8.3.2 GPU渲染
GPU渲染,也就是我们通常所说的硬件加速,从软件的层面所做的工作就是将数学模型按照GPU的规定,翻译为GPU可以识别的指令和数据,传递给GPU,生成像素阵列等图像密集型计算则由GPU负责完成。可见,当使用GPU进行渲染时,在软件层面,实质上就是组织命令和数据而已。
Intel GPU的2D驱动是如何将这些命令和数据传递给GPU的呢?读者一定想到了BO。在Intel GPU的2D驱动中,定义了使用了一种所谓的批量缓冲来保存这些命令和数据,这里所谓的批量就是将驱动准备命令和数据放到这个缓冲,然后批量地让GPU来读取,这就是批量缓冲的由来。批量缓冲的相关定义在结构体intel_screen_private中:

在结构体intel_screen_private中,数组batch_ptr是X(准确地说是2D驱动)在用户空间使用的组织命令和数据的地方,指针batch_bo则指向内核空间保存批量缓冲数据的BO。2D驱动将相关的命令和数据组织在数组batch_ptr中,然后将数组batch_ptr中的数据复制到batch_bo指向的内核空间中的BO中,供GPU来读取。
2D驱动的代码中为了方便,也定义了几个操作批量缓冲的宏,典型的有如下的OUT_BATCH和OUT_RELOC_PIXMAP_FENCED:

宏OUT_BATCH将命令或者数据写入数组batch_ptr,宏OUT_RELOC_PIXMAP_FENCED将BO的在GPU地址空间中的虚拟地址写入数组batch_ptr。
接下来,我们以具体的绘制方法miPolyRectangle为例,讨论2D驱动如何使用GPU进行绘制,也就是我们通常所说的硬件加速,具体代码如下:

根据不同的绘制条件,函数miPolyRectangle将绘制矩形的动作进行了拆分,拆分的目的是选择最合适的绘制方式进行绘制。这个拆分方法不依赖于任何具体硬件,因此,X将这个拆分过程放到mi层中。
如果矩形的线性是实心填充的,且线段交汇处是尖角(JoinMiter)风格的,并且宽度不为0,那么使用方法PolyFillRect绘制,见代码第4~9行。否则,使用方法Polylines绘制,如代码第10~14行所示。
以PolyFillRect为例,其在UXA(即uxa_ops)中对应的具体函数是uxa_poly_fill_rect:

函数uxa_poly_fill_rect首先检查各种绘制条件以确认是否适合使用GPU进行绘制,如代码第4~7行所示。如果适合使用GPU进行绘制,则陆续调用函数prepare_solid和solid为GPU准备指令和数据,下面我们会重点讨论这两个函数。
否则,正如第5行代码所示,跳转到标签fallback处,即代码第9行,使用函数uxa_check_poly_fill_rect进行绘制,这个函数实际是使用CPU进行绘制的,我们将在8.3.3节进行讨论。
UXA中的函数指针solid指向intel_uxa_solid:

根据前面讨论的批量缓冲以及为操作批量缓冲封装的几个宏,读者一定已经看出来了,上面的代码是在组织批量缓冲在用户空间的数组batch_ptr。那么函数intel_uxa_solid向batch_ptr中填入各项的意义是什么呢?这个显然要参考Intel GPU的指令格式。根据第8行代码可见,2D驱动发送给GPU的指令是XY_COLOR_BLT,该指令的功能是对目标区域以指定颜色填充。Intel GPU的指令XY_COLOR_BLT的格式如表8-1所示。
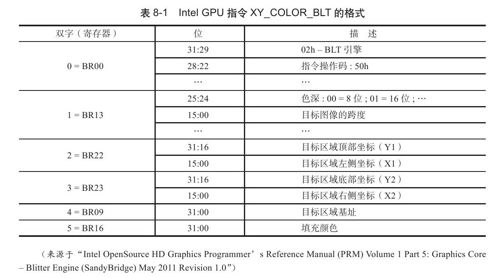
下面我们结合表8-1来分析函数intel_uxa_solid组织批量缓冲的过程。
1)由表8-1可见,指令XY_COLOR_BLT包含6个双字(DWord),第10行代码填充的是第0个双字,其中"BR00"是什么意思呢?事实上,GPU内部分为多个微核,处理不同的命令,处理2D指令的微核称为BLT引擎(Engine)。对于每个2D指令,每个双字实际上分别被送往BLT引擎的各个寄存器中。因此,这里的BR就是"BLT Register"的简写,如指令XY_COLOR_BLT中的第1个双字被送往BLT引擎的第0个寄存器,第2个双字被送往BLT引擎的第13个寄存器,等等。
因此,对于GPU指令来说,需要指明自己需要哪个微核来处理,这就是第一个双字中第29~31位的作用,0x2表示2D指令、0x3表示3D指令等。寄存器BR00中最重要的就是指令的操作码,即第22~28位,对于指令XY_COLOR_BLT,其操作码是0x50。其余位主要用于控制,如第11位用于控制是否打开Tiling,等等。因此,寄存器BR00也被称为"BLT Opcode&Control Register"。
根据宏XY_COLOR_BLT_CMD的定义:

其中从第22位开始的0x50正是指令XY_COLOR_BLT的指令操作码。第29~30位设置为2,告诉GPU这个指令是一个2D指令,需要GPU定向给BLT引擎。
2)第12行代码填充的是第1个双字,对应BLT引擎的寄存器BR13。其中"intel->BR[13]"是为了方便构建指令在程序中定义的一个变量,保存寄存器BR13的值。这就是函数uxa_poly_fill_rect在调用solid之前,调用函数prepare_solid的目的。在UXA(uxa_ops)中,prepare_solid对应的函数是intel_uxa_prepare_solid:


函数intel_uxa_prepare_solid根据图像实际使用的色深,设置相应的位。intel_uxa_prepare_solid除了计算了寄存器BR13中的色深外,也计算了寄存器BR16的值,BR16中的值是GPU进行填充时使用的颜色。
除了设置色深外,第12行代码也设置了图像的跨度(pitch),跨度是以字节为单位表示的图像的一行的长度。
3)第13行代码填充了第2个双字,对应BLT引擎的寄存器BR22,这个寄存器中保存的是目标区域的左上角的坐标。
4)第14行代码填充了第3个双字,对应BLT引擎的寄存器BR23,这个寄存器中保存的是目标区域的右下角的坐标。
5)第15~16行代码填充的第4个双字,对应BLT引擎的寄存器BR09,这个寄存器中保存的是目标区域在GPU的显存空间中的地址。这里的pixmap就是Screen Pixmap,所以宏OUT_RELOC_PIXMAP_FENCED就是将保存前缓冲的像素阵列的BO在显存空间中的地址填充到这个双字中。读者可以参见前面关于宏OUT_RELOC_PIXMAP_FENCED的介绍。
6)第17行代码填充了第5个双字,对应BLT引擎的寄存器BR16,这个寄存器中保存的是填充使用的颜色。
在完成指令XY_COLOR_BLT的构建后,函数intel_batch_submit将用户空间的batch_ptr中的数据复制内核空间的,并通知GPU,开始执行批量缓冲中的指令,代码如下:
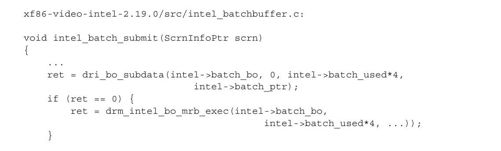

其中函数dri_bo_subdata,我们已经在8.2.2节讨论过,其负责将数据从用户空间复制到内核空间。所以这里就是2D驱动将组织在用户空间中的数组batch_ptr中的数据复制到批量缓冲在内核中对应的BO。
函数drm_intel_bo_mrb_exec通知GPU开始执行批量缓冲中的指令。方式是通过写GPU的一个寄存器,具体过程请参考8.4.2节。
