2.1 无类别域间路由
自治系统与外部路由协议的创建解决了20世纪80年代Internet的扩展性问题,但是,到了20世纪90年代早期,Internet出现了各种不同的扩展性问题,如下所述:
• Internet路由表爆炸。以指数增长的路由表开始变得难以管理(包括路由器的处理时间以及管理员),仅仅是路由表尺寸就已经耗用了大量的Internet资源,再加上日复一日的拓扑结构变化以及网络的不稳定性,使得Internet更加不堪重负。
• B类地址空间的逐渐耗尽。截止到1993年1月,16 382个B类地址已经被分配了7 133个,如果以1993年的地址分配速度,那么整个B类地址空间将在两年不到的时间内被分配完毕(如RFC 1519所述)。
• 全部32位IP地址空间的最终耗尽。
无类别域间路由为前两个问题提供了短期解决方案,另一个短期解决方案就是将在第4章中讨论的NAT(Network Address Translation,网络地址转换)。这些解决方案为Internet架构师们赢得了足够的时间来创建一个拥有足够地址空间的新IP版本,在这一思路下创建的IPng(IP Next Generation,下一代IP)最终形成了IPv6(IPv6采取了128位的地址格式)。将在第8章中讨论的IPv6技术是第三个问题的长期解决方案,但非常有趣的是,CIDR和NAT都取得了巨大的成功,以至于很少再有人像当初那样迫切地希望将网络迁移到IPv6。
CIDR仅仅是一种明智地利用了Internet分层结构的地址汇总方案,因而在进一步讨论CIDR之前,有必要先回顾一下汇总和无类别路由选择,并了解一下当前的Internet发展状况。
2.1.1 汇总概述
汇总(summarization)或路由聚合(route aggregation)(详见《TCP/IP路由技术(第一卷)》)指的是用一个较不精确的地址来宣告一个连续的地址集合。从本质上来看,汇总/路由聚合是通过减小子网掩码的长度直至屏蔽了所有被汇总地址的公共bit来实现的。例如,图2-1中的4个子网(172.16.100.192/28、172.16.100.208/28、172.16.100.224/28和172.16.100.240/ 28)可以被汇总为单个聚合地址172.16.100.192/26。
许多将汇总视为一项艰难工作的网络工程师都会惊诧于他们必须每天都要跟汇总打交道,说到底,什么是与连续主机地址群汇总不一样的子网地址呢?例如,子网地址192.168.5.224/27是主机地址192.168.5.224/32~192.168.5.255/32的聚合地址(当然,”主机地址” 192.168.5.224/32是数据链路本身的地址)。汇总地址的关键特性就是其掩码长度要短于其所要汇总的地址的掩码长度。最极端的汇总地址为默认地址0.0.0.0/0,常写为0/0。如/0所表示的那样,此时的掩码已缩减至无任何网络bit——该地址是所有IP地址的聚合地址。
汇总操作可以穿越类边界,例如,可以将4个C类网络(192.168.0.0,192.168.1.0、192.168.2.0及192.168.3.0)汇总为一个聚合地址192.168.0.0/22。需要注意的是,该聚合地址(使用了22位掩码)不再是一个合法的C类地址,因而为了支持主类网络地址的聚合,整个路由环境必须是无类别的。

图2-1 路由聚合
2.1.2 无类别路由
无类别路由包括以下两个主要特征:
• 无类别是路由协议的特性;
• 无类别是路由器的特性。
作为路由信息的一部分,无类别路由协议携带了每个被宣告地址网络部分的描述信息。网络地址的网络部分通常被称为地址前缀(address prefix),地址前缀可以用一个地址掩码以及一个指示该地址中有多少个bit是前缀bit的长度字段来表示,也可以在其更新中只用前缀 bit来表示(见图2-2)。常见的无类别IP路由协议有RIP-2、EIGRP、OSPF、集成式IS-IS和 BGP-4。
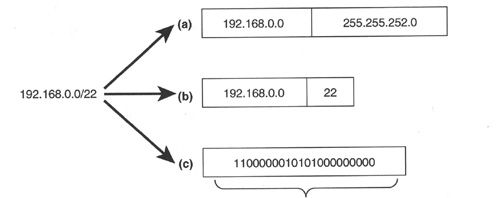
图2-2 利用无类别路由协议宣告一个地址前缀
有类别路由器在其路由表中将目的地址记录为主类网络及这些网络的子网。在执行路由查找时,有类别路由器首先查找主类网络地址,接着再在其主类地址下的子网列表中寻找匹配项。而无类别路由器则会忽略地址类别,仅进行“最长匹配”查找操作,也就是说,对任何目的地址来说,无类别路由器仅选择地址bit匹配最长的路由。以例2-1的路由表为例,例中给出了包含多个可变子网的IP网络,如果路由器是无类别的,那么该路由器将试图为每个目的地址都找到最长匹配项。
例2-1:包含多个可变子网的IP网络的路由表。
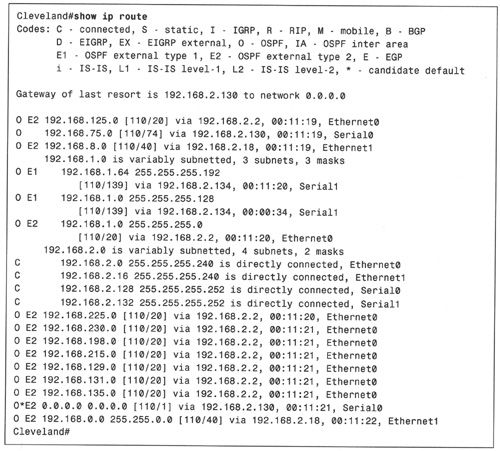
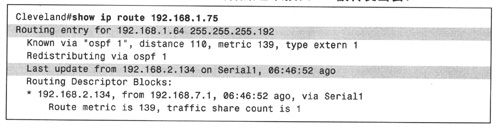
如果路由器接收到一个目的地址为192. 168. 1. 75的数据包,那么路由表中会有多个匹配项:192.168.0.0/16、192.168.1.0/24、192.168.1.0/25和192.168.1.64/26。此时,将会选择 192. 168. 1. 64/26(如例2-2所示)作为匹配项,这是因为该地址与目的地址是最长匹配,匹配长度为26bit。
例2-2:目的地址为192.168.1.75的数据包从接口S1被转发出去。
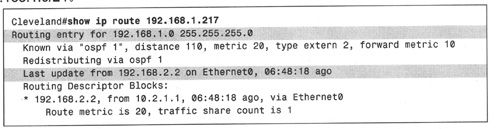
目的地址为192. 168. 1. 217的数据包与192. 168. 1. 64/26或192. 168. 1. 0/25都不匹配,该地址的最长匹配地址应该是192.168.1.0/24,如例2-3所示。
例2-3:路由器无法将192. 168. 1. 217匹配到更精确的子网,因而将其匹配为网络地址192.168.1.0/24。
目的地址192.168.5.3的最长匹配可以是聚合地址192.168.0.0/16(如例2-4所示)。
例2-4:目的地址为192. 168. 5. 3的数据包无法匹配更精确的子网或网络,因而匹配超网 192.168.0.0/16。

最后,目的地址192.168.1.1与路由表中的任何网络项都不匹配(如例2-5所示)。不过,路由器并不会丢弃这类数据包,这是因为例2-1所示的路由表中包含了一条默认路由,这类数据包将会被转发到下一跳路由器192.168.2.130。
例2-5:路由表中无192. 168. 1. 1的匹配项,去往该地址的数据包都将被转发到默认地址,出接口为SO。

从IOS 11. 3开始,Cisco路由器在默认情况下都是无类别的,在该版本之前的IOS都默认为有类别,可以利用命令ip classless来更改默认设置。
例2-1中的路由表及相关示例解释了最长匹配路由选择的一些特性,也就是说,指向聚合地址的路由无需指向聚合地址中的每个成员。图2-3给出了例2-2~例2-5中的路由向量情况。
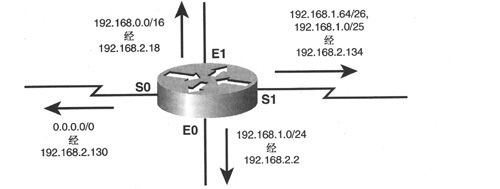
图2-3 例2-1路由表中的路由向量
考虑一个聚合了其全部子网的网络192.168.1.0/24。图2-3显示指向该网络地址的路由都从接口E0向外转发数据包,但是去往其中的两个子网192. 168. 1.0/25和192.168.1.64/26的路由却指向其他接口S1。
注意:实际上,192. 168. 1. 64/26本身就是192. 168. 1. 0/25的成员,但这两个地址拥有不同的路由(都指向S1),这就暗示了它们是由不同的上游路由器宣告而来的。
同样,192.168.1.0/24是聚合网络192.168.0.0/16的成员,但是指向较不精确地址的路由是通过接口E1向外转发的,而最不精确的路由0.0.0.0/0(是所有其他地址的聚合)是通过接口SO向外转发的。根据最长匹配路由选择原则,去往192. 168. 1. 0/25和192. 168. 1. 64/26的数据包将从接口S1向外转发,而去往网络192.168.1.0/24的其他子网的数据包则将从接口E0向外转发。以192.168(而不是192.168.1)为起始目的地址的数据包都将从接口E1向外转发,而起始目的地址不是192.168的数据包都将从接口SO向外转发。
2.1.3 汇总:好处、坏处及不对称流量
汇总可以大大节约网络资源,包括存储路由表所需的内存容量、网络带宽以及路由器传送和处理路由信息的能力。汇总还可以通过“隐藏”网络的不稳定性来节约网络资源。
例如,图2-4中存在一条翻动路由(flapping route)。这里所说的翻动路由指的是由于物理连接或路由器接口故障而导致不停Up/Down的路由。
如果没有汇总机制,那么子网192.168.1.176/28的每次Up/Down的信息都会被传送到企业互联网络中的每台路由器,反过来,这些路由器又必须处理该信息并相应地调整其路由表。如果路由器Nashville利用聚合地址192. 168. 1. 128/25来宣告所有的上行路由,那么更为精确的子网发生的任何变化都不会通过该路由器被宣告出去,此时的Nashville是聚合点,即便被聚合的某些成员有不稳定状况,聚合路由仍然会保持稳定。
汇总的代价就是牺牲了路由的精确性。如例2-6所示,由于图2-3中的路由器接口S1出现故障,因而导致该接口上从邻居学习到路由无效。但此时并不会丢弃正常情况下从接口S1向外转发的数据包(如目的地址为192. 168. 1. 75的数据包),因为这时的数据包将匹配次最佳路由192.168.1.0/24,并将从接口E0被转发出去(请与例2-2进行对比)。
例2-6:失效路由会导致数据包转发不精确。
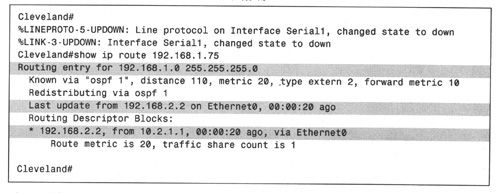
路由不精确可能是个问题,也可能不是一个问题,这取决于互联网络的状况。继续前面的例子,假设下一跳路由器192.168.2.2仍有一条经路由器Cleveland到达192. 168. 1. 64/26的路由项(或者是因为该互联网络暂未收敛,或者是该路由为手工录入),那么将会出现路由环路。另一方面,某些通过Cleveland的E0接口可达的路由器可能会有一条去往子网192. 168. 1. 64/26的“后门”路由,只有当主用路由(经Cleveland的S1接口)无效时才会使用该“后门”路由。此时,去往192. 168. 1. 0/24的路由就被设计为备用路由,例2-6所示的路由行为就属于刻意行为。
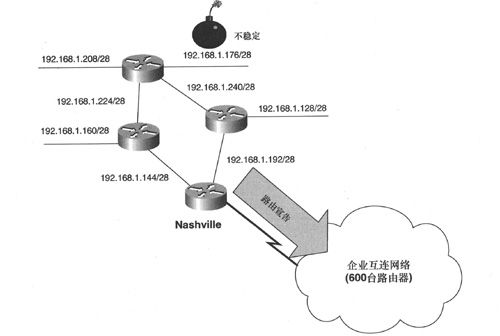
图2-4 翻动路由使得整个网络变得不稳定
如图2-5所示,失去路由精确性的互联网络会产生不同的问题,图中路由域1通过旧金山和亚特兰大的路由器连接到路由域2。对本例来说,如何定义路由域并不重要,重要的是路由域1中的所有网络都可以被汇总为地址172.16.192.0/18,路由域2中的所有网络都可以被汇总为地址172.16.128.0/18。
相对于宣告单个子网来说,旧金山和亚特兰大的路由器更愿意将汇总地址宣告到两个路由域中。如果达拉斯子网172.16.227.128/26中的某台主机向西雅图子网172.16.172.32/28发送一个数据包,那么该数据包极有可能被路由到亚特兰大(因为亚特兰大路由器是宣告路由域2汇总路由的最近路由器),由亚特兰大将数据包转发到路由域2,并最终到达西雅图。当子网172.16.172.32/28上的主机发送响应信息时,由西雅图将响应数据包转发到旧金山,因为其是宣告汇总路由172.16.192.0/18的最近路由器。
这里出现的问题就是两个子网之间的流量不对称:从172.16.227.128/26到172.16.172.32/ 28的数据包走一条路径,而从172.16.172. 32/28到172.16.227. 128/26的数据包走另一条路径,出现不对称路径的原因是达拉斯和西雅图路由器都没有对方子网的全部路由,它们仅知道去往宣告汇总路由的路由器的路由,因而必须基于该路由转发数据包。换句话说,旧金山和亚特兰大的汇总路由隐藏了这些路由背后的互联网络细节信息。
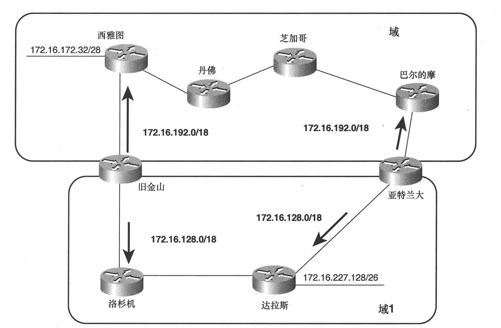
图2-5 当多台路由器被宣告为同一个聚合地址时,失去路由精确性将会产生问题
不对称流量属于非期望状况,原因主要有3个:首先,不对称流量会使互联网络的流量模型变得难以预测,使得网络基准、容量规划、故障检测及排除变得困难;其次,不对称流量会使链路使用率出现不均衡,某些链路的带宽出现饱和,而其他链路的带宽却得不到有效利用;再次,不对称流量会使出流量和入流量的延时时间出现很大的差异,这种时延变化(也称为抖动)会对某些时延敏感型应用(如语音和直播视频)造成损害。
2.1.4 Internet:迄今为止依然是分层结构
尽管从ARPANET的单骨干网结构(详见第1章)开始,Internet已经经历了巨大的发展变化,但是依然保留了一定的分层架构。分层架构中最低的一级是连接在ISP(Internet Service Provider,互联网服务提供商)上的Internet用户。在很多情况下,ISP都是本地区域范围内的一个或多个小型服务提供商,被称为本地ISP(local ISP),例如,科罗拉多州区号为303的区域内就有200家左右的ISP。这些本地ISP反过来又是某些更大ISP(覆盖整个地区,如一个或多个临近州)的客户,这些更大型的ISP被称为区域服务提供商(regional service provider),如科罗拉多州的CSD Internet和Colorado Supernet。相应地,这些区域服务提供商又连接到拥有覆盖全国或全球区域的高速(DS-3、OC-3或更高)骨干网的大型ISP,这些最大的服务提供商被称为网络服务提供商(network service provider),如MCI/WorldCom(UUNET))、SprintNet、Cable & Wireless、Concentric Network以及PSINet等。更通用地是将这些提供商分别称为Tier III、Tier II和Tier I提供商。
图2-6显示了这些不同类型ISP之间的关系。用户(无论是终端用户还是次一级的服务提供商)都在ISP的POP(Point of Presence,呈现点)处连接到上一级服务提供商,POP实际上就是一个就近的路由器,用户可以通过拨号或专用本地环路连接到该路由器上。在最高级别,网络服务提供商之间通过NAP(Network Access Point,网络接入点)进行互连。NAP实际上就是一个LAN或交换机(通常为以太网、FDDI或ATM),不同的服务提供商可以通过NAP相互交换路由和数据流量。
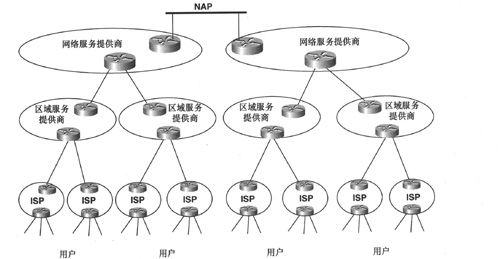
图2-6 ISP/NAP分层结构
如表2-1所示,某些NAP按名字被称为CIX(Commercial Internet Exchange,商用互联网交换中心)、FIX(Federal Internet Exchange,联邦互联网交换中心)和MAE(Metropolitan Area Exchange,城域交换中心;最初MAE被称为城域以太网(Metropolitan Area Ethernets),由Metropolitan Fiber Systems公司创造)。CIX、FIX和MAE-East都属于早期试验性质的骨干网连接点,根据这些互连点的互连经验,并且作为NSFnet退役计划的一部分,NSF(National Science Foundation,国家科学基金)于1994年建设了首批4个NAP。
表2-1 美国的已知NAP
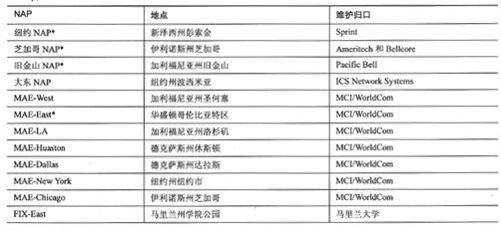
续表

除了表2-1所示的主要NAP之外,在NSP的互连处还有很多小型NAP,常常用来互连较小的区域服务提供商,如SIX(Seattle Internet eXchange,西雅图互联网交换中心)和新墨西哥网络接入点等都属于区域型NAP。
除了建立NAP之外,NSF还资助了RA(Routing Arbiter,路由仲裁)计划,RA的职责之一就是提升Internet的稳定性和可管理性。迄今为止,RA提出了一个来源于服务提供商的路由(拓扑结构)和策略(优选路径)数据库(即RADB, Routing Arbiter Database,路由仲裁数据库)。该数据库由位于NAP的路由服务器(route server)来维护,而路由服务器实质上就是一台UNIX工作站或运行了BGP的服务器。此时,每个服务提供商的路由器无需与NAP中的其他所有路由器都建立对等关系,而只要与路由服务器建立对等关系即可。各种路由及策略都要与路由服务器进行通信(RA使用一种被称为RIPE-181的复杂数据库语言来处理和维护这些信息),之后由路由服务器将合适的路由传递给其他路由器。
虽然路由服务器运行BGP并处理路由信息,但并不执行包转发功能,而是利用其Update消息通知各路由器,最佳下一跳路由器就是通过NAP直接可达的路由器。经过第1章的学习,读者已经熟悉了EGP第三方邻居的概念,通过实现可行的一对多对等(而不是多对多对等),路由服务器大大提高了网络的稳定性、可管理性以及经由NAP的流量吞吐量。
NAP和RA证明了互相竞争的网络服务提供商之间可以相互合作,从而为Internet提供可管理的网络连接及稳定性。因此,NSF在1997年1月停止了路由服务器和NAP的资助项目,将网络运营交给了商业团体。尽管公共建立的Internet研究仍在继续,如Internet2、GigaPOP及vBNS(very high-speed Backbone Network Service,甚高速骨干网络服务)等计划,但目前的Internet基本实现了商业化运营。
将Internet转移到商业化运营的一个主要原因就是,现在的Internet已经远远偏离了最初的可控性构想。受经济性、竞争性和策略利益等因素的驱动,最大的服务提供商都选择建立直接对等互连,而不是通过路由服务器来实现对等互连,而且对等关系发生在多个级别,而不仅仅局限在图2-6所示的顶级层次。
当两个或多个服务提供商同意通过NAP实现路由共享时,要么直连,要么通过路由服务器进行连接,此时需达成对等协定(peering agreement)。对等协定既可以在两个服务提供商之间直接建立(称为双边对等协定),也可以在一组规模相似的服务提供商之间建立(称为多边对等协定,即MLPA, MultiLateral Peering Agreement)。在确定对等协定中的经济利益时,流量模型起到了决定性作用,如果对等伙伴之间的双方向流量基本平衡,那么一般无需进行相互结算,此时对等伙伴之间属于公平对等互连。但是,如果通过对等互连点的流量出现一方向流量远远大于另一方向流量,如一个小型服务提供商与一个大型服务提供商进行互连时,小型服务提供商通常需要为对等特许支付相应的费用,其原因是小型服务提供商在对等互连时获得的利益要高于大型服务提供商。
偏离最初Internet构想的另ー个因素是对等点的位置。NAP (许多服务提供商互连之处,如表2-1所示)是公共对等站点,除了这些公共对等站点之外,服务提供商们在与其他服务提供商同局址的站点建立了成百上千个NAP,此时签订的对等协定通常是两个或多个服务提供商之间的私有协定。由于私有对等可以大大缓解国家级NAP的网络拥塞,增强路由的灵活性,并降低某些流量的延时,因而得到政府的鼓励。
偏离最初Internet构想还有ー个因素是Internet没有完全按照图2-6所建议的那样去发展,许多全国性、区域性服务提供商也出售本地Internet接入服务,与本地ISP形成了直接竞争。例如,例2-7中路由跟踪的“起始点”就是隶属于Concentric Network (一个骨干网服务提供商)的拨号接入POP。而区域性服务提供商也常常出现在骨干NAP,它们通过NAP与ー个或多个网络服务提供商实现互连,或者通过NAP与其他区域性NAP实现互连,从而绕过了网络服务提供商。
例2-7:从位于丹佛的Concentric Network POP发起路由跟踪。

例2-7中的路由跟踪显示了一部分Internet骨干网结构,两个路由跟踪都从位于丹佛的 Concentric Network POP发起。在第一个路由跟踪中,数据包经Concentric Network的骨干网被转发到MAE-East,进而被连接到BBN Planet骨干网(第3行和第4行),数据包经BBN Planet骨干网被转发到由BBN和US West在明尼阿波利斯共享的TierⅡ NAP(第10行和第11行),最后被传送到目的地US West。
第二次路由跟踪显示数据包在到达目的地(离路由跟踪发起点仅几英里之遥)之前几乎穿越了整个美国。首先,这些数据包沿着Concentric Network骨干网,通过位于加利福利亚的路由器(第4行)到达芝加哥NAP,通过芝加哥NAP连接到Sprint骨干网(第6行),然后又被路由到位于新泽西州彭索金的纽约NAP,接着被转发到ANS骨干网(第11行和第12行),并经由雷斯顿、休斯顿、圣路易斯及芝加哥(第二次经过),最后返回丹佛。
与最后一次路由跟踪相似,我们也是绕了一大圈才又返回到本节所讨论的主题CIDR。
2.1.5 CIDR:降低路由表爆炸的危险
假定Internet具有一定的分层结构,那么可以看出这种分层结构对地址汇总方案有很大的帮助。在顶层,大块连续的C类地址被IANA(Internet Assigned Numbers Authority,互联网编号分配机构)分配给全球范围内的不同地址分配机构。这些地址分配机构被称为区域性IP地址注册管理机构(regional IP registries)。目前一共有3个区域性IP注册管理机构,包括为北美、南美、加勒比海和撒哈拉沙漠以南非洲地区以及全球网络服务提供商分配地址的ARIN(American Registry for Internet Numbers,美洲互联网号码注册管理机构),为欧洲、中东、北非以及部分亚洲地区分配地址的RIPE(Resèaux IP Europèens,欧洲IP资源中心),以及为其余亚太地区分配IP地址的APNIC(Asia Pacific Network Information Center,亚太网络信息中心)。
注意:ARIN是1997年从InterNIC(由Network Solutions公司负责管理)中分离出来的,专门负责IP地址和域名的管理。
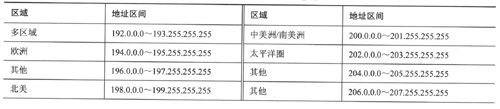
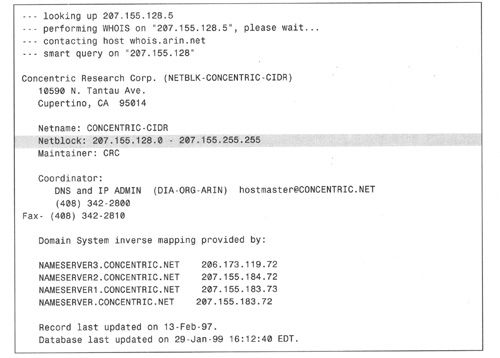
表2-2列出了将C类地址分配给这些注册管理机构所服务区域的原始方案,只是其中某些分配方案目前已经过时了。如例2-8所示,标记了“Others”的地址块目前已被分配,区域注册管理机构反过来又将这些地址块分配给大型服务提供商或本地IP注册管理机构。一般来说,在这个级别分配的地址块都不小于32个连续C类地址(通常更多)。例如,Concentric Network曾经被分配给地址块207. 155. 128. 0/17,包括128个连续C类地址(详见例2-8)。
表2-2 按地理区域分配的CIDR地址
例2-8:对例2-7的地址207.155.128.5执行WHOIS时,显示的是分配给Concentric Network的/17 CIDR地址块的一部分。
收到这些地址块的服务提供商将这些地址划分成较小的地址块并分配给其用户,如果这些用户本身就是ISP,那么他们会将这些地址块划分成更小的地址块。按这种方式分配这些C类地址块(被称为CIDR地址块)的一个明显好处就是可以按照分层结构逐级汇总。有关这些地址在Internet中分配的详细情况请参见RFC 2050(www.isi.edu/in-notes/rfc2050.txt)。
为解释清楚,假定Concentric Network将其207. 155. 128. 0/17地址块的一部分(如 207.155.144.0/20)分配给其用户。如果该用户是一个ISP,那么该ISP会将其一部分地址块(如207.155.148.0/22)分配给其自己的用户,此时的用户会将/22(读作“斜杠22”)地址块宣告给ISP,ISP以单个聚合地址207.155.144.0/20将汇总后的用户地址宣告给Concentric Network。最后,Concentric Network又以单个聚合地址207. 155. 128. 0/17将汇总后的用户地址宣告给其所连接的NAP。
很明显,将单个聚合地址宣告给上一级网络域比宣告给成百上千个独立地址要好得多。另一个同样重要的好处是,该地址分配方案大大增强了Internet的稳定性,因为低级网络域的状态变化最多会被传递到第一个聚合点,而不会被进一步传播。
表2-3列出了各种不同CIDR地址块的大小、折合C类网络的大小以及每个地址块可以容纳的主机数量。
表2-3 CIDR地址块大小

续表
2.1.6 CIDR:降低B类地址空间被耗尽的危险
B类地址耗尽的原因就是IP地址类别设计上的固有缺陷:一个C类地址可以提供254个主机地址,而一个B类地址却可以提供65 534个主机地址,两者之间的差距过于悬殊。在出现CIDR之前,如果某公司需要500个主机地址,那么一个C类地址将无法满足该需求,此时就需要申请一个B类地址,而这样就将浪费掉65 000个主机地址。有了CIDR之后,只需要/23地址块就可以满足该公司的需求,从而可以大大节省其他地址分配方式浪费掉的主机地址。
2.1.7 CIDR 面临的难题
虽然CIDR被证明已成功减缓了Internet路由表的快速增长及B类地址的急速耗尽,但是对CIDR地址块的用户来说,仍然存在一些问题。
第一个问题就是可携带性。假设某用户被分配了一个CIDR地址块,而该地址非常有可能属于某个更大的地址块(分配给ISP的地址块)。此时,如果该ISP无法满足该用户的期望或者未能完全履行合约协议,或者该用户收到了其他ISP提供的更为优厚的服务提议,那么更换ISP也就意味着很有可能需要重新编址,而且当用户离开原有ISP、重新选择一个新的ISP时,原有ISP一般也不允许用户保留分配给该用户的IP地址。不但ISP不愿意放弃其地址空间的一部分,而且区域性IP注册管理机构也强烈建议在用户更换ISP时回收已分配给该用户的地址空间。
对终端用户来说,重新编址会带来不同程度的困难,对于那些在自身路由域中使用敌友地址空间、在网络边缘使用NAT(Network Address Translation,网络地址转换,详见第4章)的用户来说,重新编址过程应该是最简单的,此时只需更改“面向公网”部分的地址,对内部用户的影响最小。另一个极端的终端用户场景就是为每个内部网络设备都静态分配了公网地址,这些用户将不得不登录网络中的每台设备进行重新编址。
如果终端用户在整个网络域都使用了CIDR地址块,那么通过DHCP(或BOOTP)可以在一定程度上减轻重新编址所带来的痛苦。此时,除了更改DHCP的地址范围并重启用户机器之外,只需逐个重新编址那些静态分配了IP地址的网络设备,如服务器和路由器。
如果是ISP(而不是终端用户)需要变更上游服务提供商,那么重新编址的问题将变得更加复杂。因为此时不仅需要对自己的互联网络进行重新编址,而且所有被ISP分配了部分CIDR地址块的用户也都需要进行重新编址。
对所有希望连接到多个服务提供商的用户来说,CIDR还会产生另一个问题。多归属(multihoming,将在本章稍后进行详细阐述)的目的是提高冗余性,使得终端用户或ISP可以免受单个上游服务提供商出现故障所带来的网络中断。此时带来的问题就是,用户必须将从第一个服务提供商获得的CIDR地址块宣告到第二个服务提供商。
图2-7解释了多归属带来的问题。如图所示,用户拥有一个属于/23 CIDR地址块(属于 ISP1的更大的/20地址块),当用户连接到ISP2时,希望通过ISP1或ISP2都能接收来自Internet的流量为此,该用户必须将其/23地址块宣告给ISP2,当ISP2将这个/23地址块宣告给其他网络时就会产生问题:所有的“外界”路由器都拥有一条由ISP1宣告的去往205. 113. 48. 0/20的路由和一条由ISP2宣告的去往205.113.50.0/23的路由,所有目的地址为该用户的数据包都将选择相对精确的路由,这样一来,几乎所有来自Internet的流量都将通过ISP2到达用户,包括那些地理位置上更靠近ISP1的流量。
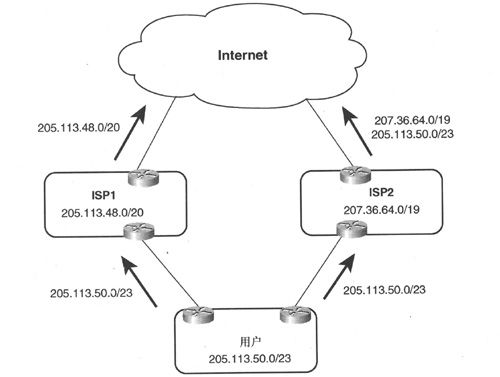
图2-7 Internet入流量匹配最精确的路由
如图2-7所示,路由205.113.50.0/23甚至还有可能通过Internet被宣告给ISP1,但这种情况一般不会发生,因为大多数ISP都会设置路由过滤器,以阻止自己的路由被重新宣告到自己的路由域中。但是,很难确保ISP1设置了正确的路由过滤机制,如果来自Internet的更为精确的路由被泄露到ISP1,那么ISP1的其他用户将跨越Internet和ISP2之后才能到达 205.113.50.0/23,而无法选择更为直接的路径。
对那些实施多归属的用户来说,ISP1除了宣告其CIDR地址块之外,还必须宣告更为精确的路由(如图2-8所示)。但大多数服务提供商都不愿意这么做,因为这样做就好比在其 CIDR地址块中“打孔”(也称为地址泄露),从而大大降低CIDR的有效性,而且在其CIDR地址块中宣告一条更为精确的路由将会给ISP带来管理负担。
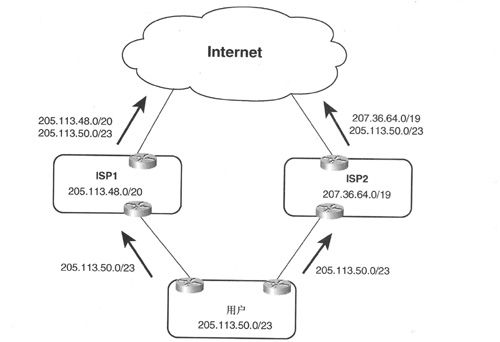
图2-8 ISP1在其CIDR地址块中“打孔”
虽然图2-7和例2-8显示的ISP1到Internet只有单一连接,但在大多数情况下,ISP一般都拥有多条连接链接到上层服务提供商及NAP。对每条连接来说,服务提供商都必须重新配置其路由器,除了CIDR地址块之外,还必须宣告更为精确的路由,而且还有可能要修改其所有的入路由过滤器。此外,为了正确宣告用户的/23地址块,还需要ISP1和ISP2进行密切配合,但由于ISP1和ISP2处于竞争状态,双方或某一方不愿意进行紧密合作,从而大大增加了管理复杂度。
即使图2-8中的用户征得ISP1和ISP2的允许,同意宣告其/23地址块,仍然存在其他障碍。因为某些Tier I提供商为了控制骨干网层次的路由表规模,仅接受/19或更小的地址前缀,此时,如果ISP1或ISP2或两者从这样的网络服务提供商获得Internet连接,那么就无法宣告用户的/23地址块。在实际应用中,过滤前缀大于/19的CIDR地址已成为惯例,前缀/19也被称为全局可路由地址(globally routable address)。这就意味着如果宣告了更长的CIDR地址前缀(如/21或/22),那么这些前缀也不会被宣告到整个Internet。请记住,如果Internet的某些网络不知道该如何到达用户的网络,那么用户也将无法到达这些网络。
注意:为了解决日益增加的用户投诉,目前许多Tier I服务提供商已经放松了/19规则。
对图2-8中的多归属用户来说,一种可能的解决方案就是获得一段与提供商相独立(provider-independent)的地址空间(也称为可携带地址空间)。也就是说,用户可以申请不属于ISP1或ISP2的CIDR地址块的独立地址块,这样一来,ISP1和ISP2就可以在不干扰其地址空间的情况下宣告用户的自有地址块。有了ARIN之后,申请一块与提供商相独立的地址空间比从InterNIC申请变得相对容易一些,虽然ARIN也强烈建议用户首选从其提供商申请IP地址,再次从其提供商的提供商申请IP地址,而将从ARIN申请与提供商相独立的地址空间作为最后解决手段。不过,即便如此,仍然要面临很多难题。
首先,准备实施多归属的用户目前的地址空间很可能是从原先的ISP获得的,更改为与提供商相独立的地址空间就需要重新编址,也就会出现上面所描述的所有问题。(当然,如果在应用CIDR之前就已经取得了属于自己的IP地址空间,那么就已经是与提供商相独立的地址空间了,也就不存在上述问题了。)
其次,注册管理机构是根据正当需求而不是长期预测需求来分配地址空间,在该分配策略下,也就意味着可能仅分配满足当前及三个月预测需求的地址空间,而且在下次申请时,必须证明已经有效地使用了原先分配的地址空间。例如,ARIN需要用户证明使用了SWIP(Shared WHOIS Project,共享式WHOIS方案)或RWHOIS(Referral WHOIS Server,参考WHOIS服务器)。其中最常用的是SWIP,做法是将WHOIS信息加入到SWIP模板当中并用电子邮件的方式发送给ARIN。要想使用RWHOIS,必须在网络前端增加RWHOIS服务器,以便ARIN能访问WHOIS信息。无论采取哪种方式,这些WHOIS信息都可以证明用户是否有效使用了地址空间、目前是否己处于即将耗尽状态以及当前的地址空间。
当然,如果用户无法证明申请一个全局可路由(/19)地址空间的正当性的话,将也是一个问题。CIDR分配规则至少会为小用户和ISP的多归属带来难题,接下来的章节将详细讨论多归属问题,并提供一些可替代的拓扑结构。
