8.4.2 渲染Pipleline
与2D渲染相比,3D渲染要复杂得多。就如同有些复杂的绘画过程,要分成几个阶段一样,OpenGL标准也将3D的渲染过程划分为一些阶段,并将由这些阶段组成的这一过程形象地称为Pipleline。
应用程序建立基本的模型包括在对象坐标中的顶点数据、顶点的各种属性(比如颜色),以及如何连接这些顶点(如是连接成直线还是连接为三角形),等等,统一存储在顶点缓冲中,然后作为Pipeline的输入,这些输入就像原材料一样,经过Pipeline这台机器的加工,最终生成像素阵列,输出到后缓冲的BO中。
OpenGL的标准规定了一个参考的Pipeline,但是各家GPU的实现与这个参考还是有很多差别的,有的GPU将相应的阶段合并,有的GPU将个别阶段又拆分了,有的可能增加了一些阶段,有的又砍了一些阶段。但是,大体上整个过程如图8-7所示。
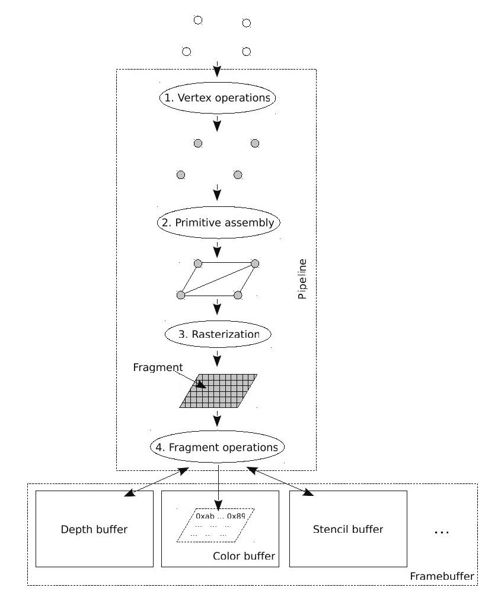
图 8-7 Pipeline
(1)顶点处理
OpenGL使用顶点的集合来定义或逼近对象,应用程序建模实际上就是组织这些顶点,当然也包括顶点的属性。Pipeline的第一个阶段就是顶点处理(vertex operations),顶点处理单元将几何对象的顶点从对象坐标系变换到视点坐标系,也就是将三维空间的坐标投影到二维坐标,并为每个顶点赋颜色值,并进行光照处理等。
(2)图元装配
显然,很多操作处理是不能以顶点单独进行处理的,比如裁减、光栅化等,需要将顶点组装成几何图形。Pipeline将处理过的顶点连接成为一些最基本的图元,包括点、线和三角形等。这个过程成为图元装配(primitive assembly)。
任何一个曲面都是多个平面无限逼近的,而最基本的是三点表示一个平面。所以,理论上,GPU将曲面都划分为若干个三角形,也就是使用三角形进行装配。但是也不排除现代GPU的设计者们使用其他的更有效的图元,比如梯形,进行装配。
(3)光栅化
我们前文提到,图形是使用像素阵列来表示的。所以,图元最终要转化为像素阵列,这个过程称为光栅化(rasterization),我们可以把光栅理解为像素的阵列。经过光栅化之后,图元被分解为一些片断(fragment),每个片段对应一个像素,其中有位置值(像素位置)、颜色、纹理坐标和深度等属性。
(4)片段处理
在Pipeline更新帧缓冲之前,Pipeline执行最后一系列的针对每个片段的操作。对于每一个片断,首先进行相关的测试,比如深度测试、模板测试。以深度测试为例,只有当片段的深度值小于深度缓存中与片段相对应的像素的深度值时,颜色缓冲、深度缓冲中的与片段相对应的像素的值才会被这个片段中对应的信息更新。
Pipeline可全部由软件实现(CPU),也可全部由硬件实现(GPU),或者二者混合,这完全取决于GPU的能力。对于GPU没有3D计算能力的,则Pipeline完全由软件实现。比如,Mesa中的_tnl_default_pipeline,即是一个纯软件的Pipeline,Pipeline中的每一个阶段均由CPU负责渲染:


对于3D计算能力比较强的GPU,如ATI的GPU,Pipeline完全由GPU实现。
而有些GPU能力不那么强大,那么CPU就要参与图形渲染了,因此,Pipeline一部分由CPU实现,一部分由GPU实现,比如基于Intel i915 GPU的Pipeline:

相比于_tnl_default_pipeline,intel_pipeline使用_intel_render_stage替换了_tnl_render_stage。
以Intel GPU为例,Pipeline的渲染过程大致如图8-8所示。
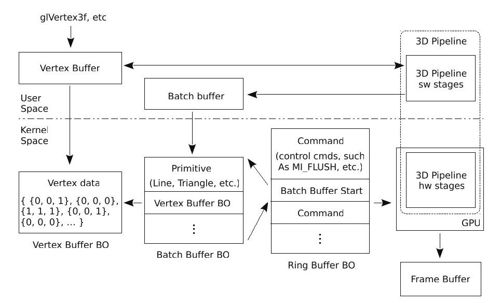
图 8-8 intel GPU 3D渲染过程
1)首先,应用程序通过glVertex等OpenGL API将数据写入用户空间的顶点缓冲。
2)当程序显示调用glFlush,或者,当顶点缓冲满时,其将自动激活glFlush,glFlush将启动Pipeline。以intel_pipeline为例,Pipeline的前几个阶段是CPU负责的,因此,所有的输入来自用户空间的顶点缓冲,计算结果也输出到用户空间的顶点缓冲;在最后的_intel_render_stage阶段,按照intel GPU的要求,从公共的顶点缓冲中读取数据,使用intel GPU的3D驱动中提供的函数,重新组织一个符合intel GPU规范的顶点缓冲。
3)glFlush调用3D驱动中的函数intel_glFlush。intel_glFlush首先将顶点缓冲和批量缓冲复制到内核空间对应的BO,实际上就是相当于复制到了GPU的显存空间,这样GPU就可以访问了。然后,内核的DRM模块将按照Intel GPU的要求建立一个环形缓冲区(ring buffer)。
4)准备好环形缓冲区后,内核中的DRM模块将环形缓冲区的信息,如缓冲区的头和尾的地址分别写入GPU的寄存器Head Offset和Tail Offset等。当DRM向寄存器Tail Offset写入数据时,将触发GPU读取并执行环形缓冲区中的命令,启动GPU中的Pipeline进行渲染。最后,GPU的Pipepline将生成的像素阵列输入到帧缓冲。
1.建立数学模型
使用OpenGL绘制,首先需要将绘制的内容使用数学模型描述出来,这个描述的过程的最终结果将保存在顶点缓冲中。我们以函数glVertex3f为例,来简单看看这个过程。
因为可能存在多个上下文,比如某个上下文使用的是软件渲染,另外一个上下文使用的是硬件渲染,因此,Mesa采用分发函数表(dispatch table)实现访问当前上下文的GL函数。
GL上下文中有一个指向结构体_glapi_table的指针Exec,用于指向当前上下文的分发函数表,具体代码如下:

函数表作为GL上下文的一部分,在创建上下文时进行初始化,具体代码如下:


其中,函数_mesa_initialize_context创建了函数表,并初始化了函数表中的部分GL函数,如glFlush。函数glVertex3f是在初始化VBO时初始化的:

在函数vbo_exec_vtxfmt_init中,函数指针Vertex3f指向的函数最后会被mesa_install_exec_vtxfmt安装到函数表中,对应函数glVertex3f。
我们先来看看函数vbo_Vertex3f的实现:

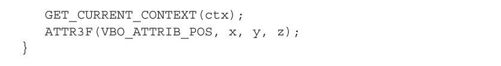
根据宏TAG的定义,显然,TAG(Vertex3f)就是vbo_Vertex3f的函数实现。其中宏ATTR3F的定义如下:

根据宏ATTR的定义可见,vbo_Vertex3f就是将数学模型的相关数据写入顶点缓冲。
了解了函数vbo_Vertex3f的实现后,我们看看_mesa_install_exec_vtxfmt是如何将其安装到函数表的:

函数SET_Vertex3f的相关代码如下:


因为宏_gloffset_Vertex3f的定义为136,所以宏SET_by_offset设置函数表中第136项的函数指针指向函数vbo_Vertex3f。我们来看看GL函数表中的第136项的函数指针:

我们看到函数表中的第136项是Vertex3f,而不是glVertex3f,是不是很困惑?
事实上,由于采用这种跳转函数表的方式,给GL函数调用带来许多不必要的开销,因此,Mesa进行了必要的优化。比如,在IA32平台上,Mesa使用汇编语言实现OpenGL API规定的这些函数。相比使用C语言,使用汇编语言实现的函数编译后的机器指令要更精简一些,相关代码如下:

因为要处理多种情况,再加上一些额外的汇编伪指令,所以代码比较复杂,为了增加可读性,笔者进行了必要的删减。
从第1行代码处开始,Mesa使用宏GL_STUB开始定义OpenGL API规定的函数,其中第3行代码定义的就是函数glVertex3f。
注意定义函数使用的宏GL_STUB,其在第6~10行代码定义。其中第7行代码定义的是函数名,代码中宏GL_PREFIX在第12行代码定义,就是给函数名称前加个前缀gl,所以

展开后为:
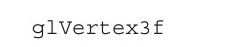
可见,第3行代码使用宏GL_STUB定义的就是函数glVertex3f。
我们再来看看宏GL_STUB定义的函数体。第9行代码获取函数表所在的基址,然后跳转到偏移off处,见第10行代码。以函数glVertex3f为例,根据第3行代码可见,这个偏移是136。也就是说,当程序执行函数glVertex3f时,其将跳转到函数表中第136项指针指向的函数。
而前面函数SET_Vertex3f正是将函数vbo_Vertex3f安装到了函数表的第136项。也就是说,当执行函数glVertex3f时,实际跳转到的函数就是vbo_Vertex3f。
2.启动Pipeline
在建模后,应用将顶点数据存入了顶点缓冲,加工需要的原材料已经准备好了,接下来就需要开动Pipeline这台加工机器了。那么,这个机器什么时候运转起来呢?通常是在程序中显示调用函数glFlush时。当然,一旦顶点缓冲已经充满了,也会自动调用glFlush。读者可能有个疑问:我们编写程序时,有时并没有显示调用glFlush啊?没错,那是通常情况下,我们使用的都是启用了双缓冲的OpenGL,即前缓冲和后缓冲。对于启用双缓冲的OpenGL程序,OpenGL规定,当程序在后缓冲渲染完成后,请求交换到前后缓冲时,使用OpenGL的API glXSwapBuffers,而实际上,函数glXSwapBuffers已经替我们调用了glFlush。
当调用函数glFlush时,将通过函数表跳转到函数_mesa_flush:

函数_mesa_flush首先使用宏FLUSH_CURRENT启动CPU负责的Pipeline。在CPU负责的Pipeline运行完毕后,_mesa_flush调用驱动中的Flush函数将用户空间的顶点缓冲、批量缓冲的数据复制到内核空间,并启动GPU中的Pipeline。
宏FLUSH_CURRENT调用函数_tnl_draw_prims开动Pipeline,具体代码如下:

我们看到,对于每个绘制原语,函数_tnl_draw_prims分别启动Pipeline对其进行加工。对于Intel GPU的3D驱动,RunPipeline指向的函数是intelRunPipeline:

函数_tnl_run_pipeline依次运行Pipeline中每个阶段的run函数,一旦某个阶段的函数run返回False,则表明整个Pipeline运行结束。
3.Pipeline中的软件计算阶段
所谓的软件计算阶段,是指计算过程是由CPU来负责的。CPU从上下文中获取上个阶段的状态信息,进行计算,然后将计算结果保存到上下文中,作为下一个阶段的输入。上下文的数据抽象为结构体TNLcontext,其中非常重要的一个成员是结构体vertex_buffer:


顾名思义,结构体vertex_buffer是保存顶点数据的。软件计算阶段的所有顶点数据来自这个vertex_buffer,经过变换后的顶点数据也输出到这个vertex_buffer中。
以intel_pipeline中的texgen阶段为例:

第9行代码计算纹理的坐标,并将结果保存到store的数组texcoord中。而在函数TexgenFunc的计算过程中,使用了来自TNLcontext中的结构体vertex_buffer中的各种状态信息。
计算完成后,函数run_texgen_stage也将这个阶段的计算结果保存到了TNLcontext中的结构体vertex_buffer中,如代码第11~12行所示。
4.Pipeline中GPU相关的阶段
很难要求所有厂家的GPU都按照一个标准设计,所以在启动GPU中的硬件阶段之前,需要将OpenGL标准规定的标准格式的顶点缓冲中的数据按照具体的GPU的要求组织一下,然后再传递给GPU。下面我们就以Intel i915系列GPU的Pipeline中的_intel_render_stage为例,看看其是如何为GPU准备批量缓冲的。
前面我们在函数_tnl_run_pipeline中看到,Pipeline在运行时,是依次调用各个阶段的run函数来运行各个阶段的。_intel_render_stage阶段的run函数是intel_run_render:


其中,代码第4~11行的for循环,将依次调用特定GPU相关的函数按照GPU要求的格式重新组织顶点缓冲。以Intel GPU的3D驱动为例,其另外分配了与驱动相关的顶点缓冲存储重新组织顶点数据:
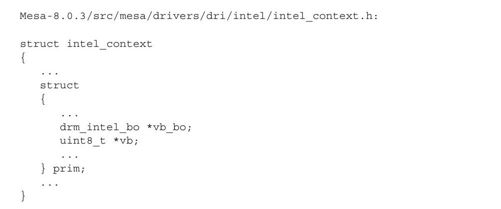
在结构体prim中,vb指向的是用户空间的顶点缓冲,vb_bo指向的是内核空间创建的保存顶点数据的BO。
intel i915系列GPU的3D驱动中组织三角形的顶点缓冲的函数为intel_draw_triangle:

函数intel_draw_triangle使用宏COPY_DWORDS向顶点缓冲中指定偏移处写入顶点数据。对于每一个三角形来说都包括三个顶点数据,因此调用三次宏COPY_DWORDS,将三角形的三个顶点写入了顶点缓冲。
处理完顶点缓冲后,函数intel_run_render就将开始为GPU组织批量缓冲。Intel GPU的3D驱动中批量缓冲的数据抽象如下:
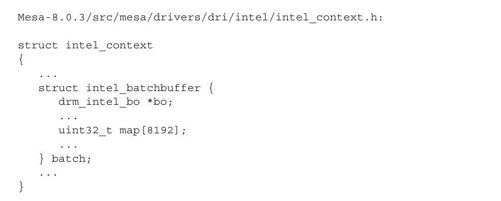
在结构体intel_batchbuffer中,数组map就是用户空间中的批量缓冲,bo指向的就是内核空间中的保存批量数据的BO。可见,3D驱动中使用批量缓冲的方式与2D驱动中的基本相同。
函数intel_run_render在最后调用了宏INTEL_FIREVERTICES,开启了批量缓冲的生成过程:

函数指针flush指向函数intel_flush_prim:

这里,我们再次看到与2D驱动中类似的宏定义(如OUT_BATCH等),它们基本与2D驱动中的定义完全相同,我们不再展开分析这些宏定义了。在上述组织批量缓冲的代码片段中:
1)第6行代码在批量缓冲中填充了发给GPU的3D命令的指令代码(opcode);
2)第8行代码在批量缓冲中填充了引用的保存顶点数据的BO;
3)第12~16行代码在批量缓冲中填写了渲染原语的相关信息,比如绘制的是三角形还是线段等;
4)第17行代码指明了绘制这个原语需要的顶点数据在保存顶点数据的BO中的偏移。
至此,用户空间中的批量缓冲也准备好了。下一步,就是将用户空间的数据复制到内核空间的BO,并启动GPU中的Pipeline。
5.复制顶点数据和批量数据到内核空间
在Pipeline的软件阶段,所有阶段的计算结果都保存在用户空间,为了启动Pipeline的硬件阶段,显然需要将这些数据复制到内核空间的BO,这样GPU才可以访问。_mesa_flush最后将调用3D驱动中的函数_intel_batchbuffer_flush进行复制:

我们先来看一下函数finish_batch。对于i915来说,其指向的函数是intel_finish_vb:

函数drm_intel_bo_subdata我们已经见过了,其将用户空间的顶点缓冲中的数据复制到内核空间中保存顶点数据的BO。
接下来,再来看函数_intel_batchbuffer_flush中调用的do_flush_locked:


函数do_flush_locked首先调用drm_intel_bo_subdata将用户空间的批量缓冲中的数据复制到内核空间中保存批量数据的BO。至此,用户空间的顶点缓冲和批量缓冲中的数据都被复制到内核空间的BO。
在将用户空间的数据复制到内核空间中的BO后,do_flush_locked调用库libdrm中的函数drm_intel_bo_mrb_exec通知GPU启动其Pipeline开始渲染,这个过程我们下一节讨论。
6.启动GPU中的Pipeline
将数据复制到内核空间的BO后,接下来就需要通知GPU来读取这些数据,并执行GPU中的Pipeline。以Intel GPU为例,其规定需要将批量数据组织到一个环形缓冲区中,然后GPU从环形缓冲区中读取并执行命令,如图8-9所示。
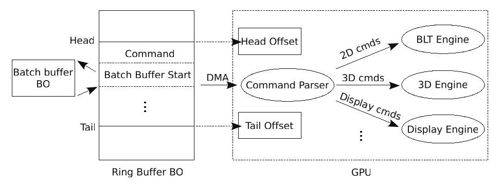
图 8-9 GPU命令流
环形缓冲区也只是从内存中分配的一块用于显存的普通存储区,所以,当内核中的DRM模块组织好其中的数据后,GPU并不会自动到环形缓冲区中读取数据,而是需要通知GPU来读取。
那么内核如何通知GPU呢?熟悉驱动开发的读者应该比较容易猜到,方法之一就是直接写GPU的寄存器。Intel GPU为环形缓冲区设计了专门的寄存器,典型的包括Head Offset、Tail Offset等。其中寄存器Head Offset中记录环形缓存区中有效数据的起始位置,寄存器Tail Offset中记录的则是环形缓存区中有效数据的结束位置。
一旦内核中的DRM模块向寄存器Tail Offset中写入数据,GPU就将对比寄存器Head Offset和Tail Offset中的值。如果这两个寄存器中的值不相等,那么就说明环形缓冲区中已经存在有效的命令了,GPU中的命令解析单元(Command Parser)通过DMA的方式直接从环形缓冲区中读取命令,并根据命令的类型,定向给不同的处理引擎。如果是3D命令,则转发给GPU中的3D引擎;如果是2D命令,则转发给GPU中的BLT引擎;如果是控制显示的,则转发给Display引擎;等等。
理解了相关原理后,下面我们就来看看DRM中具体的实现。在函数drm_intel_bo_subdata将数据复制到内核空间的BO后,do_flush_locked调用了函数drm_intel_bo_mrb_exec向内核DRM模块发送命令DRM_IOCTL_I915_GEM_EXECBUFFER或者DRM_IOCTL_I915_GEM_EXECBUFFER2(依据GPU的具体情况)。以DRM模块中处理命令DRM_IOCTL_I915_GEM_EXECBUFFER2的函数i915_gem_execbuffer2为例,组织并启动GPU读取环形缓冲区的相关代码如下:

注意函数i915_dispatch_execbuffer中的函数intel_ring_emit,读者一定想到了组织批量缓冲的宏OUT_BATCH的定义,没错,这里就是在填充环形缓冲区。
在组织好环形缓冲后,i915_dispatch_execbuffer调用了函数intel_ring_advance扣动了GPU的扳机,相关代码如下:


以i915系列为例,GPU的相应寄存器在CPU地址空间中占据的地址如下:

根据Intel的GPU的手册,地址"0x02000+0x30"恰恰就是GPU的寄存器Tail Offset在CPU的地址空间中分配的地址。
根据上述分析可见,内核的DRM模块通过写GPU的寄存器Tail Offset启动了GPU中的Pipeline。最后Pipeline会将生成的图像的像素阵列输出到后缓冲的BO。
