8.3.3 CPU渲染
根据上节讨论的函数uxa_poly_fill_rect,我们看到,GPU并不是接收全部的绘制实心矩形的操作。对于不满足GPU条件的实心矩形,则将求助于CPU绘制,对应的函数是uxa_check_poly_fill_rect:

BO是由DRM模块在内核空间分配的,因此运行在用户空间的X(2D驱动)要想访问这个内存,必须首先要将其映射到用户空间,这是由函数uxa_prepare_access来完成的。然后,X使用CPU在映射到用户空间的BO上进行绘制。看到以fb开头的函数fbPolyFillRect,读者一定猜到了,这就是X的fb层的函数,而fb层正是软件渲染的实现。
(1)映射BO到用户空间
函数uxa_check_poly_fill_rect调用uxa_prepare_access将BO映射到用户空间:

在UXA(uxa_ops)中,指针prepare_access指向的函数是intel_uxa_prepare_access:
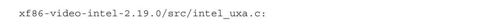

函数intel_uxa_prepare_access通过libdrm库中的函数drm_intel_gem_bo_map_gtt申请内核中的DRM模块将保存前缓冲的像素阵列的BO映射到用户空间:

看到熟悉的函数mmap,读者应该一切都明白了。从CPU的角度看,BO与普通内存并无区别,所以,映射BO与映射普通内存完全相同。其中bufmgr_gem->fd指向的就是代表BO的共享内存。
(2)使用CPU在映射到用户空间的BO上进行绘制
我们再来简单看看软件渲染函数fbPolyFillRect的实现:

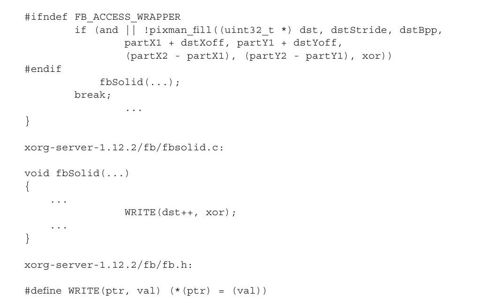
根据上面的代码可见,X的软件渲染层(即fb这一层),或者借助库pixman中的API,或者自己直接操作像素数组,完成图形的绘制。其原理非常简单,就是直接设置像素数组中的颜色值或索引。
经过对2D渲染的探讨,我们看到,所谓的软件渲染和硬件加速,本质上都是生成图像的像素阵列,只不过一个是由CPU来计算的,另外一个是由GPU来计算的。当然,对于硬件加速,CPU要充当一个翻译,将数学模型按照GPU的要求翻译为其可以识别的指令和数据。
