2.1.3 汇编
汇编器将汇编代码翻译为机器指令,每一条汇编语句几乎都对应一条机器指令,所以汇编器的汇编过程相对于编译器来讲比较简单,它没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表进行翻译就可以了。当然,汇编器的工作不仅包括翻译汇编指令到机器指令,除了生成机器码外,汇编器还要在目标文件中创建辅助链接时需要的信息,包括符号表、重定位表等。
1.目标文件
汇编过程的产物是目标文件,同前面的预编译和编译阶段产生的文本文件不同,目标文件的格式更复杂,其中包括链接需要的信息,所以在理解汇编过程前,我们需要了解一下目标文件的格式。Linux下的二进制文件包括可执行文件、静态库和动态库等,均采用ELF格式存储,目标文件的格式也不例外,也采用ELF格式存储。
对于32位的ELF文件来说,其最前部是文件头部信息,描述了整个文件的基本属性,除了包括该文件运行在什么操作系统中、运行在什么硬件体系结构上、程序入口地址是什么等基本信息外,最重要的是记录了两个表格的相关信息,如表格所在的位置、其中包括的条目数等。这两个表格一个是Section Header Table,主要是供编译时链接使用的,表格中定义了各个段的位置、长度、属性等信息;另外一个是Program Header Table,主要是供内核和动态加载器从磁盘加载ELF文件到内存时使用的。对于目标文件,由于其只是编译过程的一个中间产物,不涉及装载运行,因此,在目标文件中不会创建Program Header Table。
在后续内容中,我们将Segment和Section都翻译为段,读者可根据上下文区分。在有的上下文中,段指的是真正加载到内存中的Segment,而有的指的是ELF中链接时使用的Section。
下面我们通过命令readelf列出目标文件foo2.o的ELF头信息。
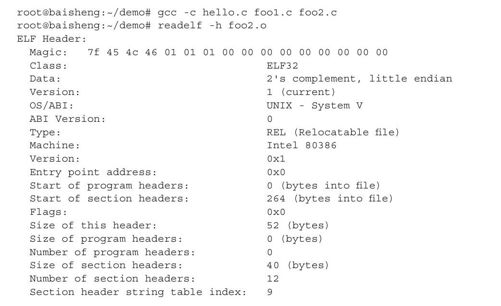
foo2.o的ELF头占用了52字节,通过ELF头可见该文件是32位的ELF文件;使用"little endian"字节序存储字节;ABI遵循UNIX-System V标准;运行在类UNIX系统上;该文件是一个"REL(Relocatable file)"类型的文件,通常,可执行文件的类型是"EXEC(Executable file)",动态共享库的类型是"DYN(Shared object file)",静态库和目标文件的类型是"REL(Relocatable file)";该目标文件是为IA32架构编译的;因为是目标文件,不存在执行的概念,所以程序入口"Entry point address"在这里不适用(同样的道理,Program Header Table也不适用);foo2.o中的Section Header Table在偏移264字节处,Section Header Table中的每个Section Header占用40字节,Section Header Table共包含12个Section Header。
在文件头信息后,就是各个段了。毫不夸张地说,ELF文件就是段的组合。大体上,段可以分为如下几类:一类是存储指令的,通常称为代码段;第二类是存储数据的,通常称为数据段。但是存储数据的又细分为两个段,已经初始化的全局数据存放在".data"段中,未初始化的全局数据存储在".bss"段。不要被BSS这个令人困惑的名称迷惑,这个名称不是非常贴切,完全是历史遗留的,".data"段和".bss"段本质并没有什么不同,但是因为未初始化的变量不包含数据,所以在ELF文件中不需要占用空间,程序装载时在内存中即时分配就可以了。所以,为了节省存储器空间,人为地将存储数据的部分划分为两个段。除了最重要的代码段和数据段外,汇编器还将在目标文件中创建辅助链接段,存储如符号表、重定位表等。
我们考察目标文件foo2.o的Section Header Table,因为排版篇幅的关系,删除了后面几列,这不影响我们讨论。有兴趣的读者,可以自行查看完整的命令输出。
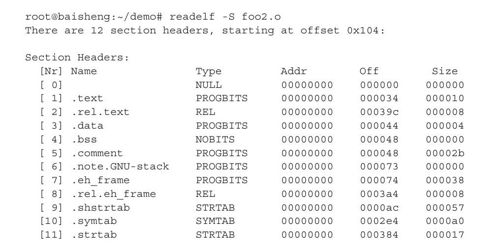
根据输出可见,目标文件foo2.o的Section Header Table中包含12个Section Header:
❑".text"段存储在文件中偏移0x34处,占据0x10个字节。读者不要将".text"段和进程的代码段混淆,进程的代码段不仅包括".text"段,在后面链接时,我们还会看到,包括.init、.fini等段存储的代码都属于代码段。这些段都被映射到Program Header Table中的一个段,在ELF加载时,统一作为进程的代码段。
❑".data"段存储在文件中偏移0x44字节处,占据0x4字节空间。
❑如我们在前面讨论的,虽然目标文件的Section Header Table中包含".bss"段,但是因为其不必记录数据,所以".bss"段在文件中只占据Section Header Table中的一个Section Header,而并没有对应的段。在加载程序时,加载器将依据".bss"段的Section Header中的信息,在内存中为其分配空间。考察程序hello的Section Header Table:
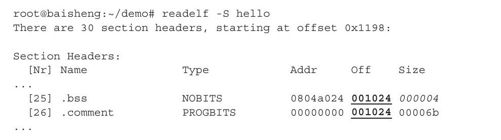
根据输出可见,".bss"段在文件中偏移为0x001024,但是占用的空间(Size)并不是0字节,而是0x4个字节,这是为什么呢?而我们再观察".comment"段在文件中的偏移,也为0x001024。也就是说,正如我们前面讨论的,".bss"段在磁盘文件中并未占据任何空间,".bss"段的Size只是告诉程序加载器在加载程序时,在内存中为该段分配的内存空间。
❑".symtab"段记录的是符号表。因为符号的名字字串长度可变,所以目标文件将符号的名字字符串剥离出来,记录在另外一个段".strtab"中,符号表使用符号名字的索引在段".strtab"中的偏移来确定符号的名字。
❑同样的道理,".shstrtab"中记录的是段的名字(sh是section header的简写)。
❑以"rel"开头的,如".rel.text"、".rel.eh_frame",记录的是段中需要重定位的符号。
❑".eh_frame"段中记录的是调试和异常处理时用到的信息。
❑".comment"、".note.GNU-stack"等段如其名字所示,都是一些"comment"和"note",无论是链接还是装载都不会用到,我们不必关心。
综上所述,目标文件的格式如图2-3所示。
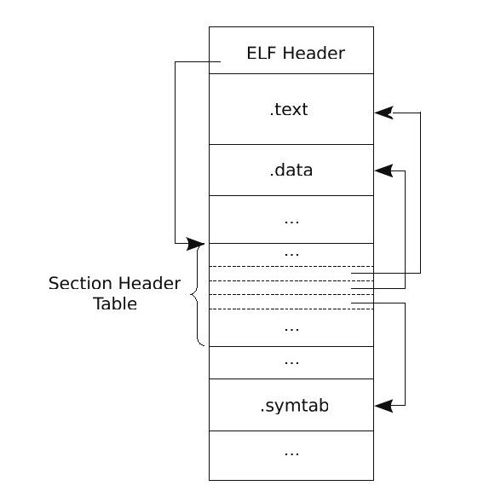
图 2-3 目标文件
2.翻译机器指令
机器指令由操作码和操作数组成,操作码指明该指令所要完成的操作,即指令的功能,例如数据传送、加法运算等基本操作。操作数是参与操作的数据,主要以寄存器或存储器地址的形式指明数据的来源或者计算结果存放的位置等。机器指令使用计算机可以识别的0和1编码,可想而知,这对程序员来说编码难度非常大。因此,为了更容易编制出程序,就出现了汇编指令。汇编指令非常接近机器指令,但是机器指令中操作码和操作数都使用更接近自然语言的符号来代替,这类自然语言符号分别称为操作码助记符和操作数助记符。人们习惯将助记符省略,直接将操作码助记符称为操作码,将操作数助记符称为操作数,读者可根据上下文区分。
汇编过程就是将助记符翻译为对应的以0和1表示的机器指令,我们也将其称为操作码和操作数的编码过程。对于IA32架构,其机器指令的格式如图2-4所示。
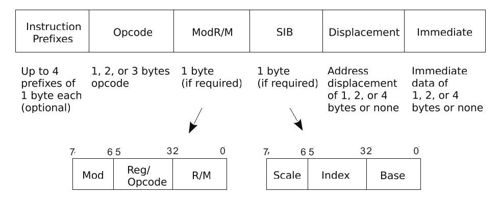
图 2-4 IA32机器指令的格式
由图2-4可见,操作码Opcode直接嵌在指令中。操作码的翻译过程相对简单,将汇编指令中的操作码助记符翻译为相应的操作码即可,操作码助记符与操作码的对应关系可根据CPU的指令手册确定。
将操作数助记符翻译为操作数的机器码相对要复杂一些,操作数并没有直接嵌在指令编码中,而是根据汇编指令使用的具体寻址方式,设置ModR/M、SIB、Displacement和Immediate各项的值,这个过程称为操作数的编码。CPU根据ModR/M、SIB、Displacement和Immediate的值,解码出操作数。
典型的操作数的编码方式包括下面几种。如果读者不太理解下面的抽象描述,没有关系,后面将结合具体的foo2.c中的函数foo2_func探讨机器指令的翻译,读者可以前后结合起来理解。
(1)操作数地址通过ModR/M中的Mod+R/M指定
ModR/M占用1字节,包含三个域:Mod、Reg/Opcode和R/M,其中Mod占两位、R/M占3位,Reg/Opcode占3位。操作数可以使用ModR/M中的Mod和R/M字段联合起来定义,寻址模式与Mod和R/M联合编码的对应关系如表2-1所示。


其中第2列表示寻址方式生成的有效地址;第3列和第4列表示对应于某个寻址方式,Mod和R/M分别对应的编码。表2-1中列出了包含直接寻址、寄存器寻址、寄存器间接寻址、基址寻址及基址变址寻址等寻址方式下ModR/M中Mod和R/M的对应的编码。如果汇编指令使用的是基址变址寻址,那么机器指令中也需要字段SIB。
以表2-1中第7行为例,假设汇编指令使用的寻址方式是"[EAX]+disp8",那么Mod应该取值01,R/M应该取值000。偏移disp8表示8位的Displacement,根据机器指令的格式,Displacement直接嵌在指令中即可。Displacement根据表示的值的范围可以使用8位、16位或者32位,这主要是出于尺寸方面的考虑。另外,在机器指令中,Displacement需要使用补码形式。也就是说,在CPU执行指令时,当解析到ModR/M这个字节时,一旦发现Mod的值是01,R/M的值是000,那么CPU就到寄存器EAX中取出其中的内容,然后再取出嵌在指令中的8位的偏移Displacement,将这两个值相加作为操作数的内存地址,从而完成操作数的解码过程。
(2)操作数通过ModR/M中的Reg/Opcode指定
ModR/M中的字段Reg/Opcode占据3位。如果在汇编指令中使用了寄存器作为操作数,那么编码时也可以使用Reg/Opcode指定操作数使用的寄存器。如果操作数不需要使用字段Reg/Opcode编码,字段Reg/Opcode也可以用于操作码的编码。表2-2列出了32位寄存器与字段Reg/Opcode取值的对应关系。

(3)操作数地址直接嵌入在机器指令中
如果在汇编指令中直接使用了操作数的地址,即所谓的直接寻址方式,那么在翻译为机器指令时,直接使用机器指令中的Displacement字段表示操作数的地址。
(4)操作数直接嵌入在指令中
如果在汇编指令中,操作数就是参与计算的数据,即所谓的立即寻址,那么在翻译为机器指令时,直接使用机器指令中的Immediate字段表示操作数。
(5)操作数隐含在Opcode中
还有一种方式,保存操作数的寄存器直接隐含在操作码Opcode中,即所谓的隐含寻址。
根据图2-4可见,除了操作码和操作数外,还有一项"Instruction Prefixes"。很难用一段话准确地描述"Instruction Prefixes",我们可以打个比方:"Instruction Prefixes"对于机器指令类似于"Modifier key"对于键盘上的按键。Shift键作为键盘上的"Modifier key"之一,如对于数字键3,当同时按下Shift键时,其值就变为了符号“#”。如同Shift键只对键盘上的某些键有修饰作用一样,"Instruction Prefixes"也只对部分指令有效。
比如对于下面的两类指令,它们的功能相同,都是在两个操作数之间传递数据。只不过第一类是在两个16位操作数之间传递数据,第二类是在两个32位操作数之间传递数据。

Intel并没有为上述两类操作分别定义两个操作码,而是使用了同一个操作码,但是使用Instruction Prefixes区分指令中的操作数是16位的还是32位的。比如在32位环境下使用了16位的操作数,那么就需要在指令前使用0x66进行标识。
以下面的汇编代码为例,汇编文件a.s中的第一条汇编代码使用了16位的寄存器,第二条汇编代码在32位寄存器间传递数据。
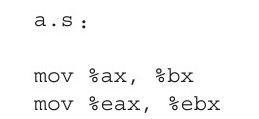
将a.s编译为目标文件,并查看对应的机器指令:

我们观察第一条指令和第二条指令的区别,因为笔者使用的是32位的计算环境,所以第一条指令多了前缀0x66。也就是说,在使用32位操作数的环境下,对于使用了16位操作数的机器指令,指令前面需要加上前缀0x66。
Intel规定了四组指令前缀:Lock and repeat prefixes、Segment override prefixes和Branchhints、Operand-size override prefix,以及Address-size override prefix。前面我们讨论的是Operand-size override prefix,其他几个不在这里讨论了,有需要的读者可以参考Intel手册。
在基本理解了从汇编指令翻译为机器指令的原理后,下面我们就结合foo2_func中的两条汇编指令具体探讨一下将汇编指令翻译为机器指令的过程。
这两条指令使用的都是mov指令,IA-32架构的mov指令说明如表2-3所示,限于篇幅,我们仅列出了部分。表2-3中有两列需要特别关注,一列是"Opcode",这个无需解释了,指令对应的操作码;另外一列是"Op/En","Op/En"是"Operand/Encoding"的简写,根据列的名称相信读者已经猜出来了,该列表示操作数的编码方式。
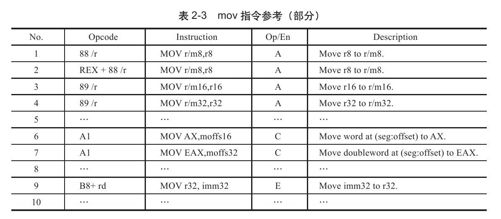
我们看到,对于MOV指令,不仅仅只有一个操作码。对于同一类操作,可能使用不同的操作数,操作数可能是寄存器,也可能是内存地址,同时操作数还会有长度之分,比如8位、16位或者32位。Intel采取的策略是为同一类指令设计了多个操作码来细分这些指令。比如下面一段代码:

我们编译并考察其机器指令:
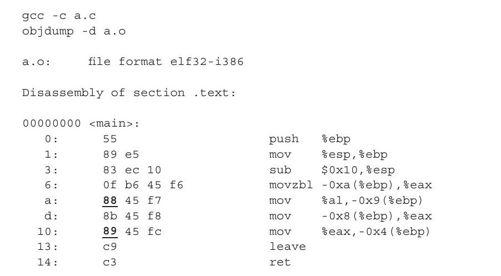
根据反汇编的输出可见,两条赋值语句,对应都是汇编中的MOV指令。但是,对于语句"x=a",即偏移a处,因为操作数是8位的,所以对应的机器码是0x88,也就是表2-3中的第1行。对于语句"y=b",对应偏移0x10处,因为操作数是32位的,所以机器码用的是0x89,即表2-3中的第4行。
表2-3中值得关注的另外一列"Op/En"指明了对应一个指令的操作数的编码方式。每一类指令都有自己的操作数编码方式,对于MOV指令,其操作数的编码方式有6类,分别用A~F来代表,如表2-4所示。
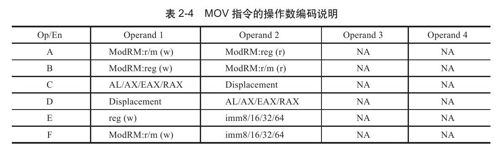
根据表2-4可见,如果采用A类编码方式,第一个操作数使用ModRM中的R/M指明,第二个操作数使用ModRM中的Reg/Opcode指明。如果使用B类编码方式,恰恰相反,第二个操作数使用ModRM中的R/M指明,第一个操作数使用ModRM中的Reg/Opcode指明。
看过了MOV指令的基本说明后,我们来讨论如下指令:
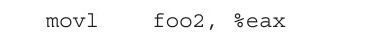
这里需要特别注意一点,编译器生成的汇编代码使用的是AT&T的格式,其操作数的顺序与Intel的汇编指令正好相反,所以这条指令中的第一个操作数"foo2"是Intel语法中的第二个操作数,这条指令中的第二个操作数"%eax"是Intel语法中的第一个操作数。
根据这条指令的两个操作数,参照表2-3,匹配表中的第7行,即"MOV EAX,moffs32",根据该行指令的说明,操作码0xA1隐含地指出了指令中的第一个操作数是寄存器EAX,也就是寻址方式中所谓的操作数隐含寻址。
根据表2-3的"Op/En"列可见,该指令的操作数的编码方式是C,参考表2-4可见,C类编码方式并不需要ModR/M,当然也不需要SIB了,而且也没有使用立即数作为操作数,亦不需要特殊的指令前缀进行修饰。而且,第一个操作数寄存器EAX是通过操作码隐含指明。所以,该条汇编代码最后转换为如下形式的机器指令:
第二个操作数"foo2"通过Displacement表示。这里,因为还没有链接,foo2的地址尚未确定,所以暂时填充0占位,在链接时将根据实际地址修改。因为是运行在32位环境下,所以地址是32位的,Displacement占用4字节。综上所述,该指令的机器码翻译为:
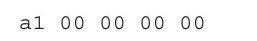
再来看指令:
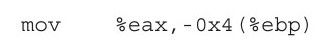
根据这条指令的两个操作数,参照表2-3可见,该指令匹配表中的第4行,即"MOV r/m32,r32",该指令的操作码为0x89。在确定了操作码后,我们再来看操作数的编码方式,根据表2-3中该指令的列"Op/En"可见,该指令使用了A类操作数编码方式。根据表2-4可见,A类编码中的第一个操作数由ModR/M中的Mod和R/M共同指明,第二个操作数由ModR/M中的Reg/Opcode指明。
指令的第一个操作数"-0x4(%ebp)",相当于[EBP]+disp8,这里Displacement为什么用8位,而不是32位呢?因为对于-4,用1字节表示足够了,使用4字节只能徒增二进制文件的尺寸。根据A类编码方式的要求,第一个操作数使用的寄存器需要由ModR/M中的Mod和R/M共同指明,参照表2-1,根据寻址模式可匹配第10行,该行中Mod为01,R/M为101,且第一个操作数中的偏移-4由Displacement表示,在机器指令中需要使用数的补码形式,-4的补码为fc。
根据A类编码方式的要求,第二个操作数由ModR/M中的Reg/Opcode指明。汇编指令的第二个操作数使用的寄存器是EAX,对照表2-2,寄存器EAX对应的Reg/Opcode值为000。
综上所述,该汇编指令对应的机器编码格式为:
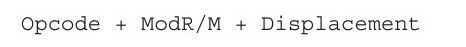
其中Opcode为0x89,ModR/M的二进制值为01 000 101,用十六进制表示为0x45,Displacement为fc,该汇编代码的机器编码为:

至此,我们通过foo2_func中的赋值语句讨论了汇编指令到机器指令的翻译过程。相信读者对机器指令(包括汇编指令)已经有了更好的理解。
我们来查看一下目标文件foo2.o中这两条汇编指令对应的真正的机器指令:
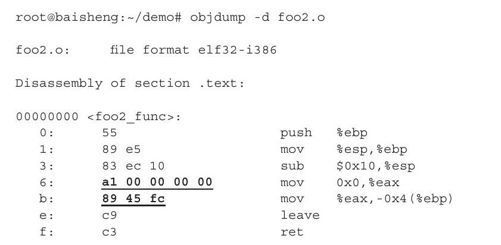
其中偏移地址0x6和0xb处,就是我们前面讨论的两条汇编指令。根据输出可见,与我们的讨论结果完全吻合。
objdump的输出是经过加工的,我们使用工具hexdump原汁原味地将目标文件foo2.o转存(dump)出来,查看其代码段部分和数据段部分。我们使用了更精确的参数控制hexdump的输出,"%04_ax"表示使用4位十六进制显示偏移;“16/1”表示每行显示16字节,逐字节解析;"%02x"表示以十六进制显示,每个字符占据两位。为了方便,读者使用参数"-C"即可。总之,要控制hexdump逐个字节解析,避免hexdump以双字节为单位进行解析,并且避免使用little-endian进行显示可能给读者造成的困惑。下面是我们截取的foo2.o的".text"段和".data"段的片段:

其中起始于偏移0x34处、占据0x10字节的加粗斜体部分正是objdump输出的foo2_func的机器指令。
注意起始于偏移0x44字节处、占据0x4字节空间的下划线标识的4字节。注意,IA32架构上,数据是按照little-endian顺序存放的,所以这4字节表示的数据是0x14,而不是0x14000000。十六进制的0x14正好是foo2.c中的全局变量foo2的初始值20。
这里转存出的".text"段和".data"段的信息与foo2.o中的Section Header Table中输出的关于".text"段和".data"段的信息也完全吻合,即".text"段起始于0x34,占据0x10字节;".data"段起始于0x44,占据0x4字节。f002.0的Section Header Table中关于这两个段的信息如下:

3.重定位表
在进行汇编时,在一个模块(这里我们将一个.c文件称为一个模块)内,如果引用了其他模块或库中的变量或者函数,汇编器并不会解析引用的外部符号。因为在汇编时,模块是独立编译的,所以对于引用的外部的符号一无所知。而且退一步说,在汇编时并没有为符号分配运行时地址(行文中有时也称为虚拟地址),所以即使汇编器找到了这些符号,也没有任何意义,这些符号的地址只是临时的,在进行链接时链接器才会为这些符号分配运行时地址。
因此,在目标文件的机器指令中,汇编器基本上是留“空”引用的外部符号的地址。然后,在链接时,在符号地址确定后,链接器再来修订这些位置,这个修订过程被称为重定位。当然除了编译时重定位,还有加载和运行时重定位,本章讨论前者,我们在第5章讨论后者。事实上,为了辅助链接器在链接时计算修订值,这些需要修订的位置并不是全部都置为0,有时这里填充的是一个Addend,这就是之所以使用引号将空引用起来的原因。下面我们将会看到这个Addend。
但是链接器并不能聪明到可以自动找到目标文件中引用外部符号的地方,所以在目标文件中需要建立一个表格,这个表格中的每一条记录对应的就是一个需要重定位的符号,这个表格通常称为重定位表,汇编器将为可重定位文件中每个包含需要重定位符号的段都建立一个重定位表。ELF标准规定,重定位表中的表项可以使用如下两种格式:

这两种格式唯一的不同是成员r_addend。这个成员一般是个常量,用来辅助计算修订值。如果使用了第一种格式,那么r_addend将被填充在引用外部符号的地址处,也就是前面所说的留“空”处。具体的体系结构可以选择适合自己的一种格式,或者两种格式都使用,只不过在不同的上下文中使用更合适的格式。IA32主要使用了前者,但是也在个别的情况下了使用了一点后者。
r_offset为需要重定位的符号在目标文件中的偏移。需要注意的是,对于目标文件与可执行文件或者动态库,这个值是不同的。对于目标文件,r_offset是相对于段的,是段内偏移;而对于可执行文件或者动态库,r_offset是虚拟地址。
r_info中包含重定位类型和此处引用的外部符号在符号表中的索引。根据符号在符号表中的索引,链接器就可以从符号表中解析出符号的地址。因为指令中包含多种不同的寻址方式,并且还要针对不同的情况,所以有多种不同的重定位类型。不同的重定位类型,重定位的方法也不同。在2.1.4节中讨论“符号重定位”时,我们将讨论编译时使用的典型的重定位类型,包括R_386_32和R_386_PC32。在第5章讨论动态重定位时,我们将讨论加载和运行时使用的典型的重定位类型R_386_GLOB_DAT和R_386_JMP_SLOT等。
了解了重定位的基本理论后,下面我们来看一下具体的实例。使用工具readelf查看目标文件hello.o的重定位表:

根据输出可见,hello.o中".text"段和".eh_frame"段中都有符号需要重定位,所以建立了两重定位表。
在".text"段的重定位表中,我们看到,目标文件hello.o引用的外部符号foo2和foo2_func分别占据表中的第一条和第二条重定位记录。根据前面目标文件hello.o的反汇编结果,foo2在偏移0xb处,foo2_func在偏移0x1b处,与这里的输出完全一致。
看过重定位表后,我们再来看看汇编器在目标文件hello.o中引用符号foo2和foo2_func处填充的Addend是什么。我们使用工具objdump查看目标文件hello.o:


根据objdump的输出可见:
❑在偏移0xb处,对应的就是变量foo2的地址,汇编器填充的Addend是0。
❑在偏移0x1b处,对应的是函数foo2_func的地址,汇编器填充的Addend是"fcffffff",因为IA32使用的是little-endian字节序,补码"fffffffc"对应的原码是4。
在引用符号foo2的位置,填充0是比较容易理解的,链接器只需要找到符号foo2的运行时地址替换这里的0就好了。但是在引用符号foo2_func的位置,为什么使用-4呢,这究竟是一个什么魔数?我们在2.1.4节中讨论“符号重定位”时,再讨论这个-4的由来。
4.符号表
既然在链接时,需要重定位目标文件中引用的外部符号,显然,链接器需要知道这些符号的定义在哪里,为此汇编器在每个目标文件中创建了一个符号表,符号表中记录了这个模块定义的可以提供给其他模块引用的全局符号。可以使用工具readelf查看文件中的符号表,如目标文件foo2.o的符号表如下:
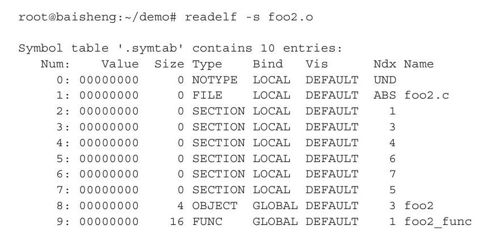
根据输出可见,foo2.o符号表包含10个符号。Value列表示的是符号的地址。前面我们提到,链接时链接器才会为符号分配地址,所以我们看到的符号的地址全部是0。Size列表示符号对应的实体占据的内存大小,如变量foo2占据4字节,函数foo2_func占据16字节。Type列表示符号的类型,如foo2类型为OBJECT,表示变量;foo2_func类型为FUNC,表示函数。Bind列表示符号绑定的相关信息,LOCAL表示模块内部符号,对外部不可见;GLOBAL表示全局符号,foo2和foo2_func都属于全局变量。Ndx列表示该符号在哪个段,如foo2在第3个段,即".data"段,foo2_func在第1个段,即".text"段。Name列表示符号的名称。
除了模块定义的符号外,符号表中也包括了模块引用的外部符号,如模块hello的符号表如下:
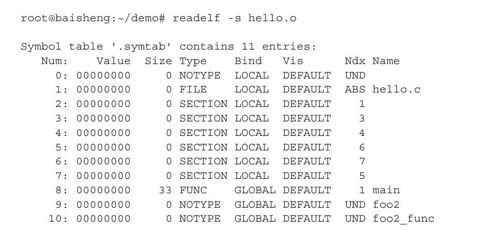
符号foo2和foo2_func都在模块foo2中定义,对于模块hello来说是外部符号,没有在任何一个段中,所以在列Ndx中,foo2和foo2_func的值是UND。UND是Undefined的缩写,表示符号foo2、foo2_func是未定义的。
在链接时,对于模块中引用的外部符号,链接器将根据符号表进行符号的重定位。如果我们将符号表删除了,那么链接器在链接时将找不到符号的定义,从而不能进行正确的符号解析。如我们将foo2.o中的符号表删除,再次进行链接,则链接器将因找不到符号定义而终止链接,如下所示:

