8.4 IPv6 功能
对任何支持IPv6的节点来说,必须实现以下IPv6功能。
• ICMPv6。
• 邻居发现。
• 无状态自动配置。
• 任播。
• 多播。
• MTU路径发现(建议)。
这些都是IPv6的基本功能,其中大多数都是对IPv4的功能增强。
IPv6的另一个功能特性就是可以为任何接口分配多个地址。该功能简化了前缀重新编址的问题,不仅任意IPv6接口都可以拥有多个前缀的多个地址,同一个链路上的两个节点之间也可以进行直接通信(与这两个节点的地址前缀无关)。
本节将详细讨论上述功能,为了帮助理解IPv6的功能,本节还将给出具体的Cisco路由器配置及命令。
8.4.1 在 Cisco路由器上启用 IPv6 能力
默认情况下,Cisco路由器是禁用IPv6的,因而需要利用以下全局命令在Cisco路由器上启用IPv6。
ipv6 unicast-routing [table-count num]
Cisco路由器支持启用多路由表机制,在默认情况下仅启用一个路由表。多路由表可以为网络管理员在路由表查询方面提供更多的控制手段,最长匹配路由不再是惟一的路由查找规则,如果启用了多路由表,那么转发算法将以增量顺序来查找路由表,直至找到可用路由。
配置IPv6的下一步工作就是启用一个IPv6接口,并启用自动配置机制或为该接口手工配置一个IPv6地址,下面将讨论自动配置机制。
启用IPv6接口并为该接口配置IPv6地址的接口子命令如下。
ipv6 address ipv6address/prefix-length[link-local]
启用IPv6接口但不指定接口地址的接口子命令如下。
ipv6 enable
路由器会自动配置一个链路本地单播地址作为该IPv6接口的一部分。
路由器Falcon和Eagle都连接在同一条以太网链路上,它们的配置情况如例8-1所示。
例8-1:在连接到同一条以太网链路上的两台路由器上启用IPv6。
请注意,例8-1中两台路由器的配置完全相同。
显示接口的IPv6状态以及相关接口信息的命令如下。
show ipv6 interface interface-type number
例8-2显示了命令show ipv6 interface的部分输出结果,显示了以太网接口的MAC地址以及该接口的IPv6状态和链路本地地址。
例8-2:使用命令show ipv6 interface ethernet 0来查看IPv6接口的信息。

请注意,Falcon的MAC地址0000. 0C0A. 2C51创建了链路本地地址FE80: : 200: CFF: FE0A: 2C51, Eagle的MAC地址0000. 0C76. 5B7C创建了链路本地地址FE80: : 200: CFF: FE76:5B7C。此外,可以看出接口上已经启用了IPv6。
8.4.2 ICMPv6
ICMPv6是IPv6的一部分,每个实现了IPv6的节点都必须完全实现ICMPv6。ICMPv6是IPv4 ICMP的修改版本,差错报告以及许多IPv6功能(如MTU路径发现和邻居发现)都需要用到ICMPv6。本节将讨论差错消息。
ICMPv6包位于IPv6头部之后或某个扩展报头之后,由前一个报头中的IPv6下一报头值 58来标识(该值与IPv4中标识ICMP的值不同),通知消息和差错消息由ICMP类型字段中的高位bit加以标识。对差错消息来说,ICMP类型字段中的高位bit为0, ICMP差错消息中包含了尽可能多的不合规数据包,只要ICMP消息的长度不超过IPv6的最小MTU(即1 280字节)即可。
本小节将讨论以下差错消息。
• 目的地不可达;
• 包过大;
• 超时;
• 参数问题。
当节点因拥塞之外的某种原因不能转发数据包时将发送目的地不可达差错消息,该节点向数据包源发送的差错消息中包含以下内容。
• 没有去往目的地的路由(0);
• 访问行为被管理性禁止(1);
• 地址不可达(3);
• 端口不可达(4)。
当数据包大小超过了链路MTU时,节点将发送包过大差错消息。与IPv4—样,IPv6中的路由器也不执行分段操作,只有源节点才对数据包进行分段,产生该差错的链路MTU将包含在该数据包中,无论IPv6目的地是单播目的地还是多播目的地,都会发送包过大消息。该消息将被用于MTU路径发现进程。
当IPv6跳数限制字段值减为0时,将会发送一条ICMP超时消息。通常来说,跳数限制为0则表明存在路由环路。
当节点发现IP头部或扩展报头有问题时,将发送ICMP参数问题消息,其中的差错代码可以标识所出现的问题。
• 出现了不正确的头部字段(0);
• 出现了无法识别的下一报头类型(1);
• 出现了无法识别的IPv6选项(2)。
8.4.3 邻居发现
ND(Neighbor Discovery,邻居发现)协议解决了很多与单一链路上的节点有关的问题,提供了无服务器的自动配置(Serverless Automatic Configuration)、路由器发现(Router Discovery)、前缀发现(Prefix discovery)、地址解析(Address Resolution)、邻居不可达检测(Neighbor Unreachability Detection)、链路MTU发现(Link MTU Discovery)、下一跳确定(Next-hop Determination)以及重复地址检测(Duplicate Address Detection)等功能。对IPv4来说,联合使用多种协议(包括DHCP、IGMP路由器发现、路由协议以及ARP等)才能提供上述功能中的部分功能,而ND仅利用ICMPv6即可完成上述功能。ND希望将这些功能全部整合到ICMPv6(IPv6的一个必需组件)中以改善IPv4的相关进程。
节点初始化之后,必须了解以下信息才能进行通信。
• 必须知道自己的IP地址;
• 必须知道自己的前缀信息,以便计算出如何向位于其他前缀的节点发送数据包;
• 必须知道该链路上的所有路由器;
• 必须知道如何确定去往目的地的路径上的下一跳;
• 必须知道如何获得与已知网络层地址相关联的链路级地址;
• 必须知道自己可以发送多大的数据包。
为了让通信更加顺畅,节点还应该了解以下信息。
• 在邻居不可达时应该有相应的检测机制,以便不再向该邻居发送数据包;
• 应该了解其链路上的邻居;
• 应该知道其试图使用的地址是否已被链路上的其他节点占用;
• 需要了解已分配给同一链路上其他节点的其他前缀;
• 应该能够将流量重定向到更好的下一跳节点(如果存在)。
ND定义了5种ICMPv6数据包,以在IPv6节点进行通信之前提供其必须知道和应该知道的信息。
• RS(Router Solicitation,路由器请求)——当节点希望路由器立即发送路由器宣告而不是等待下一个预定宣告时,由该节点以多播方式发送该消息。初始化节点可以发送RS消息,这样就可以立刻了解配置参数以及链路上的路由器情况。
• RA(Router Advertisement,路由器宣告)——周期性地发送该消息或作为RS的响应,路由器通过该消息宣告它们的存在并提供节点配置自己所需的信息。
• NS(Neighbor Solicitation,邻居请求)——使得节点可以确定邻居的链路层地址或确定该邻居是否仍然可以通过已缓存的链路层地址到达,还能让节点确定链路上是否存在重复的IP地址。
• NA(Neighbor Advertisement,邻居宣告)——作为NS的响应消息,或者在节点的链路层地址发生变化时主动发送该消息。
• 重定向——由路由器发出的消息,目的是将流量重定向到链路上更优的下一跳。
上述每条消息都是一个已定义类型的ICMP包,ICMP包中包含了与类型相关的信息,每种类型的消息都包含了一个或多个TLV选项。
ND 为无状态自动配置(即无配置服务器的自动配置)提供了基本条件,RA提供了节点配置所需的相关信息。有关自动配置的详细信息将在8.4.4小节讨论。
1.RS
如果主机希望立即接收到RA(而不用等待周期性宣告),那么就会发送RS消息,初始化主机通过发送RS可以立即学习到其所需的配置信息。
RS 消息是类型为133的ICMP包,其源地址是分配给发送主机的接口的地址,如果仍未分配地址,那么其源地址将是未指定地址0: 0: 0: 0: 0: 0: 0: 0,目的地址通常情况下是所有路由器(all-routers)地址。RS中也可以包含一个发送方链路层地址的选项,如果源地址是未指定地址,那么将不能包含链路层地址。
2.RA
路由器通过该消息宣告它们的存在并提供节点配置自己所需的信息,RA以多播方式被发送给链路作用域内的所有节点(all-nodes)多播组。
RA 消息是类型为134的ICMP包,其源地址是发送路由器的链路本地地址,目的地址是发送RS的节点的地址或链路作用域内的所有节点多播地址。跳数限制字段必须被设置为 255,这样一来就不再使用跳数限制来阻止路由器转发数据包。如果跳数限制值为1,那么就可以确保该数据包不再被转发,这是因为接收到该数据包的路由器会将跳数限制值减1,并在跳数限制值为0时丢弃该数据包;而跳数限制值为255则可以确保没有链路之外的设备试图发送RA以破坏流量流,这是因为如果链路之外的设备发送了RA,那么该RA每穿越一台路由器之后,其跳数限制值都将被自动减1,那么就表明该RA无效。接收节点验证该数据包是否有效的一种方法就是验证其跳数限制值是否为255,而IPv4则没有使用该方法来确保数据包没有穿越路由器。
接收RA消息的主机会构建一个默认路由器列表,所有宣告了RA且RA中的路由器生存期(Router Lifetime)值非0的路由器都将出现在默认路由器列表中。位于默认路由器列表中的路由器的路由器生存期值会被随后接收到的RA包所更新,如果某RA包含的路由器生存期值(是默认路由器列表中的某台路由器)为0,那么主机会立即从默认路由器列表中删除该路由器(这是对IPv4的一大改善),而IPv4主机则必须手工配置默认路由器列表。某些 IPv4主机通过路由协议(如RIP)来动态学习该信息,而某些IPv4主机则通过IRDP(ICMP Router Discovery Protocol, ICMP路由器发现协议)来学习这些信息,但并不是每台IPv4主机都实现了RIP或IRDP。
RA 中包含一个可达时间(Reachable Time)和一个重传定时器(Retransmit Timer)。其中,可达时间的作用是告诉主机从邻居接收到可达性确认之后多长时间可以认为该邻居有效,该信息被用于邻居不可达检测进程。重传定时器就是连续两条NS消息之间(以毫秒为单位)的间隔时间,被用于地址解析和邻居不可达检测进程。
RA 消息中包含两个用来告知主机如何配置自己的bit,一个是Mbit(Managed Address,被管地址),另一个是O bit(Other Stateful Configuration,其他状态化配置)。如果M bit被置位,主机将使用状态化自动配置协议(如DHCP)来配置自己的地址(除了无状态自动配置所配置的地址);如果O bit被置位,则主机在使用状态化自动配置协议来配置地址之外,还用状态化自动配置协议来配置其他信息。IPv4则需要采用手工配置方式来表明是否通过 DHCP来学习它们的IP配置信息,通过RA消息自动向链路上的主机提供这方面信息可以最大化地减少主机中所包含的静态配置信息量,从而可以大大简化将来可能存在的重新配置工作。有关自动配置方法的详细描述请参见8.4.4小节。
RA 中的可能选项是源链路层地址、MTU以及前缀信息。在RA中包含路由器的源链路层地址可以让主机无需在默认路由器上执行地址解析协议,可以选举一台路由器不包含链路层地址。MTU选项的作用是集中控制主机在链路上所使用的MTU,该值在路由器中进行设置,然后在该链路上的所有主机上启用该配置。前缀信息的作用是向其他节点告知在链前缀(on-link prefix)信息并进行地址的自动配置。如果主机能了解链路上已配置的所有前缀信息,将大大提高其流量转发能力。多归属主机可以选择最近的接口去往任何已知的链路上的目的前缀,而非多归属主机则可以利用前缀列表来协助进行下一跳检测。
前缀信息选项中包含的数据可以用于在链决策(on-link determination)和无状态自动配置,不但包含了实际的前缀及前缀长度(1〜128bit之间)等信息,还包含了用来表示该前缀是否被用于在链决策或地址配置的指示bit。如果Lbit被置位,就表示可以使用该前缀进行在链决策;如果L bit未被置位,那么将无法确定在链(on-link)或离链(off-link)信息;如果A bit被置位,那么就表示可以利用该前缀进行无状态地址配置。
前缀信息选项中还包含了一个有效生存期(Valid Lifetime)值和一个优选生存期(Pref- erred Lifetime)值。有效生存期值(以秒为单位)表示该前缀用于在链决策的有效时间,该生存期相对于数据包被发送的时间而言,如果所宣告的有效生存期为0,那么表明该前缀不再有效。优选生存期(以秒为单位)表示的是从前缀信息中自动配置的地址能保持“优选”的时间,其中,接口的优选地址(preferred address)指的是任何节点都可以用其进行通信的地址。优选生存期为0表示必须贬抑从前缀信息中配置的地址,贬抑地址(deprecated address)指的是仅用于维护现有连接而不用于发起新连接(如果存在优选地址)的地址。如果生存期为全1,则表示无穷大,可以为在链决策和地址配置使用同一个前缀。有关这两类地址的详细情况将在8.4.4小节详述。
3.NS
NS 消息被用于获取邻居的链路层地址,并用来提供链路层地址、验证邻居的可达性。NS消息是类型为135的ICMP包,其源地址是请求节点(soliciting node)的链路本地地址,目的地址是被请求节点的多播地址(在链路层决策中与目标IP地址相关联)或单播地址(在可达性验证中与目标IP地址相关联)。NS的跳数限制值为255,与RA一样,跳数限制值255可以确保该数据包没有穿越路由器,因为一旦该数据包穿越了路由器,那么跳数限制值就必然小于255。此外,NS消息中还包含了一个指示目标地址的字段。
NS 消息中可以包含源链路层地址选项。如果NS试图发现一个目标链路层地址,将会在该链路上多播发送NS,因而该数据包中必须包含源链路层地址,从而最大程度地减少了该链路上的地址解析包。
4.NA
NA 作为NS的响应消息或者主动发送该消息以传播新信息(如节点的链路层地址发生变化), NA消息是类型为136的ICMP包,其源地址是任何有效的分配给发送接口的单播地址。对所请求的宣告来说,目的地址是请求方的源地址,如果请求方的地址是未指定地址,那么目的地址将是所有节点(all-nodes)多播地址,主动宣告通常被发送给所有节点多播地址。NA包含一个S bit(Solicited flag,请求标记),当NA作为NS的响应消息时就置位该S bit。NA的跳数限制值为255,目标地址与来自请求方的目标地址相同,该地址就是链路层地址所定位的地址,对主动宣告来说,该地址是链路层地址发生变化的 IP地址。NA可以包含目标链路层地址选项,在所发送的主动宣告中向各节点告知宣告路由器的新链路层地址(新链路层地址就位于该选项中)。请求NA消息与IPv4 ARP应答消息类似,而主动NA则是IPv6的一个附加特性,通过将NA以多播方式发送给所有节点地址(目的是向其他节点告知链路层地址已发生变化),就可以取代IPv4网络上的大量 ARP请求和应答广播。
5.重定向
路由器通过发送重定向消息来告知主机存在一个更优的去往目的地的下一跳,该更优的下一跳可能是一台不同的路由器,也可能是目的地本身。如果目的地是源节点的一个邻居(即使源节点和目的节点属于不同的前缀),那么路由器就可以重定向流量以便进行直接通信(这一点是对IPv4 ICMP的增强)。当同一链路上存在其他可选路由器作为源主机去往目的主机或目的网络的更优路径时,IPv4路由器将发送ICMP重定向消息,但如果该更优下一跳是目的地本身,那么将不重定向流量。该功能特性可以让同一数据链路上拥有不同前缀的主机进行直接通信,而无需经过路由器。
重定向消息的源地址是路由器的链路本地地址,目的地址是被重定向数据包的源地址,跳数限制值为255。
ICMP包中也包含目标IP地址和目的地址,如果更优的第一跳是一台路由器,那么目标地址是该路由器的链路本地地址,如果更优的第一跳是实际的目的地,那么目标地址就是该目的地的地址。ICMP目的地址是被重定向的流量的目的IP地址,请注意,如果更优的第一跳是目的地本身,那么这两个字段所包含的地址完全相同。
重定向消息中可以包含目标链路层地址选项,其作用是让主机在不依赖地址解析进程的情况下发现链路层地址。
此外,导致生成重定向消息的IP包的一部分也可以作为可选项,重定向消息可以尽可能多地包含IP包的内容,只要重定向数据包的大小不超过1 280字节即可。
6.下一跳发现
主机在发送数据包之前必须首先确定其所要使用的下一跳,如果之前向该目的地发送了数据包,那么下一跳信息可能会存储在目的缓存中。如果这是发送给该目的地的第一个数据包,则需要将目的地址与该主机的在链前缀列表进行对比以找到下一跳。发送给在链目的地的数据包可以被直接发送到目的节点,而离链目的地则需要先发送给默认路由器。但是对IPv4节点来说,只要流量的目的地不在本子网之内,就需要发送到默认路由器。如果目的地与源位于同一条链路上,但属于不同的子网,那么路由器将会把流量转发回该链路,从而使得该流量需要穿越两次该链路。
无论下一跳是目的地本身还是默认路由器,都需要识别下一跳的链路层地址。
7.地址解析
节点执行地址解析进程的作用是寻找与已知IP地址相关联的链路层地址,地址解析进程使用NS和NA消息。在将数据包发送到目的IP地址之前,主机必须首先检查其邻居缓存,以确定是否已存在该表项,如果没有,那么该节点将会为该目的IP地址创建一条表项(状态为INCOMPLEMETE),之后该节点会向该IP地址的被请求节点(solicited-node)多播地址发送一条NS消息。该请求消息的源地址是单播地址(要么是发起该流量的节点的源地址,要么是在源节点的远程链路上查询目的地的路由器的源地址),而且数据包中可以包含源链路级地址(如果有的话)。
节点从某单播地址接收到NS消息之后(目的地是分配给其接口的地址),将响应NA消息,以指示其链路级地址。
当请求节点接收到响应NA消息之后,会以目标的链路级地址来更新其邻居缓存表项,并将该表项的状态从INCOMPLETE更改为REACHABLE。
注意: 有关各种不同反应的完整描述请参见RFC 24613。
8.邻居不可达检测
如果正与其他节点进行通信的某节点出现了故障,那么在上层协议之前检测到该故障并没有多大用处。但如果去往目的地的路径上的某台路由器出现了故障,由于可能还存在其他可用路由器,因而在上层协议之前检测到该故障将非常有用。
可以利用以下两种方法来验证邻居的可达性:通过来自上层协议的提示,或者通过NS的响应消息。如果某邻居可达,那么在转发方向上(forward-direction)就必然能进行通信,如果转发操作是由上层协议决定的,那么就可以验证邻居的可达性。例如,如果转发操作是在TCP连接中决定的(如收到数据发送后的新确认消息或收到作为发送确认响应的新数据),那么就可以验证邻居是可达的。如果转发操作是端到端决定的(也是由下一跳路由器决定的),那么就可以证实路由器的可达性。
某些上层协议并不提供类似的提示信息(如UDP通信),如果无法从上层协议收到相应的验证信息,那么节点会主动探查邻居以确定其可达性状态。节点会向已缓存的邻居链路层地址发送NS消息并等待NA消息,节点接收到NS消息之后会发送一条将S bit置位的NA消息。如果节点接收到一条S bit被置位的NA消息,那么就可以确认其邻居已经接收到其所发送的NS消息,因而表明转发方向上的通信正常。这些探查消息是随流量一起发送的,如果没有要发送给对端节点的流量,就不会向该节点发送探查消息。
邻居缓存中存储了邻居的相关信息,包括IP地址、链路层地址和可达性状态。表8-9列出了各种可能的可达性状态。

邻居缓存中的表项最初状态为INCOMPLETE,在学习到该表项的链路层地址之后,就验证了转发方向的通信。该表项的状态也将更改为REACHABLE,只要转发方向通信一直被验证,该表项的状态就一直处于REACHABLE状态。
如果没有从REACHABLE邻居接收到可达性信息,那么其状态将被更改为STALE。从某个节点接收到主动RA或NA消息之后,会在邻居缓存中加入一条INCOMPLETE表项,而该表项的状态会立即转变为STALE。请注意,主动宣告并不会提供任何有关转发通信的信息,在将流量发送给邻居之前,其表项将始终处于STALE状态。
一旦将数据包发送给了邻居,其状态就会更改为DELAY,并在邻居缓存中为该表项设置一个5秒定时器。该数据包将会被发送给已缓存的链路层地址(即使其状态为STALE),如果在接收到任何可达性验证之前定时器超时了,那么表项的状态将更改为PROBE;如果证实了邻居的可达性,那么该表项的状态将被更改为REACHABLE。
进入PEOBE状态之后,会向已缓存的邻居的链路层地址发送一条NS消息,如果没有收到响应消息,那么每秒钟都会发送请求消息(即便没有发送其他数据包)。如果在发送了3条请求消息之后的1秒钟内仍未收到响应消息,那么就会从该邻居缓存中删除该表项。
例8-3显示了命令debug ipv6 icmp和debug ipv6 nd的输出结果,以及状态从 INCOMPLETE变更为REACHABLE(经历了所有中间状态)的路由器邻居缓存。此外,例 8-3还显示了命令show ipv6 neighbor的输出结果(该命令的作用是显示邻居缓存),命令show ipv6 neighbor的输出结果中提供了IPv6地址、寿命(Age)、链路层地址(如果知道的话)、状态以及接口(通过该接口了解到邻居)等信息。
例8-3:命令debug的输出结果显示了邻居可达性状态的变更过程。
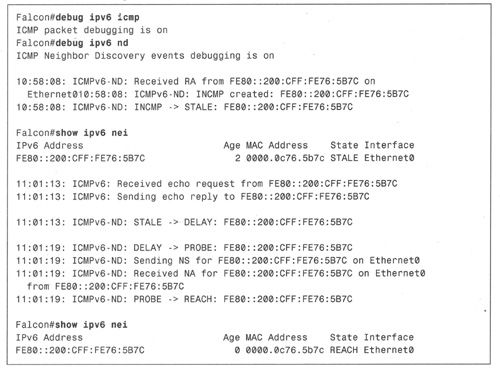
路由器Falcon从Eagle的链路本地地址FE80::200: CFF: FE76: 5B7C接收了一条RA消息,之后Falcon的邻居缓存中就创建了一条INCOMPLETE表项,该表项的状态将立即转换为 STALE(因为 RA 是主动消息),此时对邻居缓存进行查询,可以发现该地址的状态确实为 STALE。Eagle的链路层地址是已知的。
几分钟之后,Eagle向Falcon发送了ping(如接收到的回应请求所示), Falcon通过向已存储的链路层地址发送回应响应来应答Eagle,但是由于数据包被路由器发送给了STALE表项,因而该路由器必须将状态更改为DEALY,以查看其是否能验证转发方向的通信路径。由于该路由器无法通过ICMP包来加以验证,因而将状态更改为PROBE并发送NS消息,以便通过探查Eagle来确定是否能得到可达性验证,Eagle会回应NA消息,debug命令并没有显示NA消息中的S bit被置位。在接收到NA消息并验证了通信路径之后,Falcon会将Eagle的表项状态更改为REACHABLE。
利用邻居不可达检测进程,可以让主机在默认路由器失效的情况下将流量重定向到其他可选路由器,主机在检测到默认路由器故障后会选择另一台路由器来转发流量,这一切都可以在上层协议或上层应用超时之前完成。而IPv4主机则可能从来都不会检测到默认路由器出现故障,在路由器出现故障的情况下,上层协议或上层应用则将会超时。IPv4主机很可能会试图使用该停用路由器来重建连接,这是因为某些IPv4主机可能会知道多台默认路由器,从而可以利用第二台路由器来重建该连接。
9.默认路由器选择
当目的地位于链路之外并且主机中没有关于该目的地的缓存表项或现有默认路由器看起来似乎已失效时,主机都会从其默认路由器列表中选择一台路由器(可能从很多台路由器中选择)。通常在第一次向某特定目的地发送流量时需要选择一台默认路由器,主机将缓存该信息并用于随后的流量。
默认路由器选择进程使用默认路由器列表和邻居缓存,任何非不可达路由器(也就是说,这些路由器不处于INCOMPLETE状态)在成为默认路由器时都拥有相应的优先级。如果有多台路由器都处于INCOMPLETE之外的其他状态,那么默认路由器选择进程将得到同样的路由器或以循环方式从默认路由器列表中得到路由器(这与实现方式有关)。
如果下一跳路由器看起来似乎已失效,邻居不可达检测进程将会加以检测;如果该路由器确实已失效,那么将会从邻居缓存中删除该路由器表项,接着再次执行下一跳检测和地址解析操作,并使用其他可用的下一跳路由器。
案例研究:默认路由器失效和通信恢复,如下所示。
某主机利用FTP从远程服务器传送一个文件,该主机向其在链默认路由器发送流量,由于该主机能够连续接收到所发送数据的ACK消息,因而主机确认其默认路由器可达。但是在会话中间该默认路由器出现了故障,那么该主机将无法接收到ACK,也就无法再从来自TCP层的提示信息中验证转发方向通信了,因而将该路由器的状态更改为STALE。由于此时仍在试图发送数据包,因而状态被接着更改为DELAY,但5秒钟之后该主机仍未接收到有关该路由器可达性状态的肯定证实消息,因而又将该路由器的状态更改为 PROBE并发送NS消息,由于该路由器无法做出响应,因而该主机将从邻居缓存中删除该路由器。
此时的主机仍在试图发送数据包,但由于没有去往目的地的下一跳表项,因而该主机将查看目的地前缀,了解到该目的地位于链路之外,接着从其已存储的默认路由器列表中选择一台默认路由器,并将该路由器(状态为INCOMPLETE)放在其邻居缓存中。如果不存在该表项,那么就需要通过发送NS消息来解析其链路层地址。当接收到该新路由器响应的NA消息之后,就可以证实该路由器的可达性,接下来就可以通过这台新路由器来转发流量了。
10.重复地址检测
所有节点在给接口分配单播地址时都要执行重复地址检测进程,但不需要对任播地址执行该操作。需要注意的是,无论该地址是通过无状态配置、状态化配置还是手工配置的,都要执行重复地址检测操作,需要在将地址分配给接口之前以及接口初始化时进行该操作。在执行重复地址检测进程的过程中,将所要分配给接口的地址称为“不确定地址”。
在发送请求消息之前,该接口会加入所有节点多播组,以确保该节点能够从任何正在使用该地址的节点接è到NA消息,并加入关于该不确定地址的请求节点多播组,以确保是否有其他节点正在使用该地址,这两个节点都将知道对方的存在。
节点向外发送NS消息,将不确定地址作为目标地址。源地址是未指定地址,目的地址是该不确定地址的请求节点多播地址,默认情况下只发送一条请求消息。
任何已分配了该地址的邻居在接收到请求消息之后,都会发送一条NA消息作为应答,宣告消息中的目标地址就是该不确定地址,目的地址是该不确定地址的请求节点地址。如果节点接收到该NA消息,且目标地址是该接口的不确定地址,那么就表明该地址是重复地址,不能分配给该接口。某些IPv4主机在将IP地址分配给接口之前也会执行重复地址检测进程,但并不是所有的IPv4主机都会执行该进程,因而存在接口使用重复地址的可能性,从而对现有流量流造成破坏。
8.4.4 自动配置
由于网络的可管理性是网络成功的关键因素,因而IPv6协议必须内嵌相应的进程机制。如果网络中的主机采取静态配置方式(以手工方式输入),那么在发生变更时将难以管理。虽然IPv4网络中有许多简化管理工作的工具(如DHCP可以大大简化静态配置的工作量),但这一切并不是IPv4协议的必需组件。而IPv6节点则可以对自己进行自动配置(有无DHCP服务器均可),从而使得主机配置变更操作变得非常简单。
RA消息被用来告诉主机如何配置自己。RA消息中包含了两个bit,其作用是告诉主机是否使用配置服务器的bit,如果需要使用配置服务器,则告诉主机是否从该配置服务器获取除地址之外的其他信息。如果M bit(Managed Address Configuration,被管地址配置)被置位,那么主机将使用状态化地址配置协议(如DHCP)来配置其地址,其实主机也可以进行无状态的地址自动配置。O bit(Other Stateful Configuration,其他状态配置)的作用是让主机使用状态化配置协议来配置除地址之外的其他信息。与此相对,在IPv4中,若要自动获取IP地址和其他配置信息,就需要静态配置IPv4主机使用指定DHCP服务器,否则就需要全部采取手工方式输入配置信息。
1.无状态自动配置
只要知道了节点所了解的信息(其接口标识符)以及路由器所了解的信息(分配给链路的前缀),该节点就可以配置其IP地址,而无需服务器来建立基本的IP连接性,这对所有支持多播的接口上都是可行的。
接口初始化之后,节点就会立即为该接口生成一个链路本地地址。该链路本地地址就是级联了周知链路本地前缀FE80: :的接口标识符,以接口ID来代替链路本地地址最右边的0即可构成128bit地址。请注意,接口ID通常为64bit(但并不始终如此)。
链路本地地址FE80: 0: 0: 0: 200: CFF: FE0A. 2C51的链路本地前缀和接口ID分别为 FE80:0:0:0:0:0:0:0和200:CFF:FE0A.2C51。
如果接口ID的长度超过了118bit,那么将无法附加链路本地FP(其长度为10bit),也就无法进行自动配置,此时就需要进行手工配置。
节点并不会立即将所生成的链路本地地址分配给接口,而是首先确定是否存在重复地址,即发起重复地址检测进程。
如果节点发现其所生成的地址并不是惟一的,那么就必须进行手工配置。一种配置方式是为该节点配置一个替代接口ID,此时该节点仍然可以参与到无状态自动配置进程中,并自动配置其所需的每个地址以及任何已分配的单播和多播地址。另一种可选的接口ID配置方式就是在接口上手工配置IPv6地址,但这种方式将会带来大量的管理性工作量。
如果该节点没有发现重复地址,那么就会将该地址分配给该接口。
此时就建立了基本的IP连接性,同一条链路(无路由器)上的IPv6主机之间就可以进行相互通信了。如果只需要进行这种通信,那么就不需要在主机上手工配置网络层信息。
例8-4给出了Falcon和Eagle的最小基本配置。
例8-4:Falcon和Eagle进行IPv6通信的最小基本配置。
从Eagle向Falcon的链路本地地址进行ping操作,可以看出,可以进行通信(如例8-5输出结果所示)。
例8-5:通过Falcon的链路本地地址来验证Falcon与Eagle之间的通信。

为了启用基本的IP连接性,路由器和主机都要执行前面所讨论的无状态自动配置进程中的所有步骤,每个接口都必须创建一个链路本地地址。除了下面各段将要讨论的例外情况之外,在将单播地址分配给每个接口之前都要进行重复地址检测操作(而不论该IPv6地址是通过无状态自动配置、状态化自动配置或是手工配置)。
主机(不是路由器)继续自动配置进程。主机发送一条“所有路由器”多播请求以发现链路上的路由器,所有路由器都会响应以 RA 消息。RA 消息可能告诉主机使用状态化自动配置来配置地址和其他信息,主机使用被标记为地址配置的前缀信息来创建站点本地地址,为了创建一个站点本地地址,需要将站点本地FP、前缀和接口ID级联在一起。主机在分配其站点本地地址时无需执行重复地址检测进程,其理论基础是该进程只是被用来验证链路本地地址的惟一性,这就意味着对链路来说,接口标识符是惟一的。由于站点本地地址为相同的接口标识符分配了不同的前缀,因而站点本地地址也是惟一的。利用同样的方法也可以生成和分配全局可聚合地址。
RA 消息还提供了在链前缀信息,该信息是一个前缀及前缀长度列表(被标记为在链前缀),主机利用该信息来构造其前缀列表。主机使用前缀列表来确定目的节点是在链节点还是离链节点,进而确定是否需要使用默认路由器来发送流量。
需要采取状态化自动配置方式来配置其他信息(如DNS服务器)。
利用下列接口子命令可以配置路由器宣告携带指定值的前缀、设置被管配置标记(managed-confíg-flag)以及其他配置标记(other-config-flag)。
ipv6 nd prefix-advertisement 2001: ABAB: : /48 3000 3000 onlink autoconfig
ipv6 nd managed-config-flag
ipv6 nd other-config-flag
可以看出,被宣告前缀2001: ABAB: : /48携带的有效生存期为3 000秒,优选生存期为3 000秒(被用作在链宣告和自动配置)。
节点上的每个接口都要执行自动配置进程(无论在什么时候启用接口),多归属节点会在每个接口上独立执行自动配置进程。在下列情形下将会启用接口。
• 系统启动时的接口初始化;
• 接口失效或被系统管理员临时禁用后又被重新启用;
• 接口第一次连接到链路上;
• 接口被管理性关闭之后又被启用。
2.状态化自动配置
状态化自动配置可以与无状态自动配置联合使用。DHCP为IPv4提供了状态化自动配置,用于IPv6的改进型DHCP可以充分利用IPv6的各种功能特性,从而大大增强了DHCP的能力。
注意: 动态主机配置(Dynamic Host Configuration)工作组已经发布了题为“draft-ietf- dhc-dhcpv6-15.tx”的用于IPv6的DHCP草案。
配置服务器可以向请求主机分配地址和其他信息(如DNS服务器地址)。与用于无状态自动配置的前缀一样,这些地址也都有相关联的有效生存期和优选生存期,如果服务器能够要求所有主机重新验证分配给它们的地址,那么就可以利用生存期值对网络进行重新编号。
3.重新编号
虽然IPv6的地址数量极其丰富,但站点重新编号也是在所难免的。虽然可以严格维护地址前缀,但是可能需要偶尔召回分配给某个站点的地址,或者某站点希望更换ISP,而该ISP要求更该前缀,这一点与目前IPv4网络中用户更换ISP—样。不过,IPv6虽然并不能消除该现象,但却可以让重新编号工作变得相当简单。
地址的状态有优选(preferred)状态和贬抑(deprecated)状态。主机总是试图使用优选地址来进行通信,只是当使用优选地址会破坏现有连接时才将贬抑地址作为源地址。例如,如果两台主机使用优选地址建立了TCP连接,并且其中的某台主机的地址变成了贬抑地址,如果该主机切换到一个新的优选地址,那么该连接将失效。
通过使用优选地址和贬抑地址可以大大简化主机重新编号工作。可以在RA消息中设置和修改地址保持优选状态的时间,该消息会周期性地在链路上发送,而且链路上的每个节点都会处理该消息,因而只要将新前缀添加到RA消息中,就可以为接口增加新地址,并将原先的地址变为贬抑状态并予以删除。同样,也可以利用配置服务器来对主机进行重新编号,配置服务器可以向所有节点多播一条请求,要求大家重新确认分配给它们的地址,主机将查询配置服务器并获取生存期已更改的地址,贬抑现有地址或重新分配新的优选地址。这种重新编号机制的健壮性依赖于到达链路上所有主机的RA消息和状态消息。下面看一下RFC 2641中给出的案例研究。
案例研究:对网络进行重新编号,如下所示。
假设宣告了一个生存期为2个月的前缀,8月1日决定更改该前缀,并且从9月1日起不再使用该前缀。可以更改前缀宣告以使其生存期为2周,随着日期不断接近9月1日而不断减小生存期,直至将该前缀的生存期宣告为0,从而使得该地址无效。但是,如果某主机在7月31日与网络断开连接,在9月1日又重新接入网络,那么该主机将认为旧前缀在9月30日之前仍是有效前缀。强制主机不再使用之前宣告的生存期很长的前缀的惟一方法就是发送一条生存期较短的RA消息,因而要求路由器在10月1日之前持续发送生存期值为0的 RA消息,以确保在变更地址之前与网络断开连接,在2个月生存期到期之前又重新连接到网络上的主机使用无效前缀。
通常来说,路由器应该持续发送生存期值为0的RA消息,发送时间周期应该是确保任何主机在断开连接之后再次连接到网络上时不会使用旧前缀。请注意,如果路由器将前缀的生存期宣告为无穷大,那么在对链路进行重新编号以及主机频繁地建立/断开与网络的连接时将会出现问题。
若要保持通信不中断,就需要做大量的规划工作才能对路由器进行重新编号。路由器之间需要相互通信,主机也要通过路由器的链路本地地址与路由器进行通信,该通信与任何所分配的前缀都无关,因而无论分配给该链路的全局地址是什么,节点都能继续与路由器的链路本地地址进行通信。
对DNS来说,IPv6与IPv4下的重新编号工作都是一样的,要么在新地址可用之前利用手工方式将新地址输入到DNS数据库中,要么就实现DDNS(dynamically updated DNS,动态更新的DNS)服务器。
8.4.5 路由
前面的章节讨论了IPv6节点如何发现将数据包转发给邻居和下一跳路由器(如果目的地不在链路上)所需的信息,本小节将讨论IPv6的路由问题,以说明如何在大型网络中路由IPv6包。
1.MTU路径发现
IPv6网络要求每条链路上的MTU最小为1 280字节,但建议大小为1 500字节或更大,任何无法处理这样大小的数据包的链路都必须提供链路级的分段功能。只有源节点才执行IP级的分段操作,数据包传送路径上的路由器则不执行IP级的分段操作。虽然并不强制要求所有节点都实现MTU路径发现机制,但建议如此。没有实现MTU路径发现机制的节点所能使用的MTU等于最小IPv6 MTU,即1280字节,而实现了MTU路径发现机制的源节点则可以使用最大可能的数据包,从而可能获得更高的性能。路径发现可以用于单播目的地和多播目的地。
MTU路径发现机制使用ICMP Packet Too Big(ICMP包过大)差错消息。发送流量的节点初始假定PMTU(path MTU,路径MTU)等于其所连接链路的MTU,数据包分发路径上的任何节点如果检测到其无法按照该MTU发送数据包,则发送一条包含了其链路MTU大小的ICMP Packet Too Big差错消息,并丢弃该超大数据包,接收到该差错消息的源节点会将所要发送的数据包大小减小为该差错消息中所包含的MTU值。该进程会一直持续下去,直至整个分发路径上的所有节点都协商一致。图8-14给出了PMTU的发现过程。
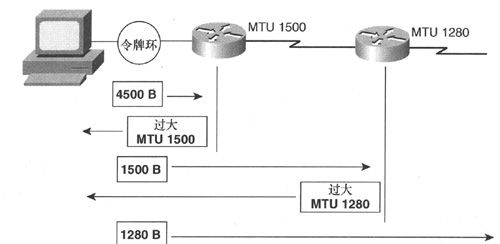
图8-14 PMTU发现进程
如图8-14所示,连接在令牌环上的PC开始发送的数据包大小为4 500字节,当数据包到达位于分发路径上的某台路由器(其链路MTU为1 500字节)时,该路由器将会发送ICMP Packet Too Big差错消息(包含其MTU值1500字节),并丢弃该数据包;之后,该PC创建更小的数据包(大小为1 500字节),第一台路由器会予以通行,但去往分发路径的下一台路由器的链路MTU值为1280字节,那么该路由器将发送一条ICMP Packet Too Big差错消息(包含其MTU值1280字节),并丢弃该数据包;之后,该主机将进一步减小数据包的大小(为 1280字节),从而可以确保该数据包能穿越这两台路由器。
与单播目的地址一样,MTU路径发现机制也可以用于多播目的地址。多播包会同时进入多条路径,这些路径上的所有节点都可以发送ICMP Packet Too Big差错消息,PMTU的最小值将决定源节点所发送的数据包大小。
2.RIPng
RIPng(其中的ng表示“next generation”,即“下一代”)基于RIP-2,它没有改变RIP-2的任何可操作进程、定时器或稳定功能,而只是对RIP-2做了一定的修改,以支持更多的IP地址以及每个IPv6接口的多地址功能。用于RIPng的UDP端口号为521, RIPng不能同时支持IPv4和IPv6,因而不与RIP-2后向兼容。
注意: 有关RIP-2的详细信息请参见《TCP/IP路由技术(第一卷)》第7章。
图8-15给出了RIPng的消息格式,其基本结构与RIP-2非常相似。
RIPng消息的字段定义如下(长度单位为字节)。
• 命令(Command):该字段要么为1(表示请求),要么为2(表示响应)。
• 版本(Version):该字段目前为1。
RIPng消息的其余部分是RTE(Route Table Entry,路由表项)列表,图8-16给出了RTE的格式。
RTE格式中的各字段定义如下。
• IPv6前缀(IPv6 Prefix): 128bit IPv6地址前缀。
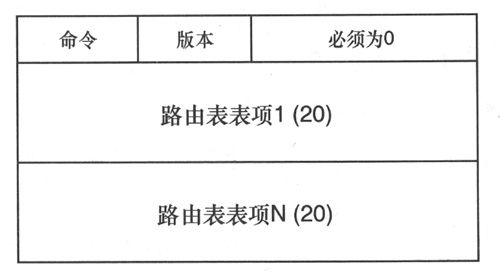
图8-15 RIPng消息格式
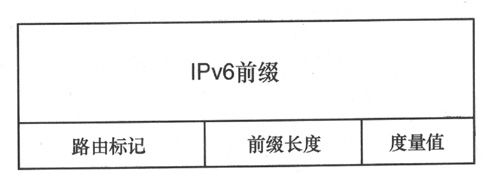
图8-16 RIPng的路由表项格式
• 路由标记(Route Tag):与RIP-2相同,用于标记外部路由或者被重分发到RIPng进程中的路由。
• 前缀长度(Prefix Length):指定地址前缀的有效部分。
• 度量值(Metric):与RIP-2相同,是1~15(含1和15)的跳数值。
一条RIPng更新消息所能包含的路由数与链路MTU、RIPng消息之前的头部信息8位组数、RIPng头部大小以及每个RTE的大小都相关。每条更新消息中所能包含的RTE数的计算公式如下。
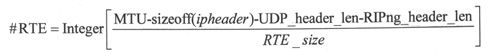
RTE的数量与链路MTU及IP头部长度、UDP头部长度和RIPng头部的长度都直接相关。
每个RIP-2 RTE都包含一个与其相关的下一跳(Next-Hop)字段,用于指定更优下一跳地址(与路由器所宣告的地址相比)。由于IPv6的地址过大,几乎是RTE的2倍,因而RIPng只指定了单个下一跳RTE(应用于随后的所有 RTE,直至消息结束或遇到另一个下一跳RTE)。图8-17显示的下一跳RTE表明路由标记字段和前缀字段必须为全0,度量值为OxFF,地址字段值 0:0:0:0: 0: 0: 0: 0表示下一跳是RIPng宣告的发起路由器。

图8-17 下一跳RTE
下一跳地址必须是下一跳路由器的链路本地地址,如果该地址不是链路本地地址,那么宣告消息的接收方将会认为该数据包的地址前缀值为0:0:0:0:0:0:0:0。
无论是周期性的RIPng响应,还是被触发的RIPng响应,都必须保持在链路本地——即不能穿越路由器。周期性更新和触发性更新都必须将路由器的链路本地地址作为宣告的源地址,并且IPv6的跳数限制值等于255,跳数限制值为255可以确保该宣告消息没有穿越路由器(因为路由器会递减每个数据包的跳数限制值)。目的多播地址则为all-rip-routers(所有 RIP路由器)多播地址FF02::9。
Cisco路由器能够运行多个RIPng进程,需要在接口子命令下启用路由进程,如下所示。
ipv6 rip tag enable
任何接口如果希望在RIPng更新消息中宣告前缀,就必须在接口上启用该命令。多个进程之间通过标记来加以区分,目前最多支持4个进程,每个进程都必须使用一个惟一的UDP端口号,如果是单一进程,则可以使用默认端口号521,必须修改后续进程的端口号,否则新进程将无法启动。RIPng用来修改UDP端口号和多播地址的全局命令如下。
ipv6 rip tagport udp-portmulticast-group multicast-address
多个进程可以共用同一个多播地址,如果没有启用该命令,则使用默认端口号521和默认多播地址FF02::9。
与RIP-2不同(RIP-2要求使用全局命令router rip来启用路由协议),无需使用全局命令来启用RIPng。
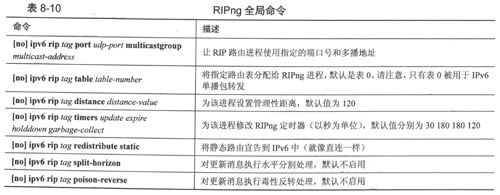
可选的全局命令可以控制整个RIPng进程并影响所有已配置接口,可以利用全局命令禁用或启用水平分割和毒性反转机制,修改UDP端口号和RIPng多播地址,更改默认定时器和管理性距离,重分发静态路由等等。RIP-2也可以提供其中的绝大多数功能。
表8-10列出了各种可用的RIPng全局命令。
RIPng中还有一些可用的接口子命令,这些接口子命令可以让更新消息通过指定接口向外宣告默认路由,汇总接口向外宣告的路由,对接口上接收到的更新消息或者从接口向外发送的更新消息应用输入和输出过滤器,以及更改接口上接收到的路由的度量值偏移(metric- offset)。这些功能在RIP-2中也都有,表8-11列出了这些接口子命令。
下面通过一个简单的网络图和路由器配置来帮助读者掌握路由器运行RIPng所需的最少配置(如图8-18所示)。
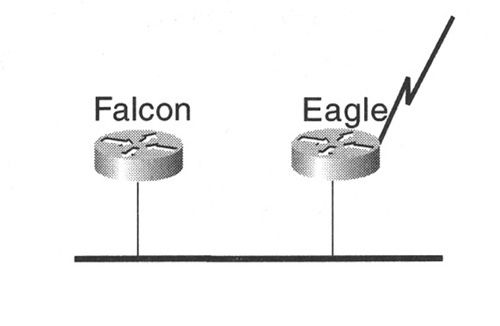
图8-18 一个简单的RIPng网络
图8-18中所示的两台路由器上都配置了RIPng(在以太网链路和串行链路上),例8-6给出了路由器的配置情况。
例8-6:在路由器Falcon和Eagle上配置RIPng。
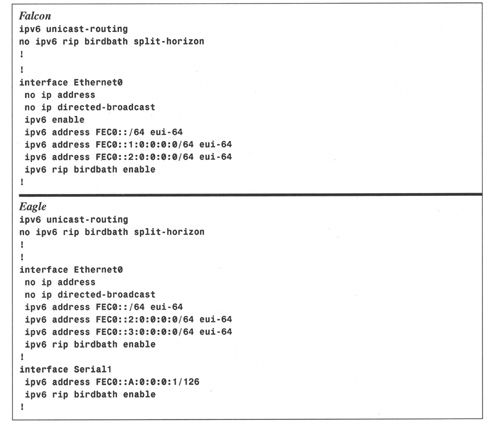
这两台路由器共享两个相同的前缀FEC0: : /64和FEC0: : 2: 0: 0: 0: 0/64,每台路由器都配置了第3个前缀。为了让这两台路由器向对方宣告非公共前缀,需要禁用水平分割,在以太网接口和Eagle的串行接口上启用RIPng。进程名为birdbath。
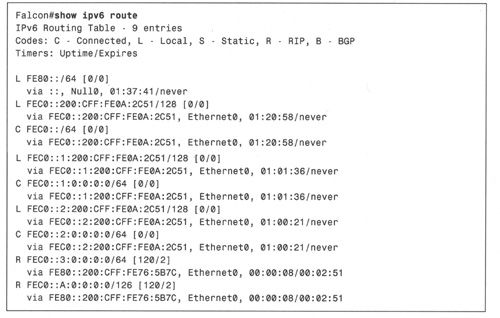
例8-7显示了Falcon的路由器情况。
从例8-7中的路由表可以看出,连接了配置在Falcon的以太网端口上的前缀,并且通过 RIPng进程学习到Eagle的以太网前缀FEC0::3:0:0:0:0/64和串口前缀FEC0::A:0:0:0:0/126。
RIPng仍然是一个非常容易实现的路由协议,引入多进程的目的是在RIP-2的基础上增加一定的灵活性,但是其缺点仍然存在(如《TCP/IP路由技术(第一卷)》第7章所述)。例如,该协议的最大跳数限制值仍然很小,从而限制了运行该协议的网络的规模。
3.IPv6 0SPF
为了支持更大的IPv6地址,需要对OSPFv2做出很多修改,并在IPv4与IPv6之间修改相应的协议语义。Cisco IOS目前不支持用于IPv6的OSPF。OSPF中的基本机制,如泛洪、 DR选举、支持域的划分、SPF等都没有变化,IPv6 OSPFv直接运行于IPv6之上,前一个头部的下一报头值为89。以下OSPF功能在IPv6中未做任何改动。
虽然IPv6 OSPF修改了Hello包,但这两种版本的OSPF协议都支持相同的数据包类型,即Hello包、数据库描述包、链路状态请求包、链路状态更新包和链路状态确认包。
• 通过交换Hello包来发现邻居信息;
• 邻接性选择和建立机制;
• 接口状态机,包括接口所经历的状态以及指派路由器选举进程;
• 邻居状态机,包括在成为邻接关系之前邻居所经历的状态;
• 链路状态数据库老化机制。
注意: 有关OSPFv2的详细描述请参见《TCP/IP路由技术(第一卷)》第9章。
某些OSPF机制发生了变化,原因是希望让OSPF与网络协议无关(因而更具扩展性),如新的地址格式、显式指定泛洪区域、接口支持多个地址和多个前缀等。OSPF协议已成为与网络协议无关的协议,其协议版本号也从2变为3,所以本章后续内容将称IPv6下的OSPF为OSPFv3。本小节将详细讨论该协议的变动情况。
(1)是链路而不是子网。
IPv6节点通过链路进行通信,而不是子网。每个IPv6节点都可以为连接到链路上的接口配置多个地址和前缀,并且能与链路上的其他节点进行通信,而与所使用的子网无关。OSPFv3关注的是链路,这一点与OSPFv2中关注的是子网不同,此时不再要求发送OSPF包的路由器接口与接收该数据包的路由器接口位于同一个子网中。这是因为,IPv6 OSPF的运行基础是链路,而不是子网。
(2)删除了寻址语义。
OSPFv3删除了OSPFv2包和LSA中的寻址语义,因而在OSPFv3创建了一个与网络协议无关的核心,为将来的多播OSPF提供了基础。许多OSPFv2包和LSA都包含了IPv4地址,表示路由器ID、域ID或LSA链路状态ID,但是由于OSPFv3中的路由器ID、域ID和 LSA链路状态ID仍然用32bit数字来表示,因而无法再用IP地址来表示(虽然可以用IP地址的一部分来表示)。OSPFv2广播和NBMA网络利用IP地址来列举邻居,OSPFv3的邻居仅以路由器ID来标识。其他OSPFv2 LSA(如路由器LSA[Router-LSA]和网络 LSA[Network-LSA])都包含了IP地址,这些IP地址在链路状态数据库中被用来表示网络拓扑结构,而OSPFv3的路由器LSA和网络LSA仅表示拓扑信息,按照与网络协议无关的方式来描述网络拓扑结构。IPv6利用接口ID来标识链路,而不再使用IP地址来标识链路,路由器上的每个接口都被分配一个惟一的接口ID,某些协议实现可能利用MIB-II iflndex值。邻居和指派路由器都以路由器ID加以标识,也不再使用IP地址来表示。只有在链路状态更新包所携带的LSA净荷中才包含IPv6地址。
(3)LSA泛洪作用域和未知LSA类型。
LSA包的泛洪作用域已经很普遍化,LSA类型决定了OSPFv2的泛洪作用域,每种LSA类型都与其泛洪作用域相关联。对OSPFv3来说,需要在LSA头部中显式配置泛洪作用域,无法识别LSA类型的OSPFv3路由器仍然知道如何泛洪该数据包,泛洪作用域可以是链路本地、区域(Area)或AS。OSPFv3允许路由器具有不同的能力,路由器接收到未知类型的LSA包时也不再要求丢弃该数据包。泛洪作用域、未知LSA类型的处理方式以及LSA类型都被编码在头部中的扩展LSA类型字段,最上面的3bit用来编码泛洪作用域和未知LSA类型的处理方式,由处理bit告知路由器要么泛洪未知LSA(泛洪作用域为链路本地),要么像已知 LSA类型那样存储并泛洪该未知LSA,因为有了已编码的泛洪作用域,所以路由器可以按照后面的方式进行处理。表8-12和表8-13分别显示了泛洪作用域值以及与未知LSA处理方式相关的值。


将泛洪作用域进行显式编码,可以将新的OSPF功能特性集成到现有网络中。
(4)每链路多OSPF实例。
单条链路上可以同时运行多个OSPFv3实例,这在多个区域需要共享同一条链路时非常有用(如图8-19所示)。OSPFv3包头中的实例ID(instance ID)即可实现该功能。
如图8-19所示,Area 1和Area 2各有4台路由器,Area 1中的2台远程路由器的主用链路连接到路由器A,备用链路连接到路由器B, Area 2中的2台远程路由器的主用链路连接到路由器B,备用链路连接到路由器A, Area 1和Area 2都必须经同一条以太网链路在路由器A和B之间运行。上述要求在OSPFv3中完全可以实现,但是在OSPFv2中则无法实现。
还有另一种应用场景,多个运行OSPF的公司或同一家公司的多个运行OSPF的独立分支机构需要共享同一条链路,并需要使用该链路进行相互通信。该链路可能属于某一家公司,该公司利用该链路连接到所有独立的组织机构。部分公司可能希望建立对等关系,而不与其他公司建立对等关系。一种更为常见的实践方法是使用BGP来互连这些独立的组织机构,但是,如果某组织机构拥有OSPF专家但没有BGP专家,那么很有可能希望使用OSPF作为互连协议,图8-20解释了该应用场景。
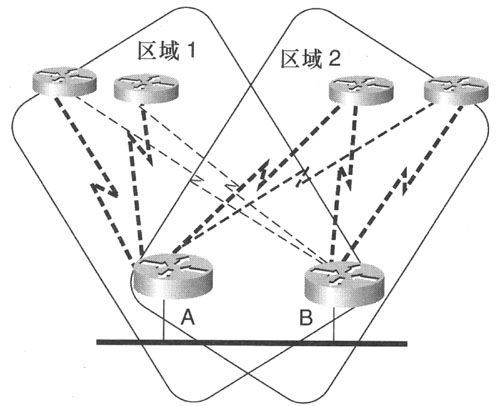
图8-19 两台路由器共享同一条链路,两个区域需要运行在同一条链路上。每链路多OSPF协议进程机制可以实现该要求
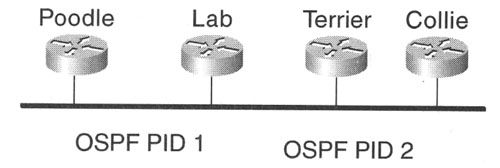
图8-20 OSPF路由器共享同一条链路,部分路由器共享同一个OSPF进程
如图8-20所示,路由器Poodle和Label为对等体,且共享同一个OSPFv3进程,路由器 Lab、Terrier和Collie也是对等体,且共享一个不同的OSPFv3进程,Lab的链路被配置了两个OSPFv3进程标识符。
(5)OSPF对链路本地地址的使用。
由于每条有效的IPv6链路都配置了链路本地地址,因而OSPFv3将这些链路本地地址用作协议包的源地址以及链路LSA(Link-LSA)的内容(将在下面的“新LSA和LSA变化”中描述)。根据定义,链路本地地址都共享相同的IPv6前缀(FE80: : /64),因而OSPFv3节点之间可以很容易地进行相互通信并构建邻接关系(而不管分配给这些节点的地址前缀是站点本地地址还是全局可聚合地址)。将链路本地地址用于LSA中来标识路由器上的链路,就不再需要将链路与某个特定的IP地址相关联,从而使得拓扑信息与所使用的网络协议无关。
(6)取消认证。
IPv6中的OSPF取消了认证机制,这是因为IPv6已经将完整性、真实性和机密性机制内嵌于该协议的网络层,而OSPFv3则直接运行于该层之上。从头部中取消了认证信息之后,可以提高OSPFv3的效率,不需要路由安全性的网络就无需处理这些头部,而那些需要路由安全性的网络则可以使用IP层的认证和安全加密净荷扩展头。
(7)新LSA和LSA变化。
虽然OSPF中的大部分功能都没有做任何变化,但仍然修改了某些OSPFv2 LSA字段,并且在OSPFv3中重新命名了这些LSA,而且还在OSPF中增加了某些新的LSA以携带IPv6地址和下一跳信息。
OSPFv2 LSA头部中包含了以下字段:寿命(Age)、选项(Options)、类型(Type)、链路状态ID(Link State ID)、宣告路由器(Advertising Router)、序列号(Sequence Number)、校验和(Checksum)和长度(Length)。OSPFv3 LSA将选项字段从8bit扩展到了24bit,并从头部移至路由器LSA(Router-LSA)、网络LSA(Network-LSA)、区域间路由器LSA(Inter-Area-Router-LSA)和链路LSA(Link-LSA)的消息体中。类型字段被扩展到16bit,并用空格来代替原先被选项字段占用的位置,其余头部字段则保持不变。
LSA类型字段包括未知类型处理方式、泛洪作用域和LSA类型bit,图8-21显示了LSA类型字段的结构。
其中的U bit指示未知LSA类型的处理方式,S2和S1则用来指示泛洪作用域。

图8-21 OSPFv3 LSA类型字段
对未知LSA类型的处理方式做了调整,IPv4 OSPF直接丢弃未知LSA类型数据包,由于 OSPFv3希望在同一条链路上允许不同能力的路由器共存,因而不希望丢弃未知LSA类型数据包。如果指派路由器比链路上的其他路由器支持更少的选项,那么将无法获得全部功能。
表8-14列出了每种LSA的链路类型值
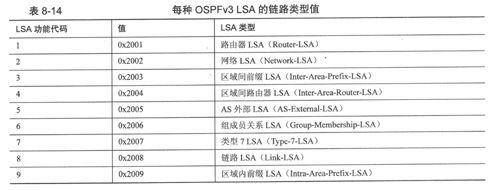
从表8-14可以看出,两个OSPFv2汇总LSA被重新命名了,并且增加了两个新的LSA:链路LSA和区域内前缀LSA。此外,还可以看到每种LSA类型的泛洪作用域和处理方式。所有列出的类型的U bit都被设置为0,表示如果LSA类型对任何接收路由器来说是未知的,那么应该按照泛洪作用域为链路本地的方式来处理该LSA,如果路由器无法识别该LSA类型,那么将根据S2和S1 bit来泛洪该LSA。例如,路由器LSA类型0x2001的S2S1值为01(二进制),则表示将该LSA泛洪到区域中的所有路由器,AS外部LSA的S2S1值为10(二进制),则表示将该LSA泛洪到AS中的所有路由器。
OSPFv2中的类型3网络汇总LSA(type-3 Network Summary-LSA)被重新命名为区域间前缀LSA,请记住,这些LSA被区域边界路由器(Area Border Router)用来宣告区域外的网络。
OSPFv2中的类型4ASBR汇总LSA(type-4 ASBR Summary-LSA)被重新命名为区域间路由器LSA,这些LSA由AS边界路由器负责宣告,并宣告区域外的ASBR。
OSPFv3将LSA选项字段从8bit扩展到24bit,该字段位于Hello包、数据库描述包和某些LSA(路由器LSA、网络LSA、区域间路由器LSA、链路LSA)中。选项字段的作用是让路由器相互说明其所支持(或不支持)的选项能力,允许混合能力的路由器共存于同一个 OSPF路由域中。当路由器不支持同样能力的时候如何处理完全取决于选项。
目前已经定义了选项字段中的以下6个bit。
• V6:如果该bit被清除,那么该路由器将参与拓扑结构分发,但不用来转发转接(transit)IPv6包。
• E:与OSPFv2中一样,当发信路由器能够接受AS外部LSA时置位该bit,末梢区域中发起的所有LSA的E都等于0。该bit也用于Hello包中,用来指示该接口发送和接收AS外部LSA的能力。E bit不匹配的邻居路由器之间无法建立邻接关系,以确保同一个区域中的所有路由器都支持同等的末梢(stub)能力。
• MC:当发信路由器能够转发IP多播包时就置位该bit, MOSPF使用该bit。
• N:仅用于Hello包,N bit被置位表示发信路由器支持NSSA外部LSA(NSSA External LSA)o如果N=0,表示发信路由器不发送或接收这些NSAA外部LSA。N bit不匹配的邻居路由器之间无法建立邻接关系,以确保同一个区域中的所有路由器都支持同等的NSSA能力。如果N=1,那么E必须等于0。
• R:R(路由器)bit被置位表示该路由器有效,如果R bit被清零,那么OSPF发言者就可以参与到拓扑分发中,而不用转发转接流量。这一点可以用于多归属节点希望参与路由选择而不希望充当路由器(即在其接口之间转发流量)的应用场合。如果R bit被置位,但V6 bit被清零,那么该节点将不转发IPv6数据报,但仍然转发属于其他协议的数据报。
• DC:当发信路由器在需求电路上支持OSPF时就置位该bit。
对比上述bit与OSPFv2选项字段中已定义的6个bit(T、E、MC、N/P, EA、DC),可以看出做了一定的变更。由于OSPFv3不支持TOS(Type of service,服务类型),因而替换了T bit; N bit仍然仅用于Hello包;P bit是OSPFv3选项集中的一部分,是与每个被宣告前缀相关联的前缀选项;OSPFv2 EA bit指示对外部属性LSA(External Attribute LSA)的支持。外部属性LSA被建议为运行iBGP(Internal BGP,内部BGP)以便在整个OSPF域中传递 BGP信息的可选项,目前不但没有实现外部属性LSA,也没有发布任何相关的草案或RFC。虽然没有任何选项bit来定义EA能力,但OSPFv3仍然支持外部属性LSA,作为一种额外的 LSA类型,其拥有指定的泛洪作用域和未知LSA类型处理方式。
新链路LSA不但被用于在同一链路上的路由器之间交换IPv6前缀和地址信息,而且被路由器用来宣告选项集,从而与为该链路而发起的网络LSA建立关联关系。链路LSA提供了路由器的链路本地地址和前缀列表,从而与该链路建立关联关系。LSA以多播方式传送给链路上的所有路由器,由网络LSA所宣告的选项是选项(由所有路由器在链路LSA中进行发送)的逻辑OR。
另一个新LSA是区域间前缀LSA,该LSA携带IPv6前缀信息,这些信息在OSPFv2中是由路由器LSA和网络LSA负责携带的。该前缀被路由器用来宣告分配给路由器本身的地址前缀,如所附属的末梢网络和所附属的转接网络。
包含前缀信息的OSPFv3 LSA都要携带前缀长度、前缀选项和前缀地址等信息,前缀选项字段长8bit,用于描述与前缀相关的能力。目前定义了以下4种选项。
• NU: “no-unicast(非单播)” bit被置位表示将该前缀从单播路由计算中剔除出来。
• LA: “local-address(本地地址)” bit被置位表示该前缀实际上是宣告路由器的IPv6地址。
• MC: “multicast-capable(具备多播能力)” bit被置位表示应该将该前缀纳入多播路由计算之中。
• P: “propagate(传播)” bit被置位表示应该在NSSA区域边界上重新宣告NSSA前缀。
每个前缀都在8bit前缀选项字段(充当不同路由计算的输入)中加以宣告,前缀选项可以用来指示特定前缀是否要被剔除或不应该对外传播。
4.BGP-4多协议扩展
对BGP-4所作的扩展并不专用于IPv6,也包括了对IPX等协议的支持,这里仅讨论与 IPv6相关的BGP-4多协议扩展,有关MBGP的详细信息已经在第7章中讨论过了。
以下3点是与IPv4相关的BGP-4信息。
• 下一跳属性;
• AGGREGATOR属性;
• NLRI(Network Layer Reachability Information,网络层可达性信息)。
截止本书写作之时,假定每个BGP-4发言者都至少维护一个IPv4地址,AGGREGATOR属性将继续使用该地址(可以回顾第2章以获取更多有关AGGREGATOR属性的知识),因而对BGP-4的扩展主要集中在下一跳属性和NLRI。此外,由于下一跳信息被用来向一组目的地转发数据包,并且仅在增加NLRI时才使用该信息(在撤销路由时不使用该信息),下一跳信息已经被加入到可达的NLRI更新中。
为了让BGP支持多协议,增加了两个新属性,分别是MP-REACH-NLRI(MultiProtocol-Reachable NLRI,多协议可达 NLRI)和 MP-UNREACH-NLRI(MultiProtocol-Unreachable NLRI,多协议不可达NLRI),这两个属性都是可选和非传递性属性。也就是说,如果BGP进程无法识别这两个属性,那么就可以直接忽略包含这些属性的更新消息,而不将这些信息宣告给其对等体。
顾名思义,MP-REACH-NLRI属性描述的是可达目的地,该属性包含了地址所属网络层的信息以及用来转发数据包(去往目的前缀列表中所包含的目的地)的下一跳信息。每条MP-REACH-NLRI更新消息都包含一个下一跳地址和一个相关的NLRI列表,NLRI是一个 <length/prefíx>形式的二元组,其中的length是前缀的长度,prefix是可达的IPv6地址前缀。
下一跳是BGP发言者在将数据包转发到相关地址前缀时使用的一个地址,回顾第2章可以知道,下一跳属性的默认规则如下。
• 如果宣告路由器与接收路由器位于不同自治系统(外部对等体),则NEXT—HOP是宣告路由器的接口IP地址;
• 如果宣告路由器与接收路由器位于同一个自治系统(内部对等体),且更新消息的NLRI指向的目的地位于同一个自治系统中,则NEXT—HOP是宣告该路由的邻居的IP地址;
• 如果宣告路由器和接收路由器是内部对等体,且更新消息的NLRI指向的目的地位于不同自治系统中,则NEXT—HOP是外部对等体(该路由学习自该外部对等体)的IP地址。
对IPv6来说,由于IPv6地址定义了作用域,因而上述规则将更加精细。IPv6 BGP路由器宣告下一跳路由器的全局地址,后面也可能包含其链路本地地址。仅当BGP发言者与下一跳字段中所标识的节点以及更新消息所要发送到的对等体共享同一个数据链路时才包含链路本地地址,在其他场合下,下一跳字段中仅包含全局地址。
下面通过网络图、路由器配置以及命令输出结果示例来说明使用IPv6的MBGP的配置及输出情况,所有这一切都与IPv4非常相似。
图8-22给出了一个简单的BGP路由器拓扑结构。
路由器Maple和Aspen为EBGP对等体,Oak和Aspen也是EBGP对等体,这3台路由器都位于同一个快速以太网网段。此外,Oak和Pine是IBGP对等体。
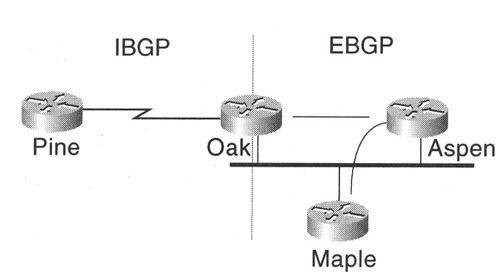
图8-22 一个简单的BGP网络
Aspen将学习自Maple的NLRI宣告给Oak,包括Maple的地址(作为下一跳信息),因而Oak可以直接将流量发送到Maple,而不用再经过额外的一跳Aspen。由于3台路由器共享同一个快速以太网网段,因而Maple的全局地址和链路本地地址都被包含在该更新中。
Oak将Maple的NLRI信息宣告给Pine,下一跳地址是Maple的全局地址,链路本地地址被删除了。例8-8显示了Oak和Aspen的配置情况。
例8-8:BGP路由器配置。

Oak的FastEthernet(快速以太网)地址是200A::2:0:0:0:1/64。从接口子命令中可以看出,Oak是Aspen的EBGP邻居,Oak还有一条IGP链路(前缀为200A:0:0:1::/124)。例8-9显示了BGP邻居的状态、从Oak发送给Aspen有关IGP前缀的BGP更新以及Aspen路由表中的表项。
例8-9:BGP命令输出结果。
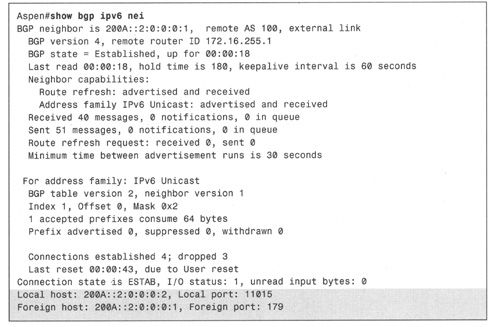
从上述输出结果中可以看出,这些信息与IPv4非常相似。事实上,由于该路由协议是 MBGP,而不是用于IPv6的新版本BGP,输出结果中惟一增加的内容就是表示IPv6和IPv6地址格式的地址族类型——加入了地址族值,而且地址类型不一样;而TCP端口号则一致,还是179。
8.4.6 任播进程
任播是一种将数据包路由到多个拥有相同地址的节点中的某个节点的机制。地址相同的多个节点可能是向客户提供周知服务的一组服务器或是属于某个ISP的一组路由器,其目的是希望流量穿越被分配了任播地址的某个路由器。节点将IP包寻址到单个任播组地址,学习该地址的下一跳(就像是单播地址一样)。如果任播地址是在链(on-link)地址,那么节点就要执行地址解析进程,第一次响应会被添加到邻居缓存中;如果任播地址是离链(off-link)地址,那么就根据路由协议的距离度量将数据包转发到最近的目的地。需要有一个包含域中任播节点集的前缀,如所有使用任播地址FEC0::A:FDFF:FFFF:FFFF:FFFE/64的节点都驻留在前缀FEC0:0:0:A::/64中,这些任播节点都要在域中被宣告为主机路由(以该前缀进行编址),节点利用该主机路由的度量值来确定最近的任播节点。可以看出,如果有很多任播组且组中有很多任播节点,而且包含的域又非常大,那么域中的路由表将非常庞大。
虽然IPv6中规定了任播机制,但目前的使用非常有限,几乎还没有广泛使用任播的服务经验,而且还存在一些周知的复杂因素,如需要确保会话的所有数据包都要到达同一个任播节点或要求任播节点共享状态信息4,随着应用经验的增加会出现更多需要解决的问题。除了所有任播子网路由器(all anycast subnet-router)之外,惟一已定义的任播组就是移动IPv6家乡代理(Mobile IPv6 home-agent)。除非能就所有问题的解决方案达成一致,否则任播的应用将仅局限于路由器。
8.4.7 多播
IPv6提供多播功能并推进了多播应用,在具备多播能力的链路上使用多播(而不是广播)可以减小请求、宣告、更新等消息对网络带来的影响。因为IPv6支持带作用域的多播地址并内嵌支持数据链路组成员关系协议——侦听者发现协议(Listener Discovery Protocol),所以能够大力推动多播的广泛应用。利用PIM(Protocol Independent Multicast,协议无关多播)路由协议,链路上的IPv6主机可以加入整个网络范围内的多播组。
1. 限定了作用域的地址
IPv6的多播地址空间加入了多播作用域,可以创建全球范围公共使用的多播应用,也可以创建某个组织机构或站点内部或单条链路上使用的多播应用。需要设置管理策略以标识站点和组织机构的边界并有效使用多播的作用域,可以在已定义的作用域内包含周知多播组,从而使得多播应用的范围控制更加简单。
2. 侦听者发现
利用源于IGMPv2的MLD(Multicast Listener Discovery,多播侦听者发现)协议,路由器可以发现链路上的哪个节点希望接收多播包以及这些节点所属的多播组,然后将这些信息传递给网络中正在使用的多播路由协议(如PIM)。MLD的功能主要包括主机功能和路由器功能两大部分。
(1)主机功能。
这里所说的主机功能与第5章中所说的IGMPv2的主机功能相似,定义了如下两种类型的报告消息。
• Membership Report(成员关系报告)消息
• Done Report(已完成报告)消息
当主机开始侦听链路上的某特定多播地址时,需要发送一条报告消息以告知路由器链路上有一个侦听者。主机将该报告发送到多播组地址并在报告包的MLD多播地址字段中包含该地址,该报告的源地址是该主机的链路本地地址,使用链路本地源地址可以防止数据包传递到本地链路之外。
路由器会周期性地发送查询消息以确定链路上的主机属于哪个多播组。如果主机接收到的是常规查询(未指定任何特定多播地址),那么就会为每个其正在侦听的多播地址都设置一个延时定时器,链路作用域所有节点(link-scope all-node)多播地址以及作用域为0(保留)或1(节点本地)的多播地址除外。如果主机接收到的是关于某特定多播地址的查询消息,那么仅为该地址设置一个延时定时器。延时定时器值是0至最大响应时间值(是查询消息的一部分)之间的任一个随机值,每个地址的定时器都被设置为一个不同的随机值。
在某多播地址的延时定时器到期时,如果主机仍然没有收到链路上其他主机发送来的报告消息,那么该主机将发送自己的报告消息;如果该主机在定时器到期之前接收到了报告消息,则将终止该延时定时器且不向外发送报告消息。虽然该链路没有因此被该多播组每个成员的报告消息所泛洪,但知道了至少存在一个组成员。
路由器接收到关于某指定多播地址的报告消息后,如果该地址没在该路由器的多播地址列表中,那么该路由器会将该多播地址加入到列表中,并告知该网络正在运行的路由协议;如果该地址已经位于多播地址列表中,那么该路由器会将该地址的定时器值重置为多播侦听者间隔(Multicast Listener Interval)值。如果该定时器到期时仍未收到关于该多播地址的报告消息,那么就会从路由器的列表中删除该地址。
图8-23所示的流程图为MLD进程的主机功能。
主机功能流程图
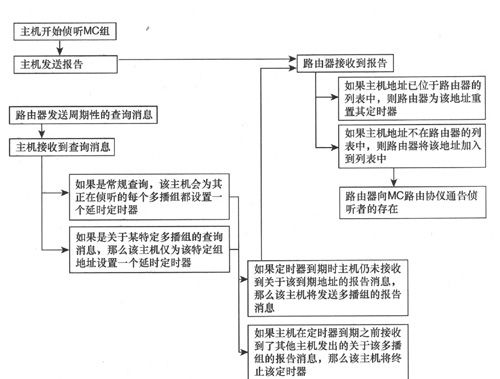
图8-23 MLD进程的主机功能
主机停止侦听多播组后,会发送一条Done(已完成)消息。该消息类似于IGMPv2中的 Leave(离开)消息,会被发送给链路作用域所有路由器(link-scope all-routers)多播组FF02::2,该消息的多播地址字段中携带了该主机停止侦听的多播组地址。但是如果主机发送的关于该地址的报告消息被来自其他节点的报告消息所中断,那么就不需要再发送Done消息,这是因为该链路上的其他节点极有可能正在侦听同一个多播地址。
(2)路由器功能。
MLD的路由器功能也非常类似于第5章中所说的IGMPv2路由器功能,只是术语有些不同。此时路由器发送的是Multicast Listener Query(多播侦听者查询)消息,该消息包括以下两种子类型消息。
• General Query(常规查询)
• Multicast-Address-Specific Query(特定多播地址查询)
查询路由器和非查询路由器的概念仍然存在,路由器为其每条多播链路都假定查询路由器和非查询路由器的状态。与IGMPv2相似,初始化路由器会假定其为查询路由器并立即发送一条General Query(常规查询),如果该路由器接收到来自其他路由器的查询消息,那么就会检查所接收到的查询消息的IPv6源地址。如果该源地址在数值上比其小,那么该路由器会将查询路由器的角色释放给其他路由器;如果地址比其大,那么该路由器将继续充当查询路由器。
查询路由器会在启动时以及周期性地利用General Query消息轮询其所连接的链路,以发现是否存在组成员。查询消息的源地址是该路由器的链路本地地址。查询消息会被发送给链路作用域所有节点(link-scope all-nodes)多播地址FF02::1。
查询路由器接收到“已完成”消息之后,如果“已完成”消息中所指定的地址在其多播地址列表中,则向该多播地址发送一条Multicast-Address-Specific Query(特定多播地址查询)消息,以确定该链路上是否还存在其他侦听者。如果在最大响应时延内都没有接收到主机的响应消息,该路由器就会从其多播地址列表中删除该地址,并告知网络中正在运行的多播路由协议。
图8-24所示的流程图为MLD进程的路由器功能。
路由器功能流程图
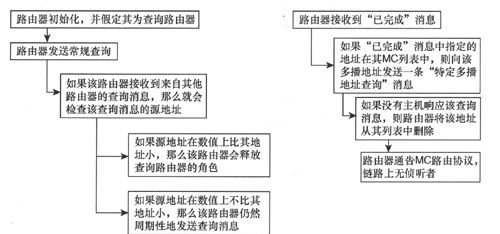
图8-24 MLD进程的路由器功能
3.PIM多播路由
与单播路由协议一样,为了支持IPv6,也要对多播路由协议进行一定的修改,但从功能角度来说,这些协议的运行方式是完全一样的,所做修改主要是为了支持更大的地址空间。PIM是目前惟一已定义了IPv6修改内容的多播路由协议,有关PIM及其他多播路由协议的讨论请参见第5章内容。
为适应IPv6,对PIM所作的修改主要有:定义了PIM消息中必须使用的地址,并说明了带作用域的多播地址以及集中式Bootstrap(引导)机制等内容。
对IPv4来说,每种不同的PIM消息都使用目的地址字段中的多播或单播地址以及其所分配的接口IP地址作为源地址。借助于IPv6带作用域的地址以及可以为每条链路分配多个地址的特点,可以进一步定义使用哪个地址的选择。
大多数PIM消息都将全局IPv6所有PIM路由器(all-PIM-routers)多播地址FF02::D作为 IPv6目的地址,将发送接口的链路本地地址作为源地址,其他PIM消息则使用它们所要通信的服务的特殊全局IPv6单播地址作为目的地址,将它们自己的全局单播地址作为源地址。
在多播接口上发送Hello消息,可以发现PIM邻居。Hello包的目的地址是所有PIM路由器(all-PIM-routers)多播地址,源地址是接口的链路本地地址,因而链路本地地址被用来构建邻居表并选举指派路由器。
路由器通过某接口(路由器将该接口视为(源,组)或(S,G)的出站接口)接收到一个多播包后就会发送Assert(声明)消息。回顾第5章的内容可以知道,多播路由器为每个特定多播源(去往某特定多播组(S,G))都维护了一个带有上行和下行接口的多播转发表,如果路由器在出站(下行)接口上接收到该(S,G)的一个多播包,那么该多播包将由连接到该下行链路上的其他路由器进行转发(如图8-25所示)。
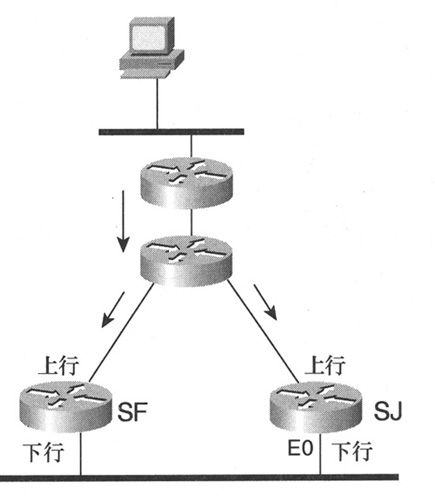
图8-25 在下行接口上接收到的多播包
路由器SJ中关于特定(S,G)的多播转发表显示出E0是离开源的下行接口,因而是出站接口。SJ通过其以太网接口接收到该(S,G)的一个多播包,利用Assert消息为该多路接入网络确定一个PIM转发路由器,由以太网上的SJ发送的Assert消息来确定哪台PIM路由器应该是PIM转发路由器,该消息被发送给所有PIM路由器(all-PIM-routers)多播地址且源自接口的链路本地地址。以链路本地地址的值作为判断依据,链路本地地址数值最大的路由器将成为转发路由器,下行路由器将转发路由器的链路本地地址保存起来以解决将来的RPF需求。
Join/Prune(加入/剪除)、Graft(嫁接)以及Graft-Ack(嫁接确认)等消息(被用来构建并剪除多播路由器的转发表)也将所有PIM路由器(all-PIM-routers)多播地址作为目的地址,并将链路本地地址作为源地址,这些消息也都包含一个上行邻居地址。上行邻居地址被设置成该邻居的链路本地地址,利用RPF查找可以获得该地址,如果无法获得该邻居的链路本地地址,那么就需要为该邻居使用一个已知的全局地址。
将所有PIM路由器(all-PIM-routers)多播地址作为目的地址,并将链路本地地址作为源地址的另一条消息是Bootstrap(引导)消息。Bootstrap消息被BSR(BootStrap Router,引导路由器)以多播方式发送给所有的PIM路由器,该消息中包含了BSR地址。由于所有PIM路由器都要能访问该地址,因而该地址是BSR在整个域范围内均可达的地址。
Register(注册)和Register Stop(注册终止)消息被用于PIM-SM,如果源DR(Designated Router,指派路由器)希望向某多播组发送流量,那么首先要将多播包封装在Register消息中并发送给RP(Rendezvous Point,聚合点),由RP向DR发送Register Stop消息,以告诉源不要再将多播包封装在Register消息中,这些事件并不要求按顺序进行。第5章描述了这些事件的完整顺序,由Register和Register Stop消息将多播包寻址到RP路由器在整个域范围内均可达的地址,源地址是DR路由器在整个域范围内均可达的地址。源DR可以从RP-set信息(由BSR以多播方式发送给所有PIM路由器(all-PIM-routers)多播地址)中获得RP地址,而RP则可以从接收自DR的Register消息的源地址中获得DR的全局IPv6地址。
每个候选RP都要将Candidate-RP-Advertisement(候选RP宣告)消息以单播方式发送给BSR,该消息中不但包含了一个多播组地址(宣告路由器是候选RP),而且包含了被用作该路由器RP地址的IPv6地址。该消息的目的地址是BSR在整个域范围内均可达的单播地址,源地址是候选RP在整个域范围内均可达的单播地址。BSR从这些宣告消息中可以构建RP-seto
虽然带有作用域的多播地址解决了多播定界问题,但是也给PIM和Bootstrap机制带来了一个问题:由于Bootstrap进程是PIM-SM域中的一个集中式进程,如果该PIM域不是某多播地址(带有作用域)域的一个子集,那么Bootstrap机制将无法正常工作。这样一来,位于某个被限定了作用域的多播地址域中的多播包将无法穿越到另一个被限定了作用域的多播地址域中。如果希望Bootstrap机制能够正常运行,就要求PIM域必须是被限定了作用域的多播地址域的子集,或者要求所有的多跳消息都必须使用全局可达的IPv6地址。
8.4.8 QoS
虽然IPv6中并没有内嵌QoS功能,例如,IPv6中没有描述通过路由器进行排队和转发不同流量等级的方法,也没有描述对多个流量流进行优先级划分的方法,但IPv6定义了允许QoS协议与其进行协同操作的相关机制,也就是下面即将讨论的IPv6头部中的流量流(Traffic Flow)和流量等级(Traffic Class)字段。
1. 流量流
发起流量的节点可能希望请求对特定流量流采取特殊处理方式,此时该节点就可以标记该流量流,从而请求IPv6路由器为该流量流采取非默认QoS处理方式。例如,呼叫中心应用要求响应时间非常快,这样使用该呼叫中心应用的呼叫中心客户代表才可以将获得自服务器的信息通过电话机顺畅地告诉客户。为此需要节点来标记该流量流,请求IPv6路由器为该流量流采取不同于其他流量流的差异QoS处理方式。
2. 流量等级
IPv6头部中的流量等级bit为源节点和/或中间路由器提供了区分不同等级或不同优先级 IP包的机制,流量等级bit的使用与IPv4中的ToS(Type-of-Service,服务类型)bit及优先级bit相似,目前仍处于实验性应用阶段。DiffServ(Differentiated Services,差分服务)重新定义了流量等级bit并将其命名为DS字段。DS字段的定义对IPv6及IPv4来说都是一样的,最左侧的6个bit被用作DiffServ的代码点(codepoint),数据包在网络边缘被标记上某个代码点,在对数据包进行排队和转发时,由代码点来确定每台路由器的处理行为,该处理行为就被称为PHB(Per-Hop Behavior,每跳行为)。
