9.7 记 账
有时收集流量流的统计信息以计算网络使用率非常有用,特别是在实施流量工程或基于使用量对网络用户进行计费时。
可以在路由器接口上启用基本的IP记账(accounting)功能,之后就可以获得数据包的源和目的地列表,以及任两个节点之间传递的字节数和数据包数量。NetFlow可以提供更为详尽的记账功能,除了源、目的地、数据包数量和字节数之外,还可以提供协议和AS信息。可以采取不同的形式来聚合NetFlow数据,包括按自治系统聚合、按子网前缀聚合或按照协议类型聚合等,有关NetFlow的详细论述请见9.7.2小节。
9.7.1 IP记账
IP记账功能可以提供基本的记账服务,可以根据源/目的地统计并维护穿越路由器的数据包数量,而源自该路由器的数据包或目的地是该路由器的数据包则不在统计之内。记账功能是在出站接口上进行的,IP记账功能将禁用接口上的自主交换(autonomous switching)和SSE交换,可以统计所有通过访问列表的数据包以及被该路由器所路由的数据包。作为可选项,也可以对未通过访问列表的数据包启用记账功能,因为如果出现了大量违反访问列表规则的数据包,则表明存在网络攻击行为或该路由器的配置有问题。
利用命令ip accounting即可在路由器的出站接口上启用记账功能。
为了显示在出站接口上启用记账功能之后的效果,可以使用命令show ip accounting [checkpoint] [access-violations].
例9-25显示了在以太网接口上收集到的IP记账数据。
例9-25:在以太网接口上启用IP记账功能,命令show ip accounting显示该接口正向外发送多播包。


上例在路由器Bowler的以太网接口0上启用了IP记账功能,所有通过该以太网端口被路由出去的数据包都将在统计之列,随后给出的记账表显示源地址为10.1.1.88的多播包被发送给224.2.127.254和228.13.20.216。
利用命令clear ip accounting可以清除记账表。
IP记账功能可以提供非常有价值的关于现有接口流量的信息,但是需要注意,启用IP记账功能之后可能会引起性能劣化,这是因为IP记账禁用了接口上的自主交换和SSE交换机制,因而需要使用效率较低的交换机制将接口上的数据包交换到网络中。此外,维护记账数据库还要消耗路由器的内存资源,在路由器的内存资源较低时不建议启用IP记账功能。
命令的作用是定义记账数据库中可以存储的表项数,默认数值是512对源/目的地,因而每个数据库的内存消耗最大为12 928字节。如果将阈值修改或设置得过大,那么所有的可用内存将被消耗掉。
在接口上启用IP记账功能可以根据源地址和目的地址快速查看出站流量,但路由器本身并没有内嵌机制将这些数据传送给可以解析这些数据的服务器,并形成有用信息。而NetFlow不但可以提供更多的流量流信息,还可以提供这方面的功能。
9.7.2 NetFlow
NetFlow交换模式可以标识流量流并在路由器上执行交换和访问列表进程,此外由于NetFlow标识了流量流,因而可以将流量流的统计信息导出到记账服务器。在数据流处于活动状态时,该数据流的数据都被保持在NetFlow的缓存中,当流量流到期时,可以将该流量流增加到聚合缓存并导出至管理站。NetFlow的默认缓存可以包含64K个流缓存表项。
注意: 与其他交换模式相比,NetFlow交换会消耗更多的内存和CPU资源,因而在路由器上启用NetFlow之前必须理解NetFlow对资源的需求。
要想启用NetFlow交换,可以使用接口子命令ip route-cache flow。
要想定义用来接收数据的流采集器的IP地址和UDP端口号,可以使用以下全局命令。
ip flow-export destination ip-address udp-port
ip flow-export [version 1 | version 5 [origin-as | peer-as]]
命令中的版本号必须与流采集器所期望的版本号一致,默认为version 1。
选项origin-as用来指定所导出的数据中应包含源和目的地的BGP发信AS。
选项peer-as用来指定所导出的数据中应包含用于采集数据的路由器的BGP对等体AS,而不是与该源和目的地相关的流量所属的实际AS。
图9-2给出了一个简单的运行BGP并在路由器Hummer上采集NetFlow数据的网络。
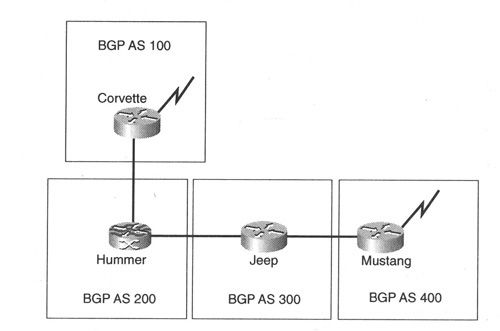
图9-2 运行NetFlow进行流量流记账的BGP网络
路由器Hummer上启用了NetFlow功能,用于采集两个接口上的流信息。例9-26显示了 Hummer的配置情况。
例9-26:让图9-2中的路由器Hummer采集两个以太网接口上的流信息。

如例9-26所示,采集数据中包含的是对等体AS,而不是发信AS。
命令show ip flow export显示了数据导出参数,而命令show ip cache flow则显示了流缓存情况。
例9-27显示了流导出参数以及路由器Hummer的流缓存情况。
例9-27:命令show ip flow export和show ip cache flow所显示的NetFlow流信息。

(待续)
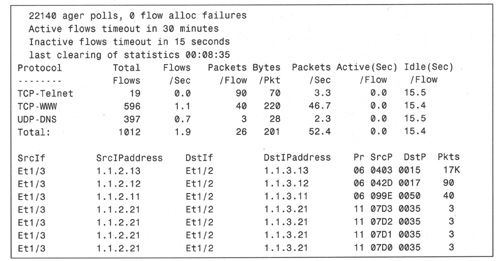
从上例可以看出,NetFlow所提供的信息要远远多于IP记账机制——包大小分布情况以及汇总信息,所有信息都以协议类型和各个流为基础进行显示。
可以采取不同的方式来聚合和组合流信息:基于自治系统号、源前缀、目的前缀或协议端口。聚合缓存可以让路由器在将采集到的NetFlow数据导出给流采集器之前进行一定的聚合,主NetFlow缓存中的流数据到期时将进入各聚合缓存。
流聚合仅使用NetFlow版本8聚合缓存,该版本允许导出聚合缓存,而版本5缓存需要在选项origin-as或peer-as中进行指定配置。
在配置流聚合之前必须在路由器上启用CEF(Cisco Express Forwarding, Cisco快速转发)和NetFlow交换,启用了CEF之后,就可以按照数据包的源地址和目的地址来聚合转发缓存(被用于聚合数据中)。
注意: 如果希望进一步了解CEF,请参考IOS 12.1配置指南中的CEF概述以及CCO上的交换服务配置指南。
利用命令ip cef即可在全局启用CEF,该命令将在所有支持CEF的接口上都启用CEF路由缓存(route-cache)。以下全局命令的作用是定义一个聚合缓存。
ip flow-aggregation cache {autonomous_system | destination-prefix | prefix | protocol-port | source-prefix}
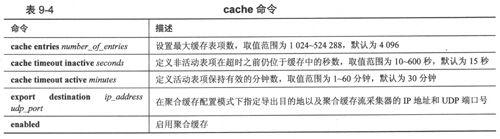
表9-4列举了可用于聚合缓存的部分命令,所有这些命令都必须在聚合缓存配置模式下输入。
AS聚合(AS aggregation)可以聚合拥有相同源BGP AS、目的BGP AS、输入接口以及输出接口的流,导出数据中包含了被聚合记录所汇总的流数、包数、字节数。
例9-28:图9-2中的路由器Hummer被配置了AS聚合。

利用命令show ip cache flow aggregation as即可显示AS聚合缓存的内容,如例9-29所示。
例9-29:利用命令show ip cache flow aggregation as查看AS聚合缓存的内容。

从上例可以看出,与源接口以太网1/3、源AS 400、目的接口以太网1/2和目的AS 100相关的流一共有357个。
可以进一步启用前缀聚合(prefix aggregation),前缀聚合除了基于与AS聚合相同的数据(包括源和目的BGP AS、输入接口及输出接口),还能进一步按照源和目的前缀以及源和目的前缀掩码对流进行聚合。
目的前缀聚合(destination-prefix aggregation)的作用是聚合拥有相同目的前缀、目的前缀掩码、目的BGP AS和输出接口的数据流,利用该机制可以按照目的地信息来检查穿越 NetFlow路由器的流量。
如例9-30所示对路由器Hummer进行配置。
例9-30:为图9-2中的路由器Hummer配置目的前缀聚合。

例9-31显示了目的前缀聚合缓存的内容。
例9-31:利用命令show ip cache flow aggregation destination-prefix查看目的前缀聚合缓存的内容。


从上例可以看出,与目的接口以太网1/2、目的前缀1.1.3.0、掩码/24、目的AS 100相关的流一共有324个。
同样,也可以利用源前缀聚合(source-prefix aggregation)机制,根据源信息来检查数据流,该方案根据源前缀、源前缀掩码、源BGP AS和输入接口来聚合数据流。
如例9-32所示对路由器Hummer进行源前缀聚合配置。

例9-32:为图9-2中的路由器Hummer配置源前缀聚合。
例9-33显示了源前缀聚合缓存的内容。
例9-33:利用命令show ip cache flow aggregation source-prefix查看源前缀聚合缓存的内容。

从上例可以看出,与源接口以太网1/3、源前缀1.1.2.0、掩码/24、源AS 400相关的流一共有181个。
如果希望按照流量类型来检查数据流,那么就可以启用协议端口聚合(protocol-port aggregation),这样就可以将具有相同IP协议、源端口号和目的端口号的流进行聚合。
如例9-34所示对路由器Hummer进行协议端口聚合配置。
例9-34:为图9-2中的路由器Hummer配置协议端口聚合。

例9-35显示了协议端口聚合缓存的内容。
例9-35:利用命令show ip cache flow aggregation protocol-port查看协议端口聚合缓存的内容。
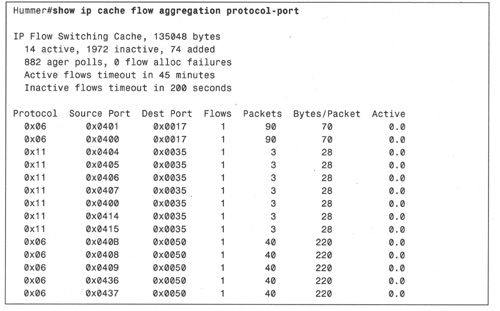
从上例可以看出,有14种协议端口流被按照IP协议、源端口和目的端口进行聚合。
不同的聚合缓存机制为流量流的聚合方式提供了更多的灵活性,这些信息完全可以被用来进行流量分析,甚至用作计费依据。
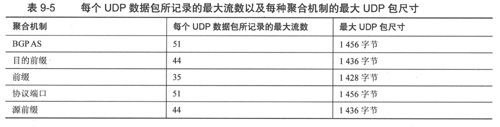
表9-5列出了每个UDP数据包所记录的最大流数以及每种聚合机制的最大UDP包尺寸。
Cisco NetFlow FlowCollector是一个收集和报告NetFlow数据的应用程序,FlowCollector负责聚合来自多台Cisco路由器(和交换机)所导出的NetFlow数据,可以对这些数据进行过滤或组合,以满足网络管理者的不同要求。
注意: 有关Cisco NetFlow FlowCollector的详细信息请参考CCO站点www.cisco.com/univercd/cc/td/doc/product/rtrmgmt/nfc/nfc_3_0/nfc_ug/index.htm。
