8.2.2 Buffer Object
与CPU相比,GPU中包含大量的重复的计算单元,非常适合如像素、光影处理、3D坐标变换等大量同类型数据的密集运算。因此,很多程序为了能够使用GPU的加速功能,都试图和GPU直接打交道。因此,系统中可能有多个组件或者程序同时使用GPU,如Mesa中的3D驱动、X的2D驱动以及一些直接通过帧缓冲驱动直接操作帧缓冲的应用等。但是多个程序并发访问GPU,一旦逻辑控制不好,势必导致系统工作极不稳定,严重者甚至使GPU陷入一个混乱的状态。
而且,如果每个希望使用GPU加速的组件或程序都需要在自身的代码中加入操作GPU的代码,也使开发过程变得非常复杂。
于是,为了解决这一乱象,开发者们在内核中设计了DRM模块,所有访问GPU的操作都通过DRM统一进行,由DRM来统一协调对GPU的访问,如图8-3所示。
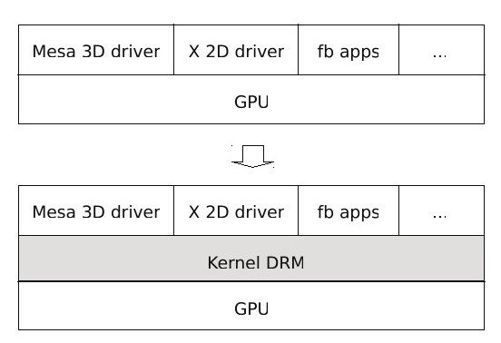
图 8-3 内核中的DRM模块
DRM的核心是显存的管理,当前内核的DRM模块中包含两个显存管理机制:GEM和TTM。TTM先于GEM开发,但是Intel的工程师认为TTM比较复杂,所以后来设计了GEM来替代TTM。目前内核中的ATI和NVIDA的GPU驱动仍然使用TTM,所以GEM和TTM还是共存的,但是GEM占据主导地位。
GEM抽象了一个数据结构Buffer Object,顾名思义,就是一块缓冲区,但是比较特别,是GPU使用的一块缓冲区,也就是一块显存。比如一个颜色缓冲的像素阵列保存在一个Buffer Object,绘制命令以及绘制所需数据也分别保存在各自的Buffer Object,等等。笔者实在找不到一个准确的中文词汇来代表Buffer Object,所以只好使用这个英文名称。开发者习惯上也将Buffer Object简称为BO,后续为了行文方便,我们有时也使用这个简称,其定义如下:


其中两个关键的字段是filp和name。
对于一个BO来说,可能会有多个组件或者程序需要访问它。GEM使用Linux的共享内存机制实现这一需求,字段filp指向的就是BO对应的共享内存,代码如下:

既然多个组件需要访问BO,GEM为每个BO都分配了一个名字。当然这个名字不是一个简单的字符,它是一个全局唯一的ID,各个组件使用这个名字来访问BO。
BO可以占用一个页面,也可以占用多个页面。但是,通常BO都是占用整数个页面,即BO的大小一般是4KB的整数倍。在i915的BO的结构体定义中,数据项pages指向的就是BO占用的页面的链表,这里并不是使用的简单的链表,结构体sg_table使用了散列技术。具体代码如下:

为了可以被GPU访问,BO使用的内存页面还要映射到GTT。这个映射过程也比较直接,就是将BO所在的页面填入到GTT的表项中。以i915为例,下面这个函数就是获取BO占据的页面:
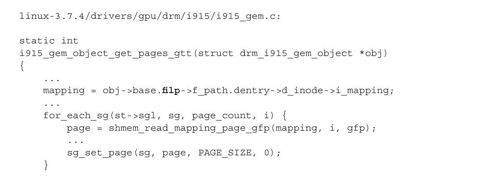

注意上面代码中使用黑体标识的filp,它指向了BO对应的共享内存区。显然,获取BO的页面实际就是获取这块共享内存的页面,代码中函数shmem_read_mapping_page_gfp就是做这件事的。当然BO可能对应多个页面,所以这里是一个循环,并将每个获取的页面放到散列表中,最后使BO中的指针pages指向这个页面散列表。
将BO的对应页表写入到GTT的表项中的代码如下:

函数intel_gtt_insert_sg_entries在内核的Intel的GTT驱动模块中,其实现代码如下:

函数intel_gtt_insert_sg_entries遍历BO对应页面的散列表,依次调用GTT驱动中的函数write_entry将页面的地址写入到GTT的表项中。GPU当然不能理解CPU使用的虚拟地址了,所以函数sg_dma_address返回的是页面的物理地址。i915系列GPU的GTT驱动的write_entry函数如下:
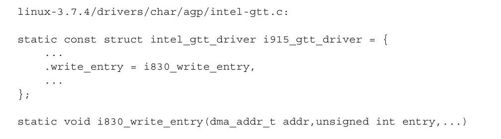

函数i830_write_entry逻辑非常简单,尤其是对于了解驱动的读者而言更是如此,其与我们向某个内存地址处赋值无本质区别。这里,addr就是页面的地址,intel_private.gtt是GTT的基址,entry是GTT中具体的表项。
读者可能有个疑问:GTT不是在BIOS划分给GPU专用的Graphics Stolen Memory中吗?那么CPU怎么可以寻址GTT,更新GTT的表项呢?内核中的GTT驱动模块已经考虑到了这点,在GTT模块初始化时,其使用ioremap将GTT所在地址映射到了CPU的地址空间,代码如下所示:

看到变量gtt_bus_addr是不是很熟悉?没错,在前面讨论i915的GTT驱动中的函数i9xx_setup时我们看到,i9xx_setup从GPU的PCI配置寄存器读取的GTT的基址就记录在这个变量中。
综上,我们看到,BO本质上就是一块共享内存,对于CPU来说BO与其他内存没有任何差别,但是BO又是特别的,它被映射进了GTT,所以它既可以被CPU寻址,也可以被GPU寻址,如图8-4所示。
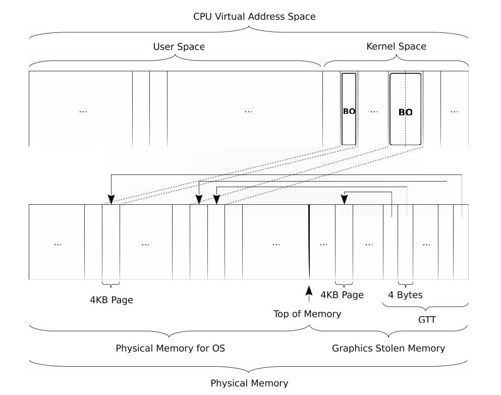
图 8-4 Buffer Object
为了方便程序使用内核的DRM模块,开发者们开发了库libdrm。在库libdrm中BO的定义如下:

其中两个重要的数据项是offset和virtual。
事实上,BO只是DRM抽象的在内核空间代表一块显存的一个数据结构。那么GPU是怎么找到BO的呢?如同CPU使用地址寻址一个内存单元一样,GPU也使用地址寻址。GPU根本不关心什么BO,它只认显存的地址。因此,每一个BO在显存的地址空间中,都有一个唯一的地址,GPU通过这个地址寻址,这就是offset的意义。offset是BO在显存地址空间中的虚拟地址,显存使用线性地址寻址,任何一个显存地址都是从起始地址的偏移,这就是offset命名的由来。offset通过GTT即可映射到实际的物理地址。当我们向GPU发出命令访问某个BO时,就使用BO的成员offset。
有时需要将BO映射到用户空间,其中数据项virtual就是记录映射的基址。
前面,我们讨论了BO的本质。下面我们从使用的角度看一看CPU与GPU又是如何使用BO的。BO是显存的基本单元,所以从保存像素阵列的帧缓冲,到CPU下达给GPU的指令和数据,全部使用BO承载。下面,我们分别从软件渲染和硬件渲染两个角度看看BO的使用。
(1)软件渲染
当GPU不支持某些绘制操作时,代表帧缓冲的BO将被映射到用户空间,用户程序直接在BO上使用CPU进行软件绘制。从这里我们也可以看出,DRM巧妙的设计使得BO非常方便地在显存和系统内存之间进行角色切换。
(2)硬件渲染
当GPU支持绘制操作时,用户程序则将命令和数据等复制到保存命令和数据的BO,然后GPU从这些BO读取命令和数据,按照BO中的指令和数据进行渲染。
库libdrm中提供了函数drm_intel_bo_subdata和drm_intel_bo_get_subdata,在程序中一般使用这两个函数将用户空间的命令和数据复制到内核空间的BO读者也会见到dri_bo_subdata和dri_bo_get_subdata。对于Intel的驱动来说,后面两个函数分别是前面两个函数的别名而已。后面讨论具体渲染过程时,我们会经常看到这几个函数。
