10.6 浏览器对DOM的支持
由于DOM已经成为一种应用非常广泛的XML解析API,因此各种主流浏览器都内置了DOM解析器用于解析XML文档。
在浏览器内可通过JavaScript来解析XML文档,JavaScript是运行于浏览器之内的脚本语言,本身并没有解析XML文档的能力,而必须借助于浏览器内置的DOM支持才可解析XML文档。不同的浏览器有不同的DOM解析器实现,Internet Explorer的DOM解析器通过ActiveX控件实现。
下面的程序示范了如何在Internet Explorer和Firefox中加载和解析XML文档。在Internet Explorer中获取DOM解析器的代码如下:

对于Firefox、Mozilla和Opera等浏览器,可使用如下代码来获取DOM解析器:

DOM解析器一旦完成了对XML文档的加载,就可以面向对象的方式来访问XML文档的每个节点。接下来的解析方式与前面的DOM解析并没有太大的差异。如下HTML页面代码片段中的JavaScript代码示范了如何解析XML文档:
程序清单:codes\10\10.6\parseXML.html


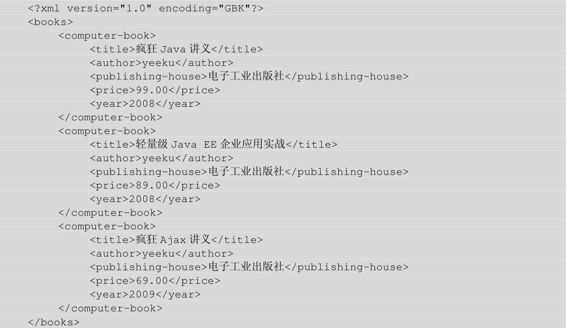
被该页面代码解析的XML文档代码如下:
程序清单:codes\10\10.6\book.xml
使用Firefox浏览上面的parseXML.html页面,可看到图10.19所示结果。
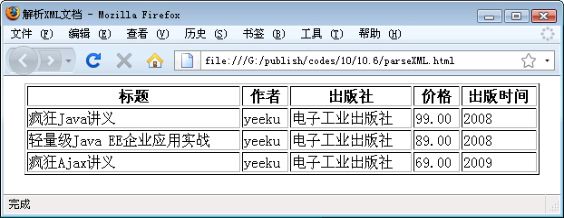
图10.19 使用Firefox解析XML文档
仔细查看上面的解析程序中的斜体字代码不难发现,为了获取<computer-book…/>元素内部5个子元素的值,不同的浏览器需要使用不同的方式:
 对于Internet Explorer浏览器而言,它自动忽略了<computer-book…/>元素内的所有空白,因此该元素内只包含<title…/>、<author…/>、<publishing-house…/>、<price…/>和<year…/>5个子元素。因此斜体字代码前半部分直接取得这5个子元素的值。
对于Internet Explorer浏览器而言,它自动忽略了<computer-book…/>元素内的所有空白,因此该元素内只包含<title…/>、<author…/>、<publishing-house…/>、<price…/>和<year…/>5个子元素。因此斜体字代码前半部分直接取得这5个子元素的值。
对于Firefox浏览器而言,它严格遵守W3C DOM规范,将完全保留<computer-book…/>元素内的所有空白,因此该元素内包括空白文本、<title…/>、空白文本、<author…/>、空白文本、<publishing-house…/>、空白文本、<price…/>、空白文本、<year…/>和空白文本共11个子元素。
