10.1 DOM、SAX和JAXP概述
当XML文档作为数据交换工具时,应用程序必须采用合适的方式来获取XML文档里包含的有用信息,这就需要通过程序来解析XML文档了。为了解析XML文档里包含的有用信息,最直接、最容易想到的方法是通过文件I/O来读取XML文档里包含的信息,但这种方式显然过于笨拙,而且完全忽略了XML文档作为结构化文档的特征,是一种下下之选。
为了利用XML文档的结构化特性进行解析,现在有两套比较流行的规范:
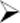 DOM:Document Object Model,即文档对象模型,它是由W3C推荐的处理XML文档的规范。目前最新版本是DOM Level 3。
DOM:Document Object Model,即文档对象模型,它是由W3C推荐的处理XML文档的规范。目前最新版本是DOM Level 3。
SAX:Simple API for XML,它并不是W3C推荐的标准,但却是整个XML行业的事实规范。目前最新版本是SAX 2.0。
一般来说,需要解析XML文档时,没必要自己手动实现XML解析器,直接利用现有的XML解析器即可。目前主流的XML解析器都会为DOM和SAX提供实现。
DOM为解析XML文档定义了一组标准接口,DOM解析器负责读入整个文档,然后将该文档转换成常驻内存的树状结构——这棵树也称为DOM树。然后程序代码就可以使用节点与节点之间的父子关系来访问DOM树,并获取每个节点所包含的数据。
DOM标准简单易用,但有一个显著的问题:它需要一次性地读取整个XML文档,而且程序运行期间,整棵DOM树常驻内存,导致系统开销过大。SAX正是为了解决DOM问题而出现的一套标准,SAX采用事件驱动机制来解析XML文档。
每当SAX解析器发现文档开始、元素开始、元素结束、文本和文档结束等事件时,就会向外发送一次事件,而程序员则通过编写事件监听器监听这些事件来获取XML文档里的信息。SAX解析方式占用内存极小,速度更快。
 提示
提示
关于SAX解析方式,笔者每次上课时都会举一个例子:假设XML文档是一片充满危险的“雷区”,而SAX解析器就是被我们送入“雷区”的“探雷工兵”(他具有不死之身),每当这个“工兵”遇到文档开始、元素开始、元素结束、文本和文档结束等事件时,他就仿佛踩到“雷”一样,大喊一声(对外发送事件),而外面的人(事件监听器)就可通过他叫喊的内容(事件)来得到关于“雷”(当前节点)的信息。
关于DOM和SAX解析方式,本书后面还会有更详细的解释,读者此处先建立一个直观认识即可。
目前,Java领域流行的XML解析器来自Apache组织提供的Xerces项目,这是一个跨语言的XML解析器,目前提供了C++、Java和Perl等语言的实现版本,读者可登录http://xerces.apache.org/站点查看该项目的情况。
对于Java程序员而言,当然是要下载Xerces项目的Java版本,也就是Xerces-J。建议读者直接下载Xerces-J的二进制编译版本。笔者成书之时,Xerces-J的最新版本是2.9.1。本书的所有示例程序都基于该版本的Xerces-J,建议读者也下载该版本。
下载完成后得到Xerces-J-bin.2.9.1.zip文件,解压缩后将得到如下所示文件结构:
data:该文件夹下包含了几个示例XML文档及对应的DTD文档。
docs:该文件夹下包含了Xerces-J的各种文档,包括用法说明和API文档。
samples:该文件夹下是Xerces-J的各种范例,这些范例是学习Xerces-J很好的材料。
xml-apis.jar:这是DOM和SAX标准的核心JAR包,该JAR包里几乎全是接口,只有少数实现类。实际上,它包含的是JAXP为DOM和SAX提供的一些实现接口。
 学生提问:接口的实现不是类吗,怎么接口的实现还是接口啊?
学生提问:接口的实现不是类吗,怎么接口的实现还是接口啊?
答:因为DOM和SAX是XML文档的两种通用的解析规范,它们并不属于任何具体的编程语言,也就是说具有跨语言的要求,所以定义DOM和SAX规范的各种接口是采用IDL(Interface Definition Language,即接口定义语言)定义的,而各种具体语言(如Java)还需为这些接口定义相应的实现。

xercesImpl.jar:Xerces-J实现的JAR包,是该项目的核心类库。
一些杂项JAR和LICENSE等文档。
假设需要使用Xerces-J实现来解析XML文档,则可以考虑使用如下代码:

上面的代码只是使用Xerces-J进行解析的代码框架,其中第1、2行粗体字代码用于创建一个XML解析器,其中的SAXParser是Xerces-J为SAX解析标准提供的一个实现类。
上面的代码虽然简单,而且易于理解,但有一个比较严重的问题:程序代码直接与Xerces-J耦合,如果有一天想换另一个XML解析器进行解析,那就必须修改上面的源代码了。
为了解决这个问题,很容易想到“面向接口”编程和工厂模式,我们希望使用类似如下格式的代码来解决这个问题:

上面的工厂模式面向org.xml.sax.XMLReader接口编程,该接口是SAX解析器的标准接口(实际上是JAXP为SAX解析器标准接口的实现),不再面向具体的SAX解析器实现类编程,当需要切换为另一个XML解析器时,上面的源代码就无须修改了。
通过上面的介绍不难发现,如果在各种XML解析器之上再增加一层“工厂模式”的抽象,就可以将应用程序代码和XML解析器彻底分离开来,从而实现更好的解耦。
这层“工厂模式”的抽象就是JAXP,它的全称是Java API for XML。JAXP支持DOM、SAX、XSLT等XML标准,可充分提高应用程序的灵活性。JAXP本身没有提供任何的XML解析支持,其底层必须依赖于各种具体的XML解析器,但它又不与任何具体的XML解析器耦合,因而使得应用程序可以在各种XML解析器之间轻松切换而无须修改源代码。
从这个意义上来看,JAXP只是建立在DOM和SAX之上的一个抽象层,它既没有提供解析XML的新方法,也没有对DOM或SAX进行任何扩充,完全没有为Java的XML 处理提供任何新的功能。JAXP只是提供了一种工厂模式,允许应用程序在不同的XML解析器之间切换。图10.1显示了JAXP的作用。
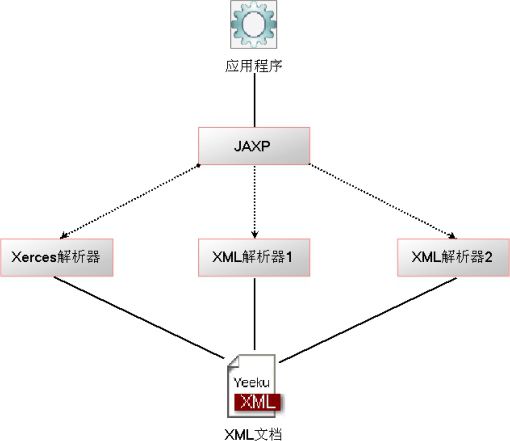
图10.1 JAXP的作用示意
通过JAXP的帮助,开发者开发应用程序时直接面向JAXP的接口和工厂类编程。至于具体选择使用哪种XML解析器,则由JAXP来决定。
提示
从图10.1可以看出,JAXP的作用有点类似于JDBC API,而不同的XML解析器实现则有点类似于各种具体的驱动程序。
JAXP本身就是JDK的一部分,JDK 1.5已经包含了JAXP 1.3,JDK 1.6则包含了JAXP 1.4。JAXP由javax.xml包及其子包、org.w3c.dom包及其子包和org.xml.sax包及其子包组成。javax.xml包及其子包主要用来获取解析器的实例,获取到解析器实例后就可以对XML进行读取。如果使用DOM进行解析,通常就使用org.w3c.dom包及其子包中的接口或者类;如果使用SAX进行解析,则通常使用org.xml.sax包及其子包中的接口或者类。
javax.xml.parsers包中提供了如下4个与DOM和SAX解析相关的类:
DocumentBuilderFactory:获取DOM解析器的工厂类,它是JAXP工厂模式里的工厂。
DocumentBuilder:DOM解析器的标准接口,所有DOM解析器都应实现该接口,应用程序采用DOM解析时面向该接口编程。
SAXParserFactory:获取SAX解析器的工厂类,它是JAXP工厂模式里的工厂。
SAXParser:SAX解析器的标准接口,所有SAX解析器都应实现该接口,应用程序采用SAX解析时面向该接口编程。
当程序中使用DocumentBuilderFactory、SAXParserFactory工厂获取DocumentBuilder、SAXParser解析器时,底层肯定需要依赖于某种XML解析器的具体实现,解析器工厂返回的解析器必然是这些DocumentBuilder、SAXParser接口的实现类的实例。
现在问题就出现了:JAXP如何确定返回哪个解析器的实例呢?程序中并没有指定解析器工厂返回哪个解析器实现类的实例,而是让解析器工厂“智能”地选择解析器实现类,那么解析器工厂到底采用怎样的机制去确定解析器实现类呢?
查看JAXP的API可以发现,DocumentBuilderFactory、SAXParserFactory都是抽象类,不能直接实例化,只能通过它们的newInstance()方法来创建实例。
提示
JAXP的API文档既可以在JDK 1.6的API文档中找到(因为JDK 1.6已经包含了JAXP 1.4),也可以在Xerces-J解压缩后的docs\javadocs\api路径下找到。
实际上,JAXP采用的是一种名为工厂方法的模式来获得解析器实例,即不同的解析器工厂产生不同的解析器实现类的实现。
提示
所谓工厂方法模式,简单地说,就是不同的工厂制造出不同的产品对象,如果需要用工厂方法来制造一批产品对象,那就需要为这批产品相应地提供一批工厂类。关于工厂方法模式,可以参考疯狂Java体系的《轻量级Java EE企业应用实战》(第3版)一书。
假设使用如下代码来创建DOM解析器工厂:
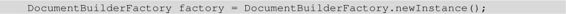
或采用如下代码来创建SAX解析器工厂:

JAXP显然无法真正返回DocumentBuilderFactory、SAXParserFactory的实例,只能返回它们的实现类的实例。那么newInstance()方法到底如何选择哪个解析器工厂的实现类呢?
JAXP将按如下规则来依次搜索解析器工厂实现类:
(1)按系统属性
newInstance()方法将会查看系统属性是否包含了javax.xml.parsers.DocumentBuilderFactory或javax.xml.parsers.SAXParserFactory两个属性。其中前一个属性用于指定DOM解析器工厂的实现类,后一个属性用于指定SAX解析器工厂的实现类。
如果用如下代码来获取DOM解析器工厂对象:

上面的代码通过系统属性设置了DOM解析器工厂的实现类,因此上面的代码返回的DOM解析器工厂是org.apache.xerces.jaxp.DocumentBuilderFactoryImpl实例。
类似地,可以使用如下代码来获取SAX解析器工厂对象:

上面的代码通过系统属性设置了SAX解析器工厂的实现类,因此上面的代码返回的SAX解析器工厂是org.apache.xerces.jaxp.SAXParserFactoryImpl实例。
上面这种设置方式虽然简单,但坏处也很明显:调用System类的setProperty()方法时依然需要与具体的XML解析器耦合,因此也不利于高层次的解耦。
幸好java.exe允许通过-D选项临时添加系统属性,因此可以通过如下命令在运行时指定DOM解析器工厂的实现类:

也可以通过如下命令在运行时指定SAX解析器工厂的实现类:

上面两条命令中的MyDOMTest、MySAXTest就是进行DOM解析、SAX解析的主程序。
(2)按jaxp.properties属性文件
如果JAXP在%JAVA_HOME%\jre\lib路径下找到一个名为jaxp.properties的文件,且该文件是一个标准的属性文件,newInstance()方法将按该文件设置的属性来获取DOM解析器工厂和SAX解析器工厂。
提示
%JAVA_HOME%代表JDK的安装路径,记住是JDK的安装路径,即%JAVA_HOME%目录下应有bin、jre、lib等子目录。
jaxp.properties文件内包含的如下两个属性分别用于指定DOM解析器工厂和SAX解析器工厂的实现类:

(3)按JAR包里META-INF\services下的文件
newInstance()方法会自动搜索类加载路径下的所有JAR包,如果在任何JAR包的META-INF\services下找到javax.xml.parsers.DocumentBuilderFactory文件,该方法将会根据该文件的内容(文件内容是DOM解析器工厂实现类的类名)来获取DOM解析器工厂;如果在任何JAR包的META-INF\services下找到javax.xml.parsers.SAXParserFactory文件,则该方法将会根据该文件的内容(文件内容是SAX解析器工厂实现类的类名)来获取SAX解析器工厂。
这种方式具有最好的解耦效果,开发者只要将具体XML解析器的JAR包丢在系统的类加载路径下,newInstance()方法就会自动在不同XML解析器之间切换,因此这也是各XML解析器厂商广泛采用的方式。
用WinRAR打开xercesImpl.jar文件,进入META-INF\services路径下,即可看到图10.2所示窗口:
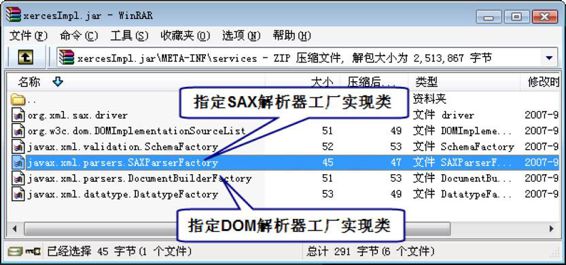
图10.2 xercesImpl.jar的解析器工厂设置
打开图10.2所示文件列表中的javax.xml.parsers.SAXParserFactory文件,可看到如下文件内容:
org.apache.xerces.jaxp.SAXParserFactoryImpl
这表明SAXParserFactory.newInstance()方法将返回org.apache.xerces.jaxp包下的SAXParserFactoryImpl类的实例。
(4)使用默认解析器
一般说来,前面3种方式已经可以确定JAXP将使用哪种解析器工厂了。如果前面3种方式依然没有找到合适的解析器工厂实现类,则会使用默认的解析器实现。
早期的JAXP(JAXP 1.1)捆绑了Crimson解析器作为默认的解析器实现,后来的JAXP则都捆绑了Xerces-J作为默认的解析器实现。
