4.2 initramfs原理探讨
在2.4以及更早版本的内核中,内核使用的是initrd。initrd是基于ramdisk技术的,而ramdisk就是一个基于内存的块设备,因此initrd也具有块设备的一切属性。比如initrd容量是固定的,一旦创建initrd时设定了一个大小,就不能再进行动态调整。而且,如同块设备一样,initrd需要按照一定的文件系统格式进行组织,因此制作initrd时需要使用如mke2fs这样的工具“格式化”initrd,访问initrd时需要通过文件系统驱动。更重要的是,虽然initrd是一个伪块设备,但是从内核的角度看,其与真实的块设备并无区别,因此,内核访问initrd也需使用缓存机制,显然这是多此一举的,因为本身initrd就在内存中。
鉴于ramdisk机制的种种限制,Linus Torvalds提出了一个想法:能否将cache当作一个文件系统直接挂载使用?基于这个想法,Linus Torvalds基于已有的缓存机制实现了ramfs。ramfs与ramdisk有着本质的区别,ramdisk本质上是基于内存的一个块设备,而ramfs是基于缓存的一个文件系统。因此,ramfs去除了前述块设备的一些限制。比如,ramfs根据其中包含的文件大小可自由伸缩;增加文件时,自动分配内存;删除文件时,自动释放内存。更重要的是,ramfs是基于已有的缓存机制,因此不必再像ramdisk那样需要和缓存之间进行多余的复制一环。
伴随着ramfs的出现,从2.6开始,内核开发人员基于ramfs开发了initramfs替代initrd。那么initramfs是怎样工作的呢?
当2.6版本的内核引导时,在挂载真正的根文件系统之前,首先将挂载一个名为rootfs的文件系统,并将rootfs的根作为虚拟文件系统目录树的总根。那么为什么要使用rootfs这么一个中间过程呢?原因之一还是为了解决鸡和蛋的问题。内核需要根文件系统上的驱动以及程序来驱动和挂载根文件系统,但是这些驱动和程序有可能没有编译进内核,而在根文件系统上。如果不借助第三方,内核是没有办法挂载真正的根文件系统的。而rootfs虽然名称为rootfs,但是并不是什么新的文件系统,事实上,其就是一个ramfs,只不过换了一个名称。换句话说,rootfs是在内存中的,内核不需要特殊的驱动就可以挂载rootfs,所以内核使用rootfs作为一个过渡的桥梁。
在挂载了rootfs后,内核将Bootloader加载到内存中的initramfs中打包的文件解压到rootfs中,而这些文件中包含了驱动以及挂载真正的根文件系统的工具,内核通过加载这些驱动、使用这些工具,实现了挂载真正的根文件系统。此后,rootfs也完成了历史使命,被真正的根文件系统覆盖(overmount)。但是rootfs作为虚拟文件系统目录树的总根,并不能被卸载。但是这没有关系,前面我们已经谈到了,rootfs基于ramfs,删除其中的文件即可释放其占用的空间。
4.2.1 挂载rootfs
在讨论具体的挂载rootfs时,因为涉及了一些文件系统相关的概念,因此,为了更好地理解文件系统相关的概念,我们有必要先来了解一下文件系统的物理组织结构,以期对这些抽象的概念有个具体的认识。
以ExtX(X=2,3,4)文件系统为例,其在存储介质上按照图4-1所示进行组织。虽然用于不同操作系统的文件系统其物理存储结构是不同的,但是Linux的虚拟文件系统通过为这些文件系统建立中间适配层,模拟这里介绍的概念来实现对这些文件系统的支持。

图 4-1 ExtX文件系统的组织结构
ExtX文件系统使用块(Block)作为基本存储单元。ExtX支持1024、2048和4096字节大小的块,块的大小是在创建文件系统时指定的,如果没有明确指出,mke2fs将使用默认大小。ExtX文件系统将整个分区分成多个块组(Block Group),除了最后一个块组,其他块组都包含相同数量的块。下面介绍每个块组包含的部分。
(1)超级块(Super Block)
超级块描述整个文件系统的信息,包括Inode总数,空闲Inode数量,每个块组包含的Inode的数量;块的总数,空闲块的数量,每个块组包含的块的数量,块的大小;挂载的次数、最近一次挂载的时间等。
(2)块组描述符(Group Descriptors)
块组描述符包含所有块组的描述。每个块组描述符存储一个块组的描述信息,包括块组中块位图所在的块、索引节点位图所在的块、索引节点表所在的块等等。
(3)块位图(Block Bitmap)
块位图用来描述块组中哪些块已用、哪些块空闲。其中每个位对应本块组中的一个块,这个位为1表示该块已用,为0表示该块空闲可用。
(4)索引节点位图(Inode Bitmap)
和块位图类似,索引节点位图用来描述索引节点表中哪些Inode已用、哪些Inode空闲。其中每个位对应索引节点位图中的一个Inode,这个位为1表示该Inode已用,为0表示该Inode空闲可用。
(5)索引节点表(Inode Table)
一个文件除了需要存储数据以外,一些描述信息也需要存储,如文件类型(常规文件、目录等)、权限、文件大小、创建/修改/访问时间等,这些信息存储在Inode中而不是数据块中。每个文件都有一个对应的Inode,一个块组中的所有Inode组成了索引节点表。除了文件属性信息外,Inode中还记录了存储文件数据的数据块。
(6)数据块(Data Block)
数据块中存储的就是文件的数据。但是对于不同的文件类型,数据块中存储的内容是不同的,以常规文件和目录为例:
❑对于常规文件,数据块中存储的是文件的数据。
❑对于目录,数据块中存储的是该目录下的所有文件名和子目录名。
当然了,不是所有的文件都需要数据块,如设备文件、socket等特殊文件将相关信息全部保存在Inode中,就不需要数据块存储数据。
因为超级块和块组描述符是文件系统的关键信息,所以每个块组中都包含一份冗余的备份。ExtX文件系统也允许在某些特殊的情况下,除了第0个块组外,其余的块组可以不包含超级块和块组描述符的备份。用户在创建文件系统时可以通过命令行参数告诉工具mke2fs。
Linux的虚拟文件系统将文件系统组织为树形结构。在初始化阶段,内核挂载rootfs文件系统,虚拟文件系统从无到有,rootfs的根作为虚拟文件系统这棵大树中的第一个节点,自然成为所有后来创建的节点的祖先。也就是说,虚拟文件系统目录树的根就是rootfs的根。
本质上,rootfs就是一个ramfs文件系统,根据下面rootfs的文件系统类型的定义就可看出这一点:

根据rootfs中mount的具体实现—rootfs_mount可见,创建rootfs超级块使用的函数恰恰是创建ramfs文件系统的函数ramfs_fill_super,这从侧面表明了rootfs就是ramfs。
在内核引导过程中,将调用mnt_init挂载rootfs,代码如下所示:

mnt_init首先调用init_rootfs向内核中注册了rootfs文件系统,代码如下所示:

然后,mnt_init调用init_mount_tree挂载rootfs,代码如下所示:

挂载rootfs的过程是由do_kern_mount来完成的,该函数所作的工作主要有以下几个方面。
(1)创建代表rootfs的mount
Linux的文件系统是按照树形组织的,不同的文件系统都可以挂载到这个树中的任何一个目录上来。内核使用数据结构mount记录具体的文件系统与虚拟文件系统这棵大树之间的关系,mount起到一个承上启下的作用,其中的mnt_mountpoint指向文件系统的挂载点,mnt_parent指向挂载点所在文件系统的mount,mnt_root指向要挂载的文件系统的根。所以do_kern_mount需要为rootfs创建一个mount,因为rootfs是整个虚拟文件系统中第一个挂载的文件系统,所以这个mount实例是没有父亲的,其指向父亲mount成员的mnt_parent指向其自身,指向rootfs挂载点的成员mnt_mountpoint指向rootfs自己的根mnt_root。
(2)创建rootfs的超级块
超级块用于描述整个文件系统信息,某种意义上,超级块就代表了整个文件系统,所以挂载文件系统时,需要创建超级块。对于一个常规的文件系统,内核将从存储介质上读入超级块信息。但是ramfs是一个基于内存的文件系统,并不存在所谓的存储介质,但是前面我们讨论的ExtX的文件系统的基本概念依然是适用的,ramfs虽然不能从存储介质上读入超级块信息,但是会模拟出一个超级块。
(3)创建rootfs根节点的Inode
内核也需要从文件系统中读入rootfs文件系统根节点的Inode信息。但是,与创建超级块同样的道理,对于ramfs来说,也是在内存中模拟一个根节点的Inode信息。
(4)创建rootfs根节点的dentry
虽然在文件系统中,每个文件都有一个Inode(对于那些没有的,Linux将模拟Inode,以使这些文件系统能够挂载到虚拟文件系统中),但是这个Inode主要是记录文件的数据块以及属性信息,而并没有记录文件间关系的信息。所以,内核设计了结构体dentry,dentry中记录了该文件的父节点和子节点,从而可以将文件挂载到虚拟文件系统树中。dentry在物理存储介质中并没有对应的实体,而只存在于内存中。为了提高搜索文件的效率,内核会缓存文件系统中最近访问的dentry。
挂载rootfs后,内核初始虚拟文件系统的结构如图4-2所示。
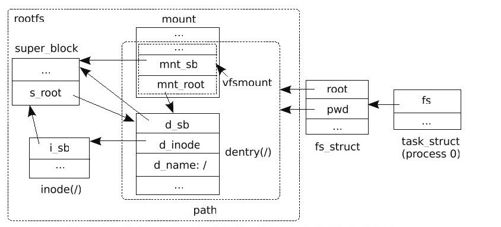
图 4-2 挂载rootfs后内核初始虚拟文件系统的结构
在虚拟文件系统中,通过文件系统的超级块、文件系统的根节点,再加上文件的dentry,就可以在虚拟文件系统中唯一确定文件的位置了。为了程序实现上的方便,内核中设计了结构体vfsmount和path。vfsmount“封装”了文件系统的超级块、文件系统的根节点等。path“封装”了mount和dentry。
事实上,虚拟文件系统这棵代表整个文件系统的大树的根对用户并不可见,我们平时在进程中所见到的根目录,仅是这棵树上的一个分支而已。因此我们看到内核中文件系统中有namespace的概念,就是每个进程都有属于自己的文件系统空间,现实中多数进程的文件系统的namespace都是相同的。进程在任务结构体task_struct中的fs_struct中记录进程的文件系统的根,也就是进程的文件系统的namespace,init_mount_tree调用set_fs_root就是这个目的。当然,此时的current指向的是内核的原始进程,即进程0。
至此,通过挂载rootfs,虚拟文件系统的根目录已经建立起来,根目录已经可以容纳文件了。所以,接下来内核解压initramfs的内容到虚拟文件系统的根中,利用initramfs中的内容挂载并切换到真正的根文件系统。
