10.2 JAXP的DOM支持
前面已经介绍了DOM、SAX和JAXP的相关概念,接下来本节将详细介绍JAXP对DOM的支持,包括如何利用JAXP提供的DOM支持来读取、创建和修改XML文档。
10.2.1 XML文档和DOM模型
DOM以树状结构组织XML文档的每个节点,这个树状结构允许开发人员在树中寻找特定信息。在访问树的节点之前,必须先加载整个文档,并构造对应的树状结构,DOM解析器才能开始解析。
DOM的解析处理具有如下优点:由于树在内存中是持久的,可以修改树的节点,对应为修改文档中元素的值,因此提供了灵活的修改。如果需要对XML文档中的数据进行重复读取,DOM的优势非常明显:由于DOM一次性将整个XML文档全部读入内存,因此可以随机访问XML文档的每个元素。
使用DOM解析XML文档时,需要将XML文档转换成一棵DOM树。而DOM解析器在装入XML文档时,会将XML文档的节点对应转换成DOM树的每个节点。图10.3显示了这种转换。
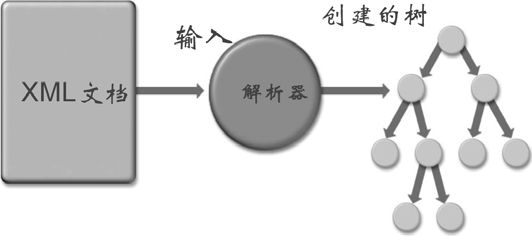
图10.3 XML文档转换成DOM树的示意
例如对于如下XML文档:

上面的文档的结构化关系为:“书籍列表”是根元素,该根元素包含了两个“计算机书籍”子元素。每个“计算机书籍”元素又包含了3个子元素。根据这种结构化的关系转换成的树状结构如图10.4所示:
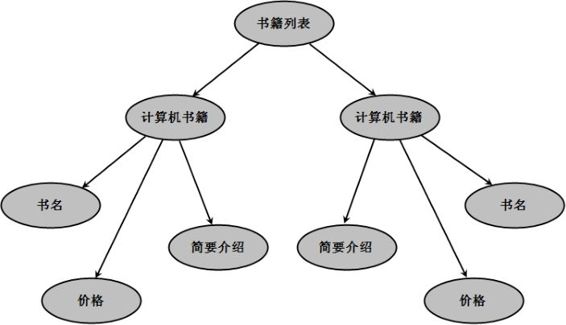
图10.4 XML文档转换的树状结构
图10.4中的DOM树将文档中的所有元素都通过树状结构的节点表示,一个节点又可以包含其他子节点。而节点本身还可包含其他信息,例如节点的值、节点的属性等。将XML文档转换成DOM树的过程,就是将文档模型对象化的过程。
DOM模型不仅描述了文档的树状结构,还定义了树状结构中各对象的行为。换句话说,图10.4所示DOM树不再是普通的树状结构,还具有对象模型的特征,如需解析该文档,只需以面向对象的方式访问这些对象的属性和方法即可。
10.2.2 DOM树中的对象类型
DOM树不仅可描述XML文档的结构化特征,而且具有对象模型的特征,也就是说DOM树所包含的每个节点都是一个对象,在DOM中使用Node接口来表示,即DOM树中的所有节点都是Node对象。
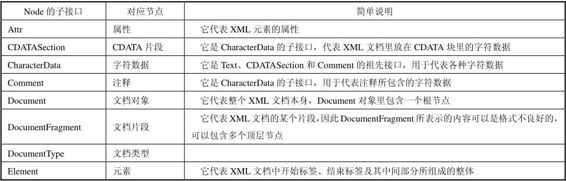
Node接口下包含表10.1所示的子接口。
表10.1 Node的各子接口

了解了DOM模型中各对象的类型之后,应用程序可以充分利用这些对象的属性和方法来访问它们所包含的数据。至于各对象所包含的各种属性和方法,读者可参考JAXP的API文档,此处不再赘述。
将一份XML文档转换成DOM树,这就是DOM解析器的责任了,下面介绍如何利用DOM解析器来解析XML文档。
10.2.3 DOM解析器
在程序中获取DOM解析器按如下两个步骤进行:
(1)调用DocumentBuilderFactory类的newInstance()方法获取解析器工厂对象。
(2)调用DOM解析器工厂的newDocumentBuilder()方法获取DOM解析器。
JAXP使用DocumentBuilder抽象类代表DOM解析器,抽象类里包含了多个重载的parse()方法,如下所示:
 Document parse(File f):将File对象对应的XML文档解析成Document对象。
Document parse(File f):将File对象对应的XML文档解析成Document对象。
Document parse(InputSource is):将InputSource输入源里包含的XML文档解析成Document对象。
Document parse(InputStream is):将InputStream输入流里包含的XML文档解析成Document对象。
Document parse(InputStream is, String systemId):将InputStream输入流里包含的XML文档解析成Document对象。systemId参数用于指定基URI。
Document parse(String uri):将指定URI所对应的XML文档解析成Document对象。
这些parse()方法用于将不同形式的XML文档解析成Document对象,一旦获得了XML文档的Document对象,XML文档就完全转换为对象模型了,整个XML文档的内容都将转换为DOM树里的各节点对象,然后就可以利用这些对象的属性和方法来获取XML文档里的数据了。
在使用DocumentBuilderFactory类获取DOM解析器之前,可使用该解析器工厂提供的如下方法来控制解析器的行为:
setCoalescing(boolean coalescing):设置该工厂创建的解析器是否将CDATA片段转换为Text节点,并将其附加到相邻(如果有)的Text节点。默认情况下,其值设置为false。
setExpandEntityReferences(boolean expandEntityRef):设置该工厂创建的解析器是否获取外部实体引用的数据。如果设置为true,则获取外部实体引用的数据,并插入到该DOM树中。默认是true。
setIgnoringComments(boolean ignoreComments):设置该工厂创建的解析器是否忽略XML文档中的注释。默认是false。
setIgnoringElementContentWhitespace(boolean whitespace):设置该工厂创建的解析器是否删除元素内容里的空格。默认是false。
setNamespaceAware(boolean awareness):设置该工厂创建的解析器是否支持XML命名空间。默认是false。
setSchema(Schema schema):设置该工厂创建的解析器解析XML时所使用的Schema。需要使用XML Schema验证XML文档的有效性时应调用此方法。Schema对象由SchemaFactory工厂类创建。
setValidating(boolean validating):设置该工厂创建的解析器解析XML之前是否先进行有效性验证,默认不验证XML的有效性。该方法只控制使用DTD验证。
10.2.4 使用DTD验证XML文档
如果需要使用DTD验证XML文档的有效性,只需调用DOM解析器工厂的setValidating(true)即可。代码如下:
程序清单:codes\10\10.2\src\lee\DTDValidate.java
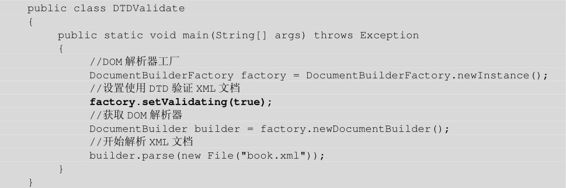
上面的粗体字代码设置了使用DTD验证XML文档的有效性,如果指定XML文档book.xml(该文档里包含外部DTD定义)不是一份有效的XML文档,则运行上面的程序将看到图10.5所示界面:
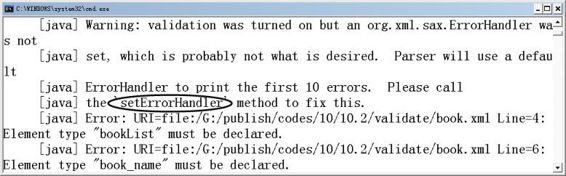
图10.5 使用DTD验证XML文档
如果被验证的XML文档不是有效的XML文档,DOM解析器将对外发出错误通知,但这些错误通知没有得到处理,因此会看到图10.5所示界面。
如图所示,为了以更优雅的方式获取验证过程中的错误通知,应该为DOM解析器注册一个ErrorHandler。
ErrorHandler其实是org.xml.sax包下的接口,该接口本质上代表了一个事件监听器,用于监听XML解析器在解析过程中所发生的各种错误。ErrorHandler接口下定义了如下3个方法:
error(SAXParseException exception):当解析XML文档过程中出现可恢复的错误时触发该方法。
fatalError(SAXParseException exception):当解析XML文档过程中出现不可恢复的错误时触发该方法。
warning(SAXParseException exception):当解析XML文档过程中出现警告消息时触发该方法。
下面为DOM解析器绑定一个ErrorHandler,然后再用DTD验证XML文档的有效性:
程序清单:codes\10\10.2\src\lee\DTDValidateWithHandler.java

上面的程序中为DOM解析器绑定了一个ErrorHandler,该ErrorHandler对象将负责监听XML解析器解析过程中所发出的消息,程序中的粗体字代码重写了ErrorHandler接口里的error()方法,当XML解析器解析过程中发生可恢复错误时将触发该方法。
程序中的SAXParseException是SAXException异常类的子类,程序可通过SAXParseException异常对象获取XML解析过程中的错误。
运行上面的程序,可看到图10.6所示结果。
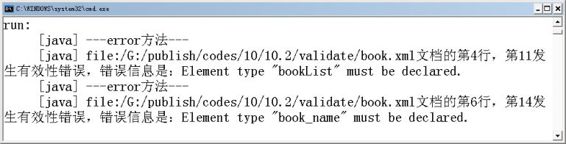
图10.6 使用ErrorHandler的效果
10.2.5 使用DOM解析XML文档
一旦获得了XML文档对应的Document对象,就可以利用DOM节点的各种方法来访问XML文档里的数据了。
Document中包含如下用来访问XML文档中的节点的方法:
Element getDocumentElement():用于获取XML文档的根节点。
Element getElementById(String elementId):用于根据XML元素的ID来获取XML元素。
NodeList getElementsByTagName(String tagname):用于根据XML元素的标签名来获取XML元素。
DOM树中的所有节点都是Node对象,每个Node对象都可能包括nodeName、nodeValue和attributes等属性,不同的Node节点对这3个属性的支持是不同的,读者可查阅Node接口的API来了解其用法。Node接口里提供了如下常用方法用于获取节点数据:
NamedNodeMap getAttributes():用于获取该节点所包含的所有属性。只有当该节点是Element时才可真正有属性,其他类型的节点调用该方法都将返回null。
NodeList getChildNodes():返回由该节点所包含的所有子节点所组成的NodeList。
Node getFirstChild():返回该节点所包含的第一个子节点。
Node getLastChild():返回该节点所包含的最后一个子节点。
String getLocalName():返回该节点的标签名的本地部分(就是标签名中的冒号后面的字符串)。
String getNamespaceURI():返回该节点的标签名中命名空间对应的URI。如果该节点没有使用命名空间,则返回null。
Node getNextSibling():返回该节点的下一个兄弟节点。
String getNodeName():返回该节点的节点名,即nodeName值。
String getNodeValue():返回该节点的节点值,即nodeValue值。
Document getOwnerDocument():返回该节点所在的Document 对象。
Node getParentNode():返回该节点的父节点。
String getPrefix():返回该节点的标签名中命名空间的前缀(就是标签名中的冒号前面的字符串)。如果没有使用命名空间,则返回null。
Node getPreviousSibling():返回该节点的上一个兄弟节点。
String getTextContent():返回该节点及其后代的文本内容。
boolean hasAttributes():返回该节点(如果它是一个元素)是否包含任何属性。
boolean hasChildNodes():返回该节点是否包含任何子节点。
在Node的所有子接口中,Element是最常用的,它代表一个XML元素,该接口下提供了如下方法来获取XML元素的内容:
String getAttribute(String name):根据属性名获取指定属性值。
Attr getAttributeNode(String name):根据属性名获取指定的属性节点。
NodeList getElementsByTagName(String name):根据标签名获取由该元素包含的所有后代元素所组成的NodeList。
String getTagName():获取该元素的标签名。
boolean hasAttribute(String name):判断该元素是否包含某个指定属性。若该元素具有名为name的默认属性(即使XML文档中没有明确指定该属性),则该方法返回true。
一般说来,使用上面这些常用方法已经可以解析一份XML文档了,下面的代码示范了如何解析XML文档内容:
程序清单:codes\10\10.2\src\lee\DomParse.java
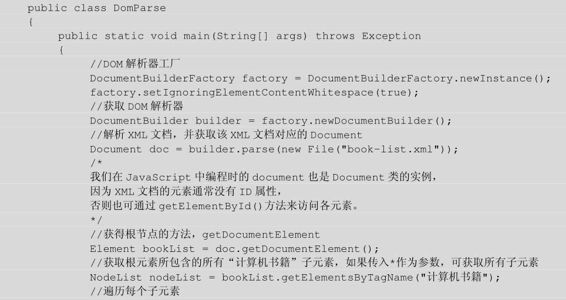

上面的程序所解析的XML文档内容如下:
程序清单:codes\10\10.2\book-list.xml

上面的程序解析XML文档的结果如图10.7所示:
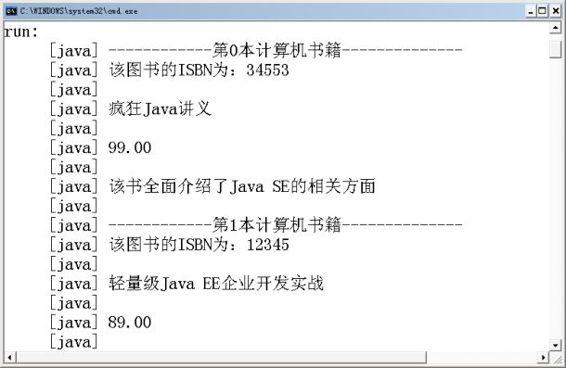
图10.7 使用DOM解析XML文档
10.2.6 使用DOM创建XML文档
利用DOM创建XML文档,基本可分为2大步:
(1)在内存中创建新的DOM树,并为DOM树添加节点。
(2)将DOM树转换成XML文档。
Document接口提供了如下常用方法来创建节点:
Attr createAttribute(String name):根据给定属性名创建属性节点。
CDATASection createCDATASection(String data):根据给定的字符串数据创建CDATA节点。
Comment createComment(String data):根据给定字符串创建注释节点。
Element createElement(String tagName):根据给定标签名创建元素。
EntityReference createEntityReference(String name):创建实体引用。
ProcessingInstruction createProcessingInstruction(String target, String data):根据给定处理指令名和处理指令属性创建处理指令。
Text createTextNode(String data):根据给定字符串数据创建文本节点。
在使用Document创建了各种类型的节点之后,可利用Node提供的各种添加节点的方法来建立节点与节点之间的结构关系,Node提供了如下常用方法来建立节点之间的结构关系:
Node appendChild(Node newChild):将newChild节点添加到当前节点的子节点列表的末尾。
Node removeChild(Node oldChild):从当前节点的子节点列表删除指定子节点。
Node replaceChild(Node newChild, Node oldChild):将当前节点的子节点列表中的oldChild替换成newChild。
Node insertBefore(Node newChild, Node refChild):在当前节点的子节点列表中refChild之前插入newChild。
Element接口里则提供了如下两个方法用于设置属性:
void setAttribute(String name, String value):添加名为name、值为value的属性。
Attr setAttributeNode(Attr newAttr):将newAttr对应的属性添加到当前元素中。
 提示
提示
笔者讲课介绍此处时总喜欢用一个比喻:我们可以把Document想象成一个文档根,每个文档根能“长”一个根节点,根节点又可“长”许多子节点,每个子节点又可“长”数量不限的子节点……依此类推,最后就可形成内存里的DOM树。
一旦在内存里成功构建了DOM树,就可利用JAXP提供的LSSerializer工具类来序列化DOM树了。所谓序列化DOM树就是将其转换成XML文本数据,该文本数据即可输出到I/O流中。LSSerializer可将DOM树转换为XML文本数据。在序列化期间所做的任何更改或修复仅影响被序列化的文本数据,对Document对象及其子对象不会有任何影响。
下列程序示范了如何利用DOM模型创建XML文档:
程序清单:codes\10\10.2\src\lee\DomCreate.java


上面的程序中的粗体字代码用于控制生成XML文档时保持良好缩进,使XML文档具有良好的可视化格式。运行上面的程序,将生成图10.8所示XML文档。
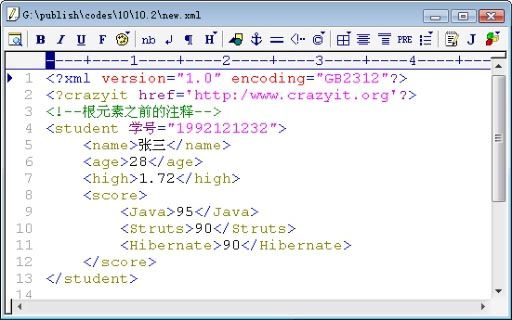
图10.8 使用DOM生成XML文档
10.2.7 使用DOM修改XML文档
使用DOM修改XML文档就简单了,只需按如下4个步骤进行即可:
(1)使用DOM解析器解析已有的XML文档。
(2)利用DOM节点之间的结构化关系找到需要修改的节点。
(3)调用各节点对象的方法修改该节点所包含的数据。
(4)使用LSSerializer再次序列化修改后的DOM树。
假设需要将图10.8所示XML文档中<name…./>节点的内容改为“孙悟空”,即可按上面4个步骤进行修改。代码如下:
程序清单:codes\10\10.2\src\lee\DomUpdate.java

上面的程序将修改后的DOM树序列化为update.xml文件,这意味着该程序运行后会多出一个update.xml文件,该文件与前面的new.xml文件基本相同,只是<name…/>节点的内容是“孙悟空”。
10.2.8 解析DTD信息
DOM使用DocumentType 对象来代表XML文档里的DTD信息,不管它们是XML文档的内部DTD,还是外部DTD,都可通过DocumentType 对象来访问。
为了获取DOM树里的DTD信息,可调用Document的getDoctype()方法,该方法返回XML文档里的DTD,包括内部DTD和外部DTD。
一旦获得了DocumentType对象,就可调用如下常用方法来获取对应DTD的相关信息:
NamedNodeMap getEntities():获取该DTD里定义的内部和外部实体。
String getInternalSubset():返回DTD里所包含内部子集的字符串,也就是返回内部DTD定义部分的字符数据。
String getName():返回DTD里定义的根元素,即紧跟在DOCTYPE关键字后面的名称。
NamedNodeMap getNotations():获取该DTD里定义的符号。
String getPublicId():返回外部DTD的公共URI。
String getSystemId():返回外部DTD的系统URI,即SYSTEM关键字后面的字符串。
假设有如下XML文档:
程序清单:codes\10\10.2\book2.xml

上面的XML文档里定义了内部DTD,还引用了另一份外部DTD文档,下面是该XML文档所引用外部DTD的代码:
程序清单:codes\10\10.2\book.dtd

下面使用如下程序来解析上面的XML文档中的DTD信息:
程序清单:codes\10\10.2\src\lee\DTDParse.Java

运行上面的程序,可看到图10.9所示界面。
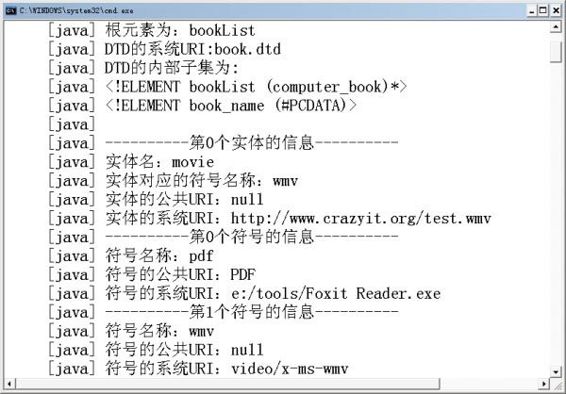
图10.9 解析DTD信息
从图10.9可以看出,上面的程序既获得了XML文档中内部DTD的信息,也获得了其中外部DTD的信息。
 学生提问:如果我想获取DTD中的元素定义、属性定义等信息该怎么办?
学生提问:如果我想获取DTD中的元素定义、属性定义等信息该怎么办?
答:DOM解析器没有提供更有效的方法来获取DTD中的元素定义、属性定义等信息。不过需要指出的是,应用程序是使用XML作为数据交换格式,并不是使用DTD作为数据交换格式。因此DOM并没有提供方法去获取DTD中更细致的信息。对于未解析实体而言,普通XML解析程序通常无法处理未解析实体所引用的数据,而要借助于符号所定义的外部程序来处理未解析实体,因此XML解析程序必须获取未解析实体所引用的外部文件,例如图10.9中的http://www.crazyit.org/test.wmv,并获取该外部文件的MIME类型或处理该外部文件的程序(根据对应的符号获取),例如上面的DTD中指定了test.wmv文件的MIME类型是video/x-ms-wmv。一旦XML解析程序获取了外部实体所引用的文件,并获得了该文件的MIME类型或处理该文件的外部程序,就可通知合适的程序来处理该外部文件了。

10.2.9 DOM和命名空间
Node接口里定义了如下几个方法用于获取命名空间相关信息:
String getLocalName():返回该节点的标签名的本地部分(就是标签名中的冒号后面的字符串)。
String getNamespaceURI():返回该节点的标签名中命名空间对应的URI。如果该节点没有使用命名空间,则返回null。
String getNodeName():返回该节点的节点名,即nodeName值。
String getPrefix():返回该节点的标签名中命名空间的前缀(就是标签名中的冒号前面的字符串)。如果没有使用命名空间,则返回null。
值得指出的是,JAXP对命名空间的支持默认是关闭的,为了让DOM解析器能正常取得XML元素、属性的命名空间信息,程序应该在创建DOM解析器之前,调用DOM解析器工厂的setNamespaceAware(true)方法启用命名空间支持。
假设有如下XML文档:
程序清单:codes\10\10.2\book3.xml
下面使用如下Java程序来解析上面的XML文档中的命名空间信息,因为上面的文件中所有元素都处于同一个命名空间之下,因此下面的解析程序只处理了根元素的命名空间信息。除此之外,下面的程序还解析了根元素所包含的多个属性的命名空间信息。
程序清单:codes\10\10.2\src\lee\NamespaceParse.java

上面的程序中的粗体字代码用于获取根元素及其中所有属性的命名空间相关信息,运行上面的程序可看到图10.10所示结果。
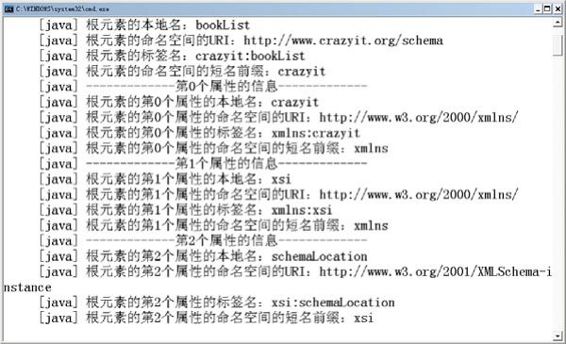
图10.10 使用DOM获取XML文档的命名空间信息
从图10.10中可以看到,DOM解析器将根元素的xmlns:prefix等当成属性处理,其中xmlns前缀对应的URI为http://www.w3.org/2000/xmlns/。
