10.3 JAXP的SAX支持
SAX采用事件机制的方式来解析XML文档,采用顺序模式来快速读取XML文档,它不需要一次性将整个XML文档载入内存中,因此效率很高。
10.3.1 SAX的处理机制
SAX与DOM的解析方式完全不同,它采用事件机制的方式来解析XML文档,这是一种快速读写XML数据的方式。使用SAX解析器对XML文档进行解析时,会触发一系列事件,这些事件将被相应的事件监听器监听,从而触发相应的事件处理方法,应用程序通过这些事件处理方法实现对XML文档的访问。
SAX解析器在解析开始的时候就开始发送事件,当解析器开始处理文档开始、元素开始和文本时,负责在文档中触发一个事件,而程序员则实现这些事件的监听器,这些监听器负责处理这些事件——事件中包含了XML元素的内容,此处的内容包括了元素值和属性。
SAX解析器根本不创建任何对象,它只是在遇到XML文档的各种标签时触发对应的事件,并将XML元素的内容封装成事件传出去。图10.11显示了SAX解析XML文档的处理流程。
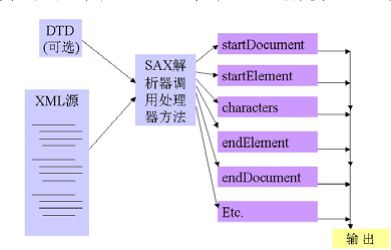
图10.11 SAX解析XML文档的流程
因为SAX解析器处理XML文档就是触发出一系列事件,所以程序员只需实现对应的事件监听器即可。在事件监听器内就可以获得XML文档的内容。
使用SAX机制解析XML文档时,SAX解析器负责在XML文档中“行走”,每当遇到文档开始、元素开始、文本、元素结束和文档结束时,都将负责向外发送事件(后文会把这类事件统称为SAX解析事件),而程序员则负责提供事件监听器来监听这些事件,并通过事件获取XML文档信息。
10.3.2 SAX解析器和监听器
JAXP为SAX解析器提供了如下2组API:
 XMLReader和XMLReaderFactory:XMLReaderFactory工厂类的createXMLReader()静态方法用于创建XMLReader。XMLReader和XMLReaderFactory位于org.xml.sax包及其子包下。
XMLReader和XMLReaderFactory:XMLReaderFactory工厂类的createXMLReader()静态方法用于创建XMLReader。XMLReader和XMLReaderFactory位于org.xml.sax包及其子包下。
SAXParser和SAXParserFactory:SAXParserFactory工厂类的newSAXParser()实例方法用于创建SAXParser。SAXParser和SAXParserFactory位于javax.xml.parsers包下。
上面两种API中的XMLReader和SAXParser都是SAX解析器,它们都定义了多个parse()方法,用于以SAX方式解析XML文档。
XMLReader定义了如下两个用于解析XML文档的方法:
void parse(InputSource input):解析InputSource输入源中的XML文档。
void parse(String systemId):解析系统URI(磁盘文件是URI的一种)所代表的XML文档。
SAXParser则定义了更多的方法用于解析XML文档:
void parse(File f, DefaultHandler dh):使用指定的dh作为监听器监听SAX解析事件,解析f文件所代表的XML文档。
void parse(InputSource is, DefaultHandler dh):使用指定的dh作为监听器监听SAX解析事件,解析is输入源中的XML文档。
void parse(InputStream is, DefaultHandler dh):使用指定的dh作为监听器监听SAX解析事件,解析is输入流中的XML文档。
void parse(String uri, DefaultHandler dh):使用指定的dh作为监听器监听SAX解析事件,解析系统URI所代表的XML文档。
对比XMLReader和SAXParser,不难发现SAXParser包含了更多的parse方法,因此用起来更加方便。SAXParser除了可解析URI和InputSource所代表的XML文档之外,还可解析File对象和InputStream所代表的XML文档,显然使用更加方便。
除此之外,调用SAXParser的parse()方法时还可传入一个DefaultHandler对象,它就是用于监听SAX解析事件的监听器。
 学生提问:为何XMLReader在调用时不需要传入SAX解析事件的监听器呢?SAX解析不是总是基于事件机制的吗?
学生提问:为何XMLReader在调用时不需要传入SAX解析事件的监听器呢?SAX解析不是总是基于事件机制的吗?
答:没错。SAX解析总是基于事件机制的。因此使用XMLReader解析XML文档时一样需要指定监听器来监听SAX解析事件。只不过XMLReader不通过parse()方法临时指定监听器。XMLReader提供了setContent Handler(ContentHandler handler)、setDTDHandler(DTDHandler handler)、setEntityResolver(EntityResolver resolver)和setErrorHandler(ErrorHandler handler)4个方法来设置监听器。也就是说,在调用XMLReader的parse()方法来解析XML文档之前,应先调用上面4个方法设置监听SAX解析事件的监听器。

通过上面老师回答中的4种设置监听器的方法可以发现,SAX解析事件一共有4种,因此需要分别设置4种监听器:
ContentHandler:监听XML文档内容处理事件的监听器。
DTDHandler:监听DTD处理事件的监听器。
EntityResolver:监听实体处理事件的监听器。
ErrorHandler:监听解析错误的监听器。
由于DOM解析过程中的错误事件也是由ErrorHandler监听器负责监听的,因此前面已经介绍了关于ErrorHandler接口的知识,此处不再赘述。
在DTDHandler接口中定义了如下两个方法:
notationDecl(String name, String publicId, String systemId):在解析DTD中的符号时将触发该方法。
unparsedEntityDecl(String name, String publicId, String systemId, String notationName):在解析DTD中的未解析实体时将触发该方法。
正如前面所提过的,解析DTD主要就是为了处理DTD中定义的未解析实体和符号,这样就可以通过相应的程序来处理未解析实体所代表的外部文件。DTDHandler里定义的这两个方法完全满足这个要求。
在ContentHandler接口中定义了如下方法:
void characters(char[]ch, int start, int length):SAX解析器处理字符数据时触发该方法。
void endDocument():SAX解析器处理文档结束时触发该方法。
void endElement(String uri, String localName, String qName):SAX解析器处理元素结束时触发该方法。
void endPrefixMapping(String prefix):SAX解析器处理元素里命名空间属性(即xmlns:prefix属性)结束时触发该方法。
void ignorableWhitespace(char[]ch, int start, int length):SAX解析器处理元素内容中可忽略的空白时触发该方法。
void processingInstruction(String target, String data):SAX解析器解析处理指令时触发该方法。
void skippedEntity(String name):SAX解析器跳过实体时触发该方法。
void startDocument():SAX解析器开始处理文档时触发该方法。
void startElement(String uri, String localName, String qName, Attributes atts):SAX解析器开始处理元素时触发该方法。
void startPrefixMapping(String prefix, String uri):SAX解析器开始处理元素里的命名空间属性(即xmlns:prefix属性)时触发该方法。
上面这些方法的意义还算比较明确,不过就算读者暂时不能准确记住每个方法在什么时候被触发也没有关系,后面会提供一个SAX解析程序,让读者看到这些监听方法分别在什么时候被触发。
通过上面的介绍不难发现,如果使用XMLReader去解析XML文档,程序员需要分别为ContentHandler、DTDHandler、EntityResolver和ErrorHandler提供实现类,然后调用XMLReader的setContentHandler()、setDTDHandler()、setEntityResolver()和setErrorHandler()方法来注册监听器,这真是一件令人沮丧的事情。
幸好JAXP提供了一个DefaultHandler类来解决这个问题,这个类实现了ContentHandler、DTDHandler、EntityResolver和ErrorHandler4个接口,并为这些接口中所包含的方法提供了空实现,它通常用于被继承,我们只需重写我们所关心的监听方法,而无须为每个方法都提供实现。
 提示
提示
DefaultHandler与ContentHandler、DTDHandler、EntityResolver和ErrorHandler的关系就是事件适配器与事件监听器的关系。如果读者忘记了事件适配器和事件监听器的关系,建议翻阅疯狂Java体系的《疯狂Java讲义》第11章。在SAX 1.0版本中,JAXP为上面4个接口提供了HandlerBase实现类,它的功能与DefaultHandler基本相似,具体可参考JAXP的API文档。
由此可见,DefaultHandler对象或其子类的对象将可同时作为ContentHandler、DTDHandler、EntityResolver和ErrorHandler 4种监听器使用,这就是SAXParser解析器调用parse()方法时只需指定一个DefaultHandler对象作为监听器即可的原因。
学生提问:XMLReader和SAXParser到底什么关系?我们到底应该用哪个呢?
答:现在是弄清XMLReader和SAXParser之间关系的时候了,XMLReader是SAX规范定义的解析器接口,ContentHandler、DTDHandler、EntityResolver和ErrorHandler也是SAX规范定义的监听器接口,因此它们通常结合在一起使用。SAXParser是JAXP对XMLReader的进一步包装,使用SAXParser可以进一步简化SAX解析编程,而DefaultHandler则是ContentHandler、DTDHandler、EntityResolver和ErrorHandler的实现类,用于简化监听器编程。讲到这里,应该使用哪组API进行SAX解析就不言而喻了:使用SAXParser和DefaultHandler明显更简单。除非开发者非常喜欢原生的SAX解析,或者需要利用某些SAX的原生特性,这才应该考虑使用XMLReader。
实际上XMLReader确实提供了setFeature(String name, boolean value)方法来设置启用某些原生特性,并提供了boolean getFeature(String name)方法来查询某原生特性是否已启用。使用这两个方法时都需要知道SAX到底支持哪些原生特性,读者可通过http://java.sun.com/javase/6/docs/api/org/xml/sax/package-summary.html页面(即org.xml.sax的包概述页面)来查看SAX到底支持哪些原生特性。
事实上,即使要使用SAX原生特性,也不一定需要使用XMLReader,因为SAXParserFactory里提供了一些更简洁的方法来控制这些特性:
void setNamespaceAware(boolean awareness):设置该工厂创建的SAX解析器支持XML命名空间。
void setSchema(Schema schema):设置该工厂创建的解析器解析XML时所使用的Schema。在需要使用XML Schema验证XML文档的有效性时应调用此方法。
void setValidating(boolean validating):设置该工厂创建的解析器在解析XML之前是否先进行有效性验证,默认不验证XML的有效性。该方法只控制使用DTD验证。
void setFeature(String name, boolean value):启用SAX的原生特性。该方法是对XMLReader的setFeature(String name, boolean value)方法的包装。
由于SAXParser和SAXParserFactory是JAXP提供的封装,因此创建SAXParser采用的也是厂方法模式:不同SAXParserFactory产生不同的SAXParser,对于如下代码:

上面的代码将生成一个SAXParserFactory子类的实例,具体产生哪个子类的实例,与DocumentBuilderFactory类的newInstance()方法的处理机制完全相同,本章10.1节已有详细说明。
对于XMLReader而言,它采用静态工厂模式来创建解析器实例——即由静态工厂方法负责决定创建XMLReader哪个实现类的实例。对于如下代码:

对于上面的代码,系统将按如下步骤来决定使用XMLReader的哪个实现类:
(1)如果设置了名为org.xml.sax.driver的属性,将使用该属性指定的实现类。
(2)如果类加载路径下任何JAR的META-INF\services下可找到org.xml.sax.driver文件,将使用该文件内容所指定的类名。这是大部分SAX解析器所使用的方法。例如用WinRAR打开xercesImpl.jar文件,进入它的META-INF\services路径下,即可看到图10.12所示窗口:
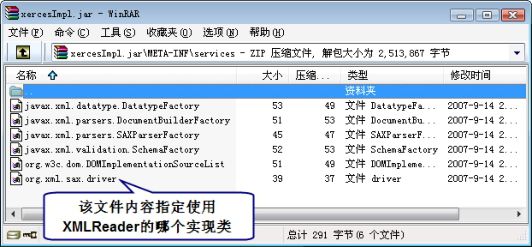
图10.12 xercesImpl.jar的XMLReader实现类设置
(3)如果上面两个步骤都没有找到合适的实现类,系统将会自动搜索并使用XMLReader的实现类。实际上,很少有SAX解析器会到这一步。
10.3.3 使用DTD验证XML的有效性
在使用SAX解析器进行解析时,同样可使用DTD来验证XML文档的有效性。
读者如果希望使用XMLReader和XMLReaderFactory这组API进行解析,则需要通过启用SAX原生特性来启用DTD验证XML文档的有效性。在程序获得XMLReader之后,通过如下代码启用DTD验证XML文档有效性即可:

读者如果使用SAXParser和SAXParserFactory这组API进行解析,则直接调用SAXParserFactory实例的setValidating(true)方法即可。代码如下:

下列代码示范了使用SAX的两套API来验证XML文档的有效性:
程序清单:codes\10\10.3\src\lee\DTDValidate.java

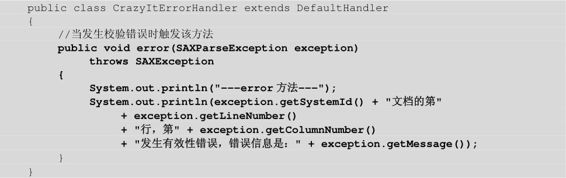
上面的程序分别使用了两种方式来验证XML文档的有效性,从上面的代码也可看出使用SAXParser和SAXParserFactory这组API更简单。上面的程序中使用了一个监听器类CrazyItErrorHandler,该监听器类继承了DefaultHandler,因此可以作为ErrorHandler使用。CrazyItErrorHandler类的代码如下:
程序清单:codes\10\10.3\src\lee\CrazyItErrorHandler.java
使用上面的验证程序来验证error-book.xml文档,由于该XML文档不满足DTD所定义的语义约束,因此运行上面的程序将看到图10.13所示结果。
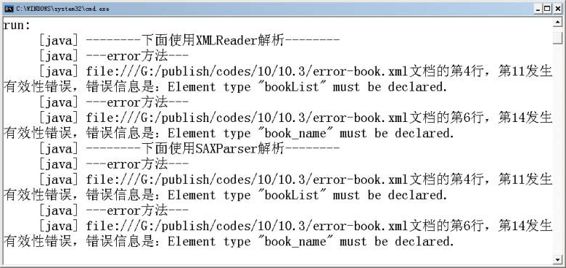
图10.13 使用DTD验证XML文档的有效性
10.3.4 使用SAX解析XML文档
根据前面的介绍,使用SAX解析XML文档也非常简单。如果使用SAXParser和SAXParserFactory这组API解析XML文档,请按如下步骤进行:
(1)通过SAXParserFactory的newInstance()方法创建SAX解析器工厂对象。
(2)调用SAXParserFactory对象的newSAXParser()方法创建SAXParser对象(SAX解析器)。
(3)调用SAXParser对象的parse()方法解析XML文档,调用该方法时需要传入一个DefaultHandler对象。
如果使用XMLReader和XMLReaderFactory这组API解析XML文档,请按如下步骤进行:
(1)调用XMLReaderFactory的createXMLReader()方法创建XMLReader对象(SAX解析器)。
(2)如果希望启用SAX解析器的原生特性,可多次调用XMLReader对象的setFeature()方法。
(3)分别调用XMLReader对象的setContentHandler、setDTDHandler、setEntityResolver和setErrorHandler方法绑定多个事件监听函数。
(4)调用XMLReader的parse()方法解析XML文档。
在使用SAX解析XML文档时,如果为解析器同时指定了ContentHandler和DTDHandler,则该解析器不仅可以获取XML文档的数据,还可以同时获取XML文档所关联DTD里的符号和未解析实体数据。下面的程序示范了如何解析XML文档和DTD信息:
程序清单:codes\10\10.3\src\lee\SaxParse.java

上面的程序分别使用了XMLReader和SAXParser解析器来解析XML文档,两个解析器共用一个CrazyItHandler对象作为监听器。CrazyItHandler由于继承了DefaultHandler,因此既可作为ContentHandler使用,也可作为DTDHandler使用。CrazyItHandler类的代码如下:
程序清单:codes\10\10.3\src\lee\CrazyItHandler.java


上面的SAX解析器所解析的XML文档代码如下:
程序清单:codes\10\10.3\book.xml
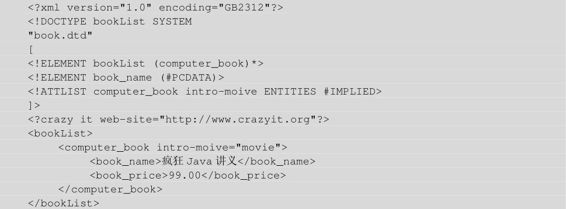
上面的book.xml文档所使用的book.dtd文档代码如下:
程序清单:codes\10\10.3\book.dtd

使用上面的解析程序来解析该XML文档时可看到图10.14所示结果。
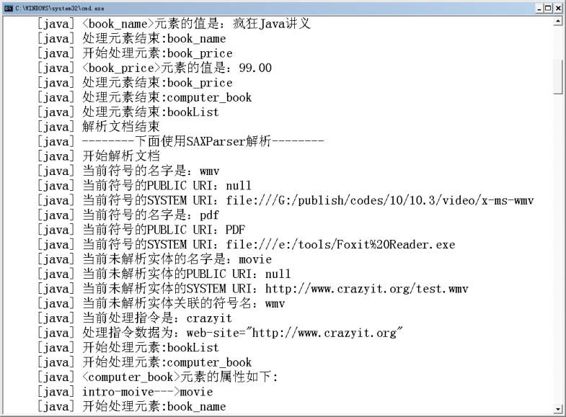
图10.14 使用SAX解析XML文档
10.3.5 SAX和命名空间
使用SAX解析方式时,命名空间信息一样通过ContentHandler监听器获得,该监听器里包含的startElement、endElement、startPrefixMapping和endPrefixMapping 4个方法用于获取命名空间相关信息。关于这些方法的说明请参阅10.3.2节的内容。
假设有如下XML文档需要解析:
程序清单:codes\10\10.3\book-ns.xml
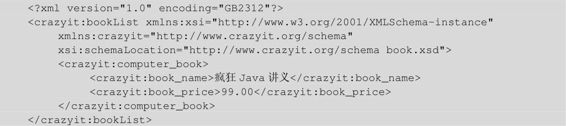
上面的XML文档中使用了命名空间支持,如果希望SAX解析器能获取该XML文档中的命名空间信息,需要做如下两方面工作:
启用SAX解析器的命名空间支持。
通过ContentHandler监听器的startElement、endElement、startPrefixMapping和endPrefixMapping 4个方法获取命名空间信息。
如果开发者使用XMLReader和XMLReaderFactory作为解析XML文档的API,可使用如下代码来启用SAX解析器的命名空间支持:

如果开发者使用SAXParser和SAXParserFactory作为解析XML文档的API,则使用如下代码来启用SAX解析器的命名空间支持:

下面的XML解析程序代码示范了通过SAX解析器来获取XML文档里的命名空间信息:
程序清单:codes\10\10.3\src\lee\NamespaceParse.java

该解析程序所使用的CrazyItNSHandler监听器类的代码如下:
程序清单:codes\10\10.3\src\lee\CrazyItNSHandler.java

使用上面的解析程序来解析前面的XML文档,可看到图10.15所示结果。
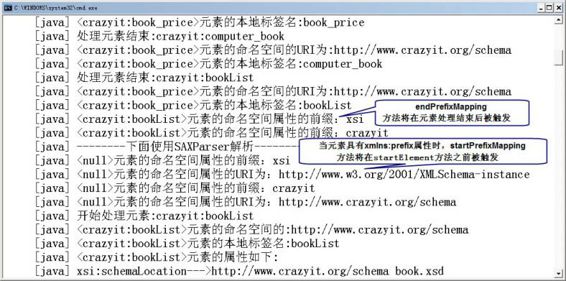
图10.15 使用SAX解析命名空间信息
由上面的运行结果可以发现:当XML文档中某个元素具有xmlns:prefix属性时(该属性用于为prefix前缀指定命名空间URI),ContentHandler监听器里的startPrefixMapping和endPrefixMapping两个监听器方法将被触发,其中startPrefixMapping方法将在处理元素之前(startElement方法被触发之前)被触发,而endPrefixMapping方法将在处理元素结束之后(endElement方法被触发之后)被触发。
