9.9 故障管理
可信赖的网络需要良好的故障管理机制,需要尽可能快地发现潜在和现有故障,以便快速采取措施来解决问题,希望在用户感知网络故障之前,故障管理系统就能检测到设备和链路的故障。
配置了SNMP的路由器在检测到故障后会向管理站发送trap消息,但是由于SNMP利用UDP来发送trap,因而无法保证描述故障信息的消息能到达管理站。因而,故障管理系统不能仅依赖trap,还需要轮询路由器以了解线路、接口和路由器部件的状态情况,除了轮询路由器的部件信息之外,有时管理站还要轮询路由器本身(利用ICMP ping),以确定路由器是否可达。为了确保能够通过任意活动接口到达路由器的IP地址,建议最好使用环回地址作为路由器的标识IP地址,这是因为如果管理站轮询或ping的是路由器的环回地址,那么就可以使用任意可用被路由路径来访问该路由器。而如果管理站轮询或ping的是路由器的非环回接口地址,那么如果该接口失效,即便能够通过其他可用路径到达该路由器,管理站也会宣告该路由器不可达。因而应该配置trap消息使用环回地址作为数据包的源地址,并配置管理站通过环回地址来轮询路由器。
与许多协议一样,需要在管理站快速检测到网络故障与所产生的流量之间做一个平衡。如果管理站没收到trap,那么就需要依赖其轮询或ping机制来检测故障,这样就有可能在一段时间之后才检测到故障。如果故障设备是一台路由器,而管理站被配置为每隔5分钟ping一次路由器,如果管理站没收到trap消息,那么管理站将至多可能需要15分钟才能检测到该故障并宣告路由器失效。至于链路故障及其他组件故障,检测速度则要快一些,因为此时管理站不再依赖于未收到这些组件的回应消息来检测故障,而是直接询问路由器有关这些组件的状态,由路由器向管理站回应这些状态信息。
例如,图9-3所示的管理站正在轮询路由器的接口状态。
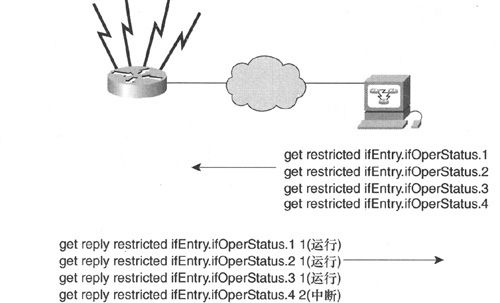
图9-3 管理站正在轮询路由器的接口状态
管理站利用MIB中的ifEntry.ifOperStatus object ID来轮询路由器的接口状态,路由器将给予回应,可以看出,3个接口处于有效状态,1个接口处于无效状态。
故障管理系统的作用就是检测故障,检测到故障之后就通过可视化或可听见的告警/发送电子邮件/发送短信等方式报告给网络操作员。发送告警的方式可以根据需要进行定制,如果用户需要7×24小时坐在管理控制台前,那么可听见和可视化告警就足够了;如果控制台不是全天有人监控,那么就可以在无人值守时发送电子邮件或短信告警。故障可以指示链路、路由器或路由器部件失效情况,在故障发生后即形成告警。此外,在故障出现之前,故障管理站也会试图向操作员发出告警。
很多时候,某些特定事件会导致组件故障,例如,串行线路在完全失效之前可能会报告高差错数或载波变换,路由器在失效之前也可能会报告内存问题。故障管理站负责维护阈值信息,超过设定的阈值之后,就会向网络操作员发送告警信息。可以为任意数量的变量设置阈值,在配置阈值之前,需要首先确定网络基准,网络基准需要在网络正常运行的一段时间(如一周)里进行测量,这样就可以得到各个变量的标准值,从而可以按照比正常值高一定比例(如20%)的方式来配置变量阈值。
下面提供了有用信息的一些MIB变量。
• 空闲内存量
• 平均CPU使用率
• 缓冲区故障
• 接口输入和输出速率
• 接口输入和输出错误
• 接口输入和输出队列丢包
• 接口包忽略
• 接口重启
• 串行接口CRC、终止和帧差错
• 帧中继FECN/BECN
• 串行接口载波转换
• 以太网冲突
• 以太网短帧、巨帧和帧差错
• 令牌环线路和突发差错
• 令牌环令牌和软故障
• 令牌环信号丢失
上面列出的某些变量可能出现在正常网络中,但是超过某个阈值之后,性能将开始劣化,并可能出现较为严重的问题。管理站会周期性地轮询路由器以获得这些变量的值,如果轮询周期之间的变量值变化情况超过了阈值,则生成告警。
也可以使用RMON来设置阈值,有了RMON,管理站就无需轮询这些变量,由路由器上的RMON代理在本地轮询这些变量,并在超出阈值时向管理站发送trap,管理站接收到trap之后就生成告警。这里存在一个网络使用率与路由器处理能力的平衡,虽然RMON能够减少网络流量,但也增大了路由器的处理需求。
