5.2 多播路由存在的问题
目前存在以下5种处于不同发展和部署阶段的多播路由协议。
• DVMRP(Distance Vector Multicast Routing Protocol,距离矢量多播路由协议)
• MOSPF(Multicast OSPF,多播OSPF)
• CBT(Core-Based Trees,核心树)
• PIM-DM(Protocol Independent Multicast, Dense Mode,协议无关多播—密集模式)
• PIM-SM(Protocol Independent Multicast, Sparse Mode,协议无关多播—稀疏模式)
后续章节中将对有关每种多播路由协议的细节信息进行详细说明,并讨论每种协议的优缺点。虽然Cisco IOS Software不同时支持上述5种协议,但学习它们有助于更好地理解为何支持/不支持它们。在上述5种协议中,Cisco IOS Software支持PIM-DM和PIM-SM,也支持DVMRP,并允许将PIM网络连接到DVMRP网络上。上述5种协议都属于多播IGP,有关跨越AS边界的多播技术将在第7章中进行详细讨论。
虽然这5种多播路由协议之间的差别很大,但与单播路由协议相似,它们之间也有一些共同点,本节将讨论任意多播路由协议设计方面的一些通用问题。
5.2.1 多播转发
与其他路由器一样,多播路由器的两个基本功能也是路由发现和包转发。本小节将讨论多播转发方面的特殊需求,下一小节将讨论多播路由发现方面的需求。
单播包转发就是将某个数据包向确定的目的地进行转发。除非配置了某些特殊策略,否则单播路由器不会关心数据包的源。在接收到数据包之后,单播路由器会检查数据包的目的IP地址,并执行最长匹配路由查找操作,最后通过某个接口将数据包向目的地进行转发。
与单播路由器将数据包向目的地进行转发不一样,多播路由器是将数据包向远离源的方向进行转发。这个区别看起来有些微不足道,但这正是正确进行多播包转发的基础。多播包源自单个源,但却去往一组目的地。对特定路由器来说,数据包会到达某个入接口,但却可能将多份数据包拷贝从多个出接口进行向外转发。
如果存在路由环路,那么一个或多个被转发的数据包将会回到入接口,然后被复制并沿着相同的出接口被转发出去,其结果就是产生多播风暴(multicast storm),让数据包不断地被环回、复制,直至TTL到期。由于数据包会被不断地复制,因而多播风暴比简单的单播环路产生的后果更加严重。因此,所有的多播路由器都必须能感知数据包的源,而且必须只能向离开源的方向转发数据包。
一个有用的常见术语就是上行(upstream)和下行(downstream),多播包应该总是沿着自源至目的地的下行方向进行传递,而不能沿着自目的地至源的上行方向进行传递。为此,每台多播路由器都必须维护一个记录(源,组)或(S,G)的多播转发表,以保证来自特定源、去往特定组的数据包只能到达上行接口,并从一个或多个下行接口转发出去。从定义上来看,上行接口比下行接口更靠近多播源(如图5-18所示)。如果路由器在其他接口(而不是该多播包所属源的上行接口)上接收到一个多播包,那么就丢弃该多播包。
当然,路由器需要利用某种机制来确定给定(S,G)的上行和下行接口,而这就是多播路由协议的职责。
5.2.2 多播路由
单播路由协议的功能就是发现去往特定目的地的最短路径,这可以通过邻居路由器的宣告(距离矢量)或由拓扑结构数据库计算出来的最短路径树(链路状态)来确定。这两种方式的结构都是在路由表或转发表中创建一条表项,以指示从哪个接口将数据包转发出去,而且还可能包括下一跳路由器。从单播路由协议的角度来看,被引用的接口是去往目的地路径上的下行接口,也就是最靠近目的地的接口。
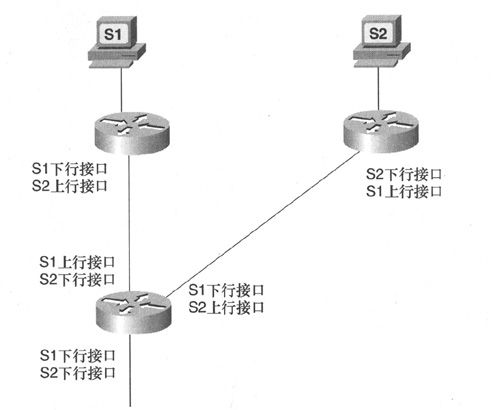
图5-18 通过标识与每个多播源相关的上行和下行接口,路由器可以避免多播路由环路
与此相反,多播路由协议的功能是确定上行接口,也就是最靠近源的接口。这是因为多播路由协议关心的是去往源最近的路径,而不是去往目的地最近的路径,多播包的转发进程也被称为反向路径转发(reverse path forwarding)。
多播路由协议在确定去往源的最短路径时,最简单的方法就是参考单播转发表。但是,正如上一小节所指出的那样,转发多播包的依据是独立的多播转发表中的信息,其原因是路由器不仅要为特定的(S,G)的源记录上行接口,还要记录与多播组相关的下行接口。
最简单的多播包转发方法就是将上行接口之外的所有接口都宣告为下行接口,但是这种被称为RPB(Reverse Path Broadcasting,反向路径广播)的方法有非常明显的缺点。顾名思义,RPB可以有效地将数据包广播到被路由互联网络中的所有子网上,但组成员可能仅位于众多子网中的某个子网——甚至可能是一个很小的子网。这样一来,将每个多播包的拷贝都泛洪到每个子网上,不仅会破坏多播仅将数据包分发给感兴趣接收者的目的,而且会破坏多播路由协议本身的目的。
稍加改进后的包转发进程就是TRPB(Truncated Reverse Path Broadcasting,剪枝反向路径广播),当路由器通过IGMP发现其所连接的某些子网中无组成员,且这些子网无下一跳路由器时,路由器就不会将多播流量转发到这些子网上。与树的术语一致,TRPB中将这样的非转接性子网称为叶子网络(leaf network)。虽然TRPB有助于节约叶子网络的资源,但是仅对PRB做了有限的改进,路由器之间的链路带宽是非常宝贵的,在TRPB下无论是否需要都必须承载多播流量。
因而多播路由协议的第二个功能就是确定与(S,G)接口对相关的实际下行接口。当所有的路由器都确定了特定源和特定多播组的上行接口和下行接口后,就建立了多播树(如图5-19所示),树根是与源直连的路由器,树枝则连接到组成员所驻留的所有子网。如果数据包仅从去往组成员的接口向外转发,则称为RPM(Reverse Path Multicast,反向路径多播)。
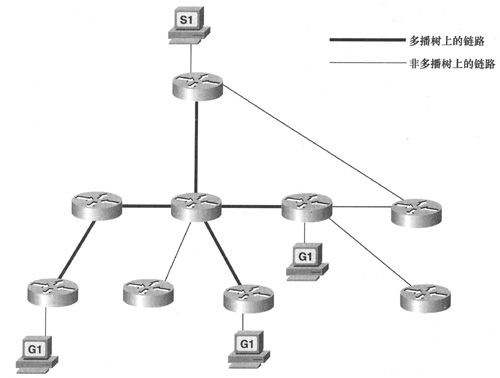
图5-19 从多播源到所有组成员所在子网的路径构成了一棵多播树
多播树仅在多播会话期间存在,由于组成员在整个会话生存期内都可以加入和离开组,因而多播树的结构是动态变化的。多播路由协议的第3种功能是管理多播树,当组成员加入多播组时负责嫁接,当组成员离开多播组时负责剪枝。接下来的3个小节将围绕第3种功能进行详细描述。
5.2.3 稀疏与密集拓扑结构
密集拓扑结构指的是某个互联网络中的多播组成员占全部主机的绝大多数,而稀疏拓扑结构指的则是互联网络的多播组成员仅占全部主机中一小部分,但并不是说稀疏拓扑结构下的组成员数量很少。例如,在拥有100 000台主机的网络中,稀疏拓扑结构下的组成员可能为2 000个。
对稀疏和密集拓扑结构来说,没有绝对的数量比例界限,但通常可以说,密集拓扑结构常见于交换式LAN和园区网络环境中,而稀疏拓扑结构则常见于WAN中。非常重要的一点是,多播路由协议在设计时就针对某种拓扑结构,并被指定为密集模式(dense mode)协议或稀疏模式(sparse mode)协议。表5-3列出了上述5种多播路由协议的类别情况。

5.2.4 隐式加入与显式加入
如前所述,成员可以在多播会话生存期内的任何时间加入和离开多播组,因而多播树是动态变化的。多播路由协议的作用就是管理这种多播树的变化情况,在组成员加入多播组时负责嫁接,在组成员离开多播组时负责剪枝。
多播路由协议可以通过隐式(implict)加入或显式(explict)加入策略来完成这项工作,其中,隐式加入由发送方发起,而显式加入则由接收方发起。
以隐式方式维护多播树的多播路由协议通常被称为广播/剪除(broadcast-and-prune)或泛洪/剪除(flood-and-prune)协议。当发送方第一次发起多播会话时,互联网络中的每台路由器都利用反向路径广播机制将数据包从所有接口(上行接口除外)转发出去,因而多播会话会到达互联网络中的所有路由器。当路由器接收到多播流量时,通过IGMP来确定其直连的子网中是否有组成员,如果没有组成员,而且没有下游路由器(需要将多播流量转发给下行路由器),那么该路由器将会向其上游邻居发送一条被称为剪除消息(prune message)的毒性反转(poison-reverse)消息。之后,上游邻居就不再向该被剪除路由器转发多播会话流量。如果该邻居的直连子网中也没有组成员,而且其所有下游路由器都已经被剪除出多播树,那么该邻居也会向其上游路由器发送剪除消息。这样一来,最终的多播树就会删除所有通向那些直连子网中无组成员的路由器的树枝。图 5-20解释了这种广播/剪除技术。
对转发表中的每个(S,G)来说,互联网络中的每台路由器都会维护其每个下行接口的状态,即转发(forward)或剪除(prune)。其中,剪除状态有一个与其相关的定时器,当定时器到期时,会重新将多播会话流量发送给该接口上的邻居。此时,每个邻居都会再次检查组成员,并将多播流量泛洪到自己的下游邻居,如果发现了新的组成员,那么将继续接受多播流量;否则,会向上游邻居发送新的剪除消息。
与稀疏拓扑结构相比,广播/剪除技术更适用于密集拓扑结构。该技术要求在初始时刻向所有路由器进行泛洪,然后进行周期性地重泛洪(当剪除状态定时器到期时),并维护剪除状态。如果许多或大部分树枝都要被剪除,此技术将会给网络资源带来很大的浪费。此外,该技术在维护剪除状态时还存在一个不合逻辑的强制性约束,即要求那些未加入多播树的路由器也得记住“它们不是多播树的一部分”。
对稀疏拓扑结构来说,一种更优的解决方案就是显式加入,此时由直接连接了组成员的路由器发起加入请求。当组成员通过IGMP告知路由器其希望加入多播组时,路由器会向上游源发送加入请求消息。与剪除消息不同,该消息被称为嫁接(graft)消息,路由器通过发送该消息将自己嫁接到多播树中。如果某路由器的所有组成员都离开了多播组,且该路由器没有处于活动状态的下游邻居,那么该路由器就会将自己从多播树中剪除出去。
由于显式加入协议从不会将多播会话流量转发到那些没有提出显式加入请求的路由器,因而可以节省网络资源。此外,由于未加入多播树的路由器无需保持剪除状态,因而可以节省路由器的总体内存资源。由此可见,显式加入协议更适用于稀疏拓扑结构。当然,可以认为无论是稀疏拓扑结构还是密集拓扑结构,显示加入协议的扩展性都更好。表5-4列出了5种多播路由协议采用显式加入和隐式加入协议的情况。
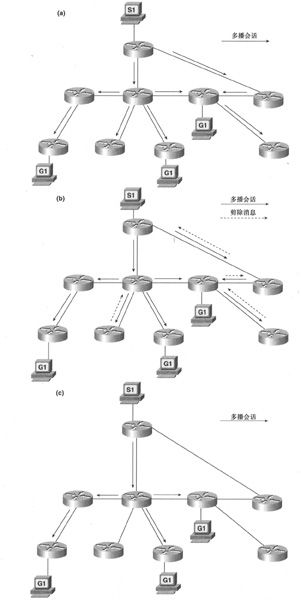
图5-20 广播/剪除协议首先利用RPB将多播会话发送给网络中的所有路由器(a),那些没有连接组成员的路由器会自行将自己从多播树中剪除出去(b),因而多播树中仅去往那些带有组成员的路由器(c)

表5-4 隐式加入和显式加入协议
5.2.5 有源树与共享树
某些多播路由协议会为每个多播源构建独立的多播树,由于这些多播树的根都是多播源,因而被称为有源树(source-based trees)。本章前面所说的多播树都是有源树。
如前所述,在多播会话的生存期内,随着组成员的加入和离开,多播树会发生动态变化,并且由多播路由协议负责管理多播树的变化情况。但某些多播树可能不会发生变化,图5-21给出了同一互联网络中的两个多播树,从图中可以看出,虽然这两个多播树有不同的源和不同的成员,但它们的路径至少经过同一台路由器。
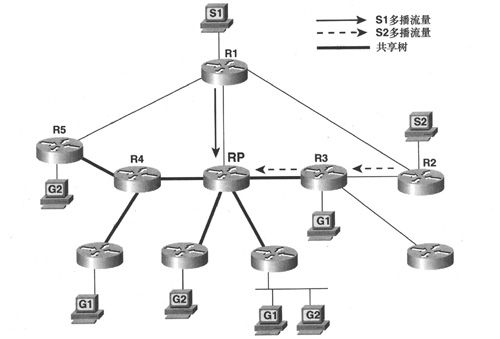
图5-21 两个多播树的现状虽然不同,但都通过同一台RP路由器
共享树(shared trees)利用了多个多播树可以共享网络中的同一台路由器这一事实。共享树不再以每个源为根建立多播树,而是以一台共享的被称为RP(Rendezvous Point,聚合点)或核心(core)的路由器为根。RP是预先确定好的,在策略上位于互联网络之中。当多播源开始一个多播会话时,需要首先向RP注册,由与多播源直连的路由器来确定去往RP的最短路径,或者由RP负责确定去往每个多播源的最短路径。显式加入协议用来创建从连接了组成员的路由器到RP的多播树,与有源树记录(S,G)不同,共享树记录的是(,G)状态,该状态表明RP是去往多播组的多播树的源,而且可能会存在多个多播源(位于RP上游)。更重要的是,有源树需要为每个源记录单独的(S,G),而共享树只需要为每个多播组记录一个(,G)。
通过一些简单的计算即可说明(S,G)表项的影响。假设有一个有源树,属于泛洪/剪除多播域,它拥有200个多播组,每个组平均30个多播源,每台路由器必须为每个组记录30条(S,G)表项,则一共30×200=6 000条表项;如果200个多播组中各有150个多播源,那么(S,G)表项数将达到150×200=30 000条。
注意: 请记住,对于交互式多播应用来说,许多组成员(接收者)同时也是多播源(发送者)。
与此相反,共享树只要为每个多播组记录一条(,G)表项即可,因此,如果一个共享树多播域中有200个多播组,那么RP只要记录200条(,G)表项,最重要的是,该数量不会随着多播源数量的变化而变化。可以用另外一种方式来说明这个问题,有源树是(SG,GN)的幂函数,而共享树是(GN)的幂函数,其中GN是多播域中的组数,SG是每个多播组中的源数。除此以外,共享树还能降低对非RP路由器的影响,这是因为这些路由器无需保存不由它们转发数据包的组的状态信息,这些路由器仅为每个活动下游组记录一条(*,G)表项。
这种扩展性意味着共享树更适用于稀疏拓扑结构,但是也要考虑一些折衷情况。首先,对每个组的每个成员来说,从源经RP到目的地的路径可能不是最优路径。重新看一下图5-21,多播组2的成员连接在路由器R5上,从源S2到该组成员的最优路径应该是R2-R1-R5,但是多播源的流量必须先经过RP,因而最后选择的路径为R2-R3-RP-R4-R5。因此,必须仔细选取RP,以便尽可能地减少次优路径。共享树的另一个缺点是存在多个大带宽多播会话时,RP将成为瓶颈。正是由于存在次优路径和RP拥塞问题,因而设计得不好的共享树互联网络中将存在时延问题。此外,RP也是单点故障源。最后,共享树也很难进行故障调试。
表5-5列出了使用有源树和共享树的多播路由协议情况。与表5-4相比可以看出,虽然 MOSPF使用了显式加入协议,但也同时使用了有源树。不过相反情况总是错误的,也就是说,使用共享树的协议必须始终使用显式加入,因为没有其他方式可以维护无环路多播树。

表5-5 有源树和共享树协议
5.2.6 多播定界
通过前面对多播路由问题的讨论可以看出,虽然多播路由能够比其他路由选择策略(如重复的单播或简单的泛洪)节省网络资源,但是在某些情况下也会浪费网络资源,特别是在稀疏拓扑结构中使用广播/剪除机制时更是如此。在某些情况下,对整个互联网络的规模来说,多播源和所有组成员通常都聚集在较近的位置,因而利用某种机制将多播流量限制在互联网络中组成员所在区域,将能大大节省网络资源。有时,出于安全性或其他策略考虑,可能需要将多播流量限定在一定范围内。
当多播流量被限定在“孤岛”内时,就称这些多播流量被限定区域(scoped)了。换句话说,多播定界(multicast scoping)就是限定多播流量的边界。
一种建立多播边界以限定多播流量的方法就是在出接口上设定特殊的过滤器,以检查所有多播包的TTL值。数据包的TTL值经路由器正常递减后,仅转发TTL值超出预配置阈值的数据包,其他的数据包则被丢弃。
图5-22给出了一个示例。在图中所示的路由器上,到达接口E2的多播包的TTL值为13,该路由器将该多播包的TTL值递减为12,接口E0的多播TTL阈值为0(为默认值),这样就不会有任何多播包会因TTL值而被阻塞,因而会将一份数据包拷贝从接口E0转发出去。与此相似,也会从接口E1转发出去一份数据包拷贝(因为接口E1的TTL阈值被设置为5,小于该数据包的TTL值),但是,由于接口E3的TTL阈值被设置为30(意味着仅转发TTL值大于30的数据包),因而不会从接口E3向外转发该多播包。
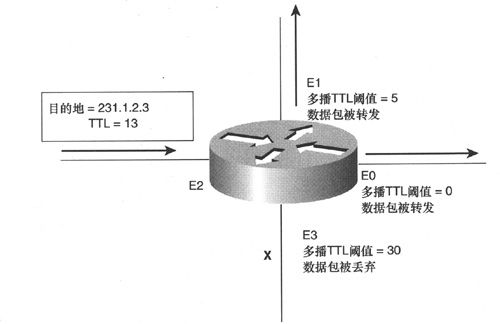
图5-22 多播包从下行接口(接口的TTL阈值小于出站数据包的TTL)被转发出去
TTL定界曾经被用于MBone, MBone是一个通过IP-over-IP隧道经互联网相连的区域性多播网络。表5-6给出了MBone中限制多播流量的典型TTL值,如果希望将多播流量限定在某个站点之内(如大带宽实时视频),可以配置多播源应用程序,转发TTL值小于等于15的数据包。
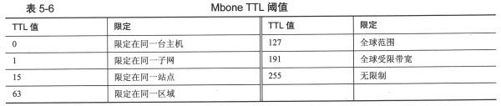
表5-6 Mbone TTL阈值
TTL定界方法也有一些缺点。首先,接口的TTL阈值会被应用于所有的多播包,如果希望某些多播会话不受TTL阈值限定,而仅限定其他多播会话,那么就需要使用其他定位多播会话源的应用程序。这样又会出现第二个问题,那就是必须信任用户能在其多播应用程序中正确地设置TTL值。如果某多播会话的TTL被多播源设置得非常大,那么将会穿越事先设定的多播边界。
TTL定界的另一个问题是很难在所有网络中加以实施,只能用于简单的网络拓扑结构。随着多播网络规模和复杂度的日益增大,正确预测TTL阈值来容纳和传递正确的多播会话将变得非常困难。
最后,TTL定界在广播/剪除协议下的效率很低。图5-23解释了这个问题,图中的互联网络是一个多播站点,边界路由器的接口上被配置了TTL阈值8,多播源正在生成多播会话,所有多播包的TTL都被设置为8。为了与本地策略一致,需要将多播流量限定在多播站点之内,由于多播树左边的树枝上没有组成员,因而这些路由器应该将自己从多播树中剪除出去,直至与多播源直连的路由器,事实上,从图中可以看到有一台路由器已经向其上游邻居发送了剪除消息。
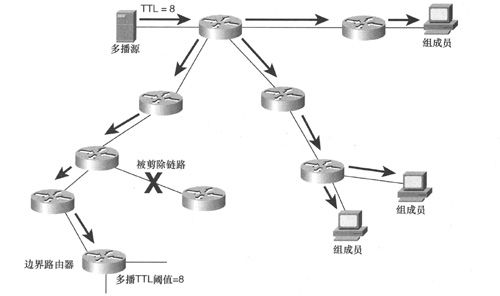
图5-23 在边界路由器上设置的多播过滤器阻止了路由器向上游邻居发送剪除消息
但问题在于边界路由器及其配置的TTL过滤器,当多播包到达该路由器时,由于多播包的TTL值小于路由器接口的TTL阈值,因而多播路由器的两个下行接口都会丢弃这些多播包。虽然这是大家所期望的处理行为,但丢弃多播包也就意味着不会出现IGMP查询消息。如果没有IGMP查询,边界路由器就不会向上游邻居发送剪除消息,这样一来,多播流量就会被毫无必要地持续通过所有路由器转发给边界路由器。
2.管理性定界
有关管理性定界方法的详细描述请见RFC 23657,这是另一种限定多播流量边界的方法,此方法不再是过滤TTL值,而是使用一段D类地址来进行多播定界。这样一来,只需要对组地址进行过滤就可以设置多播边界,这些被保留用作多播范围定界的D类多播地址是239.0.0.0〜239.255.255.255。
管理性定界多播地址空间还可以按照层次化方法进行细分。例如,RFC 2365建议将 239.255.0.0/16用作本地范围或本站点范围,239.192.0.0/14用于组织机构范围,不过企业可以根据自己的需要自由使用这些保留地址空间。在这一点上,这些保留的D类地址类似于被保留用作私有用途的RFC 1918地址,并且与RFC 1918地址相似。这些管理性定界多播地址不是全球惟一的,因而必须设置相应的过滤器,来过滤239.0.0.0〜239.255.255.255,以避免该地址空间内的地址被泄露到公众Internet上。
其实读者在本章和本书的其他地方已经接触了TTL定界和地址定界。回顾一下,IGMP和OSPF包的TTL始终被设置为1,就是要阻止任何路由器转发这些数据包,此时流量范围就是本地子网。与此相似,路由器不转发224.0.0.0〜224.0.0.255地址范围内的数据包,而该地址(包含了表5-1所列的全部地址)也是将流量范围限定在本地子网之内。
