8.4 3D渲染
运行在X上的2D程序,都将绘制请求发给X服务器,由X服务器来完成绘制。但是对于3D图形的绘制,X应用需要通过套接字向X服务器传递大量的数据,这种机制严重影响了图形的渲染效率。为了解决效率问题,X的开发者们设计了DRI机制,即X应用不再将绘制图形的请求发送给X服务器了,而是由应用自行绘制。
在Linux平台上,OpenGL的实现是Mesa,所以在本节中,我们结合Mesa,探讨3D的渲染过程。我们可以认为Mesa分为两个关键部分:
❑一部分是一套兼容OpenGL标准的实现,为应用程序提供标准的OpenGL API。
❑另外一部分是DRI驱动,通常也被称为3D驱动,其中包括Pipleline的软件实现,也就是说,即使GPU没有任何3D计算能力,那么Mesa也完全可以使用CPU完成3D渲染功能。3D驱动还负责将3D渲染命令翻译为GPU可以理解并能执行的指令。不同的GPU有各自的“指令集”,因此,在Mesa中不同的GPU都有各自的3D驱动。
Pipeline最后将生成好的像素阵列输出到帧缓冲,但是这还不够,因为最后的输出需要显示到屏幕上。而屏幕的显示是由具体的窗口系统控制的,因此,帧缓冲还需要与具体的窗口系统相结合。但是X的核心协议并不包含OpenGL相关的协议,因此,开发者们开发了GL的扩展GLX(GL Extension)。为了支持DRI,开发者们又开发了DRI扩展。显然,GLX以及DRI扩展在X和Mesa中均需要实现。
基本上,运行在X窗口系统上的OpenGL程序的渲染过程,可以划分为三个阶段,如图8-6所示。
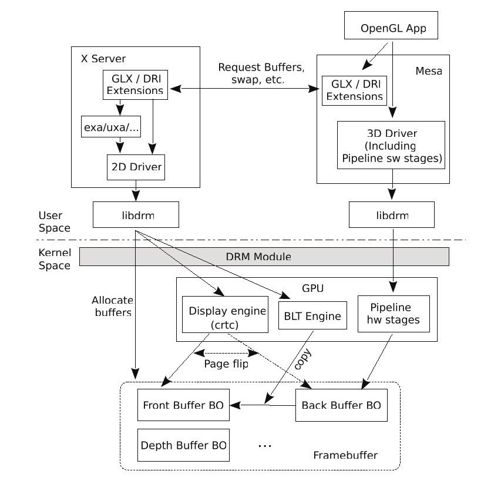
图 8-6 3D渲染架构图
1)应用创建OpenGL的上下文,包括向X服务器申请创建帧缓冲。应用为什么不自己直接向内核的DRM模块请求创建帧缓冲呢?从技术上讲,应用自己请求DRM创建请求创建帧缓冲没有任何问题,但是为了将帧缓冲与具体的窗口系统绑定,应用只能委屈一下,放低姿态请求X服务器为其创建帧缓冲。这样,X服务器就掌握了应用的帧缓冲的一手材料,在需要时,将帧缓冲显示到屏幕。帧缓冲是应用程序的“画板”,因此创建完成后,X服务器需要将帧缓冲的BO的信息返回给应用。
2)应用程序建立数学模型,并通过OpenGL的API将数学模型的数据写入顶点缓冲(vertex buffer);更新GPU的状态,如指定后缓冲,用来存储Pipeline输出的像素阵列;然后启动Pipeline进行渲染。
3)渲染完成后,应用程序向X服务器发出交换(swap)请求。这里的交换有两种方式,一种是复制(copy),所谓复制就是将后缓冲中的内容复制到前缓冲,这是由GPU中BLT引擎负责的。但是复制的效率相对较低,所以,开发者们又设计了一种称为页翻转(page flip)的模式,在这种模式下,不需要复制动作,而是通过GPU的显示引擎控制显示控制器扫描哪个帧缓冲,这个被扫描的缓冲此时扮演前缓冲,而另外一个不被扫描的帧缓冲则作为应用的“画板”,也就是所说的后缓冲。
接下来我们就围绕这三个阶段,讨论3D程序的渲染过程。
8.4.1 创建帧缓冲
在2D渲染中,渲染过程都由X服务器完成,所以毫无争议,前缓冲由而且只能由X服务器创建。但是对于DRI程序来说,其渲染是在应用中完成,应用当然需要知道帧缓冲,但是X服务器控制着窗口的显示,所以X服务器也需要知道帧缓冲。所以,帧缓冲或者由X服务器创建,然后告知应用;或者由应用创建,然后再告知X服务器。X采用的是前者。
虽然OpenGL中的帧缓冲的概念与2D相比有些不同,但本质上并无差别,帧缓冲中的每个缓冲都对应着一个BO。为了管理方便,Mesa为帧缓冲以及其中的各个缓冲分别抽象了相应的数据结构,代码如下:

其中,结构体gl_framebuffer是帧缓冲的抽象。结构体gl_renderbuffer是颜色缓冲、深度缓冲等的抽象。gl_framebuffer中的数组Attachment中保存的就是颜色缓冲、深度缓冲等。
在具体的3D驱动中,通常会以gl_renderbuffer作为基类,派生出自己的类。如对于Intel GPU的3D驱动,派生的数据结构为intel_renderbuffer:

其中指针mt间接指向缓冲区对应的BO。
如同在Intel GPU的2D驱动中,使用结构体intel_pixmap封装了BO一样,Intel GPU的3D驱动也在BO之上包装了一层intel_region。intel_region中除了包括BO外,还包括缓冲区的一些信息,如缓冲区的宽度、高度等:

当OpenGL应用调用glXMakeCurrent时,就开启了创建帧缓冲的过程,这个过程可分为三个阶段:
1)OpenGL应用向X服务器请求为指定窗口创建帧缓冲对应的BO。帧缓冲中包含多个缓冲,所以当然是创建多个BO了。
2)X服务器收到应用的请求后,为各个缓冲创建BO。在创建完成后,将BO的名字等相关信息发送给应用。
3)应用收到BO信息后,将更新GPU的状态。比如告诉GPU画板在哪里。
1.应用请求X服务器创建BO
帧缓冲与具体的GPU密切相关,因此创建帧缓冲的发起在3D驱动中。以i915系列的3D驱动为例,发起创建帧缓冲的函数为intelCreateBuffer:

函数intelCreateBuffer先后创建了帧缓冲对象和帧缓冲中包含的各个“子”缓冲对象,并将各“子”缓冲对象加入到帧缓冲对象的数组Attachment中。但是并不是OpenGL中规定的所有的缓冲对象都需要创建,所以函数intelCreateBuffer需要根据具体情况创建如前缓冲、后缓冲、深度缓冲等对象。注意,这里所谓的创建缓冲对象,仅仅是搭建起了一个空架子而已,帧缓冲尚未与具体的BO绑定。
一旦应用调用glXMakeCurrent切换自己为当前应用,glXMakeCurrent将调用3D驱动中的函数intel_update_renderbuffers请求X服务器创建指定X窗口的各个缓冲区的BO:

其中,函数intel_query_dri2_buffers_with/no_separate_stencil向X服务器申请为ID为drawable的窗口创建帧缓冲。以intel_query_dri2_buffers_with_separate_stencil为例:

函数intel_query_dri2_buffers_with_separate_stencil将帧缓冲中的各个缓冲组织为一个数组attachments,其格式是缓冲的ID加上缓冲的色深,后面组织X请求将使用这个数组attachments。然后调用getBuffersWithFormat向X服务器请求创建这些缓冲的BO。在Mesa端的DRI扩展中,getBuffersWithFormat最终调用的函数是DRI2GetBuffersWithFormat:


函数DRI2GetBuffersWithFormat首先创建一个X_DRI2GetBuffersWithFormat类型的X请求,根据前面组织的数组attachments,即申请创建的缓冲的信息,组织X请求的消息体,消息体中包含各缓冲的ID和色深。
然后调用Xlib的接口_XReply将请求发送给X服务器,并等待请求的返回。
在X服务器创建BO后,会将BO信息返回给应用,X服务器创建BO的过程我们下节讨论。根据代码我们看到,在返回的BO信息中最关键的一项就是BO的名称。回忆8.2.2节的讨论,我们谈到无论是X服务器还是应用,均使用名称访问BO。所以,这里返回的BO的名称就是为了使DRI应用通过这个名称访问BO。看到名称,我们习惯上将其理解为字符串,实际上在内核的DRM模块中,为BO的名称分配的是一个数字。
2.X服务器创建BO
X服务器中处理OpenGL应用为帧缓冲创建BO请求的函数是ProcDRI2GetBuffers WithFormat:
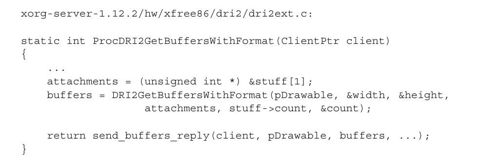
函数ProcDRI2GetBuffersWithFormat首先从应用的请求中提取attachments,然后调用函数DRI2GetBuffersWithFormat创建BO,最后通过函数send_buffers_reply将BO的信息发送给应用。
函数DRI2GetBuffersWithFormat将调用函数do_get_buffers为帧缓冲创建BO:

函数do_get_buffers中的变量count为应用请求创建BO的数量,显然,函数do_get_buffers是在循环为窗口的缓冲区创建BO。其中allocate_or_reuse_buffer调用I830DRI2CreateBuffer为缓冲区创建BO:

在前面讨论2D渲染时,我们已经看到,X服务器启动时,2D驱动在初始化输出设备时已经创建了前缓冲的BO。因为各个窗口是共享这个前缓冲的,因此,如果DRI应用申请为前缓冲创建BO,则I830DRI2CreateBuffer就不必创建了,其调用函数get_front_buffer直接查找前缓冲的BO,如代码第5~8行所示。
如果函数I830DRI2CreateBuffer执行到第10行代码时,pixmap依然空,则说明这次不是为前缓冲创建BO,于是调用函数CreatePixmap为其他缓冲创建BO。在UXA中,CreatePixmap指向函数intel_uxa_create_pixmap:


函数drm_intel_bo_alloc_for_render是库libdrm提供的接口,其请求内核的DRM模块为缓冲区创建BO。
创建好BO后,函数I830DRI2CreateBuffer使用库libdrm提供的接口pixmap_flink,请求内核的DRM模块为BO命名,见第16行代码。
在创建完缓冲区的BO后,让我们回到函数ProcDRI2GetBuffersWithFormat,其将调用send_buffers_reply将BO的相关信息发送给应用程序:

仔细观察send_buffers_reply,可见,即使应用向X服务器发出了索要前缓冲的BO的申请,X服务器也不会将真正的前缓冲的BO的信息发送给应用程序。事实上,对于运行在X窗口系统上的OpenGL应用来说,尽管应用程序有可能要求直接绘制在前缓冲上,但是X服务器发给OpenGL应用的只是一个伪前缓冲,和普通的后缓冲没有本质区别。从这里也可以看出,X不允许DRI应用不通过X直接在前缓冲上绘制,X不希望应用把屏幕显示搞乱,X要对前缓冲有绝对的控制权。如果读者熟悉Linux,一定知道第1版的DRI,在开启符合管理器后,运行DRI应用时,那个著名的glxgears转动的齿轮不受复合管理器管理的bug。
3.更新GPU状态
系统中可能存在多个OpenGL程序并行运行但是只有一个GPU的情况。因此,GPU要分时给不同的OpenGL程序使用。如同进程切换时,CPU需要切换上下文一样,在对不同的OpenGL程序进行渲染时,GPU也需要在不同程序之间切换。
以帧缓冲为例,每个OpenGL程序都有自己的帧缓冲。但是只有当前进行绘制的OpenGL应用的帧缓冲才是GPU的目标帧缓冲。因此,当不同的OpenGL程序进行切换时,GPU需要切换记录帧缓冲地址的寄存器,使其指向当前正在进行绘制的程序的帧缓冲。
以Intel i915系列GPU为例,在其3D驱动中,对应GPU状态的结构体为struct i915_hw_state:
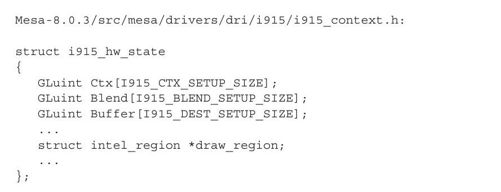
结构体i915_hw_state使用一系列的数组来记录GPU的状态,其中指针draw_region指向的就是保存输出的图像的像素阵列的BO。
应用程序从X服务器获取了各个缓冲区的BO后,需要更新GPU中帧缓冲相关的状态。以i915的3D驱动中缓冲区更新为例,更新GPU的帧缓冲状态的函数是i915_update_draw_buffer:

第5行的变量irb显然是指向一个颜色缓冲区。
Intel GPU的3D驱动中采用Mipmap的方式保存intel_region,Mipmap是一种为了加快渲染速度和减少图像锯齿,将贴图处理成由一系列被预先计算和优化过的图片的技术。因此,第6行代码中的"irb->mt->region"就是指向封装颜色缓冲BO的intel_region对象。
那么_ColorDrawBuffers中的第0个缓冲指向的是哪个颜色缓冲呢?看看下面代码片段:


根据上面的代码片段可见,这个颜色缓冲就是后缓冲。
我们继续看函数i915_update_draw_buffer中的函数set_draw_region,对于i915的3D驱动,该函数指针指向i915_set_draw_region:
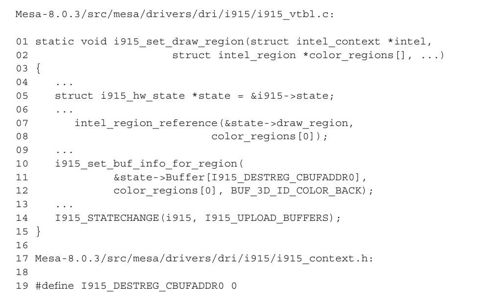
其中,第7~8行代码中调用的函数intel_region_reference比较简单,就是将i915_hw_state中的draw_region设置为color_regions[0],其就是我们刚刚在函数i915_update_draw_buffer中讨论的后缓冲。
在考察第10~12行代码调用的函数i915_set_buf_info_for_region前,先来看一下传给这个函数的3个参数。根据第19行的宏定义,可见第1个参数就是i915_hw_state中数组Buffer的首地址;第2个参数color_regions[0]是后缓冲;第3个参数从名字上可以猜出大概是GPU用来标识后缓冲的ID。了解了参数后,我们来看一下这个函数的具体代码:


显然,函数i915_set_buf_info_for_region就是设置i915_hw_state中数组Buffer的前两个元素的值。第一个元素被赋值为GPU指令_3DSTATE_BUF_INFO_CMD;第二个元素被赋值为标识后缓冲的ID。
更新了i915_hw_state中的状态信息后,函数i915_set_draw_region调用I915_STATECHANGE将状态信息组织到批量缓冲。GPU将在进行绘制之前,从批量缓冲中读取这些信息,并更新自身的状态。宏I915_STATECHANGE最终调用函数i915_emit_state组织批量缓冲:
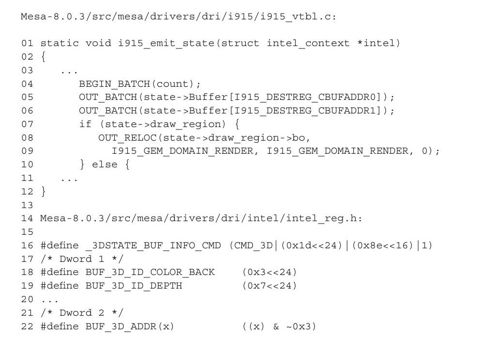
根据第5~6行代码,批量缓冲中的前两个元素分别为i915_hw_state中Buffer数组中的第一个和第二个元素。我们刚刚讨论过,这两个元素分别是GPU指令_3DSTATE_BUF_INFO_CMD和GPU用来标识后缓冲的ID的。
笔者没有找到有关GPU指令_3DSTATE_BUF_INFO_CMD的参考,但是根据上面代码第16~22行的宏定义,我们可以猜出一二:
1)_3DSTATE_BUF_INFO_CMD是个指令ID,应该是告诉GPU更新相关缓冲的信息。
2)在指令码之后,紧接的第一个参数中至少应该包含要更新的缓冲区的ID,这里BUF_3D_ID_COLOR_BACK应该是GPU内部用来标识后缓冲的ID。我们看到这个ID大约占据从24位开始的几位,如011对应的是后缓冲,111对应的是深度缓冲。
3)既然通知GPU更新后缓冲的地址,当然需要将后缓冲所在的BO告知GPU了。所以指令码之后的第二个参数应该是更新的缓冲的BO。当然了,这里要使用BO在GPU地址空间的地址。上面代码第8~9行的宏正是在批量缓冲中写入了后缓冲BO的地址。
事实上,除了更新了GPU中后缓冲的信息外,也更新了GPU的其他状态,这里不再一一讨论。
