeChain结构体,而是画得好像代表帧的assoc可以单独构建链表一样。

图9-3 普通的函数调用
2. 创建闭包
第3~11行创建了闭包。
根据规则2,闭包在创建的时候保存了指向保存了 LocalEnvironment的作用链的引用。
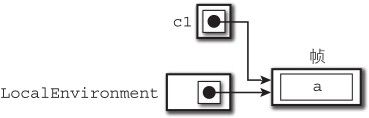
图9-4 创建闭包
并且, c1本身就是一个局部变量,因此与 a保存在了同一个帧中,图中为了使表达更为简单所以把这部分省略了。
这里的“创建闭包”是指,执行用关键字 closure创建闭包的处理的时候。第3行中创建了闭包并赋值给了变量 c1,但是并没有马上调用闭包 c1,在第5行生成另外一个闭包的时候也没有执行,直到调用了 f()将其返回,闭包 c1一直都没有被调用。
3. 调用闭包
调用 f()返回之后,在第16行调用了闭包 c1。
此时也会根据规则1新建一个 LocalEnvironment和帧,并且根据规则3,在新建了帧之后,再将其链接上保存着闭包的作用链(图9-5)。
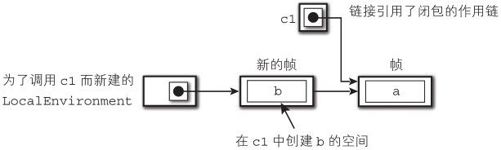
图9-5 调用闭包
在搜索局部变量的时候,会对 LocalEnvironment引用的作用链依次进行搜索。因此,在 c1中是可以引用到局部变量 a的。
4. 创建闭包中的闭包
在开始执行赋值给 c1的闭包时,首先会执行第4行为 b的赋值。 b是一个单纯的局部变量,因此会在 LocalEnvironment直接指向的帧中创建空间。
在接下来的第5~9行中创建第二个闭包 c2。
此时,根据规则2,创建闭包 c2 时保存了指向 LocalEnvironment 保存着的作用链。因此, c2 保存的作用链中链接着存有 b 的帧和存有 a 的帧(图9-6)。
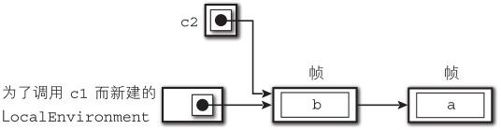
图9-6 调用闭包
5. 调用嵌套闭包
在第10行调用了 c2 的时候,根据规则3, c2 引用的作用链链接到了新的 LocalEnvironment上,因此, c2中应该可以同时引用 a和 b。
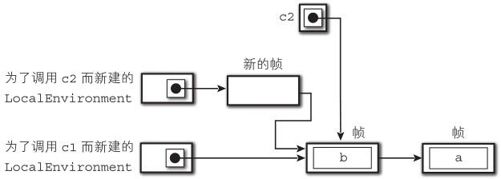
图9-7 调用嵌套闭包
9.1.7 闭包的语法规则
创建闭包的语言规则如下所示:
closure_definition
: CLOSURE IDENTIFIER LP parameter_list RP block
| CLOSURE IDENTIFIER LP RP block
| CLOSURE LP parameter_list RP block
| CLOSURE LP RP block
;
在 closure_definition被reduce的时候,在create.c中会创建如下结构体(想象一下就能知道,它是 Expression结构体的共用体成员)。
typedef struct {
CRB_FunctionDefinition *function_definition;
} ClosureExpression;
由于闭包也是函数,因此为闭包表达式构建了 CRB_FunctionDefinition。但是这个 CRB_FunctionDefinition仅可以由分析树中的 ClosureExpression引用,并不会添加到 CRB_Interpreter.的 function_list里面。
另外,在上面的四个语法规则中,有两个在关键字 closure后面加入了标识符(IDENTIFIER)。这种语法规则在创建 命名闭包 时使用。
在目前为止出现的例子中,闭包都是没有名字的。但如果想要在闭包中递归调用自己的话,给闭包起个名字就会方便很多。
至于实现上,在调用命名闭包时,首先要为其创建新的帧,此时将闭包自身作为指定名称的局部变量登录进来就可以了。
9.1.8 普通函数
到book_ver.0.3为止,crowbar的函数调用语法规则如下所示。
primary_expression
: IDENTIFIER LP argument_list RP
| IDENTIFIER LP RP
;
为了可以使用闭包,函数调用运算符 () 的左边不仅可以是 IDENTIFIER,还可以是任意的表达式。
因此,普通函数也发生了变化,函数名用来返回“表示函数的值”(C语言中的函数指针)。函数的实体也变成了 ClosureExpression。
例如,调用函数 print("hello\n")时的形式为,返回 print标识符对应的“函数”,然后再调用它。此时, print返回的 ClosureExpression中,environment成员为 NULL。
当然也可以通过下面的方法将普通函数赋值给变量。
p = print;
p("hello,world\n");
9.1.9 模拟方法(修改版)
在crowbar的数组中有例如 size()这样的“方法”。
book_ver.0.2的实现方式在4.4.2节中已经介绍过了,但是在这次的修改中,函数将作为“值”被处理。因此,像下面这样一段代码必须能够输出 array的大小。
a = array.size;
·
·
·
print("array.size.." + a());
想要实现它,就必须要让 a.size返回C语言中的函数指针——不仅如此,如果没有地方保存指向 array的引用,也不可能返回数组的大小。
因此,在 CRB_Value 共用体中,增加了专门用来“模拟方法”的 CRB_FakeMethod成员(这也是前面说过的会在后面章节中介绍的内容之一)。
typedef struct {
char method_name; / 函数名 */
CRB_Object object; / 相当于this的对象 */
} CRB_FakeMethod;
CRB_FakeMethod结构体保存了前面所说的指向 array的引用。在知道了这些引用和函数名之后,处理器就可以调用模拟方法了。
9.1.10 基于原型的面向对象
实际上,crowbar的设计方式多多少少参考了JavaScript。
像JavaScript和crowbar这样没有类的概念、每个实例都包含不同字段和方法的语言,被称为基于原型的面向对象语言(prototype based object oriented language)。与此相对,Java、C#和Diksam等具有类的概念的面向对象被称为 基于类的面向对象语言(class based object oriented language)。
但是,一般被称为“基于原型的面向对象”时,多数情况会包含如下特性:
可以通过复制(克隆)现有对象来创建新的对象。
当调用了对象的某个方法之后,如果对象中不存在这个方法,则自动将该方法的调用传递给其他对象 [7](原型链 ,prototype chain)。
虽然在JavaScript中具有原型链功能,但是在crowbar中却没有。这也就意味着,crowbar算不上是基于原型的面向对象语言。但是,基于原型的面向对象也被称为是“基于实例的”或者是“基于对象的”,从这两个方面去看crowbar,也许还能够跟它们归为一类。
