10.4 DOM和SAX的比较
DOM和SAX采用两种截然不同的方式来解析XML文档,DOM解析方式需要一次性将整份XML文档装入内存,转换成内存中的DOM树,DOM树包含的所有节点都是Node各接口的对象。
DOM模型的关键在于文档到对象之间的转换,这也是Document Object Model名称的由来,从这个意义上说,DOM模型也可理解为Document Object Mapping——即文档对象映射,不过这个名称只是笔者根据DOM含义给出的名称,并不是官方名称。从实际使用角度来看,DOM模型的作用其实就是定义了XML文档(Document)和Object(各种Node节点)之间的映射关系,从而允许用户通过内存中的DOM树(一系列Node 对象的集合)获取对应的XML文档里的信息。
SAX解析的关键在于事件驱动,SAX解析器处理XML文档时,会自动对外发送一系列的事件,这些事件将会由程序员提供的监听器所监听。因此实现SAX解析的重要工作在于实现事件监听器,监听SAX解析器在处理XML文档时所发出的一系列事件。
在为SAX解析器注册了ContentHandler、DTDHandler、ErrorHandler和EntityResolver 4种监听器之后(由于DefaultHandler已经实现了上面4个接口,因此也可以使用DefaultHandler来作为上面的4种监听器),SAX解析器处理XML文档内容的事件、处理DTD文档时的事件、处理XML文档出现错误的事件和处理XML文档中实体的事件将会被对应监听器监听到,应用程序可以通过监听器里的各方法来获取XML文档里的信息。
可以这样理解SAX的解析过程:SAX解析器就像一个电子探测器,它在XML文档中一路走过,每经过一个元素开始、元素结束、处理指令开始、处理指定结束……都将向外发送一个事件,该元素的内容就包含在该事件中,而程序则负责接收该事件,并将其中的内容解析出来。
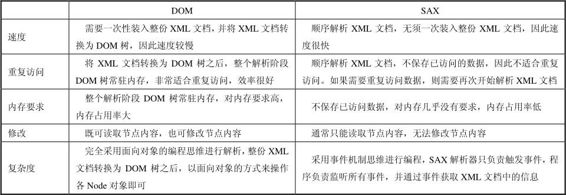
通常认为:对于解析大的XML文档,使用SAX更有优势;而对于解析小的XML文档,特别是那些需要重复读取的文档,则使用DOM更有优势。
总体来说,使用DOM和SAX解析有表10.2所示差异。
表10.2 DOM和SAX解析的差异