2.2 谁需要 BGP
许多互联网络并不像想象的那样需要BGP,一个错误的观念就是,如果需要将一个互联网络分为多个路由域,那么就应该在不同的路由域之间运行BGP。当然,BGP的确是一种可行选择,但并不一定要在不必要的情况下通过增加其他路由协议而使事情变得复杂不堪。
以一个包含3 000多台路由器、150 000个用户的跨国企业网为例,图2-9显示了这样一个庞大网络的可能构建方式。整个网络采用OSPF进行路由寻址,为了便于管理,根据地理位置关系将整个网络划分为8个OSPF路由域(routing domain),虽然图中显示的每个OSPF域只有一个骨干区域(area),但是每个域都被划分为多个OSPF区域(根据地理位置的亚区域进行划分)。
虽然BGP可以在多个OSPF域之间提供连接性,但这并不是必需的。8个OSPF骨干区域都可以将路由重分发到单个全局骨干区域中,全局骨干是另一个OSPF域,包括多个OSPF区域,虽然全局骨干一般都是由处理包交换负荷的高端路由器组成,但这些路由器在路由表和OSPF方面的处理负荷却非常小。由于整个网络采用了上述寻址方式,因而8个OSPF域都只需向全局骨干宣告一条聚合路由。实际上,聚合对上述网络设计来说非常必不可少。据估算,如果一个包含了大量子网的互联网络中没有聚合OSPF机制的话,路由处理将变得异常困难,结果就是极差的网络性能和可能的路由器故障。
在使图2-9所示的互联网络保持简单性的三个要素中,物理拓扑结构和地址空间的层次化建设是其中的两个,另一个要素是整个互联网络要有一个统一的管理团队,单一管理团队可以保持全网路由策略的统一性和一致性。在这个案例中,路由策略可以指定每个OSPF区域使用的地址范围以及所有OSPF进程都只能通过OSPF 1进行互连。
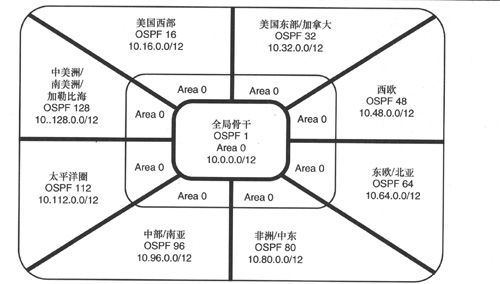
图2-9 即便是一个超大型网络也可以仅使用多IGP域来构建
注意:路由策略实际上就是通过控制路由及其特性来控制互联网络中的流量模型的设计和配置方法。重分发、路由过滤器、路由映射都是Cisco IOS Software中最常见的路由策略实施工具。
当然,在实际应用中,几乎没有哪个如图2-9所示这么大规模的企业互联网络从一开始就按照如此协调、如此有逻辑的方式进行设计。很多(即便不是大多数)大型互联网络都是从较小的互联网络逐渐演化而来的(一般都是随着部门和公司的合并而发展演化),这样一来,不同的网络管理员在互联网络中的各个部分都会做出不同的设计选择,当这些不同的网络部分相互融合时,首先要做的就是保证基本的互操作性。
其次要做的事情可能就是实施路由策略,例如,要求来自互联网络中某些域的某些流量在去往其他路由域时,必须优选某些链路或路由,或者仅在域之间宣告某些特定路由。在大部分场合下,所需的路由策略都可以通过IGP之间的重分发以及路由过滤器和路由映射等工具来实现。因而,除非有必要的工程原因(如IGP无法提供相应的工具来实施所需的路由策略,或路由表的规模无法通过汇总来加以控制),否则不建议部署BGP。实践证明,当域内运行了多种IGP时,BGP非常有用,因为此时在所有的IGP之间实施路由重分发的难度要远大于BGP。
在考虑是否需要在互联网络设计中使用BGP时,首先应该考虑的就是发明外部路由协议的缘由,外部路由协议的作用是在自治系统(也就是不同管理机构下的不同互联网络域)之间传递路由。如果是单一企业网,即使该网络大到拥有多个不同的路由域且归不同的本地管理机构管理,也完全可以通过内部路由协议提供的路由工具,以集权方式来实施路由策略。只有在互连各个独立的自治系统时,才需要使用BGP。本节的后续内容将详细说明典型的AS间拓扑结构,并说明何处需要/不需要BGP。
2.2.1 单归属自治系统
如图2-10所示,某用户通过单链路连接到ISP,这种拓扑结构下无需BGP或任何其他类型的路由协议。当这条单链路失效时,无需做出任何路由选择决定,因为不存在其他可选路由,这样一来即使有路由协议也做不了什么。在这种拓扑结构下,用户只需向边界路由器增加一条静态路由并将该路由重分发到其AS中即可。
与此类似,ISP也会增加一条指向用户地址空间的静态路由并宣告到自己的AS之中。当然,如果用户的地址空间属于ISP更大的地址空间的一部分,那么由ISP路由器宣告的这条静态路由不会被传播到该ISP的AS之外。“其余网络世界”要想到达该用户,只能通过该ISP所宣告的地址空间,只有在ISP的AS之内才能知道到达该用户的精确路由。
在处理AS间流量时,需要记住的一个重要法则是:每条物理链路实际上代表的是两条逻辑链路,一条用于入站流量,另一条用于出站流量(如图2-11所示)。
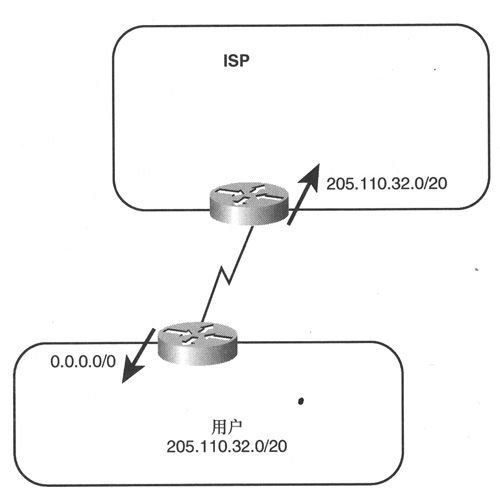
图2-10 单归属拓扑结构下只需配置静态路由即可
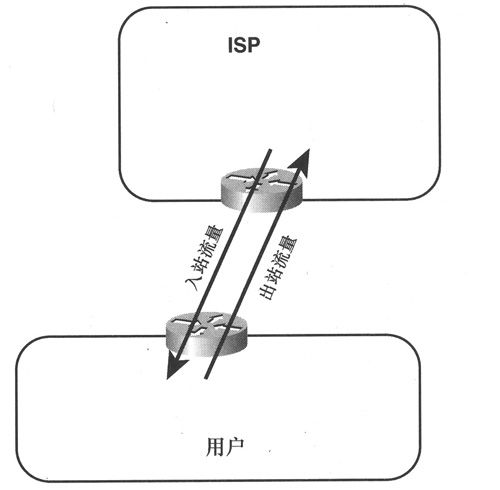
图2-11 自治系统间的每条物理链路代表两条逻辑链路,分别承载入站数据包和出站数据包
在每个方向上宣告的路由仅影响相应方向上的流量,曾经撰写过很多优秀的、关于ISP问题文章的Avi Freedman将路由宣告称为承载数据包到达路由中所表示的地址空间的允诺。在图2-10中,用户路由器将默认路由宣告到本地AS中,即一个将数据包分发到所有目的地(没有其他精确路由)的允诺;同样,宣告了路由205. 110. 32. 0/20的ISP路由器也是允诺将流量转发给用户AS。这样一来,来自用户AS的出站流量得益于默认路由,而去往用户AS的入站流量则得益于由ISP路由器宣告的路由。虽然这个概念对本例来说可能显得有些显而易见,但对今后检查更复杂的拓扑结构来说却至关重要。
图2-10所示的拓扑结构有一个非常明显的脆弱性,那就是整个网络连接都要经受很多单点故障的影响,如果图中的单数据链路出现故障,如果路由器或路由器的某个接口出现故障,如果某台路由器的配置出现故障,如果路由器的某个进程出现故障,或者是如果某个过于人性化的路由器管理员犯了错误,都将会导致用户的整个Internet连接出现故障,这种拓扑结构所缺的就是冗余性(redundancy)。
2.2.2 多归属到单自治系统
图2-12给出了一个改良后的拓扑结构,用户拥有到同一个服务提供商的两条冗余链路,至于入站流量和出站链路如何通过冗余链路则取决于这两条链路的使用方式。例如,典型的多归属到同一个提供商的设置方式是一条链路为主用(专用Internet接入链路,如T1),另一条链路为备用,此时备用链路一般为低速链路。
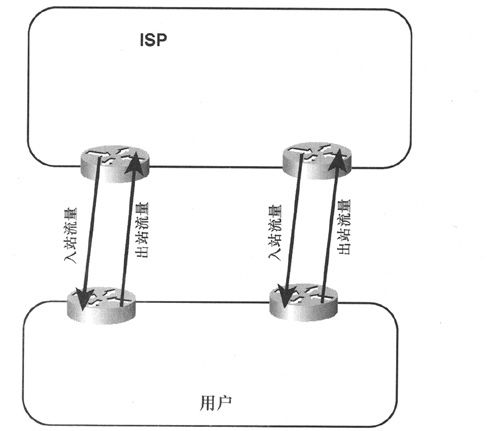
图2-12 多归属到单自治系统
如果冗余链路仅用作备份,那么也不需要使用BGP,此时的路由宣告方式与单归属应用场景一样,只是需要将与备用链路相关的路由距离设置得高一些,以便在主用链路失效时作为备用链路使用。
例2-9显示了带有主用和备用链路情况下的路由器配置情况。
例2-9:多归属到单自治系统的主用和备用链路配置。

在例2-9的配置中,备用路由器有一条管理距离被设置为150的默认路由。这样一来,仅当主用路由器的默认路由不可用时,该备用路由器的默认路由才会进入路由表。而且,备用默认路由以较高的度量值(metric)(大于主用默认路由的度量值)进行宣告,以确保OSPF域中的其他路由器优选主用默认路由。这两条路由的OSPF度量类型均为E2,因而所宣告的度量值在整个OSPF域中保持一致。这种一致性可以保证无论到每台边界路由器的内部代价(cost)是多少,每台路由器上的主用默认路由的度量值都低于备用默认路由的度量值。例2-10给出了某路由器OSPF域内的默认路由情况。
例2-10:首先显示的是主用外部路由,其次显示的是主用路由失效后使用的备用路由。

虽然主用/备用设计方式满足了冗余性的需求,但无法有效地利用可用带宽。一种更好的设计方式是同时使用这两条路径,在链路或路由器出现故障时,这两条路径可以互为备份。此时这两台路由器的配置情况如例2-11所示。
例2-11:多归属到同一AS时的负载共享配置。

上述配置中的两条静态路由的管理距离完全相同,而且默认路由也都以相同的度量值(10)向外宣告。请注意,此时的默认路由以OSPF度量值类型E1向外宣告。对该类型度量值来说,OSPF域中的每台路由器除了要考虑默认路由本身的代价之外,还要考虑到边界路由器的内部代价,因而,每台路由器在选取默认路由时都会选择最近的出口点(见图2-13)。
在大多数情况下,从多个出口点将默认路由宣告到AS中并在相同的出口点对离开AS的地址空间进行汇总,可以实现很好的互联网络性能。需要考虑的一个问题是,非对称流量模式是否会成为一个关注点。如果两个(或多个)出口点的地理间隔足够大,以至于时延变化变得很重要时,就有可能需要进行更好的路由控制,此时就可以考虑是否使用BGP了。
例如,假设图2-12中的两台出口点路由器分别位于洛杉矶和伦敦,并且用户希望所有去往东半球的出流量都使用伦敦路由器,而所有去往西半球的出流量都使用洛杉矶路由器。请记住,入站路由宣告会影响出站流量。如果提供商通过BGP将路由宣告到用户AS中,那么用户的内部路由器将拥有关于外部目的地的更为精确的路由信息。此外,BGP还可以提供相应的工具为外部目的地设置路由策略。
与此相似,出站路由宣告会影响入站流量。如果内部路由通过BGP被宣告给提供商,那么用户就可以决定在哪个出口点宣告哪条路由,并且在将流量发送到用户AS时,可以利用 BGP提供的工具(在一定程度上)影响提供商的选择。
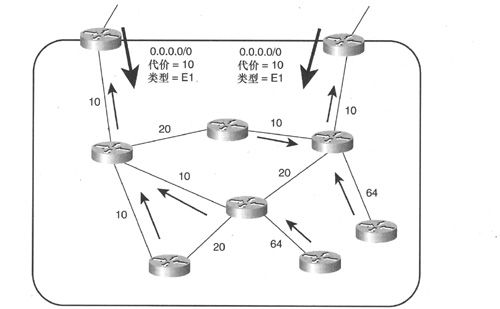
图2-13 边界路由器以度量值10和OSPF度量值类型E1宣告一条默认路由
在考虑是否使用BGP时,需要仔细权衡所得到的好处与增加路由复杂度所带来的代价。只有在对流量控制有益时才应该使用BGP,而且应该分别考虑出站和入站流量,如果仅需要控制用户的入站流量,那么可以通过BGP将路由宣告给提供商,而提供商仍然仅将默认路由宣告给用户AS。
另一方面,如果仅需要控制用户的出站流量,可以使用BGP仅接受提供商的路由,但一定要仔细考虑该从提供商接收哪些路由,“接收全部BGP路由”意味着提供商将会将整个Internet路由表宣告给用户。截至本书写作之时,大约有88 000条路由项(如例2-12所示)。要想存储和处理这么大规模的路由表,需要相当强大的路由器和最少64MB的内存(一般推荐为128MB)。另一方面,也可以利用低端路由器和适当的内存容量轻松实现相对简单的默认路由方案。
例2-12:全Internet路由表汇总信息显示一共有57 624条BGP项。

注意: 例2-12中的路由表汇总信息来源于route-server.ip.att.net公共可访问的路由服务器,另一台可以通过Telnet访问的路由服务器位于route-server.cerf.net。虽然每台服务器上的BGP项数量不完全相同,但其数量规模类似。
接收全路由和不接收任何路由的折衷点是“接收部分BGP路由”。顾名思义,部分路由指的是全部Internet路由的子集,例如,提供商可能仅宣告到达该提供商的其他用户的路由以及到达Internet其余网络的默认路由。后面章节中的内容将证明部分路由是非常有用的。
运行BGP时的另一个考虑因素就是需要利用一个自治系统号来标识用户的路由域。与 IP地址类似,自治系统号也是有限的,并且由区域性地址注册管理机构根据需要进行分配。跟IP地址一样,自治系统号也有一部分被保留用作私有用途:AS号64152~65535。几乎毫无例外,连接到单个服务提供商(无论是单归属还是多归属)的用户都使用保留范围之外的自治系统号,由服务提供商负责将私有AS号从所宣告的BGP路径上过滤掉。
尽管图2-12的拓扑结构已经在图2-10拓扑结构的基础上进行了改进(增加了冗余路由器和数据链路),但是仍然存在单点故障问题——ISP本身。如果该ISP失去了与Internet的连接,那么该用户也将失去与Internet的连接。而且,如果该ISP遭遇了严重的内部故障,那么单归属情况下的用户也将受到拖累。
2.2.3 多归属到多自治系统
如图2-14所示,当用户归属到多个服务提供商时,该用户不但具备了前面所讨论的多归属优势,而且还能防止单ISP故障导致的Internet连接丢失。
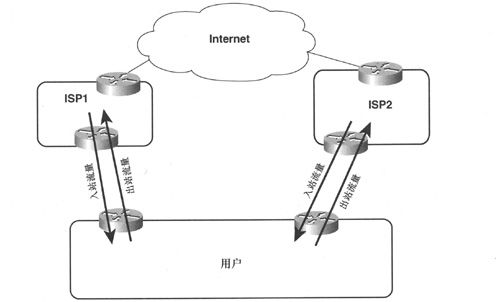
图2-14 多归属到多自治系统
对一个小型企业或小型ISP来说,多归属到多个服务提供商有很多实质性的困难。当用户的地址空间属于服务提供商较大地址空间一部分时,将衍生出来如下的问题。
• 必须说服起端的提供商在其CIDR地址块中“打个洞”;
• 必须说服第二个提供商宣告属于不同提供商的地址空间;
• 两个提供商必须都愿意紧密合作,宣告用户的地址空间;
• 如果用户的地址空间小于/19(一般小用户的地址空间都是如此),某些骨干提供商可能会拒收该路由。
最佳的多归属到多个提供商的用户是那些大到能获得(或者已经获得)与提供商相独立的地址空间以及公有自治系统号的企业和ISP。
图2-14中的用户在使用BGP之前仍然可以考虑其他解决方案。一种可选方式就是选取某个ISP作为主用Internet连接,而将另一个ISP作为备用连接;另一种可选方式是将默认路由设置为两个提供商,让路由选择进程自行选择相应的连接。但是,如果用户已经为多归属花了钱并且与多个提供商签订了相应的合约,那么上述两种解决方案都不可用,此时最好的解决方案就是BGP。
此外,需要分别考虑出站和入站流量。对入站流量来说,如果能将全部内部路由都同时宣告给两个提供商,那么将是最可靠的实现方式。此时,可以确保通过任一个AS都能到达用户AS内的所有目的地,即使两个提供商都宣告相同的路由,入站流量也会优选其中的某一条路径,BGP为此通过了相应的路径优选工具。
对出站流量来说,应仔细考虑从提供商接收到的路由。如果从两个提供商都接收了全部路由,那么就可以为每个Internet连接选择最佳路由。但是,在某些情况下,某个提供商可能是所有Internet连接的优选提供商,而另一个提供商仅是少量目的地的优选提供商,此时可以从优选的提供商处获取全部路由,而仅从另一个提供商获取少量部分路由。例如,如果仅希望通过第二提供商去往其他用户并作为主用Internet提供商的备份时(如图2-15所示),第二提供商会发送其客户路由,而用户则需要配置一条去往第二ISP的默认路由,以在主用ISP失效时使用。
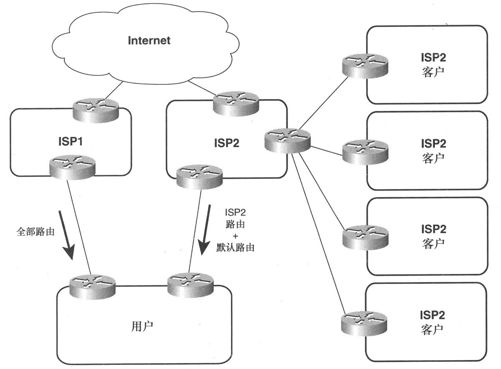
图2-15 ISP1是去往大多数Internet连接的优选提供商,而ISP2仅用于去往其他顾客的互联网络并作为备用Internet连接
需要注意的是,ISP1发送的全部路由中可能会包含ISP2的客户路由。但是,由于用户又会从 ISP2处接收到相同的路由,而用户路由器通常都会优选经ISP2的较短路径,因而,如果到ISP2的链路出现故障,那么用户将使用经ISP1及其他Internet网络的较长路径去往ISP2的客户。
与此类似,用户通常都会选择经ISP1去往除ISP2的客户之外的所有目的地,但是,如果经ISP1的部分或全部精确路由出现丢失情况,那么用户将选择经ISP2的默认路由。
如果路由器因CPU和内存的限制而无法接收全部路由的话,也可以从两个提供商处接收部分路由。每个提供商都会发送其自身的客户路由,而用户则可以将默认路由指向两个提供商。此时,用户将以牺牲路由的精确性来换取路由器硬件的节省。
在其他接收部分路由的应用场合,每个ISP除了发送其自身的客户路由之外,还有可能发送其上游提供商的客户路由。如图2-16所示,ISP1连接到Sprint, ISP2连接到MCI,由ISP1发送给用户的部分路由就包含了ISP1的客户路由和Sprint的全部客户路由,由ISP2发送给用户的部分路由就包含了ISP2的客户路由和MCI的全部客户路由,而用户的默认路由则同时指向两个提供商。由于这两个骨干服务提供商的网络规模都非常大,因而用户将拥有足够的路由对大量目的地做出有效的路由决定。同时,比起Internet全路由表来说,部分路由要小得多。
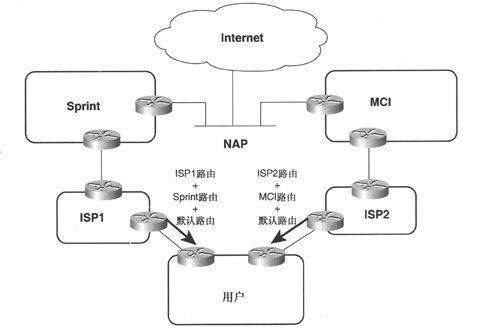
图2-16 用户从两个ISP处接收的部分路由包括每个ISP的客户路由以及相应上游提供商的客户路由
从2.3节开始将解释BGP的操作,以及为入站和出站流量设置优先级和路由策略的工具。
2.2.4 关于“负载均衡”
多归属的主要好处就是冗余性,而且还能在一定程度上增加带宽。但增加带宽并不意味着能平均有效地使用这两条链路的带宽,而且也不应该期望能以50/50的方式完全平均地将流量分布到两条链路上。在实际中,流量占用某ISP的带宽总是比另一个ISP要多得多,该 ISP本身或上游提供商可能拥有更好的路由器、更优的物理链路或更多的NAP连接,或者该 ISP在拓扑结构上有更多的节点靠近用户经常访问的目的地。
当然,这并不是说通过大量的时间及精力也无法控制路由的优先级,让路由流量在两条链路上进行平均分配。不过问题在于,如果为了所谓的负载均衡而强制将某些流量引导到非最优路由时,实质上会导致Internet性能的劣化。在大多数情况下,实际上所实现的负载均衡都是非完全均衡地使用两条ISP链路,不用太在意某条链路占用了75%,而另一条链路只占用了25%。多归属的主要目的是提供冗余性并增加路由选择的效率,而不是负载均衡。
2.2.5 BGP 的危害
创建BGP对等关系涉及一个有趣的信任与非信任问题。一方面,由于BGP对等体是另一个AS,因而必须信任对端的网络管理员,以便了解他正在做些什么;另一方面,如果足够聪明,还应该检查每个操作,以防止对端网络管理员的错误操作而对本网造成损害。在实施BGP对等连接的时候,偏执一点也许更好。
回顾前面有关路由宣告的描述,路由宣告实质上是一个将数据包分发到所宣告目的地的承诺。对外宣告的路由会直接影响所接收到的数据包,而接收到的路由会直接影响所发送的数据包。对一个好的BGP对等方案来说,双方都应该完全了解每个方向上所宣告的路由,而且必须分别考虑入站流量和出站流量;每个对等体都要确保仅传送正确路由,同时还要使用路由过滤器或其他路由策略工具(如将在第3章描述的AS_PATH过滤器)确保仅接收正确路由。
ISP一般都不会容忍用户的BGP配置差错,最糟糕的情况是双方的BGP对等方案都出现了故障。举例来说,假如用户因某种错误配置而将207.46.0.0/16宣告给了ISP,对接收方来说,ISP不但没有过滤掉该条错误路由,而且还将该路由宣告给了外部Internet,该特定CIDR地址块属于微软,但用户却对外申明拥有去往该目的地的路由。这样一来,大量的Internet团体可能都会认为通过该用户路由域去往微软是最佳路由,导致该用户将接收大量来自Internet的非期望数据包,更为严重的是,该用户接收了应该去往微软的大量黑洞流量。此时,该用户和ISP不但烦恼,而且无法理解。
图2-17给出了另一个BGP路由错误案例。该互联网络与图2-15类似,区别在于本例中用户从ISP2学习到的客户路由因疏忽而被宣告给了ISP1。
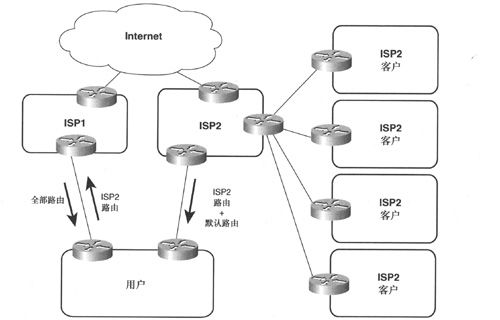
图2-17 用户将学习自ISP2的路由宣告给了ISP1,从而引导去往ISP2及其客户的数据包通过该用户路由器进行转接
在各种可能性当中,ISP1及其客户将用户的路由域视为去往ISP2及其客户的最佳路径。由于该用户确实有一条去往ISP2的路由,因而这些流量并没有被黑洞化,只是此时的用户域将成为自ISP1去往ISP2的数据包的转接域,对自身的流量不利。由于从ISP2到ISP1的路由仍然要通过Internet,因而该用户会导致ISP2出现不对称路由。
从本质上来说,本节讨论的核心是BGP被设计用来在自主控制的系统之间进行通信。一个成功的、可靠的BGP对等方案不仅需要深入了解每个方向上所宣告的路由,还要深入了解每个对等方的路由策略。
